

La commande Linux grep est un utilitaire de correspondance de chaînes et de modèles qui affiche les lignes correspondantes de plusieurs fichiers. Il fonctionne également avec la sortie canalisée d’autres commandes. Nous vous montrons comment.
Table des matières
L’histoire derrière grep
La commande grep est célèbre sous Linux et Unix cercles pour trois raisons. Premièrement, il est extrêmement utile. Deuxièmement, le la multitude d’options peut être écrasante. Troisièmement, il a été rédigé du jour au lendemain pour répondre à un besoin particulier. Les deux premiers sont parfaits; le troisième est légèrement décalé.
Ken Thompson avait extrait les capacités de recherche d’expressions régulières de l’éditeur ed (prononcé ee-dee) et a créé un petit programme – pour son propre usage – pour rechercher dans les fichiers texte. Son chef de service à Bell Labs, Doug Mcilroy, s’est approché de Thompson et a décrit le problème à l’un de ses collègues, Lee McMahon, faisait face.
McMahon essayait d’identifier les auteurs du Papiers fédéralistes par l’analyse textuelle. Il avait besoin d’un outil capable de rechercher des phrases et des chaînes dans des fichiers texte. Thompson a passé environ une heure ce soir-là à faire de son outil un utilitaire général qui pourrait être utilisé par d’autres et l’a renommé en grep. Il a pris le nom de la chaîne de commande ed g / re / p, qui se traduit par «recherche d’expression régulière globale».
Vous pouvez regarder Thompson parler à Brian Kernighan à propos de la naissance de grep.
Recherches simples avec grep
Pour rechercher une chaîne dans un fichier, transmettez le terme de recherche et le nom du fichier sur la ligne de commande:

Les lignes correspondantes s’affichent. Dans ce cas, il s’agit d’une seule ligne. Le texte correspondant est mis en surbrillance. En effet, sur la plupart des distributions, grep a un alias:
alias grep='grep --colour=auto'
Regardons les résultats où plusieurs lignes correspondent. Nous chercherons le mot «Moyenne» dans un fichier journal d’application. Comme nous ne pouvons pas nous rappeler si le mot est en minuscules dans le fichier journal, nous utiliserons l’option -i (ignorer la casse):
grep -i Average geek-1.log

Chaque ligne correspondante est affichée, avec le texte correspondant en surbrillance dans chacune.
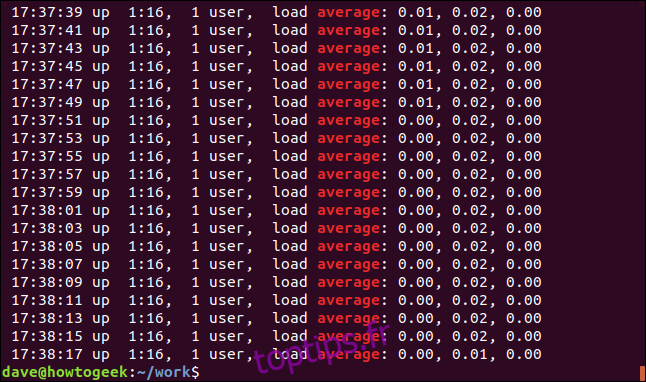
Nous pouvons afficher les lignes non concordantes en utilisant l’option -v (invert match).
grep -v Mem geek-1.log

