

Le web scraping vous permet de collecter efficacement de grandes quantités de données sur Internet de manière très rapide et est particulièrement utile dans les cas où les sites Web n’exposent pas leurs données de manière structurée grâce à l’utilisation d’interfaces de programmation d’applications (API).
Par exemple, imaginez que vous créez une application qui compare les prix des articles sur les sites de commerce électronique. Comment procéderiez-vous? Une solution consiste à vérifier manuellement le prix des articles sur tous les sites et à enregistrer vos résultats. Cependant, ce n’est pas une méthode intelligente car il existe des milliers de produits sur les plateformes de commerce électronique et il vous faudrait une éternité pour extraire les données pertinentes.
Une meilleure façon d’y parvenir consiste à supprimer le Web. Le Web scraping est le processus d’extraction automatique de données de pages Web et de sites Web grâce à l’utilisation d’un logiciel.
Les scripts logiciels, appelés web scrapers, sont utilisés pour accéder aux sites Web et récupérer des données à partir des sites Web. Les données récupérées, généralement sous une forme non structurée, peuvent ensuite être analysées et stockées de manière structurée et significative pour les utilisateurs.
Le Web scraping est très utile dans l’extraction de données car il donne accès à une multitude de données et permet une automatisation, de sorte que vous pouvez planifier l’exécution de votre script de web scraping à certains moments ou en réponse à certains déclencheurs. Le web scraping vous permet également d’obtenir des mises à jour en temps réel et facilite la réalisation d’études de marché.

De nombreuses entreprises et sociétés s’appuient sur le web scraping pour extraire des données à des fins d’analyse. Les entreprises spécialisées dans les ressources humaines, le commerce électronique, la finance, l’immobilier, les voyages, les médias sociaux et la recherche utilisent le web scraping pour extraire des données pertinentes des sites Web.
Google lui-même utilise le web scraping pour indexer les sites Web sur Internet afin de pouvoir fournir des résultats de recherche pertinents aux utilisateurs.
Cependant, il est important de faire preuve de prudence lors de la mise au rebut du Web. Bien que la suppression de données accessibles au public ne soit pas illégale, certains sites Web ne permettent pas cette suppression. Cela peut être dû au fait qu’ils disposent d’informations sensibles sur les utilisateurs, que leurs conditions d’utilisation interdisent explicitement la suppression de sites Web ou qu’ils protègent la propriété intellectuelle.
De plus, certains sites Web n’autorisent pas le web scraping, car cela peut surcharger le serveur du site Web et entraîner une augmentation des coûts de bande passante, en particulier lorsque le web scraping est effectué à grande échelle.
Pour vérifier si un site Web peut être supprimé, ajoutez robots.txt à l’URL du site Web. robots.txt est utilisé pour indiquer aux robots quelles parties du site Web peuvent être récupérées. Par exemple, pour vérifier si vous pouvez supprimer Google, accédez à google.com/robots.txt
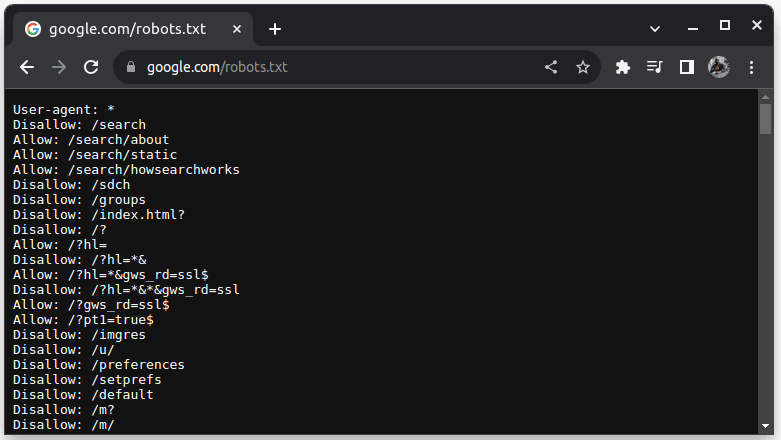
Agent utilisateur : * fait référence à tous les robots ou scripts logiciels et robots d’exploration. Disallow est utilisé pour indiquer aux robots qu’ils ne peuvent accéder à aucune URL d’un répertoire, par exemple /search. Autoriser indique les répertoires à partir desquels ils peuvent accéder aux URL.
