Comment utiliser le pipeline d'agrégation dans MongoDB
Pour l'exécution de requêtes complexes dans MongoDB, le pipeline d'agrégation est l'approche vivement recommandée. Si vous êtes encore en train d'utiliser MapReduce, il serait judicieux de migrer vers le pipeline d'agrégation pour des calculs plus performants.
Comprendre l'agrégation dans MongoDB et son fonctionnement
Le pipeline d'agrégation est un processus structuré en plusieurs étapes, conçu pour exécuter des requêtes sophistiquées au sein de MongoDB. Ce mécanisme traite les données à travers une série d'étapes consécutives, formant ce que l'on appelle un pipeline. Les résultats produits à chaque étape peuvent servir de base pour les opérations de l'étape suivante.
Par exemple, le résultat d'une opération de filtrage peut être transmis à une autre étape pour être trié. Cette approche permet d'affiner progressivement les données jusqu'à obtenir le résultat souhaité.
Chaque phase d'un pipeline d'agrégation fait appel à un opérateur spécifique de MongoDB, et génère un ou plusieurs documents transformés. Selon la nature de la requête, une même étape peut être utilisée plusieurs fois au sein du pipeline. Par exemple, les opérateurs $count ou $sort peuvent être employés à différents moments pour affiner le processus d'agrégation.
Les différentes étapes du pipeline d'agrégation
Le pipeline d'agrégation conduit les données à travers une séquence d'étapes, le tout en une seule requête. Ces étapes sont variées, et vous pouvez trouver des informations détaillées à leur sujet dans la documentation de MongoDB.
Voici une présentation de quelques-unes des étapes les plus fréquemment utilisées:
L'étape $match
Cette étape permet de définir des critères de filtrage précis avant de lancer les autres étapes d'agrégation. Elle est utilisée pour sélectionner uniquement les données qui correspondent aux conditions spécifiées et qui seront incluses dans le pipeline.
L'étape $group
L'étape de groupement permet de segmenter les données en groupes distincts, en utilisant des paires clé-valeur. Chaque groupe est identifié par une clé unique dans le document de sortie.