Il n’y a pas de mise en évidence car ce sont les lignes qui ne correspondent pas.
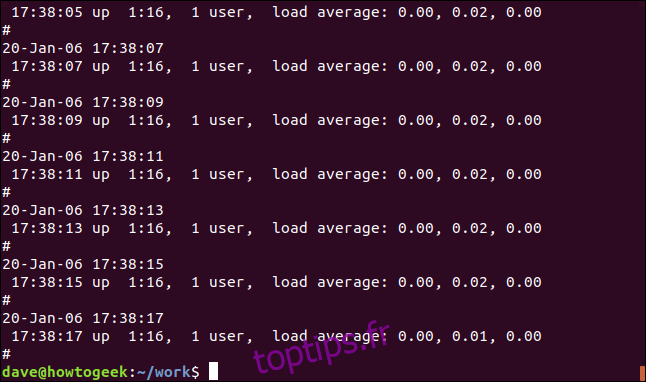
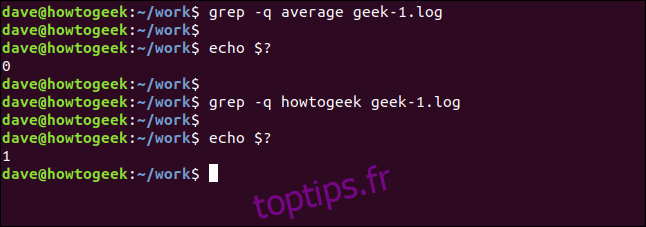
Nous pouvons faire en sorte que grep soit complètement silencieux. Le résultat est passé au shell en tant que valeur de retour de grep. Un résultat de zéro signifie que la chaîne a été trouvée, et un résultat de un signifie qu’elle n’a pas été trouvée. Nous pouvons vérifier le code de retour en utilisant le $? paramètres spéciaux:
grep -q average geek-1.log
echo $?
grep -q howtogeek geek-1.log
echo $?
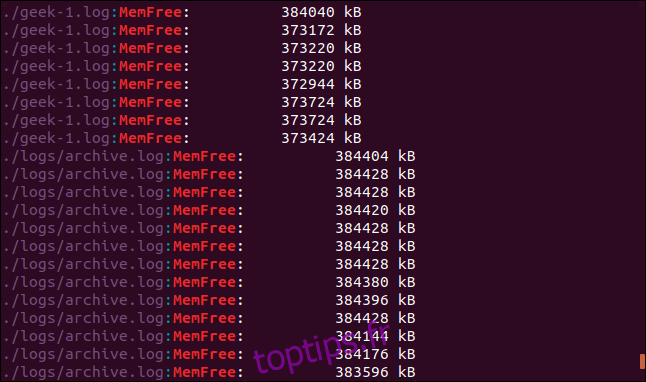
Recherches récursives avec grep
Pour rechercher dans les répertoires et sous-répertoires imbriqués, utilisez l’option -r (récursive). Notez que vous ne fournissez pas de nom de fichier sur la ligne de commande, vous devez fournir un chemin. Ici, nous recherchons dans le répertoire actuel « . » et tous les sous-répertoires:
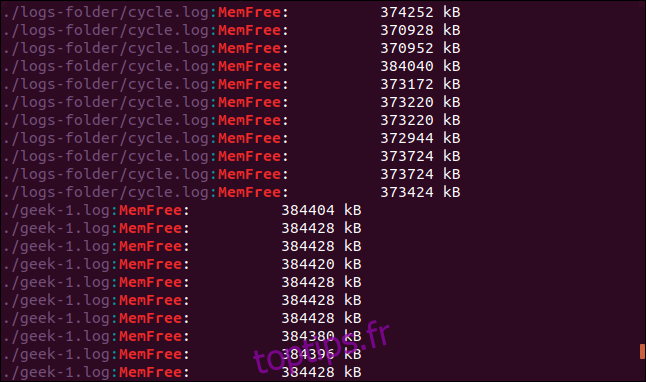
grep -r -i memfree .

La sortie comprend le répertoire et le nom de fichier de chaque ligne correspondante.
Nous pouvons faire en sorte que grep suive les liens symboliques en utilisant l’option -R (déréférence récursive). Nous avons un lien symbolique dans ce répertoire, appelé logs-folder. Il pointe vers / home / dave / logs.
ls -l logs-folder

Répétons notre dernière recherche avec l’option -R (déréférence récursive):
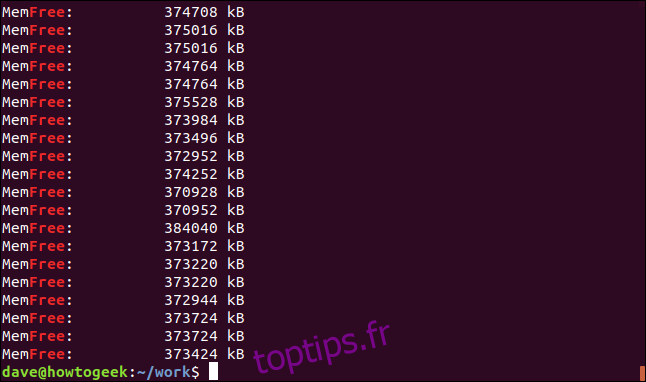
grep -R -i memfree .

