Un changement de paradigme dans l’IA et l’apprentissage automatique
L'apprentissage fédéré marque une transition radicale par rapport aux méthodes conventionnelles de collecte de données et d'élaboration de modèles d'apprentissage automatique.
Grâce à l'apprentissage fédéré, le développement du machine learning profite d'une formation moins coûteuse et respectueuse de la confidentialité des informations. Cet article a pour objectif d'exposer ce qu'est précisément l'apprentissage fédéré, comment il opère, ses champs d'application ainsi que les infrastructures techniques existantes.
Qu'est-ce que l'apprentissage fédéré ?
Source: Wikipédia
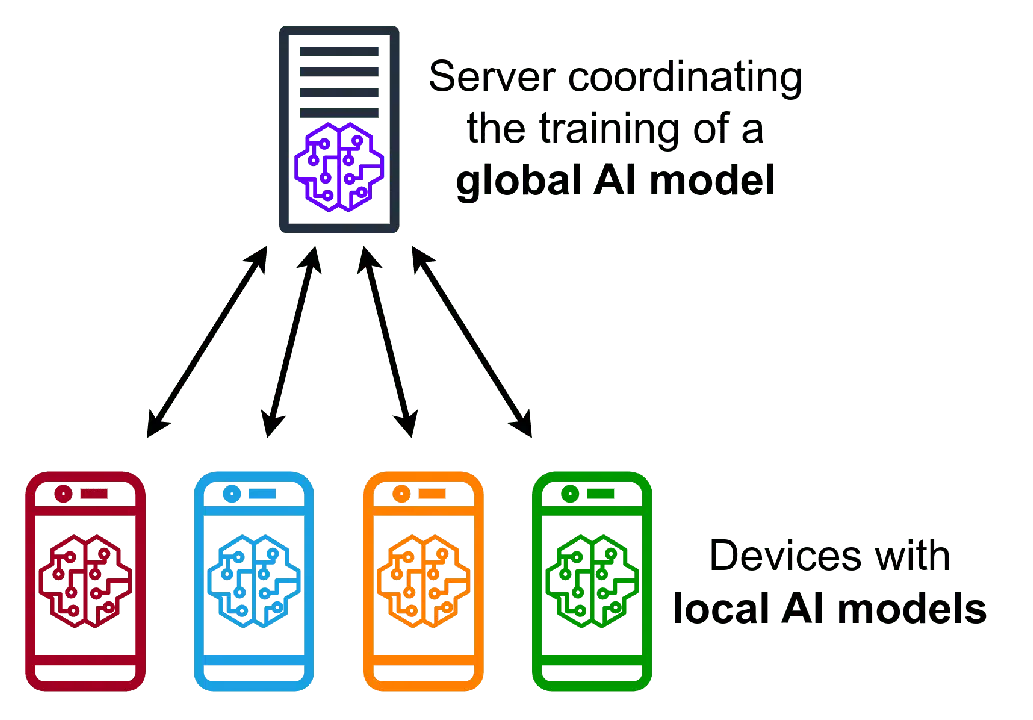
L'apprentissage fédéré représente une innovation dans la manière dont les modèles d'apprentissage automatique sont conçus. Habituellement, dans les modèles d'apprentissage automatique, les données sont rassemblées dans un dépôt central unique, provenant d'une variété de sources. À partir de ce dépôt, les modèles d'apprentissage automatique sont entraînés puis mis en application pour effectuer des prédictions. L'apprentissage fédéré inverse cette démarche. Au lieu de centraliser les données, les clients effectuent l'entraînement du modèle sur leurs propres informations. Cela assure la protection de leurs données privées.
À lire également : Les principaux modèles d'apprentissage automatique expliqués
Comment fonctionne l'apprentissage fédéré ?
L'apprentissage fédéré se compose d'une succession d'étapes séquentielles qui donnent naissance à un modèle. Ces étapes sont désignées par le terme de cycles d'apprentissage. Une configuration d'apprentissage typique parcourt ces cycles, améliorant le modèle à chaque étape. Chaque cycle d'apprentissage englobe les phases suivantes.
