Web Scraping avec Java expliqué en termes plus simples
L'extraction de données web, ou web scraping, est une technique efficace pour collecter rapidement de vastes ensembles de données disponibles sur internet. Elle s'avère particulièrement utile lorsque les sites web ne proposent pas leurs données de manière structurée via des interfaces de programmation (API).
Imaginez par exemple que vous développiez une application qui compare les tarifs d'articles sur diverses plateformes de commerce en ligne. Comment procéderiez-vous ? Une approche consisterait à vérifier manuellement le prix de chaque article sur tous les sites et à consigner vos observations. Cette méthode s'avère peu pratique étant donné la multitude de produits disponibles en ligne et le temps considérable qu'il faudrait pour extraire les données essentielles.
Une stratégie plus judicieuse consiste à utiliser le web scraping. Il s'agit d'un processus d'extraction automatisée de données à partir de pages et de sites web grâce à un logiciel spécifique.
Des scripts logiciels, désignés comme "web scrapers", sont employés pour accéder aux sites web et collecter les informations qu'ils contiennent. Ces données, initialement sous forme non structurée, peuvent ensuite être analysées et organisées de manière logique et significative pour les utilisateurs.
Le web scraping est un outil précieux pour l'extraction de données. Il donne accès à une quantité importante d'informations et permet l'automatisation. Ainsi, vous pouvez programmer l'exécution de votre script d'extraction à des moments précis ou en réponse à des événements spécifiques. Il facilite également l'obtention de mises à jour en temps réel et simplifie la réalisation d'études de marché.
De nombreuses organisations exploitent le web scraping pour extraire des données à des fins d'analyse. Les secteurs des ressources humaines, du commerce électronique, de la finance, de l'immobilier, du voyage, des médias sociaux et de la recherche utilisent cette technique pour collecter des informations pertinentes sur les sites web.