Prenons l'exemple de données de ventes suivantes :
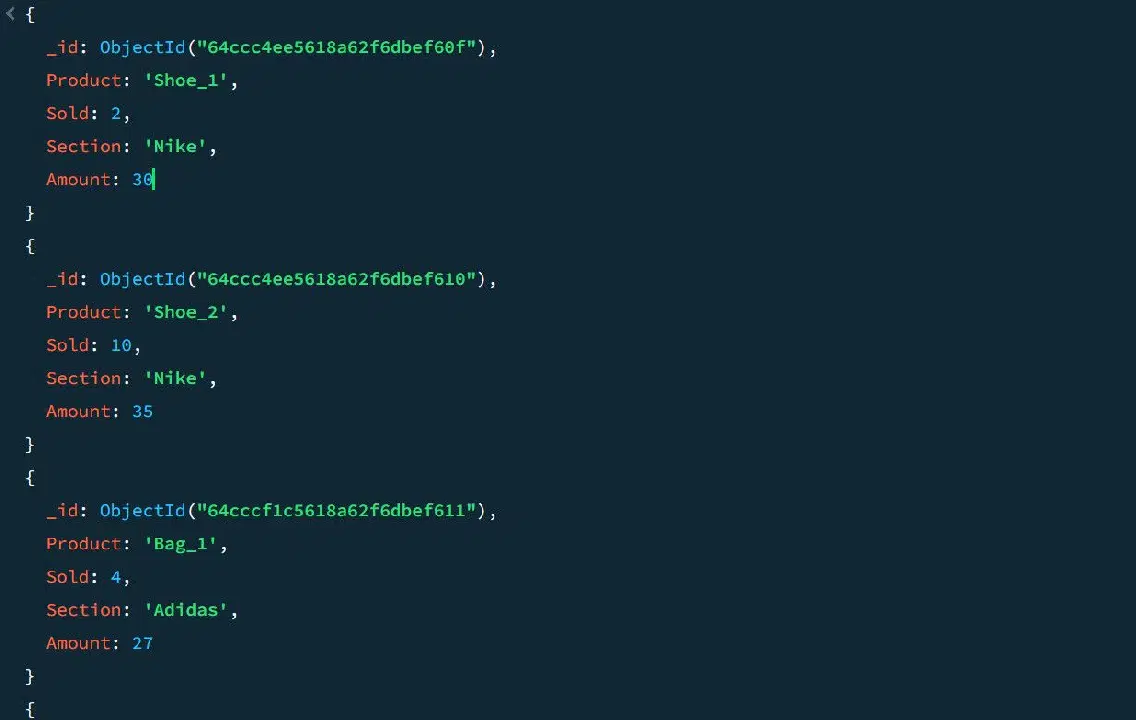
Grâce au pipeline d'agrégation, il est possible de calculer le nombre total de ventes et le montant de la meilleure vente pour chaque section de produits :
{
$group: {
_id: $Section,
total_sales_count: {$sum : $Sold},
top_sales: {$max: $Amount},
}
}
La paire _id : $Section a pour effet de regrouper les données de sortie en fonction des sections. En spécifiant les champs total_sales_count et top_sales, MongoDB crée de nouvelles clés en fonction de l'opération définie par l'agrégateur, qui peut être $sum, $min, $max ou $avg.
L'étape $skip
L'étape $skip permet d'ignorer un nombre déterminé de documents dans le résultat. Cette étape intervient souvent après la phase de groupement. Par exemple, si vous attendez deux documents en sortie, mais que vous souhaitez en exclure un, l'agrégation ne produira que le deuxième document.
Pour ajouter cette étape, il suffit d'inclure l'opérateur $skip dans le pipeline d'agrégation :
...,
{
$skip: 1
},
L'étape de tri $sort
L'étape de tri permet de classer les données en ordre croissant ou décroissant. Il est ainsi possible de trier les données de l'exemple précédent pour identifier la section ayant généré le plus de ventes, en ordre décroissant.
Pour ce faire, on ajoute l'opérateur $sort à la requête précédente :
...,
{
$sort: {top_sales: -1}
},
L'étape $limit
L'opération de limitation a pour but de réduire le nombre de documents affichés par le pipeline d'agrégation. Par exemple, en utilisant l'opérateur $limit, il est possible d'obtenir la section ayant généré le plus de ventes parmi celles triées à l'étape précédente :
...,
{
$sort: {top_sales: -1}
},
{"$limit": 1}
Cette opération ne renvoie que le premier document, qui correspond donc à la section ayant le plus haut niveau de ventes après le tri.
L'étape $project
L'étape $project offre la possibilité de façonner le document de sortie à votre guise. Cet opérateur vous permet de sélectionner les champs à inclure dans la sortie et de personnaliser les noms de clés.
