Apache Hive vs Apache Impala : Différences majeures
Si vous vous lancez dans l'exploration de l'analyse de données de grande envergure, la suite d'outils Apache pourrait attirer votre attention. Cependant, la complexité liée à l'utilisation de multiples outils peut s'avérer confuse, voire intimidante.
Cet article a pour objectif de clarifier cette confusion et d'expliquer les spécificités d'Apache Hive et d'Impala, en mettant en lumière leurs différences fondamentales.
Présentation d'Apache Hive
Apache Hive est une interface SQL permettant d'accéder aux données au sein de la plateforme Apache Hadoop. Hive vous donne la possibilité d'interroger, d'agréger et d'analyser des données en utilisant la syntaxe SQL.
Un schéma de lecture est utilisé pour les données stockées dans le système de fichiers HDFS, vous permettant de manipuler ces données comme s'il s'agissait d'une table standard ou d'un SGBD relationnel. Les requêtes HiveQL sont transformées en code Java pour les tâches MapReduce.
Les requêtes Hive sont écrites à l'aide du langage de requête HiveQL, qui s'inspire du SQL mais ne prend pas entièrement en charge la norme SQL-92.
Ce langage offre néanmoins aux développeurs la possibilité d'utiliser leurs propres requêtes lorsque l'usage des fonctionnalités de HiveQL s'avère inadapté ou inefficace. HiveQL peut être enrichi par des fonctions scalaires définies par l'utilisateur (UDF), des agrégations (UDAF) et des fonctions de table (UDTF).
Fonctionnement d'Apache Hive
Apache Hive convertit les instructions écrites en langage HiveQL (proche du SQL) en une ou plusieurs tâches MapReduce, Apache Tez ou Apache Spark. Ces trois moteurs d'exécution peuvent être lancés sur Hadoop. Ensuite, Apache Hive organise les données sous forme de table afin que le Hadoop Distributed File System (HDFS) puisse exécuter les tâches sur un cluster et fournir une réponse.
Les tables Apache Hive présentent des similitudes avec les bases de données relationnelles, avec les unités de données organisées de la plus significative à la plus granulaire. Les bases de données sont structurées en tables, divisées en partitions, elles-mêmes subdivisées en "buckets".
L'accès aux données se fait via HiveQL. Au sein de chaque base de données, les données sont numérotées, chaque table étant associée à un répertoire HDFS.
L'architecture Apache Hive propose diverses interfaces, comme une interface web, une CLI, ou encore des clients externes.
Le serveur "Apache Hive Thrift" permet aux clients distants de soumettre des commandes et des requêtes à Apache Hive en utilisant différents langages de programmation. Le répertoire central d'Apache Hive est un "metastore" qui regroupe toutes les informations essentielles.
Le moteur qui anime Hive est appelé "le pilote". Il inclut un compilateur et un optimiseur, chargés de déterminer le plan d'exécution le plus efficace.
La sécurité est gérée par Hadoop, qui s'appuie sur Kerberos pour l'authentification mutuelle entre le client et le serveur. L'autorisation pour les fichiers nouvellement créés dans Apache Hive est gérée par HDFS, avec des autorisations accordées à l'utilisateur, au groupe ou selon d'autres paramètres.
Caractéristiques clés de Hive
- Supporte les moteurs de calcul Hadoop et Spark
- Utilise HDFS et fonctionne comme un entrepôt de données
- Exploite MapReduce et prend en charge l'ETL
- Bénéficie de la tolérance aux pannes de Hadoop grâce à HDFS
Avantages d'Apache Hive
Apache Hive représente une solution idéale pour les requêtes et l'analyse de données, offrant des informations qualitatives essentielles. Il permet d'obtenir un avantage concurrentiel et d'améliorer la réactivité face aux exigences du marché.
Parmi les avantages majeurs d'Apache Hive, on note sa facilité d'utilisation grâce à son langage proche du SQL. De plus, l'insertion initiale des données est accélérée car celles-ci n'ont pas besoin d'être lues ou indexées à partir d'un disque dans un format de base de données interne.
Puisque les données sont stockées dans HDFS, il est possible de gérer de très grands ensembles de données, pouvant atteindre des centaines de pétaoctets. Cette solution est bien plus évolutive qu'une base de données traditionnelle. Fonctionnant comme un service cloud, Apache Hive permet aux utilisateurs de lancer rapidement des serveurs virtuels en fonction des fluctuations de la charge de travail.