Même Google utilise le web scraping pour indexer les sites web sur internet afin de fournir des résultats de recherche pertinents aux utilisateurs.
Il est cependant crucial de faire preuve de prudence lors de l'extraction de données. Bien que la récupération de données accessibles publiquement ne soit pas illégale, certains sites web interdisent cette pratique. Cela peut être dû à la présence d'informations sensibles sur les utilisateurs, à des conditions d'utilisation interdisant explicitement l'extraction, ou à la protection de la propriété intellectuelle.
De plus, certains sites web n'autorisent pas le web scraping car il peut surcharger leurs serveurs et entraîner une augmentation des coûts de bande passante, notamment lorsque l'extraction est effectuée à grande échelle.
Pour vérifier si un site web autorise l'extraction de données, ajoutez "robots.txt" à la fin de son URL. Ce fichier indique aux robots d'exploration quelles parties du site web sont autorisées à être récupérées. Par exemple, pour vérifier si vous pouvez extraire des données de Google, accédez à "google.com/robots.txt".
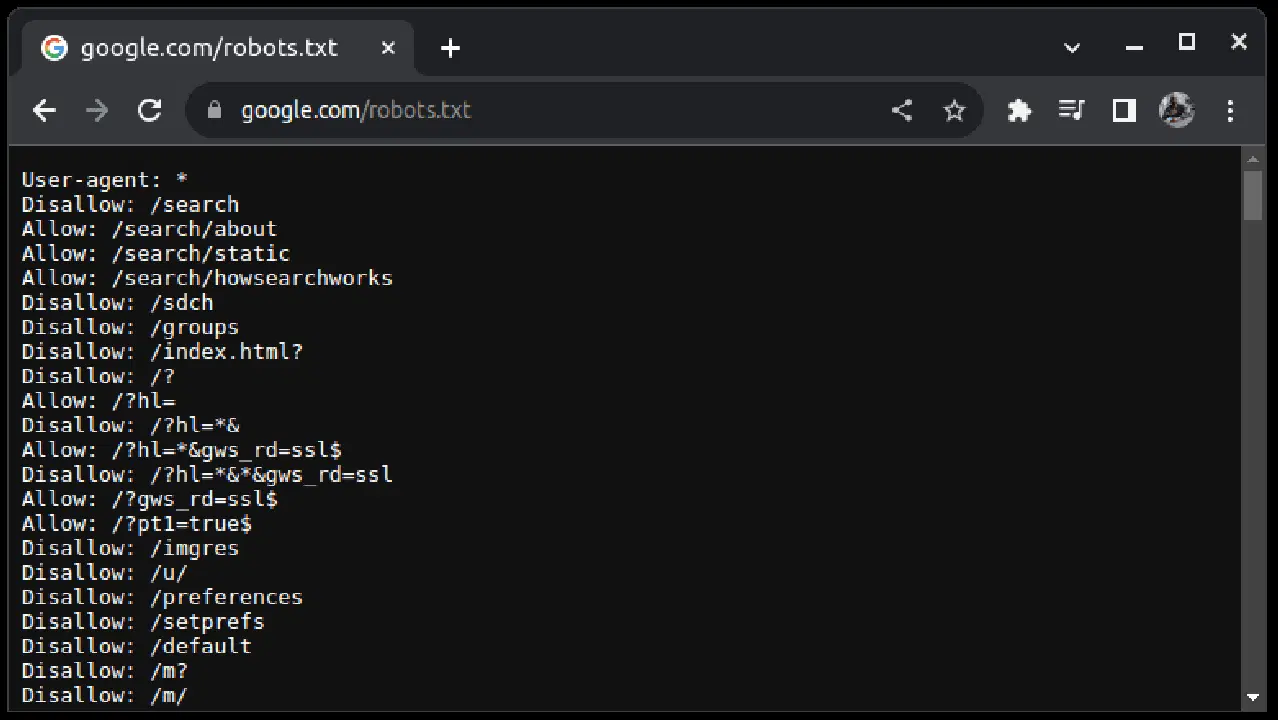
"Agent utilisateur : *" fait référence à tous les robots ou scripts d'exploration logiciels. "Disallow" indique aux robots qu'ils ne peuvent pas accéder à une URL dans un répertoire spécifique, tel que "/search". "Allow" spécifie les répertoires où ils peuvent accéder aux URL.
Un exemple de site n'autorisant pas le scraping est LinkedIn. Pour vérifier si vous pouvez extraire des données de LinkedIn, accédez à "linkedin.com/robots.txt".
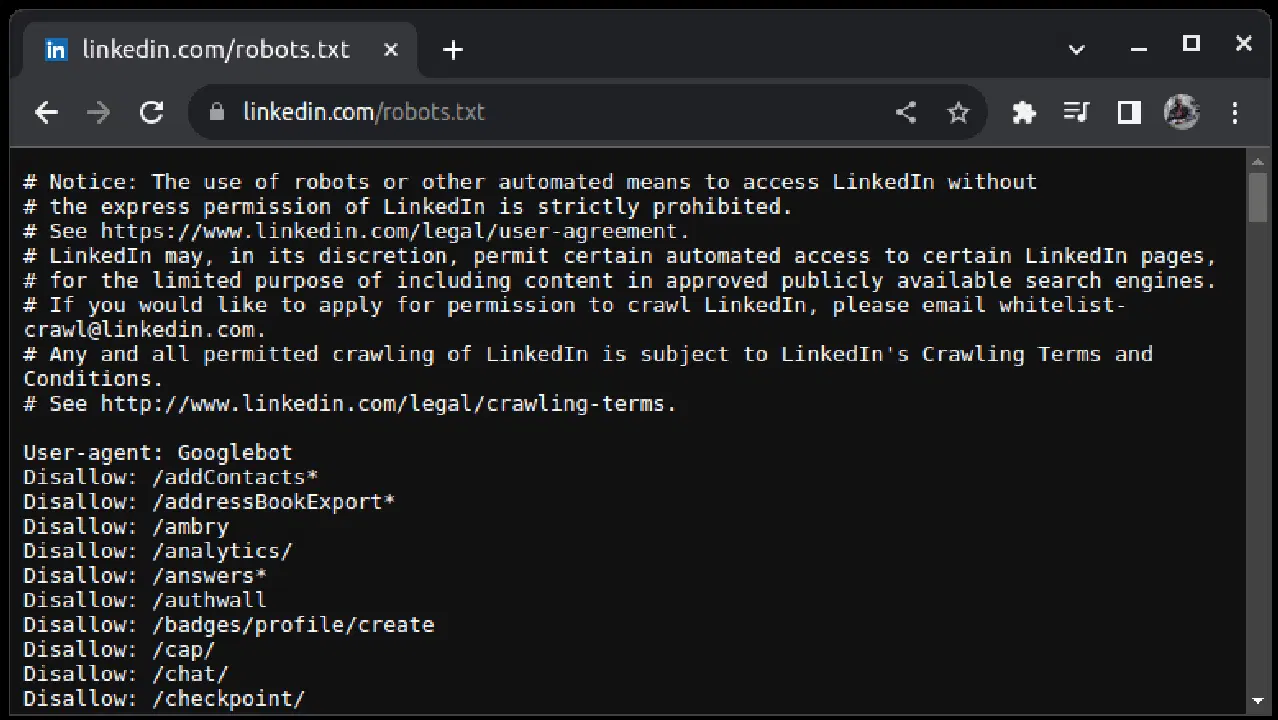
Comme vous pouvez le constater, l'extraction de données de LinkedIn n'est pas autorisée sans leur consentement. Vérifiez toujours si un site web autorise le scraping pour éviter tout problème légal.
