Guide pour prévenir les intrusions sur le réseau
Les informations constituent un pilier central pour les entreprises et les institutions. Cependant, leur utilité ne se manifeste pleinement que lorsqu'elles sont structurées avec soin et gérées avec efficacité.
Des études récentes révèlent que 95% des organisations rencontrent des difficultés notables dans la gestion et l'organisation des données non structurées.
C'est précisément là qu'intervient l'exploration de données, un processus crucial qui englobe la découverte, l'analyse et l'extraction de schémas significatifs et d'informations précieuses à partir de vastes ensembles de données non structurées.
Les entreprises s'appuient sur des logiciels spécialisés pour identifier des tendances dans d'importants volumes de données. Cela leur permet de mieux cerner leur clientèle et leur public cible, et d'élaborer des stratégies commerciales et marketing optimisées pour stimuler les ventes et réduire les dépenses.
Au-delà de cet avantage, l'exploration de données joue un rôle majeur dans la détection des fraudes et des anomalies, des applications parmi les plus critiques.
Cet article se penche sur la détection des anomalies, en explorant en profondeur son potentiel pour prévenir les violations de données et les intrusions réseau, assurant ainsi la protection des informations.
Qu'est-ce que la détection d'anomalies et quels sont ses différents types ?
Tandis que l'exploration de données vise à identifier des schémas, des liens et des tendances, elle constitue un outil puissant pour repérer les anomalies ou les points de données atypiques au sein d'un réseau.
Dans ce contexte, les anomalies désignent des points de données qui se distinguent des autres et qui s'écartent du modèle de comportement normal de l'ensemble de données.
Ces anomalies peuvent être classées en plusieurs catégories :
- Changements d'événements : font référence à des variations brusques ou progressives par rapport à un comportement considéré comme normal.
- Valeurs aberrantes : Modèles anormaux isolés et non systématiques qui apparaissent au sein d'un ensemble de données. On distingue les valeurs aberrantes globales, contextuelles et collectives.
- Dérive : évolution progressive, non directionnelle et à long terme des données.
Ainsi, la détection d'anomalies représente une méthode de traitement de données précieuse pour détecter les transactions frauduleuses, gérer des situations où les classes sont déséquilibrées et identifier des maladies, contribuant ainsi à la construction de modèles robustes en science des données.
Par exemple, une entreprise peut analyser ses flux de trésorerie pour identifier des transactions inhabituelles ou récurrentes sur un compte bancaire inconnu, signalant potentiellement une fraude et nécessitant une enquête approfondie.
Bénéfices de la détection d'anomalies
La détection des anomalies dans le comportement des utilisateurs contribue à renforcer les systèmes de sécurité, en les rendant plus précis et efficaces.
Elle permet d'analyser et d'interpréter les données fournies par les systèmes de sécurité afin d'identifier les menaces potentielles et les risques au sein du réseau.
Voici quelques avantages de la détection d'anomalies pour les entreprises :
- Détection en temps réel des menaces de cybersécurité et des violations de données, grâce à des algorithmes d'intelligence artificielle (IA) qui analysent continuellement les données à la recherche de comportements inhabituels.
- Le suivi des activités et des modèles anormaux est plus rapide et plus aisé que la détection manuelle, ce qui réduit le temps et les efforts nécessaires pour résoudre les problèmes.
- Minimisation des risques opérationnels par l'identification des erreurs, comme les baisses soudaines de performance, avant qu'elles ne surviennent.
- Réduction des pertes financières en détectant rapidement les anomalies, car sans un système de détection d'anomalies, les entreprises pourraient mettre des semaines ou des mois à identifier les menaces potentielles.
Ainsi, la détection d'anomalies constitue un atout majeur pour les entreprises qui stockent de grandes quantités de données client et commerciales. Elle leur permet d'identifier des opportunités de croissance et d'éliminer les menaces de sécurité et les goulets d'étranglement opérationnels.
Techniques de détection d'anomalies
La détection d'anomalies s'appuie sur diverses méthodes et algorithmes d'apprentissage automatique (ML) pour surveiller les données et identifier les menaces.