Un exemple de site qui n’autorise pas le scraping est LinkedIn. Pour vérifier si vous pouvez supprimer LinkedIn, accédez à linkedin.com/robots.txt
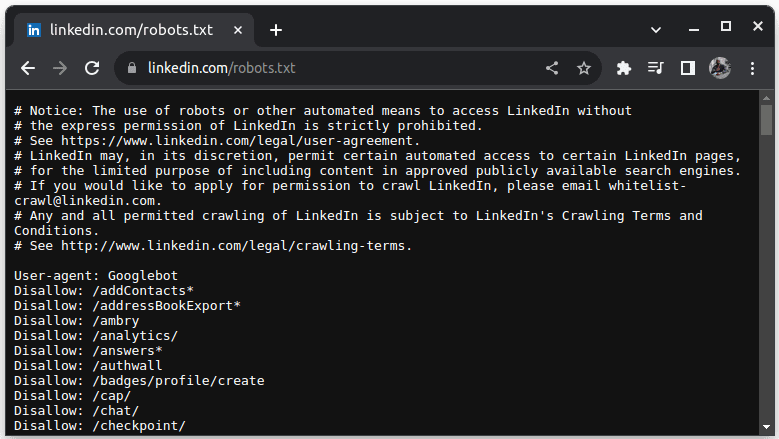
Comme vous pouvez le constater, vous n’êtes pas autorisé à supprimer LinkedIn sans leur autorisation. Vérifiez toujours si un site Web autorise le scraping pour éviter tout problème juridique.
Table des matières
Pourquoi Java est un langage approprié pour le Web Scraping
Bien que vous puissiez créer un grattoir Web avec une variété de langages de programmation, Java est particulièrement idéal pour ce travail pour plusieurs raisons. Premièrement, Java possède un écosystème riche et une vaste communauté et fournit une variété de bibliothèques de web scraping telles que JSoup, WebMagic et HTMLUnit, qui facilitent l’écriture de web scrapers.

Il fournit également des bibliothèques d’analyse HTML pour simplifier le processus d’extraction de données à partir de documents HTML et des bibliothèques réseau telles que HttpURLConnection pour effectuer des requêtes vers différentes URL de sites Web.
La forte prise en charge par Java de la concurrence et du multithreading est également bénéfique pour le web scraping, car elle permet un traitement et une gestion parallèles des tâches de web scraping avec plusieurs requêtes, vous permettant ainsi de scraper plusieurs pages simultanément. L’évolutivité étant l’un des principaux atouts de Java, vous pouvez facilement supprimer des sites Web à grande échelle à l’aide d’un grattoir Web écrit en Java.
La prise en charge multiplateforme de Java est également utile car elle vous permet d’écrire un grattoir Web et de l’exécuter sur n’importe quel système doté d’une machine virtuelle Java compatible. Par conséquent, vous pouvez écrire un grattoir Web dans un système d’exploitation ou un appareil et l’exécuter dans un autre système d’exploitation sans avoir besoin de modifier le grattoir Web.
Java peut également être utilisé avec des navigateurs sans tête tels que Headless Chrome, HTML Unit, Headless Firefox et PhantomJs, entre autres. Un navigateur sans tête est un navigateur sans interface utilisateur graphique. Les navigateurs sans tête peuvent simuler les interactions des utilisateurs et sont très utiles lors du scraping de sites Web qui nécessitent des interactions des utilisateurs.
Pour couronner le tout, Java est un langage très populaire et largement utilisé qui est pris en charge et peut facilement être intégré à une variété d’outils tels que des bases de données et des frameworks de traitement de données. Ceci est avantageux car cela garantit que lorsque vous récupérez des données, tous les outils dont vous aurez besoin pour récupérer, traiter et stocker les données prennent probablement en charge Java.
