
Eh bien, les statistiques de Forbes indiquent que jusqu’à 90% des organisations mondiales utilisent l’analyse de Big Data pour créer leurs rapports d’investissement.
Avec la popularité croissante du Big Data, il y a par conséquent une augmentation des opportunités d’emploi Hadoop plus qu’auparavant.
Par conséquent, pour vous aider à obtenir ce rôle d’expert Hadoop, vous pouvez utiliser ces questions et réponses d’entretien que nous avons rassemblées pour vous dans cet article pour vous aider à passer votre entretien.
Peut-être que connaître les faits comme l’échelle salariale qui rendent les rôles Hadoop et Big Data lucratifs vous motivera à passer cet entretien, n’est-ce pas ? 🤔
- Selon Indeed.com, un développeur Big Data Hadoop basé aux États-Unis gagne un salaire moyen de 144 000 $.
- Selon itjobswatch.co.uk, le salaire moyen d’un développeur Big Data Hadoop est de 66 750 £.
- En Inde, la source Indeed.com déclare qu’ils gagneraient un salaire moyen de 16 000 000 ₹.
Lucratif, vous ne pensez pas ? Passons maintenant à la découverte de Hadoop.
Table des matières
Qu’est-ce qu’Hadoop ?
Hadoop est un framework populaire écrit en Java qui utilise des modèles de programmation pour traiter, stocker et analyser de grands ensembles de données.
Par défaut, sa conception permet de passer d’un serveur unique à plusieurs machines offrant un calcul et un stockage locaux. De plus, sa capacité à détecter et à gérer les défaillances de la couche application entraînant des services hautement disponibles rend Hadoop assez fiable.
Passons directement aux questions d’entretien Hadoop fréquemment posées et à leurs réponses correctes.
Questions et réponses de l’entretien d’Hadoop
Qu’est-ce que l’unité de stockage dans Hadoop ?
Réponse : L’unité de stockage de Hadoop s’appelle Hadoop Distributed File System (HDFS).
En quoi le stockage en réseau est-il différent du système de fichiers distribué Hadoop ?
Réponse : HDFS, qui est le stockage principal de Hadoop, est un système de fichiers distribué qui stocke des fichiers volumineux à l’aide de matériel standard. D’autre part, le NAS est un serveur de stockage de données informatiques au niveau des fichiers qui permet à des groupes de clients hétérogènes d’accéder aux données.
Alors que le stockage des données dans le NAS se fait sur du matériel dédié, HDFS distribue les blocs de données sur toutes les machines du cluster Hadoop.
Le NAS utilise des périphériques de stockage haut de gamme, ce qui est plutôt coûteux, tandis que le matériel de base utilisé dans HDFS est rentable.
Le NAS stocke séparément les données des calculs, ce qui le rend inadapté à MapReduce. Au contraire, la conception de HDFS lui permet de fonctionner avec le framework MapReduce. Les calculs se déplacent vers les données dans le framework MapReduce au lieu des données vers les calculs.
Expliquer MapReduce dans Hadoop et Shuffling
Réponse : MapReduce fait référence à deux tâches distinctes que les programmes Hadoop effectuent pour permettre une grande évolutivité sur des centaines à des milliers de serveurs au sein d’un cluster Hadoop. Le shuffling, d’autre part, transfère la sortie de la carte des mappeurs vers le réducteur nécessaire dans MapReduce.
Donner un aperçu de l’architecture Apache Pig
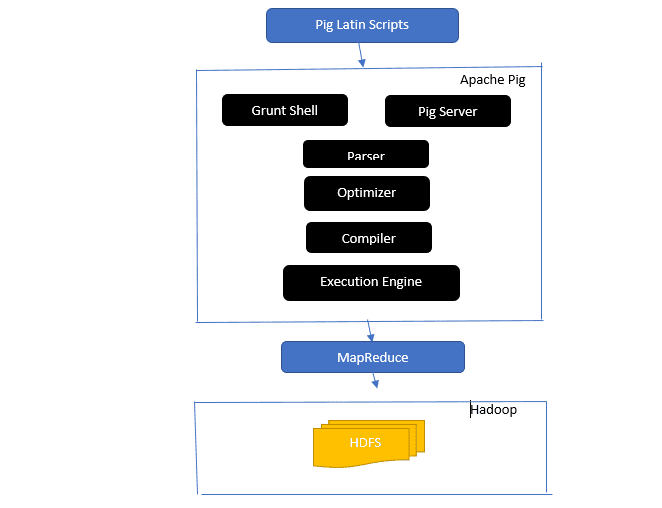 L’architecture du cochon apache
L’architecture du cochon apache
Réponse : L’architecture Apache Pig dispose d’un interpréteur Pig Latin qui traite et analyse de grands ensembles de données à l’aide de scripts Pig Latin.