Voici les principales techniques utilisées :
#1. Techniques d'apprentissage automatique

Les techniques d'apprentissage automatique emploient des algorithmes de ML pour analyser les données et repérer les anomalies. Parmi les types d'algorithmes d'apprentissage automatique couramment utilisés, on retrouve :
- Algorithmes de regroupement
- Algorithmes de classification
- Algorithmes d'apprentissage profond
Les techniques de ML fréquemment utilisées pour la détection des anomalies et des menaces comprennent les machines à vecteurs de support (SVM), le clustering k-means et les auto-encodeurs.
#2. Techniques statistiques
Les techniques statistiques utilisent des modèles pour identifier des schémas inhabituels (par exemple, des fluctuations anormales dans les performances d'une machine) dans les données. Elles permettent de détecter les valeurs qui dépassent les limites attendues.
Les méthodes statistiques de détection d'anomalies courantes incluent les tests d'hypothèse, l'intervalle interquartile (IQR), le score Z, le score Z modifié, l'estimation de densité, les boîtes à moustaches, l'analyse des valeurs extrêmes et l'histogramme.
#3. Techniques d'exploration de données

Les techniques d'exploration de données utilisent des méthodes de classification et de regroupement afin d'identifier les anomalies dans un ensemble de données. On retrouve parmi les techniques courantes le regroupement spectral, le regroupement basé sur la densité et l'analyse en composantes principales.
Les algorithmes de regroupement sont utilisés pour organiser les points de données en groupes en fonction de leur similarité, ce qui permet de repérer les anomalies situées en dehors de ces groupes.
D'un autre côté, les algorithmes de classification attribuent les points de données à des classes prédéfinies et détectent ceux qui ne correspondent à aucune de ces classes.
#4. Techniques basées sur des règles
Comme leur nom l'indique, les techniques de détection d'anomalies basées sur des règles utilisent un ensemble de règles préétablies pour détecter les anomalies.
Bien qu'elles soient relativement simples à mettre en œuvre, ces techniques peuvent manquer de flexibilité et d'efficacité pour s'adapter à l'évolution des comportements et des schémas de données.
Par exemple, il est facile de programmer un système basé sur des règles pour signaler les transactions dépassant un montant spécifique comme étant potentiellement frauduleuses.
#5. Techniques spécifiques à un domaine
Les techniques spécifiques à un domaine permettent de détecter les anomalies au sein de systèmes de données particuliers. Elles peuvent être très efficaces dans leurs domaines d'application, mais moins performantes en dehors.
Par exemple, il est possible de concevoir des techniques dédiées à la détection d'anomalies dans les transactions financières. Ces techniques ne fonctionneraient pas nécessairement pour identifier des anomalies dans les performances d'une machine.
Nécessité de l'apprentissage automatique pour la détection d'anomalies
L'apprentissage automatique est un élément essentiel et très utile dans le domaine de la détection d'anomalies.
De nos jours, la plupart des entreprises et des organisations qui doivent détecter des valeurs aberrantes traitent d'immenses quantités de données, qu'il s'agisse de texte, d'informations client, de transactions ou encore de fichiers multimédias tels que des images et des vidéos.
L'analyse manuelle de chaque transaction bancaire ou de toutes les données générées à chaque seconde pour en extraire des informations utiles est une tâche quasiment impossible. De plus, de nombreuses entreprises peinent à structurer les données non structurées et à les organiser de manière significative pour l'analyse.
C'est là que des outils et des techniques tels que l'apprentissage automatique (ML) jouent un rôle essentiel pour collecter, nettoyer, structurer, organiser, analyser et stocker d'énormes volumes de données non structurées.
Les algorithmes et techniques de ML permettent de traiter de vastes ensembles de données et offrent la possibilité de combiner différentes approches pour obtenir les meilleurs résultats.
De plus, l'apprentissage automatique permet de rationaliser les processus de détection d'anomalies pour des applications réelles et d'économiser des ressources précieuses.
Voici quelques autres avantages de l'apprentissage automatique en matière de détection d'anomalies :
- Il facilite la détection des anomalies à grande échelle en automatisant l'identification des schémas et des anomalies sans nécessiter de programmation explicite.
- Les algorithmes d'apprentissage automatique s'adaptent facilement à l'évolution des schémas dans les ensembles de données, ce qui les rend efficaces et robustes au fil du temps.
- Il gère facilement les ensembles de données volumineux et complexes, ce qui rend la détection d'anomalies efficace malgré la complexité des données.
- Il assure l'identification précoce des anomalies en les détectant au fur et à mesure qu'elles surviennent, ce qui permet d'économiser du temps et des ressources.