Le lien symbolique est suivi et le répertoire vers lequel il pointe est également recherché par grep.
Recherche de mots entiers
Par défaut, grep correspondra à une ligne si la cible de recherche apparaît n’importe où dans cette ligne, y compris dans une autre chaîne. Regardez cet exemple. Nous allons rechercher le mot «gratuit».
grep -i free geek-1.log

Les résultats sont des lignes contenant la chaîne «free», mais ce ne sont pas des mots séparés. Ils font partie de la chaîne « MemFree ».
Pour forcer grep à correspondre uniquement à des «mots» séparés, utilisez l’option -w (expression rationnelle de mot).
grep -w -i free geek-1.log
echo $?
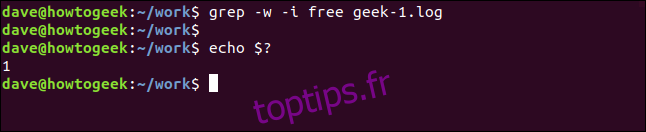
Cette fois, il n’y a pas de résultats car le terme de recherche «gratuit» n’apparaît pas dans le fichier en tant que mot distinct.
Utilisation de plusieurs termes de recherche
L’option -E (expression régulière étendue) vous permet de rechercher plusieurs mots. (L’option -E remplace la version obsolète egrep version de grep.)
Cette commande recherche deux termes de recherche, «moyenne» et «sans mémoire».
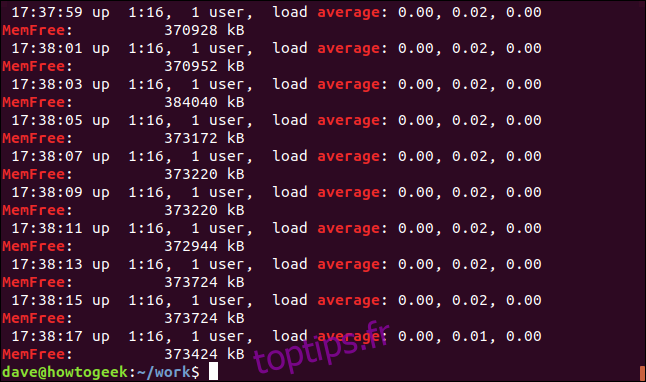
grep -E -w -i "average|memfree" geek-1.log

Toutes les lignes correspondantes sont affichées pour chacun des termes de recherche.
Vous pouvez également rechercher plusieurs termes qui ne sont pas nécessairement des mots entiers, mais qui peuvent également être des mots entiers.
L’option -e (modèles) vous permet d’utiliser plusieurs termes de recherche sur la ligne de commande. Nous utilisons la fonction de crochet d’expression régulière pour créer un modèle de recherche. Il indique à grep de correspondre à l’un des caractères contenus entre crochets « []. » Cela signifie que grep correspondra à «Ko» ou «Ko» lors de sa recherche.
![grep -e MemFree -e [kK]B geek-1.log dans une fenêtre de terminal](https://toptips.fr/wp-content/uploads/2021/01/1610319020_434_Comment-utiliser-la-commande-grep-sous-Linux.png)
Les deux chaînes sont mises en correspondance et, en fait, certaines lignes contiennent les deux chaînes.
![Sortie de grep -e MemFree -e [kK]B geek-1.log dans une fenêtre de terminal](https://toptips.fr/wp-content/uploads/2021/01/1610319021_345_Comment-utiliser-la-commande-grep-sous-Linux.png)
Correspondance exacte des lignes
Le -x (expression rationnelle de ligne) ne correspondra qu’aux lignes dont la ligne entière correspond au terme de recherche. Cherchons une date et un horodatage dont nous savons qu’ils n’apparaissent qu’une seule fois dans le fichier journal:
grep -x "20-Jan--06 15:24:35" geek-1.log

