L'ingestion de données expliquée dans les termes les plus simples
L'intégration de données constitue un pilier essentiel de tout processus axé sur la donnée. Elle assure que les organisations accèdent aux informations adéquates au moment opportun pour évaluer et optimiser leurs performances commerciales.
Les entreprises contemporaines génèrent des volumes considérables de données quotidiennement, lesquelles s'avèrent d'une importance capitale pour leurs activités.
L'analyse de ces données permet aux organisations d'acquérir des connaissances approfondies, facilitant ainsi la prise de décisions éclairées et basées sur des faits concrets.
Ces informations jouent un rôle majeur dans la compréhension des clients, la prévision des tendances du marché, la planification stratégique et l'anticipation des évolutions futures, apportant ainsi de multiples avantages.
Toutefois, pour mener à bien certaines tâches, il est indispensable d'extraire et d'analyser ces données, en y accédant facilement depuis un point centralisé.
C'est précisément là qu'intervient l'intégration de données.
Cette approche consiste à extraire des données de diverses sources, permettant ainsi de déceler des informations cachées et de les exploiter pour dynamiser votre entreprise.
Dans cet article, nous allons explorer l'intégration de données, ses différentes formes, le déroulement étape par étape, son architecture, ses applications, ses avantages, les pratiques recommandées et les défis associés.
Commençons notre exploration!
Qu'est-ce que l'intégration de données ?
L'intégration de données est le processus qui consiste à recueillir des informations provenant d'une ou plusieurs sources pour les importer dans un entrepôt de données, en vue d'une utilisation immédiate. Il s'agit d'une des phases cruciales du flux de travail d'analyse des données.
Les données peuvent être intégrées par lots ou diffusées en temps réel. Une fois transférées vers leur emplacement cible, elles sont stockées de manière appropriée, puis exploitées à des fins d'analyse.
Les sources de données peuvent être des lacs de données, des bases de données, des appareils IoT, des applications SaaS, des bases de données sur site et d'autres plateformes pouvant héberger des informations pertinentes et essentielles.
L'intégration de données est un processus simple qui consiste à extraire des données de leur source, à les nettoyer et à les acheminer vers une destination où une entreprise peut utiliser, consulter et analyser ces informations.
L'intégration de données permet aux organisations de prendre des décisions éclairées, en réponse à la complexité et au volume croissant des informations qu'elles produisent au quotidien.
Lorsqu'une organisation recueille des données, celles-ci conservent leur état brut et original, tel qu'elles existaient dans leur source. Une opération de transformation est nécessaire lorsqu'il s'agit de mettre en forme les données ou de les analyser sous un format lisible et compatible avec diverses applications.
L'objectif principal de l'intégration de données est de déplacer efficacement de grands ensembles d'informations d'un emplacement à un autre, en utilisant l'automatisation logicielle. Ce processus se limite à l'intégration des données, sans transformation. Pour de nombreuses organisations, c'est un outil essentiel pour gérer leur interface de données.
Il existe plusieurs méthodes pour intégrer des données dans votre data mart. En fonction de vos besoins spécifiques et de vos exigences en matière de conception, vous pouvez choisir la méthode d'intégration la plus appropriée.
Comment fonctionne l'intégration de données ?
L'intégration de données consiste à collecter des informations provenant de diverses sources où elles ont été initialement stockées ou produites. Elle procède ensuite au chargement ou au transfert de ces données vers la destination ou la zone de transit. Le pipeline d'intégration de données applique des transformations légères pour filtrer ou optimiser les données, avant de les envoyer vers une file d'attente de messages, un entrepôt de données ou une destination.
L'intégration de données peut également exécuter des transformations complexes, telles que le tri, les jointures et les agrégations, pour des applications spécifiques, des systèmes de reporting et d'analyse, en utilisant des pipelines additionnels.
Pour appréhender le processus étape par étape de l'intégration de données, il est nécessaire d'étudier son architecture.