- Les systèmes de détection d'anomalies basés sur l'apprentissage automatique offrent une plus grande précision par rapport aux méthodes traditionnelles.
Ainsi, la détection d'anomalies, combinée à l'apprentissage automatique, permet une détection plus rapide et plus précoce des anomalies afin de prévenir les menaces de sécurité et les violations malveillantes.
Algorithmes d'apprentissage automatique pour la détection d'anomalies
Il est possible de détecter des anomalies et des valeurs aberrantes dans les données grâce à différents algorithmes d'exploration de données utilisés pour la classification, le regroupement ou l'apprentissage de règles d'association.
Ces algorithmes d'exploration de données sont généralement classés en deux catégories : les algorithmes d'apprentissage supervisés et non supervisés.
Apprentissage supervisé
L'apprentissage supervisé est un type d'algorithme courant qui englobe des méthodes telles que les machines à vecteurs de support, la régression logistique et linéaire et la classification multiclasse. Ce type d'algorithme est entraîné sur des données étiquetées, c'est-à-dire que l'ensemble de données d'entraînement comprend à la fois des données d'entrée normales et des sorties correctes ou des exemples anormaux pour construire un modèle prédictif.
Ainsi, son objectif est de générer des prédictions de sortie pour des données inédites et nouvelles basées sur les modèles présents dans les données d'entraînement. Parmi les applications des algorithmes d'apprentissage supervisé, on retrouve la reconnaissance d'images et de la parole, la modélisation prédictive et le traitement du langage naturel (TAL).
Apprentissage non supervisé
L'apprentissage non supervisé n'est pas entraîné sur des données étiquetées. Au lieu de cela, il découvre des processus complexes et des structures de données sous-jacentes sans guide de formation, au lieu de faire des prédictions spécifiques.
Les applications des algorithmes d'apprentissage non supervisé comprennent la détection d'anomalies, l'estimation de la densité et la compression de données.
Examinons à présent quelques algorithmes populaires de détection d'anomalies basés sur l'apprentissage automatique.
Facteur de valeur aberrante locale (LOF)
Le facteur de valeur aberrante locale (Local Outlier Factor ou LOF) est un algorithme de détection d'anomalies qui prend en compte la densité locale des données pour déterminer si un point de données est une anomalie.
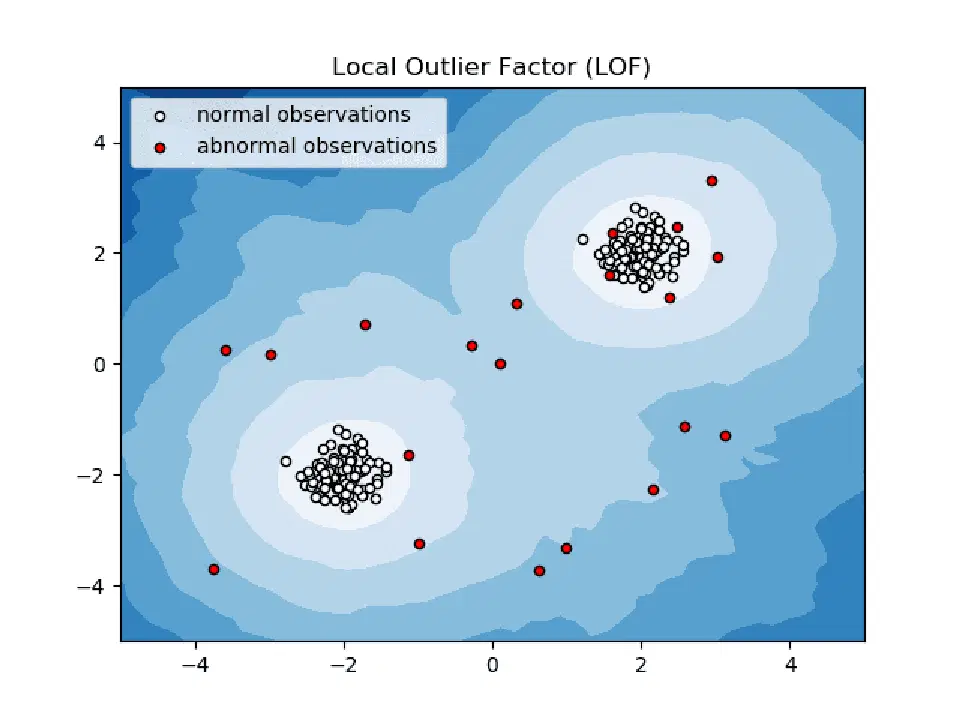
Il compare la densité locale d'un élément avec celle de ses voisins afin d'identifier les zones de densités similaires et les éléments dont la densité est considérablement inférieure à celle de leurs voisins, qui sont considérés comme des anomalies ou des valeurs aberrantes.
