
Les entreprises d’aujourd’hui sont centrées sur les données. Les entreprises trouvent des moyens d’extraire et d’analyser efficacement des données provenant de diverses sources et d’améliorer leurs revenus et leurs bénéfices.
Mais quel est l’endroit le plus sûr pour stocker et intégrer des données provenant de plusieurs sources et en tirer le meilleur parti ?
Les lacs de données et les entrepôts de données sont des moyens populaires de gérer de grandes quantités de données volumineuses. Les différences entre eux résident dans la manière dont les organisations ingèrent, stockent et utilisent les données. Lisez la suite pour en savoir plus.
Table des matières
Qu’est-ce qu’un lac de données ?
Un lac de données fait référence à un référentiel de stockage central où les données ingérées à partir de plusieurs sources – dans n’importe quel format (structuré ou non structuré) – sont stockées telles qu’elles ont été reçues. C’est comme un pool de données brutes, dont le but est encore inconnu. Les entreprises stockent généralement des données qui pourraient être potentiellement utiles pour une analyse future dans un lac de données.
Principales caractéristiques d’un lac de données :
- Il contient un mélange de données utiles et non utiles et nécessite donc beaucoup d’espace de stockage.
- Stocke à la fois des données en temps réel et par lots – par exemple, vous pouvez stocker des données en temps réel à partir d’appareils IoT, de médias sociaux ou d’applications cloud et des données par lots à partir de bases de données ou de fichiers de données.
- A une architecture plate.
- Comme les données ne sont pas traitées tant qu’elles ne sont pas nécessaires à l’analyse, elles doivent être bien gérées et entretenues ; sinon, il peut se transformer en marécages de données.
Alors, comment pouvons-nous récupérer rapidement des données à partir d’un référentiel de stockage aussi vaste et apparemment désordonné ? Eh bien, un lac de données utilise des balises de métadonnées et des identifiants à cette fin !
Qu’est-ce qu’un entrepôt de données ?
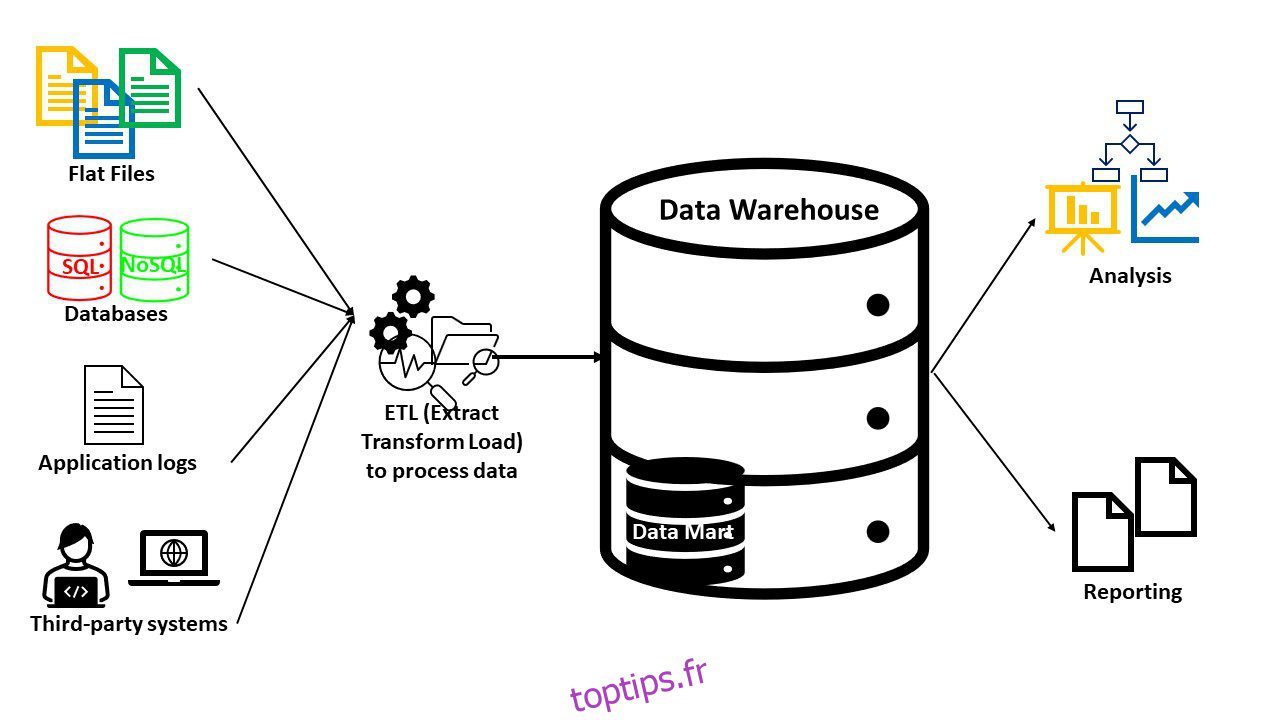
Un référentiel plus organisé et structuré – un entrepôt de données contient des données prêtes à être analysées. Les données structurées, semi-structurées ou non structurées provenant de plusieurs sources sont ingérées, intégrées, nettoyées, triées, transformées et adaptées à l’utilisation.
