

Le pipeline d’agrégation est le moyen recommandé pour exécuter des requêtes complexes dans MongoDB. Si vous utilisez MapReduce de MongoDB, vous feriez mieux de passer au pipeline d’agrégation pour des calculs plus efficaces.
Table des matières
Qu’est-ce que l’agrégation dans MongoDB et comment ça marche ?
Le pipeline d’agrégation est un processus en plusieurs étapes permettant d’exécuter des requêtes avancées dans MongoDB. Il traite les données à travers différentes étapes appelées pipeline. Vous pouvez utiliser les résultats générés à partir d’un niveau comme modèle d’opération dans un autre.
Par exemple, vous pouvez transmettre le résultat d’une opération de correspondance à une autre étape pour le trier dans cet ordre jusqu’à ce que vous obteniez le résultat souhaité.
Chaque étape d’un pipeline d’agrégation comporte un opérateur MongoDB et génère un ou plusieurs documents transformés. En fonction de votre requête, un niveau peut apparaître plusieurs fois dans le pipeline. Par exemple, vous devrez peut-être utiliser les étapes d’opérateur $count ou $sort plusieurs fois dans le pipeline d’agrégation.
Les étapes du pipeline d’agrégation
Le pipeline d’agrégation transmet les données à travers plusieurs étapes en une seule requête. Il y a plusieurs étapes et vous pouvez retrouver leurs détails dans la Documentation MongoDB.
Définissons ci-dessous quelques-uns des plus couramment utilisés.
L’étape $match
Cette étape vous aide à définir des conditions de filtrage spécifiques avant de démarrer les autres étapes d’agrégation. Vous pouvez l’utiliser pour sélectionner les données correspondantes que vous souhaitez inclure dans le pipeline d’agrégation.
La scène $group
L’étape de groupe sépare les données en différents groupes en fonction de critères spécifiques à l’aide de paires clé-valeur. Chaque groupe représente une clé dans le document de sortie.
Par exemple, considérons les exemples de données de ventes suivants :
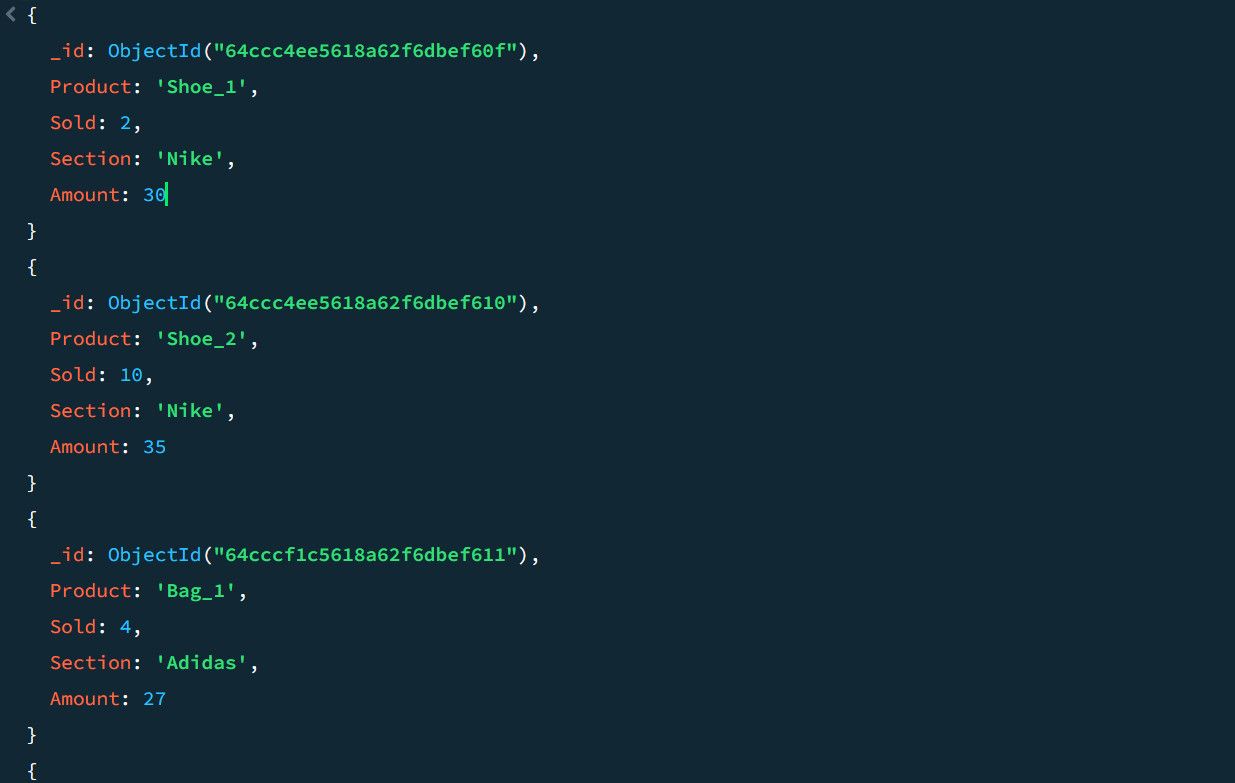
À l’aide du pipeline d’agrégation, vous pouvez calculer le nombre total de ventes et les meilleures ventes pour chaque section de produit :
{
$group: {
_id: $Section,
total_sales_count: {$sum : $Sold},
top_sales: {$max: $Amount},
}
} La paire _id : $Section regroupe le document de sortie en fonction des sections. En spécifiant les champs top_sales_count et top_sales, MongoDB crée de nouvelles clés basées sur l’opération définie par l’agrégateur ; cela peut être $sum, $min, $max ou $avg.