Un cycle d'apprentissage typique
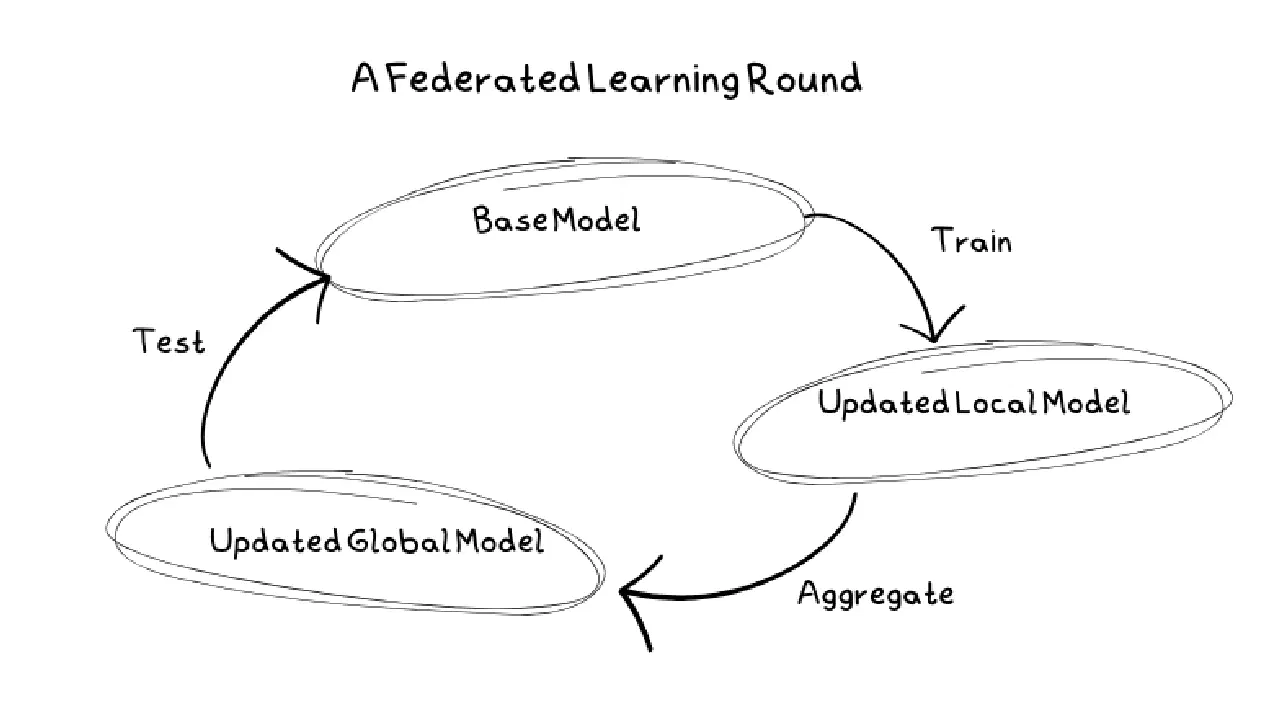
En premier lieu, le serveur sélectionne le modèle à entraîner et les hyperparamètres tels que le nombre de cycles, les nœuds clients à impliquer et la part de nœuds utilisée à chaque étape. Le modèle est également initialisé avec des paramètres de base afin de constituer le modèle initial.
Ensuite, les clients reçoivent une copie du modèle initial à entraîner. Ces clients peuvent être des appareils mobiles, des ordinateurs personnels ou des serveurs. Ils entraînent le modèle avec leurs données locales, évitant ainsi de divulguer des informations sensibles aux serveurs.