L’entrepôt de données contient de grandes quantités de données passées et actuelles. Habituellement, les données sont traitées pour un problème métier spécifique (analyse). Ces informations sont interrogées par les systèmes de Business Intelligence (BI) à des fins d’analyse, de création de rapports et d’informations.
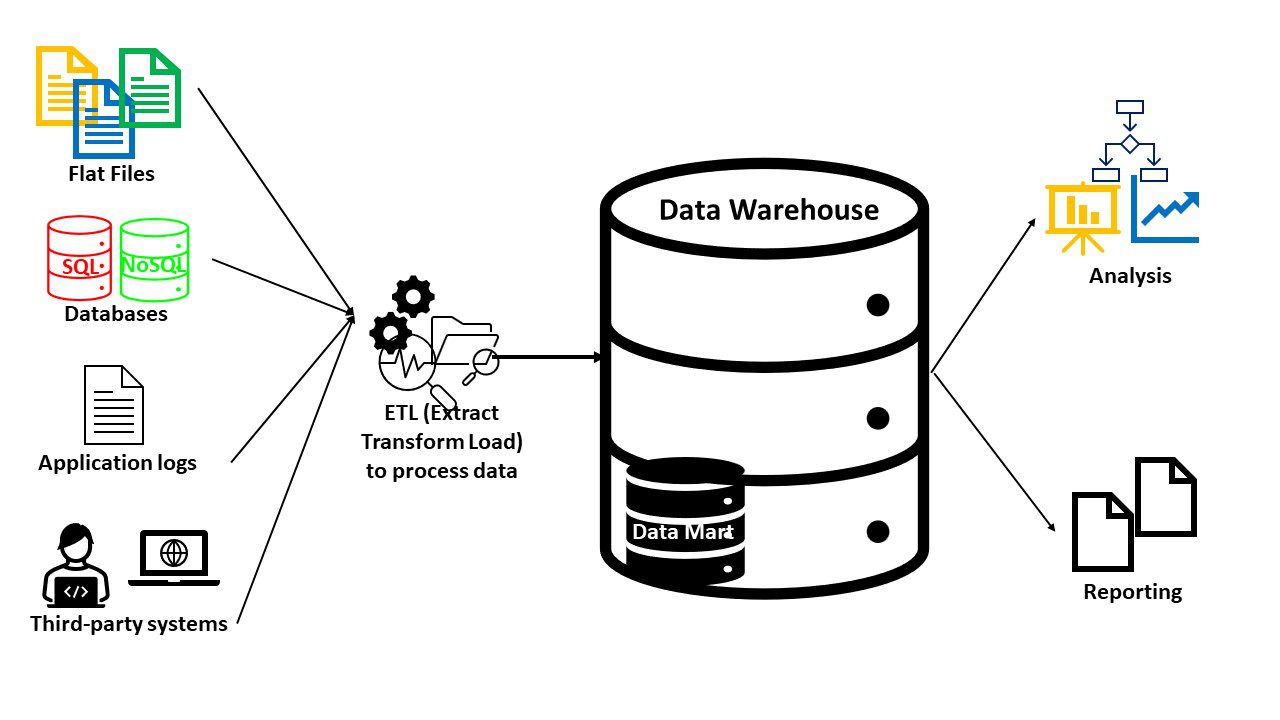
Les entrepôts de données se composent généralement des éléments suivants :
- Une base de données (SQL ou NoSQL) pour stocker et gérer les données
- Outils de transformation et d’analyse des données pour préparer les données
- Outils de BI pour l’exploration de données, l’analyse statistique, le reporting et la visualisation
Les entrepôts de données ayant un objectif spécifique, vous disposerez toujours de données pertinentes. Vous pouvez également utiliser des outils supplémentaires dans les entrepôts de données pour répondre aux fonctionnalités avancées telles que l’intelligence artificielle et les fonctionnalités spatiales ou graphiques. Les entrepôts de données créés pour un domaine spécifique sont appelés data marts.