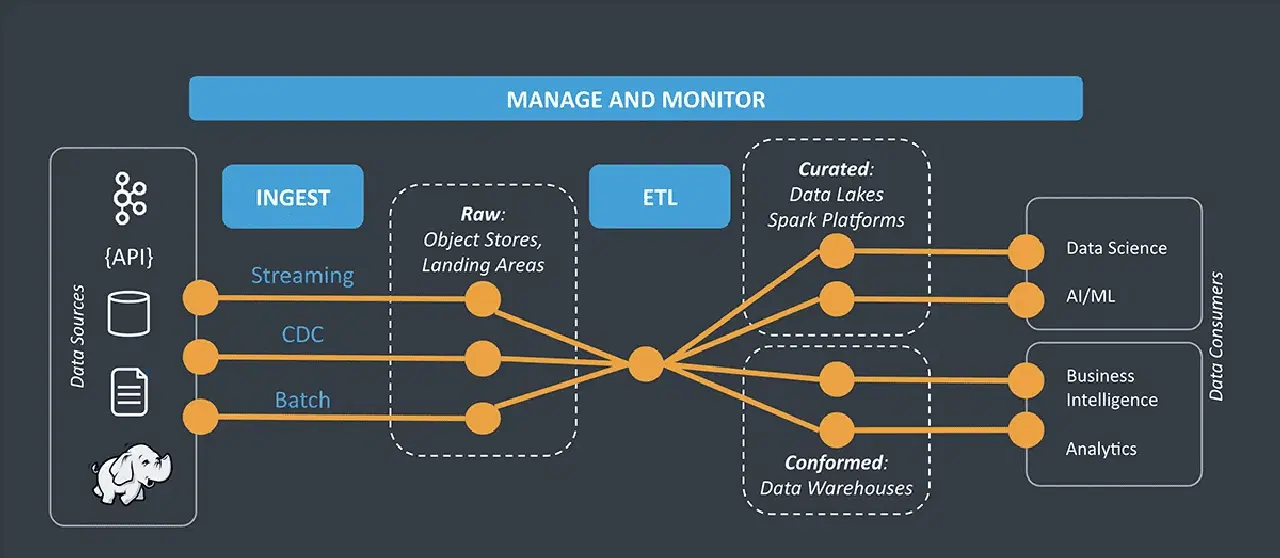 Source: StreamSets
Source: StreamSets
Architecture de l'intégration de données
L'architecture de l'intégration de données illustre le flux d'informations à travers les couches suivantes :
- Couche de collecte de données : Cette couche a pour mission de recueillir des données provenant de sources variées et de les stocker dans votre entrepôt de données. Elle détermine la manière dont les données sont transférées ou traitées vers les autres couches de l'architecture d'intégration. En outre, elle contribue à la décomposition des données pour le traitement analytique.
- Couche de traitement des données : Cette couche récupère les données de la couche précédente pour gérer le transfert des données stockées. Elle définit la destination vers laquelle vous souhaitez envoyer les données et les regroupe en conséquence.
- Couche de stockage des données : Une fois les données regroupées, elles sont stockées dans un emplacement adéquat pour un transfert ultérieur.
- Couche de requête de données : Cette couche correspond à la partie analytique de l'architecture d'intégration de données. C'est à ce niveau que les données sont interrogées, afin d'en extraire des informations précieuses.
- Couche de visualisation des données : La visualisation des données constitue la dernière couche. Elle traite de la présentation des informations, en les affichant sous un format visuel et compréhensible pour que votre organisation puisse obtenir des informations en temps réel.
Avantages de l'intégration de données

Examinons quelques-uns des avantages de l'intégration de données :
- Disponibilité : La mise en œuvre d'un processus d'intégration de données permet à l'organisation d'accéder facilement aux informations. Les données étant collectées à partir de sources variées et transférées vers un emplacement de stockage unique, toute personne disposant d'une autorisation valide peut y accéder aisément à des fins d'analyse.
- Cohérence : Une bonne pratique d'intégration de données améliore la qualité des informations en transformant divers types de données en un format unifié. Cette harmonisation facilite la manipulation et la compréhension des données pour des analyses ultérieures.
- Productivité accrue : L'intégration de données permet de tirer parti des informations pour améliorer la productivité. Elle offre aux ingénieurs de données une plus grande flexibilité et leur permet de développer leurs capacités d'évolution.
- Amélioration de la prise de décision : Le processus d'intégration de données permet aux organisations de prendre des décisions plus éclairées et plus judicieuses, en utilisant des données en temps réel. De plus, il est possible d'obtenir des analyses pertinentes pour prendre des décisions tactiques et suivre les indicateurs clés de performance (KPI) ainsi que les objectifs potentiels.