En d'autres termes, la densité autour d'un élément aberrant ou anormal diffère de celle autour de ses voisins. Cet algorithme est donc également appelé algorithme de détection de valeurs aberrantes basé sur la densité.
K plus proches voisins (K-NN)
K-NN est l'algorithme de classification et de détection d'anomalies supervisé le plus simple à mettre en œuvre. Il conserve tous les exemples et données disponibles et classe les nouveaux exemples en fonction de la similarité des métriques de distance.
Cet algorithme de classification est également connu sous le nom d'apprenant paresseux, car il se contente de stocker les données d'entraînement étiquetées, sans effectuer d'autres opérations pendant le processus de formation.
Lorsqu'un nouveau point de données d'apprentissage non étiqueté arrive, l'algorithme examine les K points de données d'apprentissage les plus proches afin de déterminer la classe de ce nouveau point de données non étiqueté.
L'algorithme K-NN utilise les méthodes de détection suivantes pour déterminer les points de données les plus proches :
- Distance euclidienne pour mesurer la distance entre les données continues.
- Distance de Hamming pour mesurer la proximité ou la similarité de deux chaînes de texte pour les données discrètes.
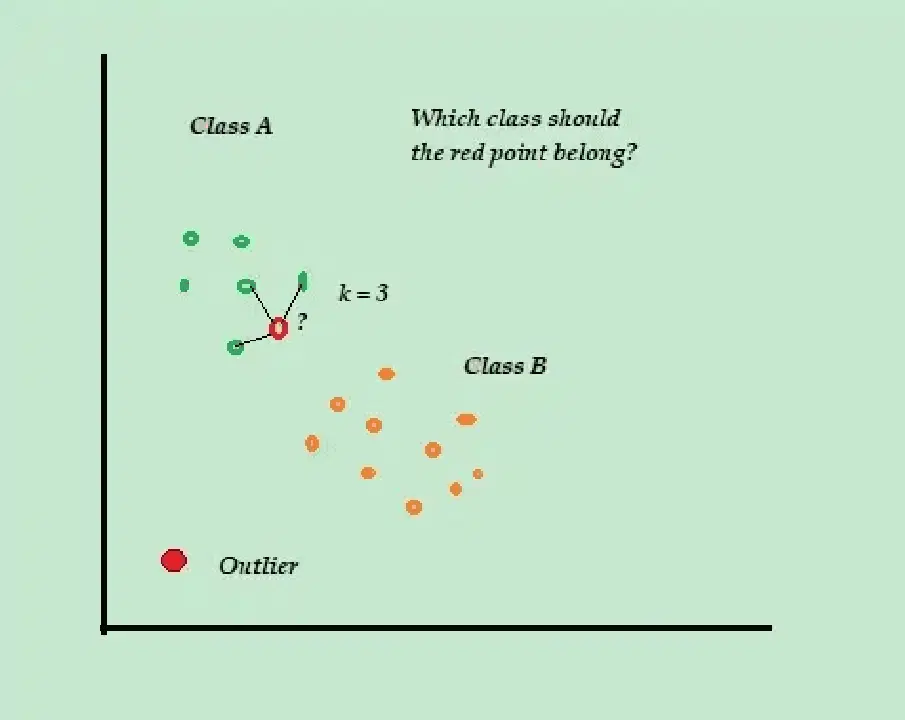
Par exemple, supposons que vos ensembles de données d'entraînement comportent deux étiquettes de classe : A et B. Si un nouveau point de données arrive, l'algorithme calcule la distance entre ce nouveau point et chacun des points de données de l'ensemble de données, puis sélectionne les points les plus proches du nouveau point.
Donc, si K=3 et que 2 points de données sur 3 sont étiquetés comme A, alors le nouveau point de données sera étiqueté comme classe A.