Principales différences entre les lacs de données et les entrepôts de données
Pour reprendre ce que nous avons lu plus haut, le data lake contient des données brutes dont la finalité n’a pas été définie. En revanche, un entrepôt de données contient des données prêtes à être analysées et déjà sous leur meilleure forme.
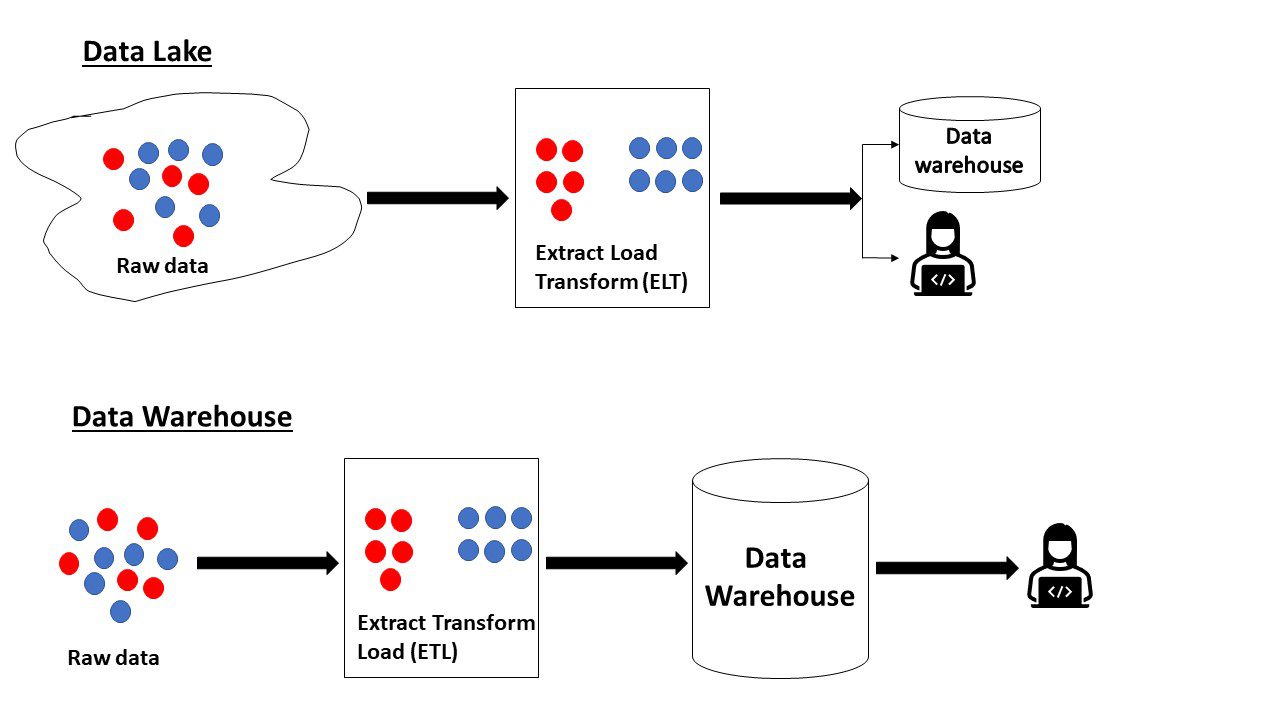 Lac de données vs entrepôt de données
Lac de données vs entrepôt de données
Certaines différences entre un lac de données et un entrepôt de données sont :
Data LakeData WarehouseLes données brutes ou traitées dans n’importe quel format sont ingérées à partir de plusieurs sourcesLes données sont obtenues à partir de plusieurs sources pour l’analyse et la création de rapports. Il est structuré Le schéma est créé à la volée selon les besoins (schéma en lecture) Schéma prédéfini lors de l’écriture dans l’entrepôt (Schéma en écriture) De nouvelles données peuvent être ajoutées facilement Les données sont prêtes après le traitement, donc toute nouvelle modification nécessite plus de temps et Les données doivent être mises à jour et régies pour être pertinentes Les données sont déjà sous leur meilleure forme, elles ne nécessitent donc pas de maintenance spécifique Elles consistent en d’énormes volumes de données volumineuses (pétaoctets) Les données sont généralement inférieures à celles du lac de données (téraoctets). L’entrepôt de données peut contenir des données opérationnelles d’une organisation entière, des données analytiques ou des données pertinentes pour un domaine particulier. Utilisé par les scientifiques des données à diverses fins telles que l’analyse en continu, l’intelligence artificielle, l’analyse prédictive et de nombreux cas d’utilisation. Utilisé par les analystes commerciaux pour le traitement des transactions ( OLTP), analyse opérationnelle (OLAP), création de rapports, création de visualisationsLes données peuvent être stockées et archivées pendant une période prolongée pour être analysées à tout moment. Les données doivent être fréquemment purgées pour accueillir les dernières données. Le stockage est peu coûteux. -consommatrices, doivent donc être planifiées judicieusement.Les scientifiques des données peuvent développer de nouveaux problèmes