Comment renommer en bloc des fichiers en noms de fichiers numériques sous Linux - -
Souhaitez-vous attribuer une séquence numérique à une série de fichiers (1.pdf, 2.pdf, 3.pdf, etc.) sous Linux ? C'est tout à fait réalisable grâce à quelques scripts simples, et cet article vous dévoilera précisément comment procéder.
Attribution de noms numériques aux fichiers
Il est fréquent que les fichiers PDF numérisés, qu'ils proviennent d'un appareil mobile ou d'un scanner, soient nommés selon un format tel que : 2020_11_28_13_43_00.pdf. De nombreux systèmes automatisés génèrent des noms de fichiers similaires, basés sur la date et l'heure.
Le nom d'un fichier peut également inclure des informations telles que l'application utilisée, la résolution en DPI (points par pouce) ou le format de papier lors de la numérisation.
Lorsque l'on collecte des fichiers PDF de diverses sources, les conventions de nommage peuvent varier considérablement. Il peut donc être judicieux de standardiser les noms de fichiers en utilisant une numérotation, partielle ou complète.
Ce besoin s'étend à d'autres types de fichiers : recettes, collections de photos, données issues de systèmes de surveillance, fichiers journaux destinés à l'archivage, ensembles de fichiers SQL pour les ingénieurs de bases de données, et de manière générale, toutes les données provenant de différentes sources avec des schémas de nommage hétérogènes.
Renommer des fichiers en masse avec une numérotation
Sous Linux, il est aisé de renommer un ensemble de fichiers en une séquence numérique. Bien que l'exécution soit simple, la programmation du renommage massif de fichiers en nombres est intrinsèquement complexe. Le script suivant, par exemple, a nécessité 3 à 4 heures de recherche, de création et de tests. De nombreuses autres commandes essayées présentaient des limitations que j'ai souhaité éviter.
Veuillez noter qu'aucune garantie n'est donnée. Ce code est fourni tel quel. Il est important de faire vos propres recherches avant de l'utiliser. Cela étant dit, je l'ai testé avec succès sur des fichiers contenant divers caractères spéciaux, ainsi que sur plus de 50 000 fichiers, sans aucune perte. J'ai également vérifié un fichier nommé 'a'$'n''a.pdf' incluant un saut de ligne.
if [ ! -r _e -a ! -r _c ]; then echo 'pdf' > _e; echo 1 > _c ;find . -name "*.$(cat _e)" -print0 | xargs -0 -I{} bash -c 'mv -n "{}" $(cat _c).$(cat _e);echo $[ $(cat _c) + 1 ] > _c'; rm -f _e _c; fi
Examinons d'abord son fonctionnement, puis décortiquons la commande. Supposons un répertoire contenant huit fichiers, tous avec l'extension .pdf, mais avec des noms variés. L'exécution de la commande ci-dessus entraîne le renommage des fichiers en 1.pdf, 2.pdf, 3.pdf, etc.

Si des fichiers nommés 1.pdf à x.pdf existent déjà, il est conseillé de les déplacer dans un répertoire séparé, d'ajuster la commande (echo 1) à un nombre plus élevé pour démarrer la numérotation des fichiers restants à un décalage donné, puis de fusionner les deux répertoires.
La prudence est de mise pour éviter l'écrasement de fichiers. Il est toujours recommandé d'effectuer une sauvegarde rapide avant toute modification.
Analysons maintenant la commande en détail. L'ajout de l'option -t à xargs nous permet de visualiser ce qui se passe en coulisses :
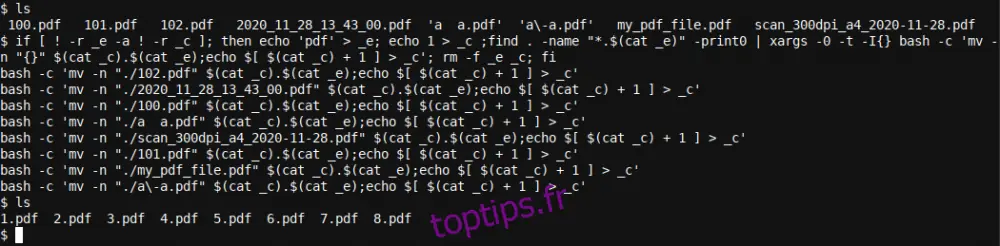
Pour commencer, la commande utilise deux fichiers temporaires (_e et _c) pour le stockage temporaire. Un contrôle de sécurité est effectué au début du script avec une instruction if pour vérifier l'absence de ces fichiers. Si l'un d'eux existe déjà, le script s'arrête.
Quant à l'utilisation de fichiers temporaires plutôt que de variables, j'ai rencontré deux problèmes :
Le premier est qu'une variable exportée au début d'une commande, et réutilisée ensuite, peut causer des interférences si un autre script utilise la même variable (y compris si ce script est exécuté plusieurs fois simultanément). Il est donc préférable d'éviter de telles interférences lors du renommage de nombreux fichiers.
Le second est que xargs combiné avec bash -c semble limiter la gestion des variables dans la ligne de commande bash -c. Malgré des recherches approfondies en ligne, aucune solution viable n'a été trouvée. L'utilisation d'un fichier temporaire _c qui incrémente à chaque itération s'est donc avérée nécessaire.
_e représente l'extension que nous allons rechercher et utiliser, tandis que _c est un compteur qui s'incrémente à chaque renommage. Le code echo $[ $(cat _c) + 1 ] > _c permet de récupérer la valeur actuelle du compteur avec cat, de l'incrémenter de un, puis de la réécrire dans le fichier.
Enfin, cette commande utilise la méthode la plus appropriée pour gérer les caractères spéciaux dans les noms de fichiers en utilisant la terminaison nulle plutôt que la terminaison de nouvelle ligne standard.