Par conséquent, l'algorithme K-NN fonctionne mieux dans les environnements dynamiques où les données doivent être fréquemment mises à jour.
Il s'agit d'un algorithme populaire de détection d'anomalies et d'exploration de texte utilisé dans le domaine de la finance et des entreprises pour détecter les transactions frauduleuses et augmenter le taux de détection des fraudes.
Machine à vecteurs de support (SVM)
La machine à vecteurs de support (SVM) est un algorithme de détection d'anomalies basé sur l'apprentissage automatique supervisé, principalement utilisé pour la régression et la classification.
Elle utilise un hyperplan multidimensionnel pour séparer les données en deux groupes (normal et nouveau). Cet hyperplan sert de frontière de décision, en séparant les observations de données normales des nouvelles données.
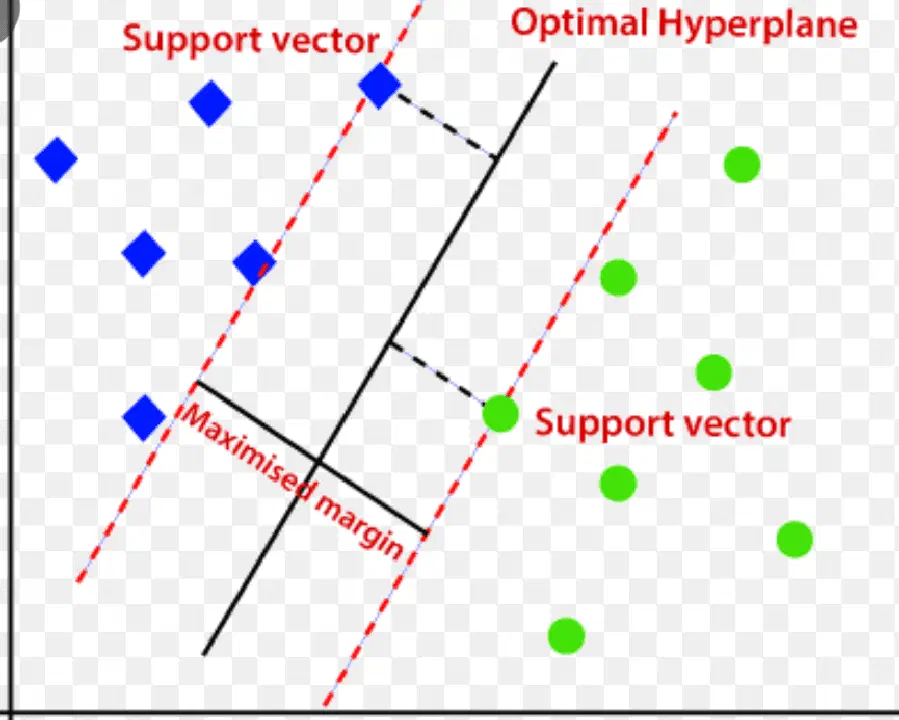
La distance entre ces deux points de données est appelée marges.
Puisque l'objectif est d'augmenter la distance entre les deux points, la SVM détermine le meilleur ou l'hyperplan optimal avec la marge maximale pour s'assurer que la distance entre les deux classes est la plus large possible.
En ce qui concerne la détection d'anomalies, la SVM calcule la marge entre l'observation du nouveau point de données et l'hyperplan afin de le classer.
Si la marge dépasse le seuil défini, la nouvelle observation est classée comme une anomalie. Si la marge est inférieure au seuil, l'observation est classée comme normale.
Ainsi, les algorithmes SVM sont très efficaces pour gérer des ensembles de données complexes et de grande dimension.
Forêt d'isolement
La forêt d'isolement (Isolation Forest) est un algorithme de détection d'anomalies non supervisé basé sur l'apprentissage automatique. Son concept est dérivé d'un classificateur de forêt aléatoire.
