
Les réseaux de neurones convolutifs offrent un moyen plus évolutif pour les tâches de reconnaissance d’objets et de classification d’images.
Il y a beaucoup de progrès qui se produisent dans le monde de la technologie. L’intelligence artificielle et l’apprentissage automatique sont des éléments courants que vous pourriez entendre fréquemment.
Actuellement, ces technologies sont utilisées dans presque tous les domaines, du marketing, du commerce électronique et du développement de logiciels à la banque, la finance et la médecine.
L’IA et le ML sont de vastes domaines, et des efforts sont déployés pour élargir leurs applications afin de résoudre de nombreux problèmes du monde réel. C’est pourquoi vous pourriez voir beaucoup de branches à l’intérieur de ces technologies ; Le ML est un sous-ensemble de l’IA elle-même.
Les réseaux de neurones convolutifs sont l’une des branches de l’IA qui devient populaire de nos jours.
Dans cet article, je vais discuter de ce que sont les CNN, de leur fonctionnement et de leur utilité dans le monde moderne.
Plongeons dedans !
Table des matières
Qu’est-ce qu’un réseau de neurones convolutifs ?
Un réseau de neurones convolutifs (ConvNet ou CNN) est un réseau de neurones artificiels (ANN) qui utilise des algorithmes d’apprentissage en profondeur pour analyser des images, classer des visuels et effectuer des tâches de vision par ordinateur.
CNN exploite les principes de l’algèbre linéaire, tels que la multiplication matricielle, pour détecter des motifs dans une image. Comme ces processus impliquent des calculs complexes, ils nécessitent des unités de traitement graphique (GPU) pour entraîner les modèles.
En termes simples, CNN utilise des algorithmes d’apprentissage en profondeur pour prendre des données d’entrée comme des images et attribuer une importance sous la forme de biais et de poids apprenables à différents aspects de cette image. De cette façon, CNN peut différencier les images ou les classer.
CNN : un bref historique
Puisqu’un réseau de neurones convolutifs est un réseau de neurones artificiels, il est important de réitérer les réseaux de neurones.
En informatique, un réseau de neurones fait partie de l’apprentissage automatique (ML) utilisant des algorithmes d’apprentissage en profondeur. C’est analogue aux schémas de connectivité suivis par les neurones dans le cerveau humain. Les réseaux de neurones artificiels s’inspirent également de l’agencement du cortex visuel.

Ainsi, différents types de réseaux de neurones ou réseaux de neurones artificiels (ANN) sont utilisés à des fins différentes. L’un d’entre eux est CNN utilisé pour la détection et la classification d’images, et plus encore. Il a été introduit par un chercheur postdoctoral, Yann LeCun, dans les années 1980.
La première version de CNN – LeNet, du nom de LeCun, était capable de reconnaître les chiffres manuscrits. Ensuite, il a été utilisé dans les services bancaires et postaux pour lire les chiffres sur les chèques et les codes postaux écrits sur les enveloppes.
Cependant, cette première version manquait de mise à l’échelle; par conséquent, les CNN n’étaient pas beaucoup utilisés dans l’intelligence artificielle et la vision par ordinateur. De plus, cela nécessitait des ressources de calcul et des données importantes pour travailler plus efficacement pour des images plus grandes.
De plus, en 2012, AlexNet a revisité l’apprentissage en profondeur qui utilise des réseaux de neurones composés de plusieurs couches. À cette époque, la technologie s’est améliorée et de grands ensembles de données et de lourdes ressources informatiques étaient disponibles pour permettre la création de CNN complexes capables d’effectuer efficacement des activités de vision par ordinateur.
Couches dans un CNN
Comprenons les différentes couches d’un CNN. L’augmentation des couches dans un CNN augmentera sa complexité et lui permettra de détecter plus d’aspects ou de zones d’une image. À partir d’une fonction simple, il devient capable de détecter des caractéristiques complexes telles que la forme de l’objet et des éléments plus grands jusqu’à ce qu’il puisse enfin détecter l’image.