- Expérience utilisateur améliorée : Les organisations utilisent des données actualisées pour servir leurs clients de manière optimale. Les analyses basées sur les données permettent de créer des outils et des applications efficaces pour les utilisateurs.
Types d'intégration de données
Il existe trois types d'intégration de données : le traitement par lots, l'intégration de données en temps réel et l'intégration de données basée sur l'architecture Lambda. Le choix entre ces options dépend en grande partie du type d'entreprise, de l'infrastructure informatique, du budget, du calendrier et des objectifs visés. De plus, les entreprises sélectionnent leur modèle et leurs outils en fonction des sources de données qu'elles utilisent.
Examinons plus en détail chaque type.
#1. Le traitement par lots
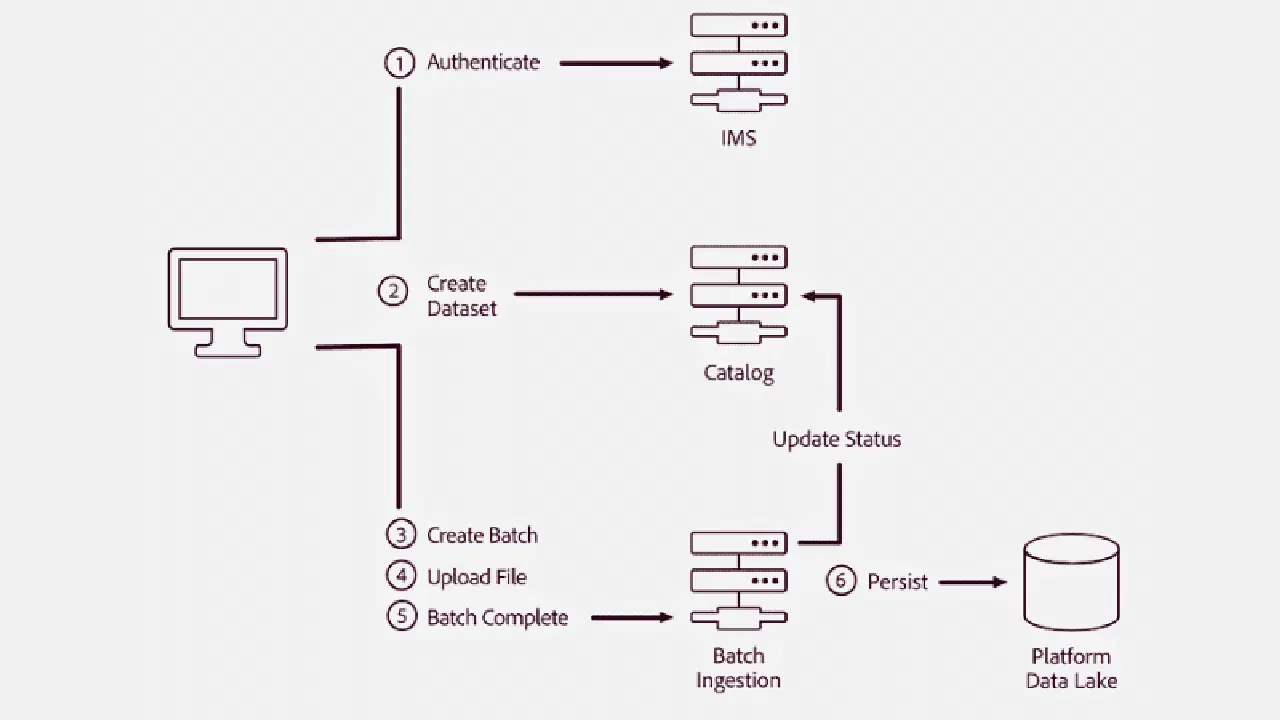 Source: Adobe Experience League
Source: Adobe Experience League
Il s'agit de la méthode d'intégration la plus répandue. La couche d'intégration rassemble et regroupe progressivement les données provenant de diverses sources. Elle transfère ensuite ces données par lots vers une application, un système ou un emplacement où elles sont requises.