Voici à quoi peut ressembler un résultat sans l'étape $project :
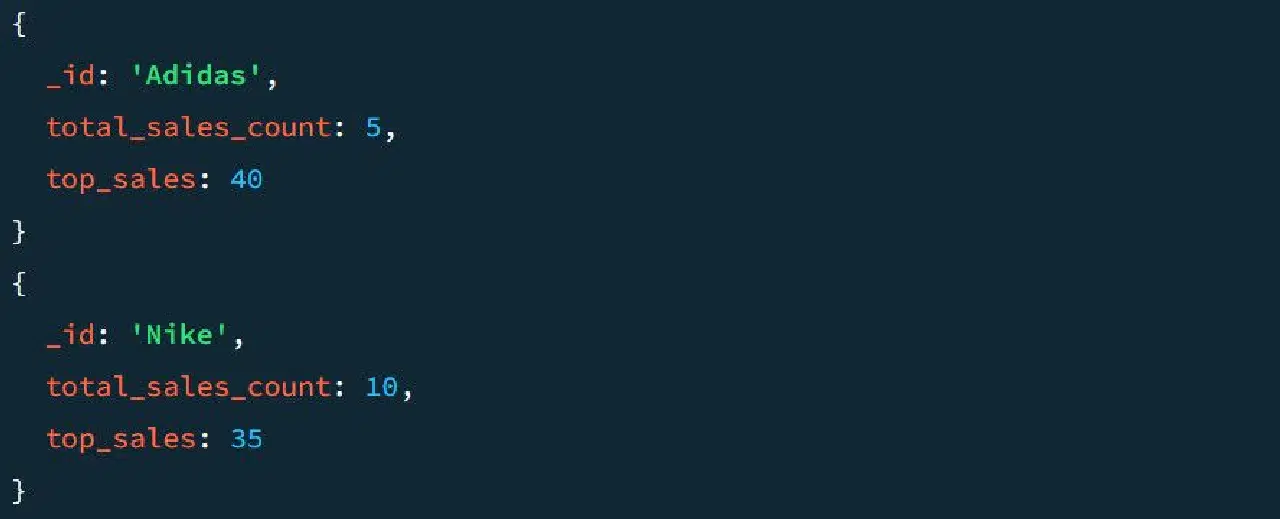
Voyons maintenant le résultat avec l'étape $project. Pour ajouter cette étape au pipeline :
...,
{
"$project": {
"_id": 0,
"Section": "$_id",
"TotalSold": "$total_sales_count",
"TopSale": "$top_sales",
}
}
Étant donné que les données ont été précédemment regroupées par section, cette configuration garantit que chaque section de produits apparaît dans le document de sortie. Elle assure également que le nombre de ventes agrégées et les meilleures ventes soient disponibles dans la sortie, sous les noms TotalSold et TopSale.
Le résultat final est beaucoup plus clair qu'avant :

L'étape $unwind
L'étape $unwind décompose un tableau au sein d'un document en documents individuels. Prenons l'exemple des données de commandes suivantes :
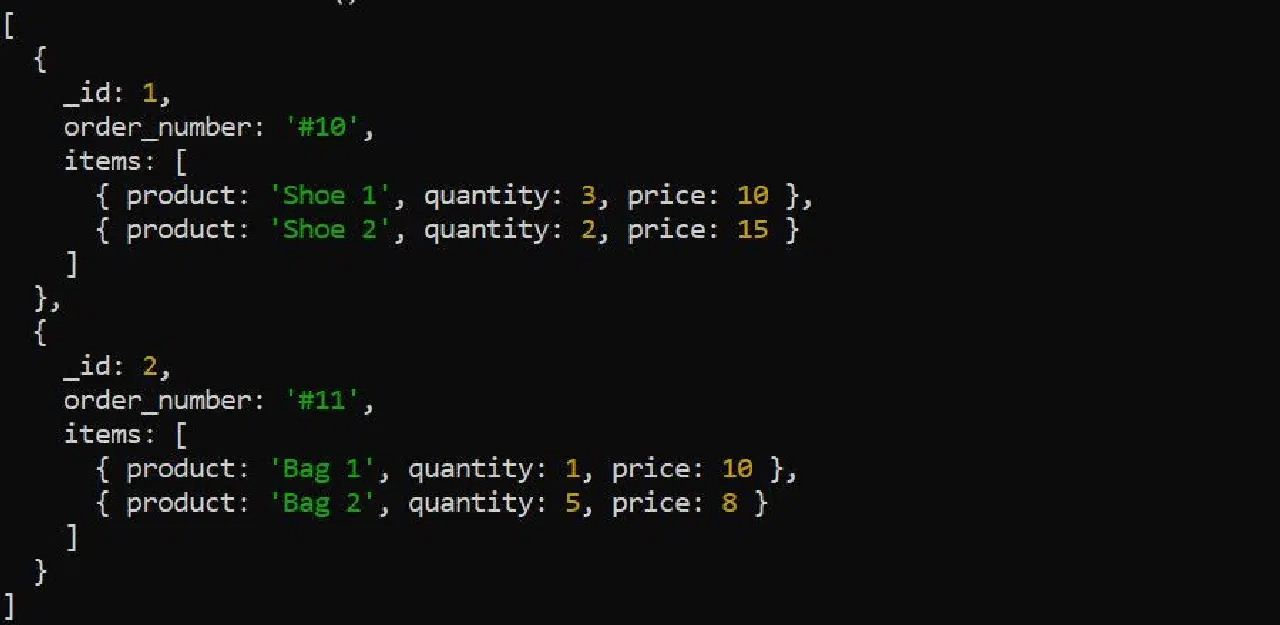
L'étape $unwind permet de décomposer le tableau d'éléments avant d'appliquer les autres étapes d'agrégation. Il est par exemple pertinent de dérouler le tableau items pour calculer le revenu total par produit :
db.Orders.aggregate(
[
{
"$unwind": "$items"
},
{
"$group": {
"_id": "$items.product",
"total_revenue": { "$sum": { "$multiply": ["$items.quantity", "$items.price"] } }
}
},
{
"$sort": { "total_revenue": -1 }
},
{
"$project": {
"_id": 0,
"Product": "$_id",
"TotalRevenue": "$total_revenue",
}
}
])
Voici le résultat de la requête d'agrégation ci-dessus :

Comment mettre en place un pipeline d'agrégation dans MongoDB
Bien que le pipeline d'agrégation soit composé de nombreuses opérations, les étapes que nous venons de présenter vous donnent une idée de leur application au sein du pipeline, ainsi que la requête de base pour chacune d'elles.
En reprenant l'exemple des données de ventes, nous allons regrouper certaines des étapes décrites précédemment afin d'obtenir une vision plus globale du pipeline d'agrégation :
db.sales.aggregate([
{
"$match": {
"Sold": { "$gte": 5 }
}
},
{