La seule ligne qui correspond est trouvée et affichée.
Le contraire ne montre que les lignes qui ne correspondent pas. Cela peut être utile lorsque vous consultez des fichiers de configuration. Les commentaires sont excellents, mais il est parfois difficile de repérer les paramètres réels parmi tous. Voici le fichier / etc / sudoers:
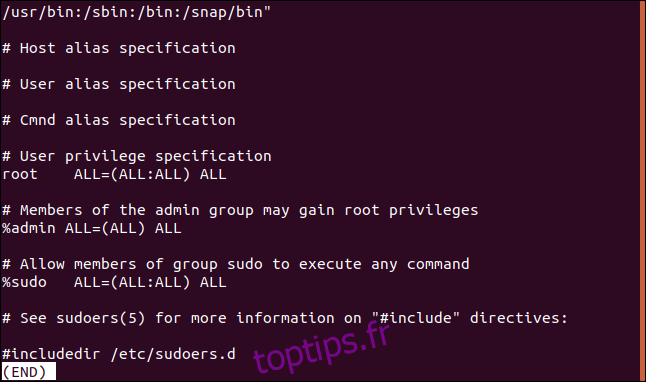
Nous pouvons filtrer efficacement les lignes de commentaires comme ceci:
sudo grep -v "https://www.howtogeek.com/496056/how-to-use-the-grep-command-on-linux/#" /etc/sudoers
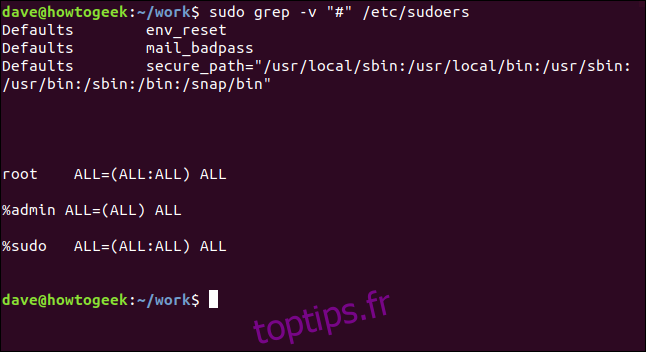
C’est beaucoup plus facile à analyser.
Afficher uniquement le texte correspondant
Il se peut que vous ne souhaitiez pas voir toute la ligne correspondante, juste le texte correspondant. L’option -o (seulement correspondant) fait exactement cela.
grep -o MemFree geek-1.log

L’affichage est réduit à n’afficher que le texte qui correspond au terme de recherche, au lieu de toute la ligne correspondante.

Compter avec grep
grep ne concerne pas seulement le texte, il peut également fournir des informations numériques. Nous pouvons faire en sorte que grep compte pour nous de différentes manières. Si nous voulons savoir combien de fois un terme de recherche apparaît dans un fichier, nous pouvons utiliser l’option -c (count).
grep -c average geek-1.log

grep signale que le terme de recherche apparaît 240 fois dans ce fichier.
Vous pouvez faire en sorte que grep affiche le numéro de ligne pour chaque ligne correspondante en utilisant l’option -n (numéro de ligne).
grep -n Jan geek-1.log