Voyons comment nous pouvons utiliser Java pour la suppression de sites Web.
Java pour le Web Scraping : prérequis
Pour utiliser Java dans le web scraping, les conditions préalables suivantes doivent être remplies :
1. Java – Java doit être installé, de préférence la dernière version de support à long terme. Si Java n’est pas installé, allez sur installer Java pour savoir comment installer Java sur votre machine
2. Environnement de développement intégré (IDE) – Vous devez avoir un IDE installé sur votre machine. Dans ce didacticiel, nous utiliserons IntelliJ IDEA, mais vous pouvez utiliser n’importe quel IDE que vous connaissez.
3. Maven – ceci sera utilisé pour la gestion des dépendances et pour installer une bibliothèque de web scraping.
Si Maven n’est pas installé, vous pouvez l’installer en ouvrant le terminal et en exécutant :
sudo apt install maven
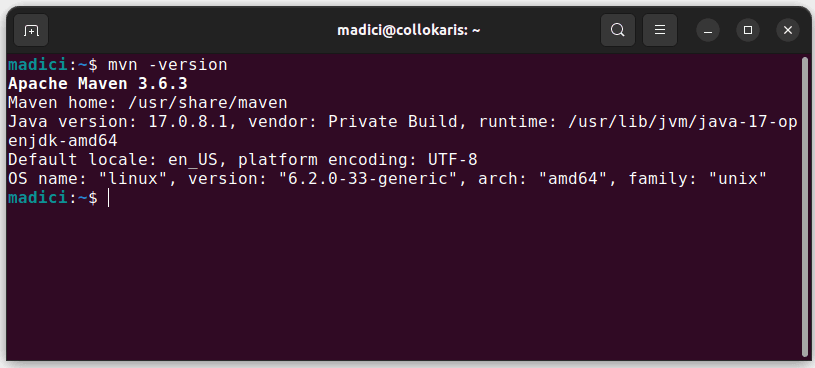
Cela installe Maven à partir du référentiel officiel. Vous pouvez confirmer que Maven a été installé avec succès en exécutant :
mvn -version
Si l’installation a réussi, vous devriez obtenir le résultat suivant :
Configuration de l’environnement
Pour configurer votre environnement :
1. Ouvrez IntelliJ IDEA. Dans la barre de menu de gauche, cliquez sur Projets, puis sélectionnez Nouveau projet.
2. Dans la fenêtre Nouveau projet qui s’ouvre, remplissez-la comme indiqué ci-dessous. Assurez-vous que la langue est définie sur Java et que le système de construction est Maven. Vous pouvez donner au projet le nom de votre choix, puis utiliser Emplacement pour spécifier le dossier dans lequel vous souhaitez créer le projet. Une fois terminé, cliquez sur Créer.