et solutions en examinant les données.La portée des données est limitée à un problème métier spécifique.Puisque les données ne sont pas organisées de manière particulière, à la fois relationnelle et non- les bases de données relationnelles peuvent être utilisées pour stocker des données. Les entrepôts de données utilisent généralement des bases de données relationnelles car les données doivent être dans une partie format culier.
Cas d’utilisation pour Data Lake et Data Warehouse
Il est facile de considérer un lac de données comme un choix plus pratique car il est plus évolutif, flexible et convivial. Cependant, un entrepôt de données peut être une excellente idée lorsque vous avez besoin de données plus pertinentes et structurées pour une analyse spécifique.
Certains cas d’utilisation du lac de données sont les suivants :
#1. Chaîne d’approvisionnement et gestion
L’énorme quantité de données volumineuses dans les lacs de données facilite l’analyse prédictive pour le transport et la logistique. À l’aide de données historiques et actuelles, les entreprises peuvent planifier leurs opérations quotidiennes en douceur, inspecter le mouvement des stocks en temps réel et optimiser les coûts.
#2. Soins de santé
Le lac de données contient toutes les informations passées et actuelles des patients. Cela est utile dans la recherche, la recherche de modèles, la fourniture d’un meilleur traitement à l’avance pour les maladies, l’automatisation des diagnostics et l’obtention des détails les plus récents sur la santé d’un patient.
#3. Données en continu et IdO
Les lacs de données peuvent recevoir en continu des données en continu soumises à des pipelines d’analyse pour des rapports continus et la détection de toute activité et mouvement inhabituels. Cela est possible grâce à la capacité du lac de données à collecter des données en temps (presque) réel.
Voici quelques cas d’utilisation de l’entrepôt de données :
#1. Finance
Les informations financières d’une entreprise peuvent être plus adaptées à un entrepôt de données. Les employés peuvent facilement accéder à des informations organisées et structurées sous forme de graphiques et de rapports pour gérer les processus financiers, gérer les risques et prendre des décisions stratégiques.