Le numéro de ligne de chaque ligne correspondante est affiché au début de la ligne.
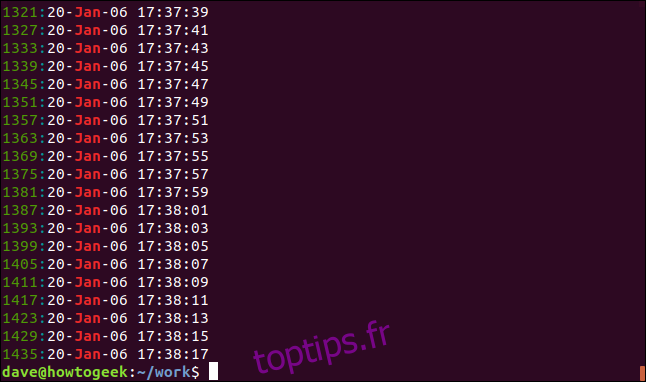
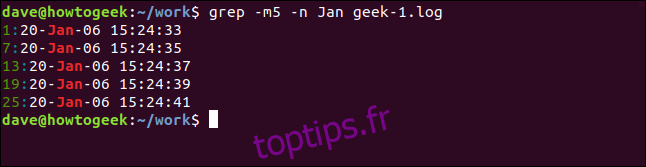
Pour réduire le nombre de résultats affichés, utilisez l’option -m (nombre max). Nous allons limiter la sortie à cinq lignes correspondantes:
grep -m5 -n Jan geek-1.log
Ajout de contexte
Il est souvent utile de pouvoir voir des lignes supplémentaires – éventuellement des lignes non correspondantes – pour chaque ligne correspondante. cela peut aider à distinguer les lignes correspondantes qui vous intéressent.
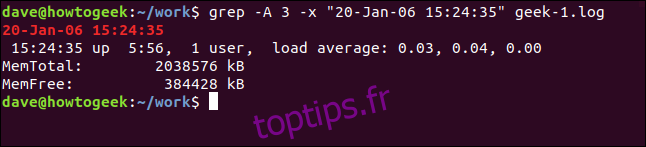
Pour afficher quelques lignes après la ligne correspondante, utilisez l’option -A (après le contexte). Nous demandons trois lignes dans cet exemple:
grep -A 3 -x "20-Jan-06 15:24:35" geek-1.log
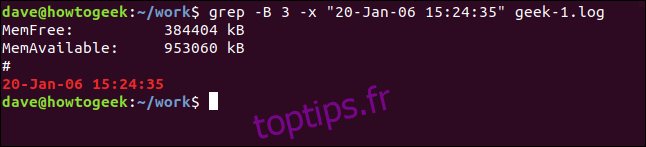
Pour voir quelques lignes avant la ligne correspondante, utilisez l’option -B (contexte avant).
grep -B 3 -x "20-Jan-06 15:24:35" geek-1.log
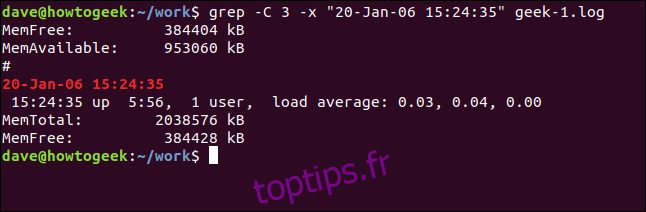
Et pour inclure les lignes avant et après la ligne correspondante, utilisez l’option -C (contexte).
grep -C 3 -x "20-Jan-06 15:24:35" geek-1.log
Affichage des fichiers correspondants
Pour voir les noms des fichiers contenant le terme de recherche, utilisez l’option -l (fichiers avec correspondance). Pour savoir quels fichiers de code source C contiennent des références au fichier d’en-tête sl.h, utilisez cette commande:
grep -l "sl.h" *.c

Les noms de fichiers sont répertoriés, pas les lignes correspondantes.

Et bien sûr, nous pouvons rechercher des fichiers qui ne contiennent pas le terme de recherche. L’option -L (fichiers sans correspondance) fait exactement cela.
grep -L "sl.h" *.c

Début et fin des lignes
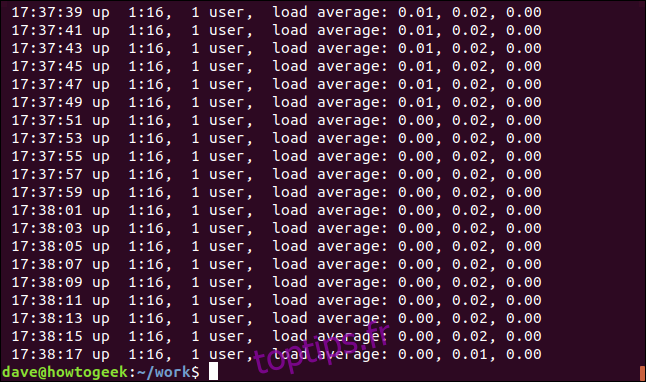
Nous pouvons forcer grep à n’afficher que les correspondances qui se trouvent au début ou à la fin d’une ligne. L’opérateur d’expression régulière «^» correspond au début d’une ligne. Pratiquement toutes les lignes du fichier journal contiendront des espaces, mais nous allons rechercher les lignes qui ont un espace comme premier caractère:
grep "^ " geek-1.log

Les lignes qui ont un espace comme premier caractère – au début de la ligne – sont affichées.
Pour faire correspondre la fin de la ligne, utilisez l’opérateur d’expression régulière «$». Nous allons rechercher les lignes qui se terminent par «00».
grep "00$" geek-1.log