Apache pig se compose également d’ensembles d’ensembles de données sur lesquels des opérations de données telles que joindre, charger, filtrer, trier et regrouper sont effectuées.
Le langage Pig Latin utilise des mécanismes d’exécution tels que les shells Grant, les UDF et intégrés pour écrire des scripts Pig qui exécutent les tâches requises.
Pig facilite le travail des programmeurs en convertissant ces scripts écrits en séries de travaux Map-Reduce.
Les composants de l’architecture Apache Pig incluent :
- Analyseur – Il gère les scripts Pig en vérifiant la syntaxe du script et en effectuant une vérification de type. La sortie de l’analyseur représente les instructions et les opérateurs logiques de Pig Latin et est appelée DAG (graphe acyclique dirigé).
- Optimiseur – L’optimiseur implémente des optimisations logiques telles que la projection et le refoulement sur le DAG.
- Compilateur – Compile le plan logique optimisé à partir de l’optimiseur en une série de tâches MapReduce.
- Moteur d’exécution – C’est là que se produit l’exécution finale des tâches MapReduce dans la sortie souhaitée.
- Mode d’exécution – Les modes d’exécution dans Apache pig incluent principalement local et Map Reduce.
Réponse : Le service Metastore dans Local Metastore s’exécute dans la même JVM que Hive, mais se connecte à une base de données s’exécutant dans un processus distinct sur la même machine ou sur une machine distante. D’autre part, Metastore dans le métastore distant s’exécute dans sa JVM distincte de la JVM du service Hive.
Quels sont les Cinq V du Big Data ?
Réponse : Ces cinq V représentent les principales caractéristiques du Big Data. Ils comprennent:
- Valeur : Le Big Data cherche à fournir des avantages significatifs d’un retour sur investissement (ROI) élevé à une organisation qui utilise le Big Data dans ses opérations de données. Le Big Data apporte cette valeur grâce à sa découverte d’informations et à sa reconnaissance de modèles, ce qui se traduit par des relations clients plus solides et des opérations plus efficaces, entre autres avantages.
- Variété : Cela représente l’hétérogénéité du type de types de données recueillies. Les différents formats incluent CSV, vidéos, audio, etc.
- Volume : définit la quantité et la taille importantes des données gérées et analysées par une organisation. Ces données représentent une croissance exponentielle.
- Vélocité : il s’agit du taux de vitesse exponentiel pour la croissance des données.
- Véracité : la véracité fait référence à la façon dont les données disponibles sont « incertaines » ou « inexactes » parce que les données sont incomplètes ou incohérentes.
Expliquer les différents types de données de Pig Latin.
Réponse : Les types de données dans Pig Latin incluent des types de données atomiques et des types de données complexes.
Les types de données atomiques sont les types de données de base utilisés dans toutes les autres langues. Ils comprennent les éléments suivants :
- Int – Ce type de données définit un entier 32 bits signé. Exemple : 13
- Long – Long définit un entier 64 bits. Exemple : 10L
- Float – Définit une virgule flottante 32 bits signée. Exemple : 2,5 F
- Double – Définit une virgule flottante 64 bits signée. Exemple : 23,4
- Booléen – Définit une valeur booléenne. Il comprend : Vrai/Faux
- Datetime – Définit une valeur date-heure. Exemple : 1980-01-01T00:00.00.000+00:00
Les types de données complexes incluent :
- Map-Map fait référence à un ensemble de paires clé-valeur. Exemple: [‘color’#’yellow’, ‘number’#3]
- Bag – C’est une collection d’un ensemble de tuples, et il utilise le symbole ‘{}’. Exemple : {(Henry, 32), (Kiti, 47)}
- Tuple – Un tuple définit un ensemble ordonné de champs. Exemple : (Age, 33)
Que sont Apache Oozie et Apache ZooKeeper ?