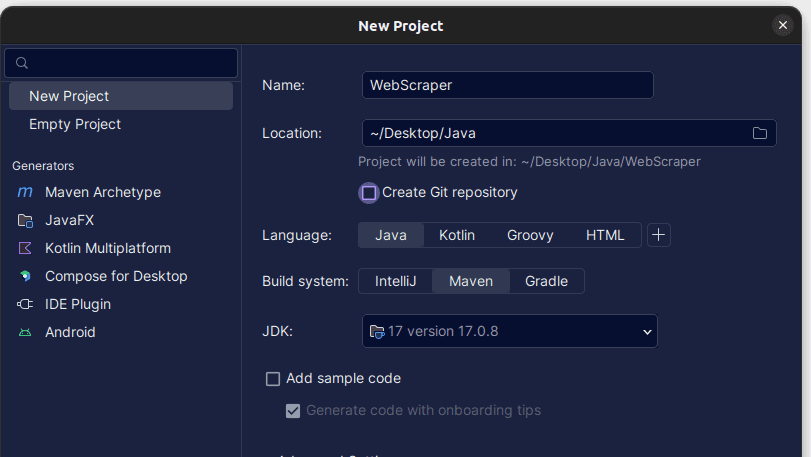
3. Une fois votre projet créé, vous devriez avoir un pom.xml dans votre projet comme indiqué ci-dessous.
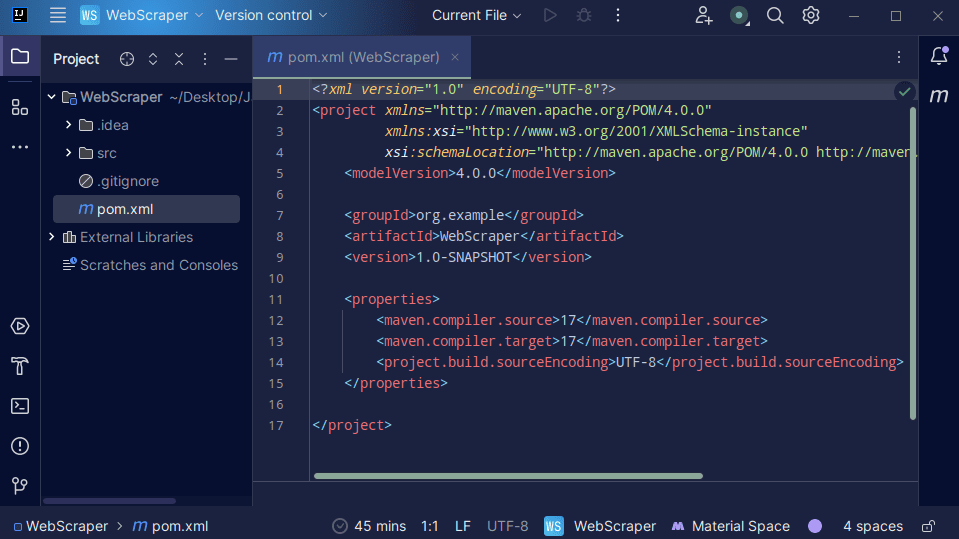
Le fichier pom.xml est créé par Maven et contient des informations sur le projet et les détails de configuration utilisés par Maven pour créer le projet. C’est ce fichier que nous utilisons également pour indiquer que nous utiliserons des bibliothèques externes.
Pour créer un web scraper, nous utiliserons la bibliothèque jsoup. Nous devons donc l’ajouter en tant que dépendance dans le fichier pom.xml afin que Maven puisse le rendre disponible dans notre projet.
4. Ajoutez la dépendance jsoup dans le fichier pom.xml en copiant le code ci-dessous et en l’ajoutant à votre fichier pom.xml
<dependencies>
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.16.1</version>
</dependency>
</dependencies>Le résultat devrait être comme indiqué ci-dessous :
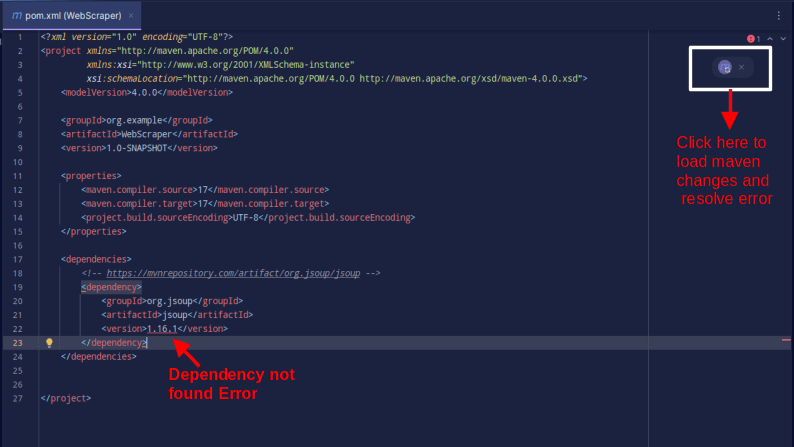
Si vous rencontrez une erreur indiquant que la dépendance est introuvable, cliquez sur l’icône indiquée pour que Maven charge les modifications apportées, charge la dépendance et supprime l’erreur.
Avec cela, votre environnement est entièrement configuré.