La sécurité est également un point fort de Hive, avec sa capacité à répliquer les charges de travail critiques pour la récupération en cas de problème. Enfin, sa capacité de traitement est exceptionnelle puisqu'il peut effectuer jusqu'à 100 000 requêtes par heure.
Présentation d'Apache Impala
Apache Impala est un moteur de requêtes SQL massivement parallèle conçu pour l'exécution interactive de requêtes SQL sur des données stockées dans Apache Hadoop. Il est écrit en C++ et distribué sous licence Apache 2.0.
Impala est également qualifié de moteur MPP (Massively Parallel Processing), de SGBD distribué, voire de base de données de pile SQL sur Hadoop.

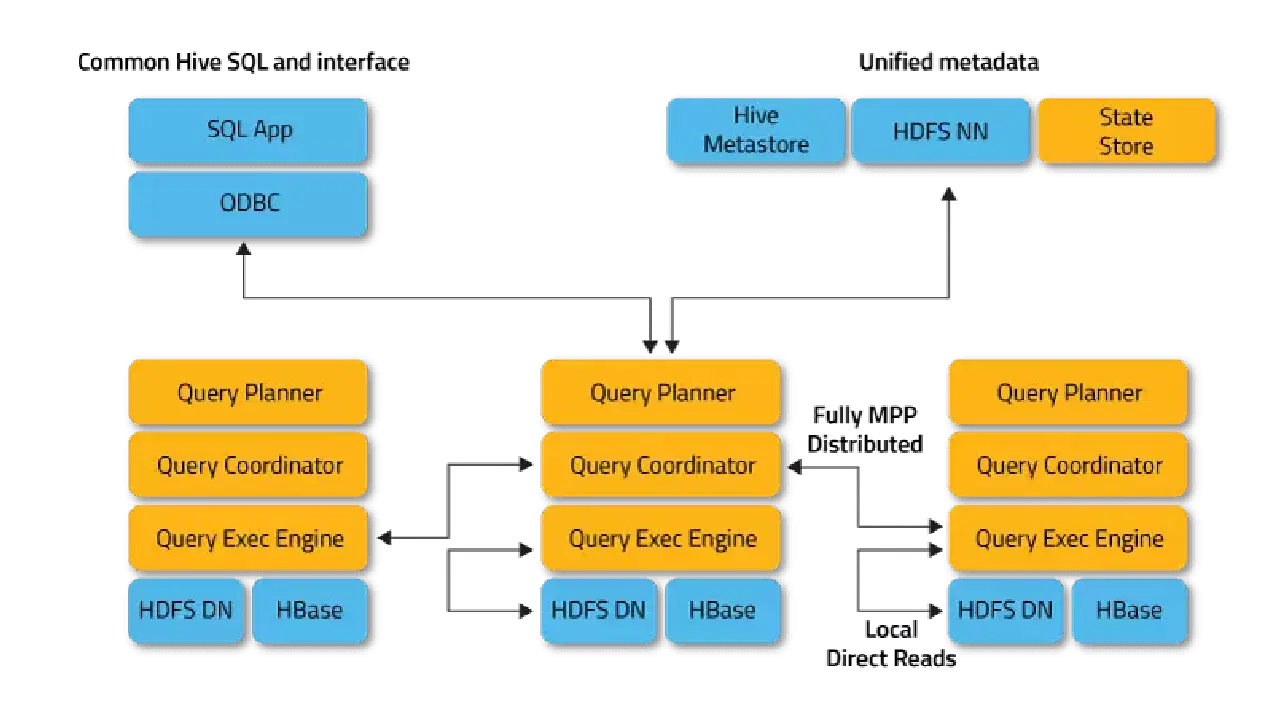
Impala fonctionne en mode distribué, avec des instances de processus qui s'exécutent sur divers nœuds du cluster, en recevant, planifiant et coordonnant les requêtes des clients. L'exécution parallèle de parties de la requête SQL est ainsi rendue possible.
Les clients sont des utilisateurs et des applications qui envoient des requêtes SQL sur des données stockées dans Apache Hadoop (HBase et HDFS) ou Amazon S3. L'interaction avec Impala s'effectue via l'interface Web HUE (Hadoop User Experience), ODBC, JDBC et le shell en ligne de commande Impala Shell.