Le transfert de données est basé sur l'activation de règles via des événements déclencheurs, un ordre analogique ou des calendriers préexistants, assurant ainsi le transfert des données. Le traitement par lots est particulièrement utile pour les organisations qui ont besoin de collecter quotidiennement des données spécifiques, pour des activités telles que la gestion des feuilles de présence ou la génération de rapports.
Cette approche est moins coûteuse et est souvent considérée comme une méthode traditionnelle.
#2. Intégration de données en temps réel
L'intégration de données en temps réel, également appelée traitement de flux, consiste à recueillir et à transférer les données d'une source donnée vers leur destination en temps réel. Il n'y a pas de regroupement dans ce processus. Les données sont plutôt recherchées, chargées et traitées dès que la couche d'intégration détecte de nouvelles informations.
Pour mettre en œuvre l'intégration de données en temps réel, une solution courante est utilisée : la capture des changements de données (CDC). Cependant, ce type d'intégration de données est plus coûteux que l'intégration par lots. Cela s'explique par la nécessité de surveiller en permanence les sources afin d'identifier les nouvelles informations et de s'assurer qu'elles sont correctement reflétées dans la plateforme cible.
Malgré un coût plus élevé, cette méthode est particulièrement bénéfique pour les entreprises qui souhaitent effectuer des analyses en utilisant les données les plus récentes, afin de prendre des décisions opérationnelles rapides.
Par exemple, l'intégration de données en temps réel est la solution idéale pour prendre des décisions liées aux transactions boursières. Elle est également très utile pour la surveillance de l'infrastructure.
#3. Intégration de données basée sur l'architecture Lambda
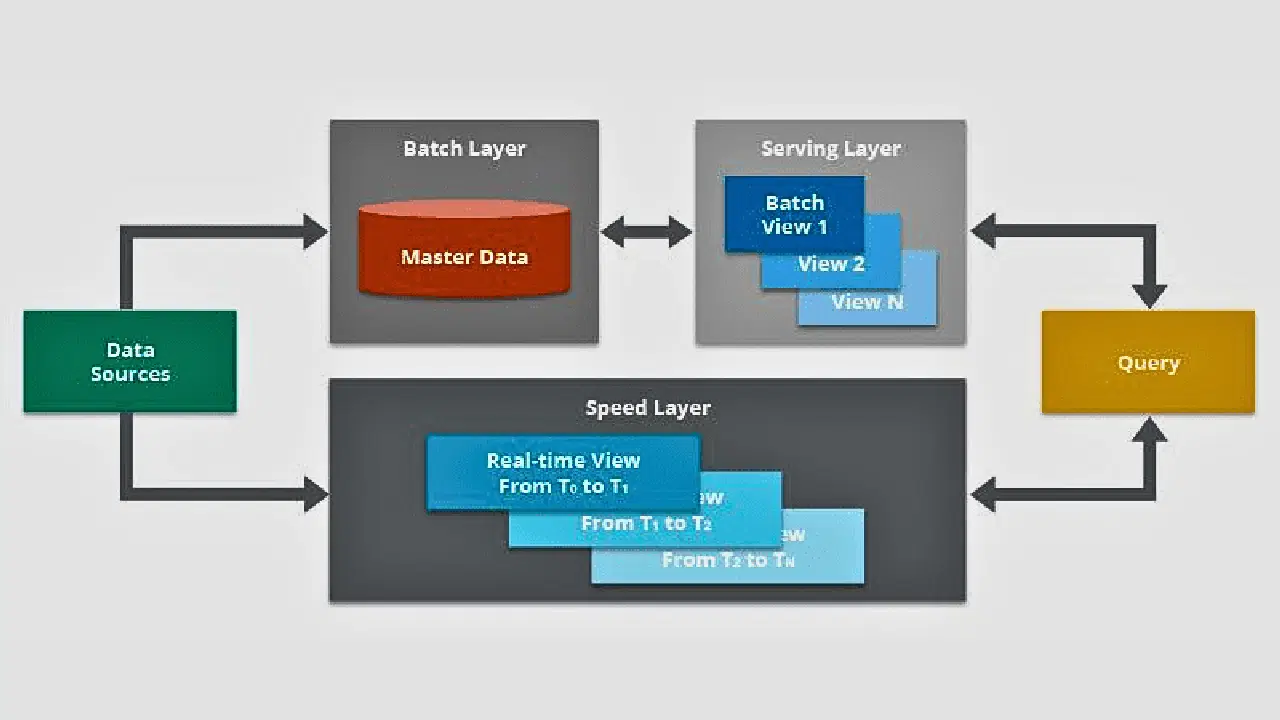 Source: Hazelcast
Source: Hazelcast
Cette méthode combine deux types d'intégration de données : le traitement par lots et l'intégration en temps réel.