Scraping Web avec Java
Pour le web scraping, nous allons récupérer les données de Gratter ce sitequi fournit un bac à sable dans lequel les développeurs peuvent pratiquer le web scraping sans se heurter à des problèmes juridiques.
Pour gratter un site Web en utilisant Java
1. Dans la barre de menu de gauche sur IntelliJ, ouvrez le répertoire src, puis le répertoire principal, qui se trouve à l’intérieur du répertoire src. Le répertoire principal contient un répertoire appelé java ; faites un clic droit dessus et sélectionnez Nouveau, puis Classe Java
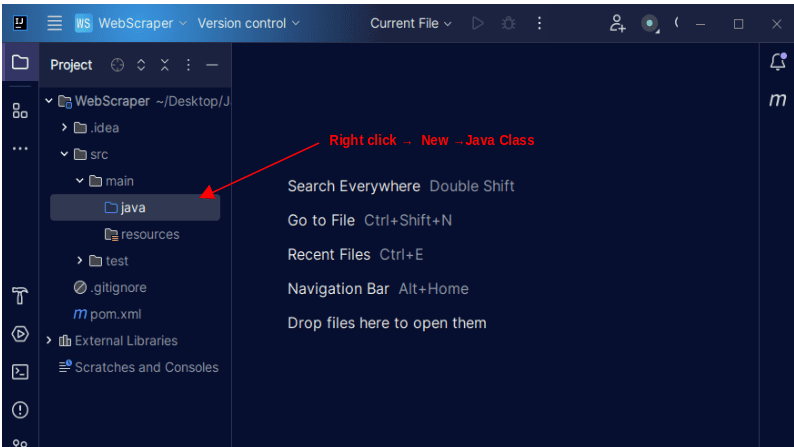
Donnez à la classe le nom de votre choix, par exemple WebScraper, puis appuyez sur Entrée pour créer une nouvelle classe Java.
Ouvrez le fichier nouvellement créé contenant les classes Java que vous venez de créer.
2. Le Web scraping consiste à obtenir des données à partir de sites Web. Par conséquent, nous devons spécifier l’URL à partir de laquelle nous souhaitons extraire les données. Une fois que nous avons spécifié l’URL, nous devons nous connecter à l’URL et faire une requête GET pour récupérer le contenu HTML de la page.
Le code qui fait cela est affiché ci-dessous :
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import java.io.IOException;
public class WebScraper {
public static void main(String[] args) {
String url = "https://www.scrapethissite.com/pages/simple/";
try {
Document doc = Jsoup.connect(url).get();
System.out.println(doc);
} catch (IOException e) {
System.out.println("An IOException occurred. Please try again.");
}
}
}
Sortir:
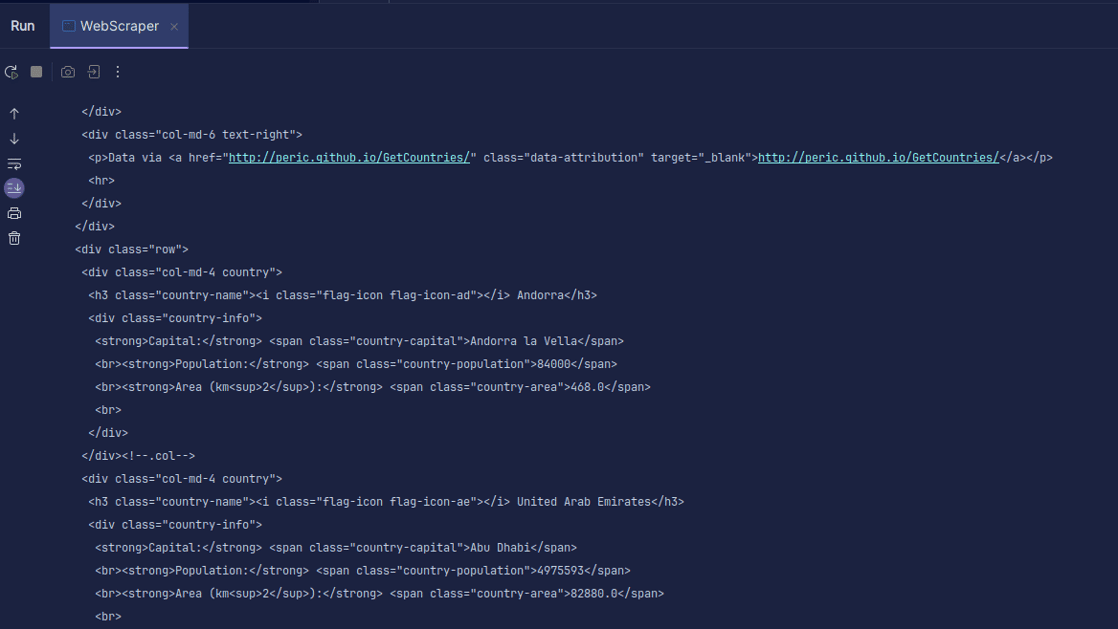
Comme vous pouvez le voir, le code HTML de la page est renvoyé et c’est ce que nous imprimons. Lors du scraping, l’URL que vous spécifiez peut contenir une erreur et la ressource que vous essayez de scraper peut ne pas exister du tout. C’est pourquoi il est important d’envelopper notre code dans une instruction try-catch.
La ligne:
Document doc = Jsoup.connect(url).get();