Couche convolutive
La première couche d’un CNN est la couche convolutive. C’est le bloc de construction principal de CNN où la plupart des calculs ont lieu. Il nécessite moins de composants, tels que des données d’entrée, une carte des fonctionnalités et un filtre.
Un CNN peut également avoir des couches convolutionnelles supplémentaires. Cela rend la structure des CNN hiérarchique puisque les couches suivantes peuvent visualiser les pixels dans les champs récepteurs des couches précédentes. Ensuite, les couches convolutionnelles transforment l’image donnée en valeurs numériques et permettent au réseau de comprendre et d’extraire des modèles précieux.
Mise en commun des couches
Les couches de regroupement sont utilisées pour réduire les dimensions et sont appelées sous-échantillonnage. Il réduit les paramètres utilisés dans l’entrée. L’opération de mise en commun peut déplacer un filtre sur l’entrée complète comme la couche convolutionnelle mais manque de poids. Ici, le filtre applique une fonction conjointe aux valeurs numériques dans le champ récepteur pour remplir le tableau de résultats.
La mutualisation est de deux types :
- Regroupement moyen : La valeur moyenne est calculée dans le champ récepteur que le filer balaie sur l’entrée pour la transmettre au tableau de sortie.
- Max pooling : il choisit le pixel de valeur maximale et l’envoie au tableau de sortie lorsque le filtre balaie l’entrée. La mise en commun maximale est plus utilisée que la mise en commun moyenne.
Bien que des données importantes soient perdues lors de la mise en commun, cela offre toujours de nombreux avantages à CNN. Il aide à réduire les risques de surajustement et la complexité tout en améliorant l’efficacité. Cela améliore également la stabilité de CNN.
Couche entièrement connectée (FC)
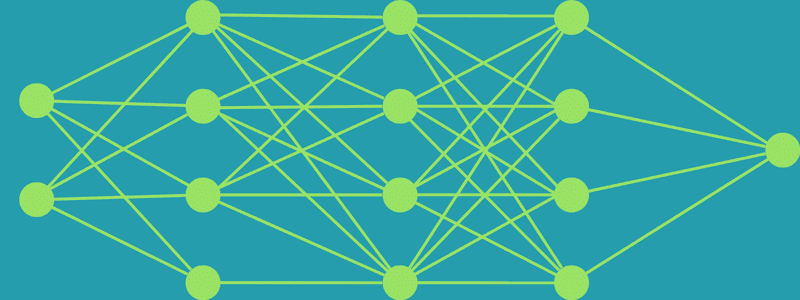
Comme son nom l’indique, tous les nœuds d’une couche de sortie sont directement connectés au nœud de la couche précédente dans une couche entièrement connectée. Il classe une image en fonction des caractéristiques extraites via les couches précédentes avec leurs filtres.
De plus, les couches FC utilisent généralement une fonction d’activation softmax pour classer correctement les entrées au lieu des fonctions ReLu (comme dans le cas des couches de regroupement et de convolution). Cela aide à produire une probabilité de 0 ou 1.
Comment fonctionnent les CNN ?
Un réseau de neurones convolutifs est constitué de plusieurs couches, voire de centaines d’entre elles. Ces couches apprennent à identifier diverses caractéristiques d’une image donnée.
Bien que les CNN soient des réseaux de neurones, leur architecture diffère d’un ANN ordinaire.

Ce dernier place une entrée à travers de nombreuses couches cachées pour la transformer, où chaque couche est créée avec un ensemble de neurones artificiels et est entièrement connectée à chaque neurone de la même couche. Enfin, il y a une couche entièrement connectée ou la couche de sortie pour afficher le résultat.
D’autre part, CNN organise les couches en trois dimensions – largeur, profondeur et hauteur. Ici, une couche du neurone ne se connecte qu’aux neurones d’une petite région au lieu de se rapporter à chacun d’eux dans la couche suivante. Enfin, le résultat final est représenté par un seul vecteur avec un score de probabilité et n’a que la dimension de profondeur.