Réponse : Apache Oozie est un planificateur Hadoop chargé de planifier et de lier les tâches Hadoop en une seule tâche logique.
Apache Zookeeper, d’autre part, se coordonne avec divers services dans un environnement distribué. Il fait gagner du temps aux développeurs en exposant simplement des services simples tels que la synchronisation, le regroupement, la maintenance de la configuration et la dénomination. Apache Zookeeper fournit également une prise en charge prête à l’emploi pour la mise en file d’attente et l’élection du chef.
Quel est le rôle du Combiner, du RecordReader et du Partitioner dans une opération MapReduce ?
Réponse : Le combinateur agit comme un mini réducteur. Il reçoit et travaille sur les données des tâches cartographiques, puis transmet la sortie des données à la phase de réduction.
Le RecordHeader communique avec le InputSplit et convertit les données en paires clé-valeur pour que le mappeur les lise correctement.
Le partitionneur est chargé de décider du nombre de tâches réduites nécessaires pour résumer les données et de confirmer comment les sorties du combineur sont envoyées au réducteur. Le partitionneur contrôle également le partitionnement des clés des sorties de carte intermédiaires.
Mentionnez les différentes distributions spécifiques au fournisseur de Hadoop.
Réponse : Les différents fournisseurs qui étendent les fonctionnalités de Hadoop incluent :
- Plate-forme ouverte IBM.
- Distribution Cloudera CDH Hadoop
- Distribution MapR Hadoop
- Amazon Elastic MapRéduire
- Plate-forme de données Hortonworks (HDP)
- Suite pivot de données volumineuses
- Analyse d’entreprise Datastax
- HDInsight de Microsoft Azure – Distribution Hadoop basée sur le cloud.
Pourquoi HDFS est-il tolérant aux pannes ?
Réponse : HDFS réplique les données sur différents DataNodes, ce qui le rend tolérant aux pannes. Le stockage des données dans différents nœuds permet de les récupérer à partir d’autres nœuds lorsqu’un mode tombe en panne.
Différencier une fédération et une haute disponibilité.
Réponse : La fédération HDFS offre une tolérance aux pannes qui permet un flux de données continu dans un nœud lorsqu’un autre tombe en panne. D’autre part, la haute disponibilité nécessitera deux machines distinctes configurant séparément le NameNode actif et le NameNode secondaire sur les première et deuxième machines.
La fédération peut avoir un nombre illimité de NameNodes non liés, tandis qu’en haute disponibilité, seuls deux NameNodes liés, actif et en veille, qui fonctionnent en continu, sont disponibles.
Les NameNodes de la fédération partagent un pool de métadonnées, chaque NameNode ayant son pool dédié. En haute disponibilité, cependant, les NameNodes actifs s’exécutent chacun à la fois tandis que les NameNodes de secours restent inactifs et ne mettent à jour leurs métadonnées qu’occasionnellement.
Comment trouver l’état des blocs et la santé du système de fichiers ?
Réponse : Vous utilisez la commande hdfs fsck / au niveau de l’utilisateur racine et dans un répertoire individuel pour vérifier l’état de santé du système de fichiers HDFS.
Commande fsck HDFS en cours d’utilisation :
hdfs fsck / -files --blocks –locations> dfs-fsck.log
Description de la commande :
- -files : imprime les fichiers que vous vérifiez.
- –locations : imprime les emplacements de tous les blocs lors de la vérification.
Commande pour vérifier l’état des blocs :
hdfs fsck <path> -files -blocks
: commence les vérifications à partir du chemin transmis ici. - – blocks : Il imprime les blocs du fichier lors de la vérification
Quand utilisez-vous les commandes rmadmin-refreshNodes et dfsadmin-refreshNodes ?