#2. Marketing et segmentation clientèle
L’entrepôt de données crée une source unique de « vérité » ou de données correctes sur les clients collectées à partir de plusieurs sources. Les entreprises peuvent analyser ces données pour comprendre les comportements des clients, proposer des remises personnalisées, segmenter les clients en fonction de leurs préférences et générer davantage de prospects.
#3. Tableaux de bord et rapports de l’entreprise
De nombreuses entreprises utilisent des entrepôts de données CRM et ERP pour extraire des données sur les clients externes et internes. Les données sont toujours pertinentes et fiables pour créer tout type de rapport et de visualisation.
#4. Migrer des données à partir de systèmes hérités
En utilisant les capacités ETL des entrepôts de données, les entreprises peuvent facilement transformer les données système héritées en un format plus utilisable que les nouveaux systèmes peuvent analyser. Cela aidera les organisations à mieux comprendre les tendances historiques et à prendre des décisions commerciales précises.
Exemples d’outils Data Lake
Certains des principaux fournisseurs de lacs de données sont :
- Microsoft Azure – Azure peut stocker et analyser des pétaoctets de données. Azure facilite le débogage et l’optimisation des programmes Big Data.
- Google Cloud – Google Cloud offre une ingestion, un stockage et une analyse rentables d’énormes volumes de données volumineuses de tout type. Il s’intègre également à des outils d’analyse comme Apache Spark, BigQuery et d’autres accélérateurs d’analyse.
- Atlas MongoDB – Le lac de données Atlas est un magasin de lac de données entièrement géré. Il fournit des moyens rentables de stocker des données à grande échelle et peut exécuter des requêtes hautes performances qui utilisent moins de puissance de calcul, ce qui permet d’économiser du temps et de l’argent.
- AmazonS3 – Le cloud AWS fournit les outils nécessaires pour créer un lac de données flexible, sécurisé et rentable. Il dispose d’une console interactive pour gérer les utilisateurs du lac de données et contrôler l’accès aux utilisateurs.
Exemples d’outils d’entrepôt de données
Certains des principaux fournisseurs de solutions d’entrepôt de données sont :
- SÈVE – L’entrepôt de données SAP permet aux utilisateurs d’accéder sémantiquement à des données riches provenant de plusieurs sources. Les entreprises peuvent partager en toute sécurité des informations et des modèles, accélérer la prise de décision et combiner en toute sécurité des données externes et internes.
- ClicData – L’entrepôt de données intelligent et intégré de ClicData garantit l’intégrité, la qualité et la facilité des rapports des données. ClicData propose à la fois des systèmes de planification et des API en temps réel afin que vous puissiez obtenir des données mises à jour à tout moment.
- Redshift d’Amazon – L’un des entrepôts de données les plus utilisés, Redshift utilise SQL pour analyser tous les types de données présentes dans diverses bases de données, lacs ou autres entrepôts. Il offre un excellent équilibre entre coût et performance.
- Entrepôt IBM Db2 – IBM fournit des solutions d’entreposage de données internes, cloud et intégrées. Il intègre également des outils d’apprentissage automatique et d’intelligence artificielle pour une analyse plus approfondie des données et partage un moteur SQL commun pour rationaliser les requêtes.
- Entrepôt de données Oracle Cloud – Oracle utilise une base de données en mémoire et offre des capacités graphiques, d’apprentissage automatique et spatiales pour plonger en profondeur dans les données pour une analyse de données plus rapide mais plus riche.
Derniers mots
Les lacs de données et les entrepôts de données ont leurs propres avantages et cas d’utilisation idéaux. Alors que les lacs de données sont plus évolutifs et flexibles, les entrepôts de données disposent toujours d’informations fiables et structurées. La mise en œuvre du lac de données est relativement nouvelle, tandis que l’entrepôt de données est un concept établi utilisé par de nombreuses organisations pour gérer efficacement leurs données internes et externes.