Maintenant, vous pouvez vous demander ce qu’est la « convolution » dans un CNN.
Eh bien, la convolution fait référence à une opération mathématique pour fusionner deux ensembles de données. Dans CNN, le concept de convolution est appliqué aux données d’entrée pour produire une carte de caractéristiques en filtrant les informations.
Cela nous amène à certains des concepts et terminologies importants utilisés dans les CNN.
- Filtre : Également appelé détecteur de caractéristiques ou noyau, un filtre peut avoir une certaine dimension, telle que 3 × 3. Il parcourt une image d’entrée pour effectuer une multiplication matricielle pour chaque élément afin d’appliquer la convolution. L’application de filtres à chaque image d’entraînement à différentes résolutions ainsi que la sortie de l’image convoluée fonctionneront comme une entrée pour la couche suivante.
- Rembourrage : il est utilisé pour étendre une matrice d’entrée jusqu’aux bordures de la matrice en insérant de faux pixels. C’est fait pour contrer le fait que la convolution réduit la taille de la matrice. Par exemple, une matrice 9×9 peut se transformer en une matrice 3×3 après filtrage.
- Striding : si vous souhaitez obtenir une sortie plus petite que votre entrée, vous pouvez effectuer un striding. Il permet de sauter certaines zones pendant que le filtre glisse sur l’image. En sautant deux ou trois pixels, vous pouvez produire un réseau plus efficace en réduisant la résolution spatiale.
- Poids et biais : les CNN ont des poids et des biais dans leurs neurones. Un modèle peut apprendre ces valeurs pendant l’entraînement, et les valeurs restent les mêmes dans une couche donnée pour tous les neurones. Cela implique que chaque neurone caché détecte les mêmes caractéristiques dans différentes zones d’une image. En conséquence, le réseau devient plus tolérant lors de la traduction des objets en une image donnée.
- ReLU : il signifie Rectified Linear Unit (ReLu) et est utilisé pour un entraînement plus efficace et plus rapide. Il mappe les valeurs négatives sur 0 et conserve les valeurs positives. C’est aussi appelé activation, car le réseau ne transporte que les caractéristiques d’image activées dans la couche suivante.
- Champ récepteur : dans un réseau de neurones, chaque neurone reçoit une entrée provenant de différents emplacements de la couche précédente. Et dans les couches convolutionnelles, chaque neurone reçoit une entrée d’une zone restreinte uniquement de la couche précédente, appelée champ récepteur du neurone. Dans le cas de la couche FC, toute la couche précédente est le champ récepteur.
Dans les tâches de calcul du monde réel, la convolution est généralement effectuée dans une image 3D nécessitant un filtre 3D.
Pour en revenir à CNN, il comprend différentes parties ou couches de nœuds. Chaque couche de nœud a un seuil et un poids et est connectée à une autre. En cas de dépassement de la limite de seuil, les données sont envoyées à la couche suivante de ce réseau.
Ces couches peuvent effectuer des opérations pour modifier les données afin d’apprendre les fonctionnalités pertinentes. De plus, ces opérations répètent des centaines de couches différentes qui continuent d’apprendre à détecter d’autres caractéristiques d’une image.
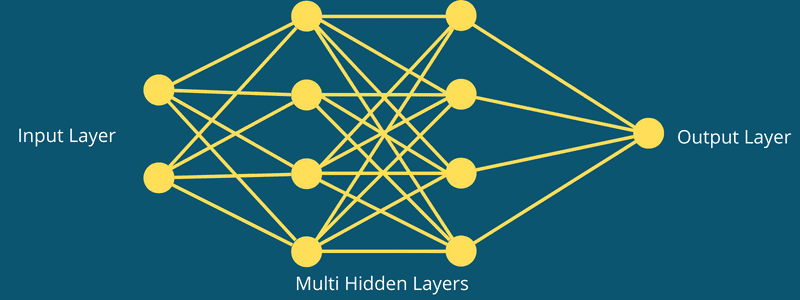
Les parties d’un CNN sont :
- Une couche d’entrée : c’est là que l’entrée est prise, comme une image. Ce sera un objet 3D avec une hauteur, une largeur et une profondeur définies.