L’écran affiche les lignes qui ont «00» comme caractères finaux.
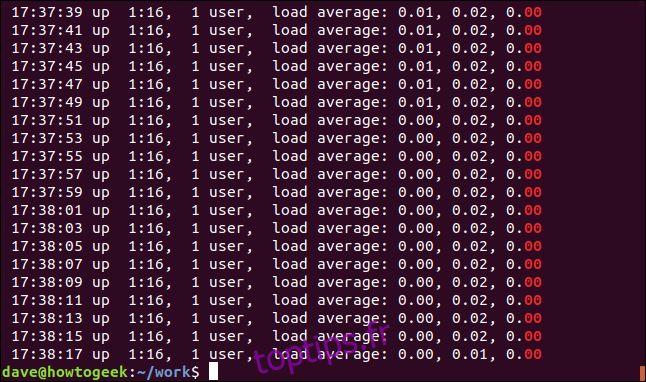
Utilisation de tuyaux avec grep
Bien sûr, vous pouvez diriger l’entrée vers grep, diriger la sortie de grep vers un autre programme et placer grep au milieu d’une chaîne de canaux.
Disons que nous voulons voir toutes les occurrences de la chaîne «ExtractParameters» dans nos fichiers de code source C. Nous savons qu’il y en aura pas mal, nous réduisons donc la sortie en moins:
grep "ExtractParameters" *.c | less

La sortie est présentée en moins.
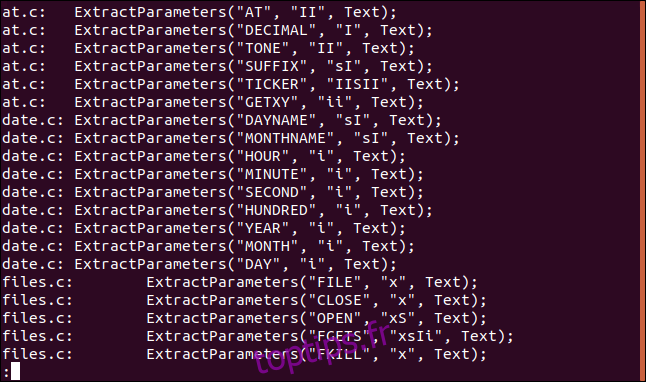
Cela vous permet de parcourir la liste des fichiers et d’utiliser la fonction de recherche de less.
Si nous acheminons la sortie de grep vers wc et utilisons l’option -l (lignes), nous peut compter le nombre de lignes dans les fichiers de code source contenant «ExtractParameters». (Nous pourrions y parvenir en utilisant l’option grep -c (count), mais c’est une manière intéressante de démontrer la sortie de grep.)
grep "ExtractParameters" *.c | wc -l

Avec la commande suivante, nous acheminons la sortie de ls vers grep et la sortie de grep vers tri. Nous listons les fichiers dans le répertoire actuel, en sélectionnant ceux contenant la chaîne « Aug », et les trier par taille de fichier:
ls -l | grep "Aug" | sort +4n
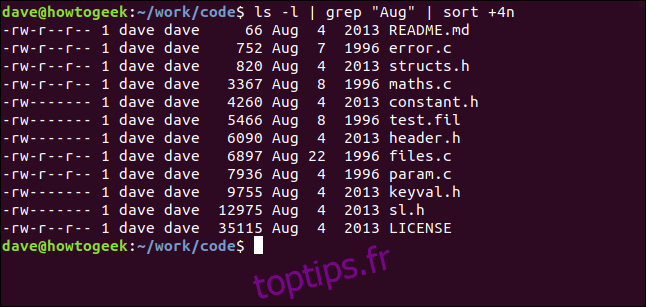
Décomposons cela:
ls -l: exécute une longue liste de format des fichiers en utilisant ls.
grep “Aug”: Sélectionnez les lignes de la liste ls qui contiennent “Aug”. Notez que cela permet également de rechercher les fichiers dont le nom contient «Aug».
sort + 4n: trie la sortie de grep sur la quatrième colonne (taille du fichier).
Nous obtenons une liste triée de tous les fichiers modifiés en août (quelle que soit l’année), par ordre croissant de taille de fichier.
grep: moins une commande, plus un allié
grep est un outil formidable à avoir à votre disposition. Il date de 1974 et continue de fonctionner car nous avons besoin de ce qu’il fait, et rien ne le fait mieux.
Le couplage de grep avec des expressions régulières-fu l’amène vraiment au niveau supérieur.