"$group": {
"_id": "$Section",
"total_sales_count": { "$sum": "$Sold" },
"top_sales": { "$max": "$Amount" },
}
},
{
"$sort": { "top_sales": -1 }
},
{"$skip": 0},
{
"$project": {
"_id": 0,
"Section": "$_id",
"TotalSold": "$total_sales_count",
"TopSale": "$top_sales",
}
}
])
Le résultat final ressemble à ce que nous avons déjà obtenu précédemment :
Comparaison entre le pipeline d'agrégation et MapReduce
Avant sa dépréciation à partir de MongoDB 5.0, l'approche habituelle pour l'agrégation de données était MapReduce. Bien que MapReduce ait des applications plus vastes que MongoDB, il est moins efficace que le pipeline d'agrégation. Il requiert des scripts tiers pour écrire les fonctions map et reduce séparément.
Le pipeline d'agrégation, en revanche, est une fonctionnalité propre à MongoDB. Il offre une manière plus simple et plus efficace d'exécuter des requêtes complexes. En plus de la simplicité et de l'évolutivité des requêtes, les étapes du pipeline présentées permettent de personnaliser le résultat de manière plus précise.
Il existe de nombreuses autres différences entre le pipeline d'agrégation et MapReduce. Ces différences deviendront apparentes lors de votre migration de MapReduce vers le pipeline d'agrégation.
Optimiser les requêtes Big Data dans MongoDB
Pour exécuter des calculs complexes sur des données volumineuses dans MongoDB, il est essentiel que vos requêtes soient aussi efficaces que possible. Le pipeline d'agrégation est un outil idéal pour les requêtes avancées. Plutôt que de manipuler les données par le biais d'opérations séparées, ce qui peut nuire à la performance, l'agrégation permet de regrouper toutes ces opérations au sein d'un seul pipeline performant, et de les exécuter en une seule fois.
Bien que le pipeline d'agrégation soit plus efficace que MapReduce, il est possible d'améliorer encore son efficacité en indexant vos données. Ceci a pour effet de limiter la quantité de données que MongoDB doit analyser à chaque étape d'agrégation.