Est utilisé pour se connecter à l’URL que vous souhaitez récupérer. La méthode get() est utilisée pour effectuer une requête GET et récupérer le HTML sur la page. Le résultat renvoyé est ensuite stocké dans un objet Document JSOUP, nommé doc. Stocker le résultat dans un document JSOUP vous permet d’utiliser l’API JSOUP pour manipuler le code HTML renvoyé.
3. Allez à Gratter ce site et inspectez la page. Dans le HTML, vous devriez voir la structure ci-dessous :
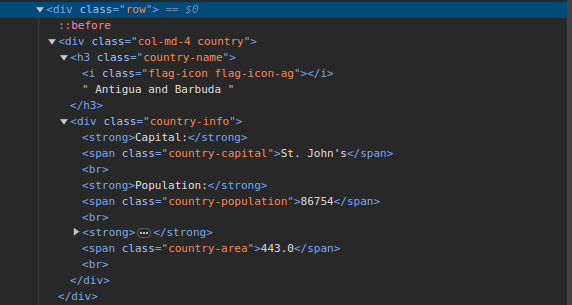
Notez que tous les pays de la page sont stockés sous une structure similaire. Il existe un div avec une classe appelée country avec un élément h3 avec une classe country-name contenant le nom de chaque pays sur la page.
À l’intérieur du div principal, il y a un autre div avec une classe d’informations sur le pays, et il contient des informations telles que la capitale, la population et la superficie du pays. Nous pouvons utiliser ces noms de classe pour sélectionner les éléments HTML et en extraire des informations.
4. Extrayez le contenu spécifique du HTML de la page en utilisant les lignes suivantes :
Elements countries = doc.select(".country");
for (Element country : countries) {
String countryName = country.select(".country-name").text();
String capitalCity = country.select(".country-capital").text();
String population = country.select(".country-population").text();
System.out.println(countryName + " - " + capitalCity + " Population - " + population);
}Nous utilisons la méthode select() pour sélectionner les éléments du HTML de la page qui correspondent au sélecteur CSS spécifique que nous transmettons. Dans notre cas, nous transmettons les noms de classe. En inspectant la page, nous avons vu que toutes les informations sur le pays sur la page sont stockées sous un div avec une classe de pays.
Chaque pays a son propre div avec une classe de pays et le div contient des informations telles que le nom du pays, la capitale et la population.
Par conséquent, nous sélectionnons d’abord tous les pays de la page en utilisant la classe .country. Nous stockons ensuite cela dans une variable appelée country de type Elements, qui fonctionne comme une liste. Nous utilisons ensuite une boucle for pour parcourir les pays, extraire le nom du pays, la capitale et la population et imprimer ce qui est trouvé.