Le traitement par lots est utilisé pour collecter des données par groupes, tandis que l'intégration de données en temps réel est utilisée pour traiter les données sensibles au temps d'une manière différente. L'intégration de données basée sur l'architecture Lambda divise les données collectées en groupes plus petits et les intègre de manière incrémentale. Cette approche est particulièrement efficace pour différentes applications nécessitant un flux de données.
Cas d'utilisation de l'intégration de données
Les organisations du monde entier utilisent les processus d'intégration de données comme un élément essentiel de leurs pipelines de données.
- Internet des objets (IoT) : L'intégration de données est utilisée dans divers systèmes IoT pour collecter et transformer les données provenant d'une large gamme d'appareils connectés.
- Analyse du Big Data : L'analyse du Big Data est une nécessité courante pour toutes les organisations. Elle exige l'intégration de volumes importants de données provenant de sources multiples, en utilisant des systèmes distribués tels que Spark ou Hadoop.
- Détection de la fraude : Les organisations utilisent le processus d'intégration de données pour détecter la fraude en important et en transformant des données provenant de diverses sources, telles que le comportement des clients, les flux de données tiers et les transactions.
- Commerce électronique : Les entreprises de commerce électronique utilisent le processus d'intégration de données pour recevoir des informations provenant de sources variées, telles que les transactions des clients, les catalogues de produits, les analyses de sites Web, etc. Cela leur permet de se développer en utilisant des données pertinentes en temps réel.
- Personnalisation : Le processus d'intégration de données peut être utilisé pour offrir des expériences ou des recommandations personnalisées aux utilisateurs, en extrayant des informations de différentes sources, comme les interactions avec les clients, les données des réseaux sociaux, les analyses de sites Web, etc.
- Gestion de la chaîne d'approvisionnement : Pour gérer la chaîne d'approvisionnement, une organisation a besoin de données provenant de diverses sources, telles que les données d'inventaire, de logistique et des fournisseurs. L'intégration de données permet de traiter ces informations provenant de différentes sources, pour une gestion efficace de la chaîne d'approvisionnement.
- Analyse des sentiments et des médias sociaux : L'intégration de données en temps réel aide les entreprises à surveiller les flux des médias sociaux, à identifier les tendances émergentes et à analyser efficacement le sentiment de la marque, en recueillant des données provenant de diverses sources. Cette approche permet d'améliorer les relations avec les clients, de développer des stratégies de conquête de marché et de mettre en œuvre des campagnes marketing efficaces.
Défis

L'intégration de données peut être confrontée à certains défis :
- Évolutivité : Il peut être difficile d'adapter le processus à la gestion de grands ensembles de données tout en intégrant des informations provenant de sources variées. La quantité de données traitées nécessite une mise à l'échelle verticale ou horizontale de l'infrastructure pour gérer la charge accrue, ce qui peut entraîner des complications.
- Qualité des données : La qualité des données est un défi majeur dans le processus d'intégration. Lors de l'extraction des informations, il n'est pas toujours garanti qu'elles soient de haute qualité.
- Écosystème diversifié : Il existe une multitude de sources et de types de données, ce qui peut rendre difficile le développement d'un modèle d'intégration fiable. Certains outils et fonctionnalités ne prennent en charge que des technologies de base, ce qui oblige les organisations à utiliser plusieurs outils, nécessitant ainsi une variété de compétences.
- Coût : Le coût de l'intégration est directement proportionnel aux volumes de données. À mesure que les volumes de données augmentent, les coûts globaux d'intégration progressent également. Pour intégrer toutes les données, il est nécessaire d'augmenter le nombre de serveurs et de systèmes de stockage, ce qui entraîne une hausse des coûts.