Une fois que les clients ont entraîné le modèle sur leurs données locales, ils renvoient leurs mises à jour au serveur. Une fois reçue par le serveur, cette mise à jour est mise en commun avec celles des autres clients pour générer un nouveau modèle de base. Étant donné que les clients ne sont pas toujours fiables, il est possible que certains ne transmettent pas leurs mises à jour. Le serveur est alors en charge de la gestion des erreurs.
Avant de redéployer le modèle de base, il est impératif de le tester. Cependant, le serveur ne conserve pas de données. Il faut donc renvoyer le modèle aux clients afin qu'ils puissent l'évaluer sur leurs données locales. S'il se révèle plus performant que le modèle initial, il est adopté et mis en application.
Voici un guide pratique sur le fonctionnement de l'apprentissage fédéré proposé par l'équipe Federated Learning de Google AI.
Centralisé vs fédéré vs hétérogène
Dans ce modèle, un serveur central est responsable de la supervision de l'apprentissage. Ce type de configuration est désigné sous le nom d'apprentissage fédéré centralisé.
L'antithèse de l'apprentissage centralisé serait l'apprentissage fédéré décentralisé, où les clients communiquent directement entre eux.
Enfin, l'apprentissage hétérogène est un modèle où les clients ne partagent pas nécessairement la même architecture de modèle globale.
Avantages de l'apprentissage fédéré
- L'avantage le plus important de l'apprentissage fédéré est la préservation de la confidentialité des données. Les clients transmettent les résultats de l'entraînement, et non les données elles-mêmes. Des protocoles peuvent également être mis en place afin de regrouper les résultats de manière à ce qu'ils ne soient pas attribuables à un client en particulier.
- Cela réduit également la charge du réseau car il n'y a pas de transfert de données entre le client et le serveur, mais plutôt un échange de modèles.
- De plus, cela diminue le coût des modèles d'entraînement car l'acquisition de matériel de formation coûteux devient inutile. Les développeurs utilisent plutôt les ressources des clients pour entraîner les modèles. Cette approche, nécessitant peu de données, n'impose pas de contrainte importante sur l'appareil du client.
Inconvénients de l'apprentissage fédéré
- Ce modèle repose sur l'implication de nombreux nœuds différents, dont certains échappent au contrôle du développeur. Leur disponibilité n'est donc pas garantie, ce qui peut rendre le matériel d'entraînement peu fiable.
- Les clients sur lesquels les modèles sont entraînés ne sont pas des GPU puissants, mais plutôt des appareils courants comme des téléphones. Ces appareils, même collectivement, pourraient s'avérer moins performants que des clusters de GPU.
- L'apprentissage fédéré suppose que tous les nœuds clients sont fiables et œuvrent pour le bien commun. Cependant, certains pourraient ne pas respecter cette règle et publier des mises à jour erronées, ce qui entraînerait une dérive du modèle.
Applications de l'apprentissage fédéré
L'apprentissage fédéré permet d'apprendre tout en garantissant la confidentialité. Cela trouve son utilité dans de nombreuses situations, par exemple :
- Suggestions de mots suivants sur les claviers des smartphones.
- Appareils IoT capables d'entraîner des modèles localement en fonction des exigences spécifiques du contexte dans lequel ils se trouvent.
- Secteurs pharmaceutiques et de la santé.
- Les industries de la défense pourraient également tirer parti de modèles de formation sans que le partage de données sensibles ne soit nécessaire.
Cadres pour l'apprentissage fédéré
Il existe une multitude de cadres pour mettre en place des modèles d'apprentissage fédéré. Parmi les plus performants, on retrouve NVFlare, FATE, Flower et PySft. Ce guide offre une comparaison détaillée des différents cadres que vous pouvez utiliser.
Conclusion
Cet article constituait une introduction à l'apprentissage fédéré, à son fonctionnement ainsi qu'aux avantages et inconvénients de sa mise en oeuvre. De plus, j'ai abordé les applications et les frameworks courants pour déployer l'apprentissage fédéré en production.
Pour aller plus loin, consultez notre article sur les meilleures plateformes MLOps pour entraîner vos modèles de Machine Learning.