Impala dépend de l'infrastructure d'un autre outil SQL-on-Hadoop populaire, Apache Hive, en utilisant son magasin de métadonnées. Le Hive Metastore permet notamment à Impala de connaître la disponibilité et la structure des bases de données.
Lors de la création, de la modification et de la suppression d'objets de schéma ou du chargement de données dans des tables via des instructions SQL, les modifications de métadonnées sont automatiquement propagées à tous les nœuds Impala grâce à un service d'annuaire spécifique.
Les principaux composants d'Impala sont les exécutables suivants :
- Le démon Impalad ou Impala est un service système qui planifie et exécute les requêtes sur les données HDFS, HBase et Amazon S3. Un processus impalad s'exécute sur chaque nœud du cluster.
- Statestore est un service de nommage qui assure le suivi de l'emplacement et de l'état de toutes les instances d'impalad dans le cluster. Une instance de ce service système s'exécute sur chaque nœud et sur le serveur principal (nœud maître).
- Le catalogue est un service de coordination des métadonnées qui propage les modifications des instructions Impala DDL et DML à tous les nœuds Impala concernés, de sorte que les nouvelles tables ou les données nouvellement chargées soient immédiatement accessibles à tous les nœuds du cluster. Il est conseillé qu'une instance de Catalog soit exécutée sur le même hôte de cluster que le démon Statestored.
Fonctionnement d'Apache Impala
Impala, à l'instar d'Apache Hive, utilise un langage de requête déclaratif similaire, Hive Query Language (HiveQL), qui est un sous-ensemble de SQL92, au lieu du SQL complet.
L'exécution effective d'une requête dans Impala se déroule comme suit :
L'application cliente soumet une requête SQL en se connectant à n'importe quel impalad via des interfaces de pilote ODBC ou JDBC standardisées. L'impalad connecté devient le coordinateur de la requête en cours.
La requête SQL est analysée afin de déterminer les tâches pour les instances d'impalad dans le cluster. Le plan d'exécution optimal de la requête est alors établi.
Impalad accède directement à HDFS et HBase en utilisant des instances locales des services système pour obtenir les données. Contrairement à Apache Hive, cette interaction directe réduit considérablement le temps d'exécution des requêtes, car les résultats intermédiaires ne sont pas sauvegardés.
En réponse, chaque démon renvoie des données à l'impalad de coordination, qui transmet ensuite les résultats au client.
Caractéristiques clés d'Impala
- Supporte le traitement en mémoire en temps réel
- Compatible avec SQL
- Gère les systèmes de stockage comme HDFS, Apache HBase et Amazon S3
- Permet l'intégration avec des outils de BI tels que Pentaho et Tableau
- Utilise la syntaxe HiveQL
Avantages d'Apache Impala
Impala élimine tout temps de démarrage superflu car tous les processus du démon système sont initialisés directement au démarrage. Il réduit considérablement le temps d'exécution des requêtes. L'augmentation de la vitesse d'Impala est également due au fait que cet outil SQL pour Hadoop, contrairement à Hive, ne stocke pas les résultats intermédiaires et accède directement à HDFS ou HBase.
De plus, Impala génère le code de programme à l'exécution et non à la compilation, comme le fait Hive. Cependant, un effet secondaire des performances à grande vitesse d'Impala est une fiabilité réduite.
En effet, si un nœud de données tombe en panne pendant l'exécution d'une requête SQL, l'instance Impala redémarrera alors que Hive maintiendra la connexion à la source de données, assurant une meilleure tolérance aux pannes.
Les autres avantages d'Impala incluent la prise en charge intégrée du protocole d'authentification réseau sécurisé Kerberos, la hiérarchisation et la gestion de la file d'attente des requêtes, ainsi que la compatibilité avec des formats Big Data populaires tels que LZO, Avro, RCFile, Parquet et Sequence.
Similitudes entre Hive et Impala
Hive et Impala sont distribués gratuitement sous licence Apache Software Foundation et sont considérés comme des outils SQL pour la manipulation de données stockées dans un cluster Hadoop. De plus, tous deux utilisent le système de fichiers distribué HDFS.