Réponse : Ces deux commandes sont utiles pour actualiser les informations sur le nœud, soit pendant la mise en service, soit lorsque la mise en service du nœud est terminée.
La commande dfsadmin-refreshNodes exécute le client HDFS et actualise la configuration du nœud du NameNode. La commande rmadmin-refreshNodes, d’autre part, exécute les tâches administratives du ResourceManager.
Qu’est-ce qu’un point de contrôle ?
Réponse : Checkpoint est une opération qui fusionne les dernières modifications du système de fichiers avec la FSImage la plus récente afin que les fichiers journaux d’édition restent suffisamment petits pour accélérer le processus de démarrage d’un NameNode. Le point de contrôle se produit dans le NameNode secondaire.
Pourquoi utilisons-nous HDFS pour les applications ayant de grands ensembles de données ?
Réponse : HDFS fournit une architecture DataNode et NameNode qui implémente un système de fichiers distribué.
Ces deux architectures offrent un accès hautes performances aux données sur des clusters hautement évolutifs de Hadoop. Son NameNode stocke les métadonnées du système de fichiers dans la RAM, ce qui entraîne une quantité de mémoire limitant le nombre de fichiers du système de fichiers HDFS.
Que fait la commande ‘jps’ ?
Réponse : La commande Java Virtual Machine Process Status (JPS) vérifie si des démons Hadoop spécifiques, notamment NodeManager, DataNode, NameNode et ResourceManager, sont en cours d’exécution ou non. Cette commande doit être exécutée à partir de la racine pour vérifier les nœuds d’exploitation dans l’hôte.
Qu’est-ce que l’« exécution spéculative » dans Hadoop ?
Réponse : Il s’agit d’un processus dans lequel le nœud maître dans Hadoop, au lieu de réparer les tâches lentes détectées, lance une instance différente de la même tâche en tant que tâche de sauvegarde (tâche spéculative) sur un autre nœud. L’exécution spéculative permet de gagner beaucoup de temps, en particulier dans un environnement de charge de travail intensive.
Nommez les trois modes dans lesquels Hadoop peut fonctionner.
Réponse : Les trois nœuds principaux sur lesquels Hadoop s’exécute incluent :
- Le nœud autonome est le mode par défaut qui exécute les services Hadoop à l’aide du système de fichiers local et d’un seul processus Java.
- Le nœud pseudo-distribué exécute tous les services Hadoop à l’aide d’un seul déploiement Hadoop ode.
- Le nœud entièrement distribué exécute les services maître et esclave Hadoop à l’aide de nœuds distincts.
Qu’est-ce qu’un FDU ?
Réponse : UDF (fonctions définies par l’utilisateur) vous permet de coder vos fonctions personnalisées que vous pouvez utiliser pour traiter les valeurs des colonnes lors d’une requête Impala.
Qu’est-ce que DistCp ?
Réponse : DistCp ou Distributed Copy, en bref, est un outil utile pour la copie de données inter ou intra-cluster à grande échelle. À l’aide de MapReduce, DistCp implémente efficacement la copie distribuée d’une grande quantité de données, entre autres tâches telles que la gestion des erreurs, la récupération et la création de rapports.
Réponse : Hive metastore est un service qui stocke les métadonnées Apache Hive pour les tables Hive dans une base de données relationnelle telle que MySQL. Il fournit l’API de service metastore qui permet à cent d’accéder aux métadonnées.
Définir RDD.
Réponse : RDD, qui signifie Resilient Distributed Datasets, est la structure de données de Spark et une collection distribuée immuable de vos éléments de données qui calcule sur les différents nœuds du cluster.
Comment les bibliothèques natives peuvent-elles être incluses dans les tâches YARN ?
Réponse : Vous pouvez implémenter cela en utilisant -Djava.library. path sur la commande ou en définissant LD+LIBRARY_PATH dans le fichier .bashrc en utilisant le format suivant :
<property> <name>mapreduce.map.env</name> <value>LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/path/to/my/libs</value> </property>
Expliquez ‘WAL’ dans HBase.