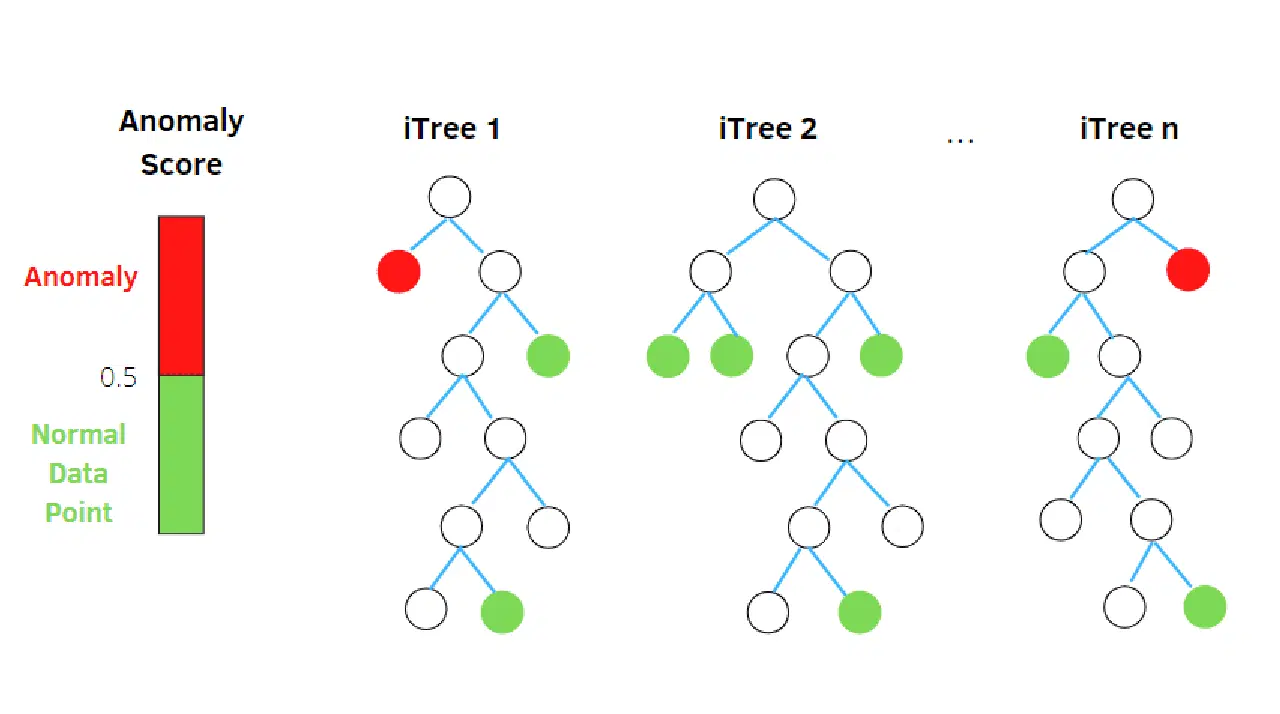
Cet algorithme utilise des données sous-échantillonnées aléatoirement dans l'ensemble de données dans une structure arborescente basée sur des attributs aléatoires. Il construit plusieurs arbres de décision pour isoler les observations. Une observation est considérée comme anormale si elle est isolée dans moins d'arbres, en fonction de son taux de contamination.
En d'autres termes, l'algorithme de la forêt d'isolement divise les points de données en différents arbres de décision, garantissant ainsi que chaque observation est isolée des autres.
Les anomalies se trouvent généralement loin des groupes de points de données, ce qui facilite leur identification par rapport aux points de données normaux.
Les algorithmes de forêt d'isolement peuvent facilement gérer des données catégorielles et numériques. Par conséquent, ils sont plus rapides à entraîner et très efficaces pour détecter les anomalies dans de grands ensembles de données de grande dimension.
Intervalle interquartile
L'intervalle interquartile (IQR) est utilisé pour mesurer la variabilité ou la dispersion statistique afin de trouver des points anormaux dans les ensembles de données en les divisant en quartiles.