L’étape $skip
Vous pouvez utiliser l’étape $skip pour omettre un nombre spécifié de documents dans la sortie. Cela vient généralement après la phase de groupes. Par exemple, si vous attendez deux documents de sortie mais en ignorez un, l’agrégation ne produira que le deuxième document.
Pour ajouter une étape de saut, insérez l’opération $skip dans le pipeline d’agrégation :
...,
{
$skip: 1
},
L’étape du tri $
L’étape de tri vous permet de classer les données par ordre décroissant ou croissant. Par exemple, nous pouvons trier davantage les données de l’exemple de requête précédent par ordre décroissant pour déterminer quelle section a les ventes les plus élevées.
Ajoutez l’opérateur $sort à la requête précédente :
...,
{
$sort: {top_sales: -1}
},
L’étape $limite
L’opération de limitation permet de réduire le nombre de documents de sortie que vous souhaitez que le pipeline d’agrégation affiche. Par exemple, utilisez l’opérateur $limit pour obtenir la section avec les ventes les plus élevées renvoyées à l’étape précédente :
...,
{
$sort: {top_sales: -1}
},{"$limit": 1}
Ce qui précède renvoie uniquement le premier document ; il s’agit de la section avec les ventes les plus élevées, telle qu’elle apparaît en haut de la sortie triée.
L’étape $project
L’étape $project vous permet de façonner le document de sortie à votre guise. À l’aide de l’opérateur $project, vous pouvez spécifier le champ à inclure dans la sortie et personnaliser son nom de clé.
Par exemple, un exemple de sortie sans l’étape $project ressemble à ceci :
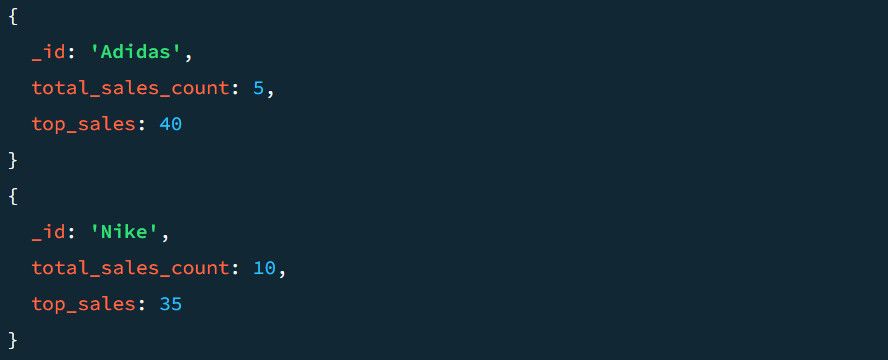
Voyons à quoi cela ressemble avec l’étape $project. Pour ajouter le $project au pipeline :
...,{
"$project": {
"_id": 0,
"Section": "$_id",
"TotalSold": "$total_sales_count",
"TopSale": "$top_sales",}
}
Puisque nous avons précédemment regroupé les données en fonction des sections de produits, ce qui précède inclut chaque section de produit dans le document de sortie. Il garantit également que le nombre de ventes agrégées et les meilleures ventes figurent dans la sortie sous la forme TotalSold et TopSale.