Réponse : Le Write Ahead Log (WAL) est un protocole de récupération qui enregistre les modifications de données MemStore dans HBase vers le stockage basé sur des fichiers. WAL récupère ces données si le RegionalServer plante ou avant de vider le MemStore.
YARN remplace-t-il Hadoop MapReduce ?
Réponse : Non, YARN ne remplace pas Hadoop MapReduce. Au lieu de cela, une technologie puissante appelée Hadoop 2.0 ou MapReduce 2 prend en charge MapReduce.
Quelle est la différence entre ORDER BY et SORT BY dans HIVE ?
Réponse : Bien que les deux commandes récupèrent les données de manière triée dans Hive, les résultats de l’utilisation de SORT BY peuvent n’être que partiellement triés.
De plus, SORT BY nécessite un réducteur pour trier les lignes. Ces réducteurs nécessaires à la sortie finale peuvent également être multiples. Dans ce cas, la sortie finale peut être partiellement commandée.
D’autre part, ORDER BY ne nécessite qu’un seul réducteur pour un ordre total en sortie. Vous pouvez également utiliser le mot-clé LIMIT qui réduit le temps de tri total.
Quelle est la différence entre Spark et Hadoop ?
Réponse : bien que Hadoop et Spark soient tous deux des infrastructures de traitement distribuées, leur principale différence réside dans leur traitement. Là où Hadoop est efficace pour le traitement par lots, Spark est efficace pour le traitement des données en temps réel.
De plus, Hadoop lit et écrit principalement des fichiers sur HDFS, tandis que Spark utilise le concept Resilient Distributed Dataset pour traiter les données dans la RAM.
Sur la base de leur latence, Hadoop est un framework informatique à latence élevée sans mode interactif pour traiter les données, tandis que Spark est un framework informatique à faible latence qui traite les données de manière interactive.
Comparez Sqoop et Flume.
Réponse : Sqoop et Flume sont des outils Hadoop qui collectent des données collectées à partir de diverses sources et chargent les données dans HDFS.
- Sqoop (SQL-to-Hadoop) extrait des données structurées à partir de bases de données, notamment Teradata, MySQL, Oracle, etc., tandis que Flume est utile pour extraire des données non structurées à partir de sources de bases de données et les charger dans HDFS.
- En termes d’événements pilotés, Flume est piloté par les événements, tandis que Sqoop n’est pas piloté par les événements.
- Sqoop utilise une architecture basée sur des connecteurs où les connecteurs savent comment se connecter à une autre source de données. Flume utilise une architecture à base d’agents, le code écrit étant l’agent chargé de récupérer les données.
- En raison de la nature distribuée de Flume, il peut facilement collecter et agréger des données. Sqoop est utile pour le transfert de données parallèle, ce qui entraîne la sortie dans plusieurs fichiers.
Expliquez le BloomMapFile.
Réponse : BloomMapFile est une classe étendant la classe MapFile et utilise des filtres Bloom dynamiques qui fournissent un test d’appartenance rapide pour les clés.
Énumérez la différence entre HiveQL et PigLatin.
Réponse : Alors que HiveQL est un langage déclaratif similaire à SQL, PigLatin est un langage de flux de données procédural de haut niveau.
Qu’est-ce que le nettoyage des données ?
Réponse : Le nettoyage des données est un processus crucial pour éliminer ou corriger les erreurs de données identifiées, notamment des données incorrectes, incomplètes, corrompues, dupliquées et mal formatées dans un ensemble de données.
Ce processus vise à améliorer la qualité des données et à fournir des informations plus précises, cohérentes et fiables nécessaires à une prise de décision efficace au sein d’une organisation.
Conclusion💃
Avec l’augmentation actuelle des opportunités d’emploi dans le Big Data et Hadoop, vous voudrez peut-être améliorer vos chances d’y entrer. Les questions et réponses de l’entretien Hadoop de cet article vous aideront à réussir cet entretien à venir.
Ensuite, vous pouvez consulter de bonnes ressources pour apprendre le Big Data et Hadoop.
Bonne chance! 👍