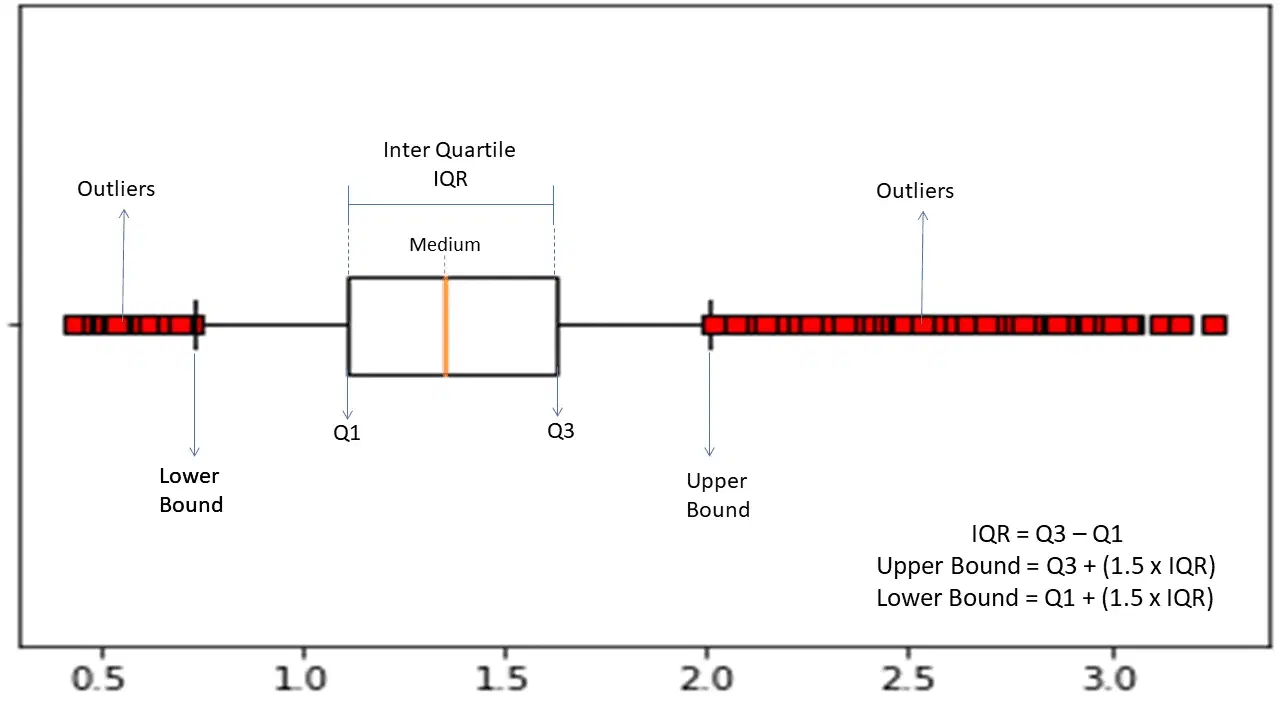
L'algorithme trie les données par ordre croissant et divise l'ensemble en quatre parties égales. Les valeurs séparant ces parties sont les Q1, Q2 et Q3 : premier, deuxième et troisième quartiles.
Voici la distribution en centiles de ces quartiles :
- Q1 correspond au 25e centile des données.
- Q2 correspond au 50e centile des données.
- Q3 correspond au 75e centile des données.
L'IQR est la différence entre les valeurs du troisième (75e) et du premier (25e) centile, ce qui représente 50 % des données.
Pour utiliser l'IQR dans le cadre de la détection d'anomalies, il faut calculer l'IQR de l'ensemble de données, puis définir les limites inférieure et supérieure des données afin d'identifier les anomalies.
- Limite inférieure : Q1 – 1,5 * IQR
- Limite supérieure : Q3 + 1,5 * IQR
Généralement, les observations qui se situent en dehors de ces limites sont considérées comme des anomalies.
L'algorithme IQR est efficace pour les ensembles de données dont la distribution est inégale et lorsque la distribution n'est pas bien comprise.
Conclusion
Les risques liés à la cybersécurité et les violations de données ne semblent pas diminuer dans les années à venir. Il est même attendu que le secteur des cyberattaques, déjà risqué, prenne encore de l'ampleur en 2023 et que les cyberattaques ciblant l'internet des objets (IoT) doublent d'ici 2025.
De plus, les cybercrimes devraient coûter aux entreprises et organisations mondiales environ 10,3 billions de dollars par an d'ici 2025.
C'est pourquoi les techniques de détection d'anomalies sont de plus en plus utilisées aujourd'hui pour détecter les fraudes et prévenir les intrusions dans les réseaux.
Cet article vous a permis de mieux comprendre ce que sont les anomalies dans le cadre de l'exploration de données, leurs différents types, ainsi que les méthodes permettant d'empêcher les intrusions dans les réseaux grâce aux techniques de détection d'anomalies basées sur l'apprentissage automatique.
Vous pouvez maintenant approfondir vos connaissances sur la matrice de confusion en apprentissage automatique.