Le résultat final est beaucoup plus propre par rapport au précédent :

L’étape $détente
L’étape $unwind décompose un tableau d’un document en documents individuels. Prenons par exemple les données de commandes suivantes :
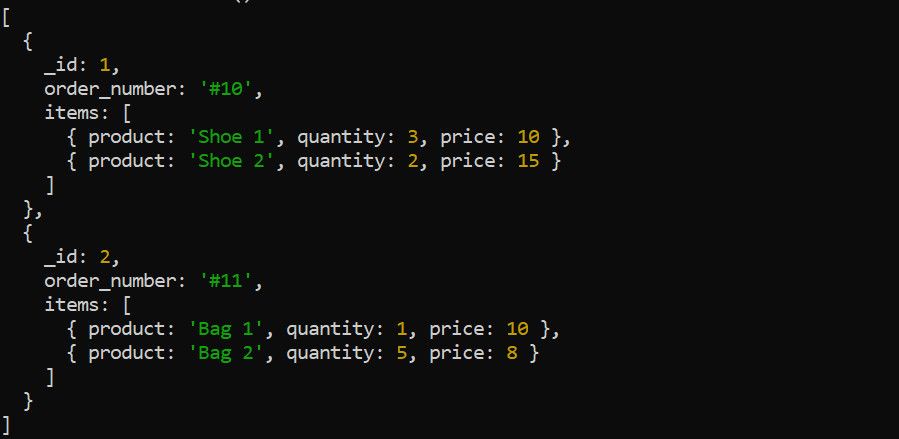
Utilisez l’étape $unwind pour déconstruire le tableau d’éléments avant d’appliquer d’autres étapes d’agrégation. Par exemple, dérouler le tableau items est logique si vous souhaitez calculer le revenu total pour chaque produit :
db.Orders.aggregate(
[
{
"$unwind": "$items"
},
{
"$group": {
"_id": "$items.product",
"total_revenue": { "$sum": { "$multiply": ["$items.quantity", "$items.price"] } }
}
},
{
"$sort": { "total_revenue": -1 }
},{
"$project": {
"_id": 0,
"Product": "$_id",
"TotalRevenue": "$total_revenue",}
}
])
Voici le résultat de la requête d’agrégation ci-dessus :

Comment créer un pipeline d’agrégation dans MongoDB
Bien que le pipeline d’agrégation comprenne plusieurs opérations, les étapes présentées précédemment vous donnent une idée de la façon de les appliquer dans le pipeline, y compris la requête de base pour chacune.
En utilisant l’exemple de données de ventes précédent, regroupons certaines des étapes décrites ci-dessus en un seul morceau pour une vue plus large du pipeline d’agrégation :
db.sales.aggregate([{
"$match": {
"Sold": { "$gte": 5 }
}
},{
"$group": {
"_id": "$Section",
"total_sales_count": { "$sum": "$Sold" },
"top_sales": { "$max": "$Amount" },
}},
{
"$sort": { "top_sales": -1 }
},{"$skip": 0},
{
"$project": {
"_id": 0,
"Section": "$_id",
"TotalSold": "$total_sales_count",
"TopSale": "$top_sales",}
}
])
Le résultat final ressemble à quelque chose que vous avez vu précédemment :
Pipeline d’agrégation et MapReduce
Jusqu’à sa dépréciation à partir de MongoDB 5.0, la manière conventionnelle d’agréger des données dans MongoDB était via MapReduce. Bien que MapReduce ait des applications plus larges que MongoDB, il est moins efficace que le pipeline d’agrégation, nécessitant des scripts tiers pour écrire la carte et réduire les fonctions séparément.
Le pipeline d’agrégation, en revanche, est spécifique à MongoDB uniquement. Mais il offre un moyen plus propre et plus efficace d’exécuter des requêtes complexes. Outre la simplicité et l’évolutivité des requêtes, les étapes de pipeline présentées rendent la sortie plus personnalisable.
Il existe de nombreuses autres différences entre le pipeline d’agrégation et MapReduce. Vous les verrez lorsque vous passerez de MapReduce au pipeline d’agrégation.
Rendre les requêtes Big Data efficaces dans MongoDB
Votre requête doit être la plus efficace possible si vous souhaitez exécuter des calculs approfondis sur des données complexes dans MongoDB. Le pipeline d’agrégation est idéal pour les requêtes avancées. Plutôt que de manipuler les données dans des opérations distinctes, ce qui réduit souvent les performances, l’agrégation vous permet de toutes les regrouper dans un seul pipeline performant et de les exécuter une seule fois.
Bien que le pipeline d’agrégation soit plus efficace que MapReduce, vous pouvez rendre l’agrégation plus rapide et plus efficace en indexant vos données. Cela limite la quantité de données que MongoDB doit analyser à chaque étape d’agrégation.