Impala et Hive ont pour but commun le traitement SQL de grandes quantités de données stockées dans un cluster Apache Hadoop. Impala fournit une interface de type SQL, permettant la lecture et l'écriture de tables Hive, facilitant ainsi l'échange de données.
Dans le même temps, Impala accélère les opérations SQL sur Hadoop, ce qui permet d'utiliser ce SGBD dans des projets de recherche d'analyse de Big Data. Autant que possible, Impala utilise l'infrastructure Apache Hive existante, déjà utilisée pour exécuter des requêtes SQL par lot de longue durée.
De plus, Impala stocke ses définitions de table dans un metastore, une base de données MySQL ou PostgreSQL classique, c'est-à-dire au même endroit où Hive stocke des données similaires. Cela permet à Impala d'accéder aux tables Hive tant que toutes les colonnes utilisent des types de données, des formats de fichiers et des codecs de compression pris en charge par Impala.
Différences entre Hive et Impala

Langage de programmation
Hive est développé en Java, tandis qu'Impala est écrit en C++. Cependant, Impala utilise également certaines UDF Hive basées sur Java.
Cas d'utilisation
Les ingénieurs de données utilisent Hive pour les processus ETL (extraction, transformation, chargement), par exemple, pour les tâches par lots de longue durée sur de grands ensembles de données, comme dans les agrégateurs de voyages et les systèmes d'information aéroportuaires. Impala est davantage destiné aux analystes et aux scientifiques des données, et il est principalement utilisé pour des tâches comme la business intelligence.
Performance
Impala exécute les requêtes SQL en temps réel, tandis que Hive se caractérise par une faible vitesse de traitement des données. Pour des requêtes SQL simples, Impala peut s'exécuter de 6 à 69 fois plus rapidement que Hive. Cependant, Hive est plus performant pour les requêtes complexes.
Latence/débit
Le débit de Hive est nettement supérieur à celui d'Impala. La fonctionnalité LLAP (Live Long and Process), qui permet la mise en cache des requêtes en mémoire, confère à Hive de bonnes performances de bas niveau.
LLAP intègre des services système de longue durée (démons), ce qui permet d'interagir directement avec les nœuds de données HDFS et de remplacer la structure de requête DAG étroitement intégrée (graphe acyclique dirigé) – un modèle de graphe couramment utilisé dans le traitement Big Data.
Tolérance aux pannes
Hive est un système tolérant aux pannes qui conserve tous les résultats intermédiaires. Cela a un impact positif sur l'évolutivité, mais entraîne une diminution de la vitesse de traitement des données. Impala, quant à lui, ne peut pas être considéré comme une plateforme tolérante aux pannes, car il est davantage lié à la mémoire.
Conversion de code
Hive génère les expressions de requête au moment de la compilation, tandis qu'Impala les génère à l'exécution. Hive est caractérisé par un problème de "démarrage à froid" lors de la première exécution de l'application. Les requêtes sont converties lentement en raison de la nécessité d'établir une connexion à la source de données.
Impala ne présente pas ce type de surcharge de démarrage. Les services système nécessaires (démons) pour le traitement des requêtes SQL sont démarrés au lancement, ce qui accélère le processus.
Prise en charge du stockage
Impala prend en charge les formats LZO, Avro et Parquet, tandis que Hive fonctionne avec le texte brut et ORC. Les deux plateformes prennent cependant en charge les formats RCFIle et Sequence.
| Apache Hive | Apache Impala | |
| Langage | Java | C++ |
| Cas d'utilisation | Ingénierie des données | Analyse et analytique |
| Performance | Élevée pour les requêtes simples | Latence relativement faible |
| Latence | Plus de latence due à la mise en cache | Moins de latence |
| Tolérance aux pannes | Plus tolérant grâce à MapReduce | Moins tolérant grâce à MPP |
| Conversion | Lente en raison du démarrage à froid | Conversion plus rapide |
| Support de stockage | Texte brut et ORC | LZO, Avro, Parquet |
Derniers mots
Hive et Impala ne sont pas en concurrence mais se complètent efficacement. Bien qu'il existe des différences significatives entre les deux, ils ont aussi beaucoup de points communs. Le choix de l'un ou de l'autre dépend des données et des exigences spécifiques du projet.
Vous pouvez également explorer des comparaisons directes entre Hadoop et Spark.
.