L’intégralité de notre base de code est présentée ci-dessous :
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import org.jsoup.nodes.Element;
import java.io.IOException;
public class WebScraper {
public static void main(String[] args) {
String url = "https://www.scrapethissite.com/pages/simple/";
try {
Document doc = Jsoup.connect(url).get();
Elements countries = doc.select(".country");
for (Element country : countries) {
String countryName = country.select(".country-name").text();
String capitalCity = country.select(".country-capital").text();
String population = country.select(".country-population").text();
System.out.println(countryName + " - " + capitalCity + " - Population - " + population);
}
} catch (IOException e) {
System.out.println("An IOException occurred. Please try again.");
}
}
}
Sortir:
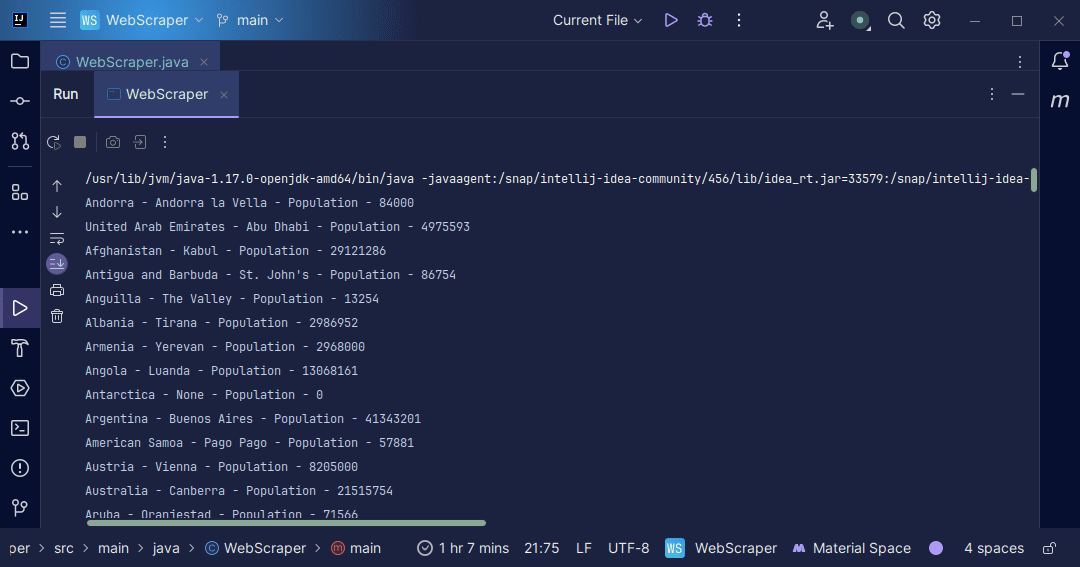
Avec les informations que nous récupérons de la page, nous pouvons faire diverses choses, comme les imprimer comme nous venons de le faire ou les stocker dans un fichier au cas où nous souhaiterions poursuivre le traitement des données.
Conclusion
Le Web scraping est un excellent moyen d’extraire des données non structurées de sites Web, de stocker les données de manière structurée et de traiter les données pour extraire des informations significatives. Cependant, il est important de faire preuve de prudence lors du web scraping, car certains sites Web ne permettent pas le web scraping.
Par mesure de sécurité, utilisez des sites Web proposant des bacs à sable pour vous entraîner à la mise au rebut. Sinon, inspectez toujours le robots.txt de chaque site Web que vous souhaitez supprimer pour savoir si le site Web autorise la suppression.
lors de l’écriture de Web Scrapper, Java est un excellent langage car il fournit des bibliothèques qui rendent le Web Scraping plus facile et plus efficace. En tant que développeur Java, créer un web scraper vous aidera à développer encore plus vos compétences en programmation. Alors allez-y et écrivez votre propre web scrapper ou modifiez celui utilisé dans l’article pour extraire différents types d’informations. Bon codage !
Vous pouvez également explorer certaines solutions populaires de web scraping basées sur le cloud.