- Une/plusieurs couches cachées ou phase d’extraction de caractéristiques : ces couches peuvent être une couche convolutive, une couche de regroupement et une couche entièrement connectée.
- Une couche de sortie : Ici, le résultat sera affiché.
Le passage de l’image à travers la couche de convolution est transformé en une carte de caractéristiques ou une carte d’activation. Après avoir convolué l’entrée, les calques convoluent l’image et transmettent le résultat au calque suivant.
Le CNN effectuera de nombreuses convolutions et techniques de mise en commun pour détecter les caractéristiques pendant la phase d’extraction des caractéristiques. Par exemple, si vous entrez l’image d’un chat, le CNN reconnaîtra ses quatre pattes, sa couleur, ses deux yeux, etc.
Ensuite, des couches entièrement connectées dans un CNN agiront comme un classificateur sur les caractéristiques extraites. Sur la base de ce que l’algorithme d’apprentissage en profondeur a prédit à propos de l’image, les couches donneraient le résultat.
Avantages des CNN

Précision supérieure
Les CNN offrent une plus grande précision que les réseaux de neurones classiques qui n’utilisent pas la convolution. Les CNN sont utiles, en particulier lorsque la tâche implique de nombreuses données, la reconnaissance de vidéos et d’images, etc. Ils produisent des résultats et des prédictions très précis ; par conséquent, leur utilisation augmente dans différents secteurs.
Efficacité de calcul

Les CNN offrent un niveau d’efficacité de calcul supérieur à celui des autres réseaux de neurones classiques. Cela est dû à l’utilisation du processus de convolution. Ils utilisent également la réduction de dimensionnalité et le partage de paramètres pour rendre les modèles plus rapides et plus faciles à déployer. Ces techniques peuvent également être optimisées pour fonctionner sur différents appareils, que ce soit votre smartphone ou votre ordinateur portable.
Extraction de caractéristiques
CNN peut facilement apprendre les caractéristiques d’une image sans nécessiter d’ingénierie manuelle. Vous pouvez tirer parti des CNN pré-formés et gérer les pondérations en leur fournissant des données lorsque vous travaillez sur une nouvelle tâche, et le CNN s’y adaptera de manière transparente.
Applications de CNN
Les CNN sont utilisés dans différentes industries pour de nombreux cas d’utilisation. Certaines des applications réelles des CNN incluent :
Classification des images
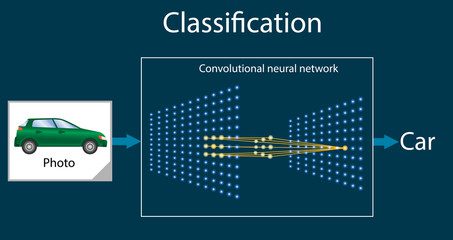
Les CNN sont largement utilisés dans la classification des images. Ceux-ci peuvent reconnaître des caractéristiques précieuses et identifier des objets dans une image donnée. Par conséquent, il est utilisé dans des secteurs comme la santé, en particulier les IRM. De plus, cette technologie est utilisée dans la reconnaissance des chiffres manuscrits, qui est l’un des premiers cas d’utilisation des CNN en vision par ordinateur.
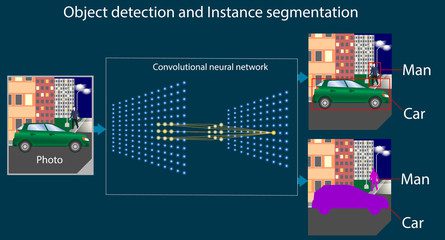
Détection d’objet
CNN peut détecter des objets dans des images en temps réel et également les étiqueter et les classer. Par conséquent, cette technique est largement utilisée dans les véhicules automatisés. Il permet également aux maisons intelligentes et aux piétons de reconnaître le visage du propriétaire du véhicule. Il est également utilisé dans les systèmes de surveillance alimentés par l’IA pour détecter et marquer des objets.