- Sécurité : Comme les données sont stockées à de nombreux points du pipeline lors de leur intégration, elles sont exposées à des risques de sécurité et à la divulgation d'informations. Cela peut rendre le processus d'intégration vulnérable et entraîner des failles de sécurité. Ainsi, les organisations peinent à maintenir la conformité aux normes et réglementations tout au long du processus.
- Intégration des données : L'intégration des données provenant de sources tierces dans le pipeline d'intégration peut poser quelques difficultés. C'est pourquoi un outil complet, capable de gérer ces intégrations, est indispensable.
- Manque de fiabilité : Si les données ne sont pas intégrées correctement, le processus peut devenir peu fiable, ce qui peut entraîner des interruptions de communication et des pertes de données.
Les meilleures pratiques
Examinons quelques pratiques d'intégration de données que vous pouvez suivre pour améliorer les performances de votre entreprise.
Intégration automatisée de données
L'intégration automatisée de données peut résoudre de nombreux problèmes liés à l'intégration manuelle. Elle reconnaît la complexité et le caractère inévitable de la transformation des données brutes en informations utiles, en particulier lorsque les données proviennent de sources disparates.
Les organisations peuvent utiliser des outils d'intégration de données pour automatiser les processus récurrents de collecte de données, afin d'obtenir de meilleures analyses et de meilleurs rapports, tout en réduisant le risque d'erreurs humaines.
Créer des accords de niveau de service (SLA) pour les données
Les SLA de données définissent :
- Les besoins spécifiques de l'entreprise.
- Les attentes de l'entreprise concernant les données.
- Le délai dans lequel les données doivent répondre aux attentes.
- Les parties concernées.
- La méthode pour vérifier le respect des SLA et les mesures à prendre en cas de violation.
Ainsi, l'approche d'intégration de données vous aide à obtenir toutes les informations nécessaires pour créer efficacement des SLA de données.
Bande passante du réseau
Le pipeline d'intégration de données peut être conçu de manière à gérer efficacement la bande passante du réseau.
Le trafic n'est pas toujours constant et peut augmenter ou diminuer en fonction de paramètres sociaux et physiques. La bande passante du réseau dépend également de la quantité de données à intégrer à un moment donné.
Systèmes et technologies hétérogènes

Une organisation doit vérifier si le modèle de pipeline d'intégration de données est compatible avec les outils et applications tiers, ainsi qu'avec divers systèmes d'exploitation.
Prise en charge des données peu fiables
Le pipeline d'intégration de données reçoit des données provenant de sources diverses et de structures variées, comme des fichiers audio, des fichiers journaux, des images, et bien d'autres.
Différentes structures nécessitent des vitesses variables, ce qui peut rendre l'ensemble du pipeline peu fiable. Les organisations doivent concevoir un pipeline d'intégration de données prenant en charge tous les formats, sans compromettre la fiabilité.
Haute précision
Le processus d'intégration de données est directement lié aux données auditables. Il nécessite un processus bien conçu, capable de modifier les fonctions intermédiaires en fonction des besoins.
Données en continu
Les entreprises ont besoin de processus d'intégration de données en temps réel et par lots, afin d'améliorer leurs services et de gagner en efficacité.
Découplage des bases de données

Certaines organisations, en particulier les plus grandes, intègrent directement leur base de données analytique ou de business intelligence à leur base de données opérationnelle. Le découplage des bases de données analytiques et opérationnelles aide les organisations à limiter les répercussions des problèmes d'une base de données sur l'autre.
Conclusion
L'intégration de données fournit des informations immédiates qui vous permettent de comprendre les tendances actuelles du marché, de maintenir une faible latence et d'évaluer l'expérience client. Le pipeline d'intégration de données est constitué de plusieurs couches, allant de l'extraction et de la collecte des données à leur visualisation et à leur analyse.
Grâce à l'intégration de données, les organisations peuvent facilement améliorer leur efficacité opérationnelle, détecter plus rapidement la fraude, obtenir des analyses en temps réel et mettre en place une maintenance proactive. Les entreprises peuvent également utiliser l'intégration de données en temps réel pour obtenir des informations à jour, et s'en servir pour gagner un avantage concurrentiel et prendre des décisions éclairées.
Vous pouvez également vous renseigner davantage sur l'orchestration de données en termes simples.