Correspondance audiovisuelle
L’aide de CNN dans l’appariement audiovisuel permet d’améliorer les plateformes de streaming vidéo telles que Netflix, YouTube, etc. Elle permet également de répondre aux demandes des utilisateurs telles que « les chansons d’amour d’Elton John ».
Reconnaissance de la parole

Outre les images, les CNN sont utiles pour le traitement du langage naturel (TAL) et la reconnaissance vocale. Un exemple concret de cela pourrait être Google utilisant des CNN dans son système de reconnaissance vocale.
Reconstruction d’objets
Les CNN peuvent être utilisés dans la modélisation 3D d’un objet réel dans un environnement numérique. Il est également possible pour les modèles CNN de créer un modèle de visage 3D à l’aide d’une image. De plus, CNN est utile pour construire des jumeaux numériques dans les domaines de la biotechnologie, de la fabrication, de la biotechnologie et de l’architecture.
L’utilisation de CNN dans différents secteurs comprend :
- Soins de santé : la vision par ordinateur peut être utilisée en radiologie pour aider les médecins à détecter les tumeurs cancéreuses avec une meilleure efficacité chez une personne.
- Agriculture : Les réseaux peuvent utiliser des images de satellites artificiels tels que LSAT et exploiter ces données pour classer les terres fertiles. Cela permet également de prévoir les niveaux de fertilité des terres et de développer une stratégie efficace pour maximiser le rendement.
- Marketing : les applications de médias sociaux peuvent suggérer une personne dans une photo publiée sur le profil de quelqu’un. Cela vous aide à taguer des personnes dans vos albums photo.
- Commerce de détail : les plates-formes de commerce électronique peuvent utiliser la recherche visuelle pour aider les marques à recommander des articles pertinents que les clients cibles souhaitent acheter.
- Automobile : CNN trouve une utilisation dans les automobiles pour améliorer la sécurité des passagers et des conducteurs. Il le fait à l’aide de fonctionnalités telles que la détection de lignes de voie, la détection d’objets, la classification d’images, etc. Cela aide également le monde des voitures autonomes à évoluer davantage.
Ressources pour apprendre les CNN
Cours :
Coursera propose ce cours sur CNN que vous pouvez envisager de suivre. Ce cours vous apprendra comment la vision par ordinateur a évolué au fil des ans et certaines applications des CNN dans le monde moderne.
Amazone:
Vous pouvez lire ces livres et conférences pour en savoir plus sur CNN :
- Réseaux de neurones et apprentissage en profondeur : il couvre les modèles, les algorithmes et la théorie de l’apprentissage en profondeur et des réseaux de neurones.
- A Guide to Convolutional Neural Networks for Computer Vision: Ce livre vous apprendra les applications des CNN et leurs concepts.
- Réseaux de neurones convolutifs pratiques avec Tensorflow : vous pouvez résoudre divers problèmes de vision par ordinateur en utilisant Python et TensorFlow à l’aide de ce livre.
- Advanced Applied Deep Learning : Ce livre vous aidera à comprendre les CNN, l’apprentissage en profondeur et leurs applications avancées, y compris la détection d’objets.
- Réseaux de neurones convolutifs et réseaux de neurones récurrents : ce livre vous apprendra sur les CNN et les RNN et sur la manière de créer ces réseaux.
Conclusion
Les réseaux de neurones convolutifs sont l’un des domaines émergents de l’intelligence artificielle, de l’apprentissage automatique et de l’apprentissage en profondeur. Il a diverses applications dans le monde actuel dans presque tous les secteurs. Compte tenu de son utilisation croissante, on s’attend à ce qu’il se développe davantage et soit plus utile pour résoudre les problèmes du monde réel.