Pourquoi Java est un langage adapté pour le Web Scraping
Bien qu'il soit possible de créer un scraper web avec divers langages de programmation, Java est particulièrement bien adapté à cette tâche pour plusieurs raisons. Premièrement, Java bénéficie d'un écosystème riche et d'une communauté étendue, offrant de nombreuses bibliothèques spécialisées dans le web scraping, telles que JSoup, WebMagic et HTMLUnit, qui simplifient l'écriture de scrapers.

De plus, il propose des bibliothèques d'analyse HTML pour simplifier le processus d'extraction de données à partir de documents HTML, ainsi que des bibliothèques réseau telles que HttpURLConnection pour effectuer des requêtes vers différentes URL de sites web.
La gestion de la concurrence et du multithreading par Java est également un avantage pour le web scraping. Elle permet un traitement et une gestion parallèles des tâches d'extraction avec de multiples requêtes, vous autorisant ainsi à scraper plusieurs pages simultanément. L'évolutivité étant l'un des principaux points forts de Java, vous pouvez facilement extraire des données de sites web à grande échelle grâce à un scraper écrit dans ce langage.
La prise en charge multiplateforme de Java est également un atout, car elle permet d'écrire un scraper web et de l'exécuter sur n'importe quel système doté d'une machine virtuelle Java compatible. Ainsi, vous pouvez écrire un scraper sur un système d'exploitation donné et l'exécuter sur un autre sans avoir à le modifier.
Java peut également être utilisé avec des navigateurs headless, tels que Headless Chrome, HTML Unit, Headless Firefox et PhantomJs. Un navigateur headless est un navigateur sans interface graphique. Ces navigateurs sont capables de simuler les interactions des utilisateurs et sont très utiles lors de l'extraction de données de sites web nécessitant de telles interactions.
Enfin, Java est un langage très répandu et populaire, bénéficiant d'un bon support et facilement intégrable à une variété d'outils tels que des bases de données et des frameworks de traitement de données. Cet avantage garantit que les outils nécessaires pour la récupération, le traitement et le stockage des données sont probablement compatibles avec Java.
Voyons maintenant comment nous pouvons utiliser Java pour l'extraction de données web.
Java pour le Web Scraping : Prérequis
Pour utiliser Java dans le web scraping, les prérequis suivants doivent être satisfaits :
1. **Java** : Java doit être installé, de préférence la dernière version LTS. Si Java n'est pas installé, consultez un guide pour apprendre comment l'installer sur votre machine.
2. **Environnement de développement intégré (IDE)** : Un IDE doit être installé sur votre ordinateur. Dans ce tutoriel, nous utiliserons IntelliJ IDEA, mais vous pouvez utiliser l'IDE de votre choix.
3. **Maven** : Il servira à la gestion des dépendances et à l'installation d'une bibliothèque de web scraping.
Si Maven n'est pas installé, vous pouvez l'installer en ouvrant le terminal et en exécutant la commande suivante :
sudo apt install maven
Cela installera Maven à partir du référentiel officiel. Vous pouvez vérifier si Maven a été installé avec succès en exécutant :
mvn -version
Si l'installation a réussi, vous devriez obtenir un résultat similaire à celui-ci :
Configuration de l'environnement
Pour configurer votre environnement :
1. Ouvrez IntelliJ IDEA. Dans la barre de menu à gauche, cliquez sur "Projets", puis sélectionnez "Nouveau projet".
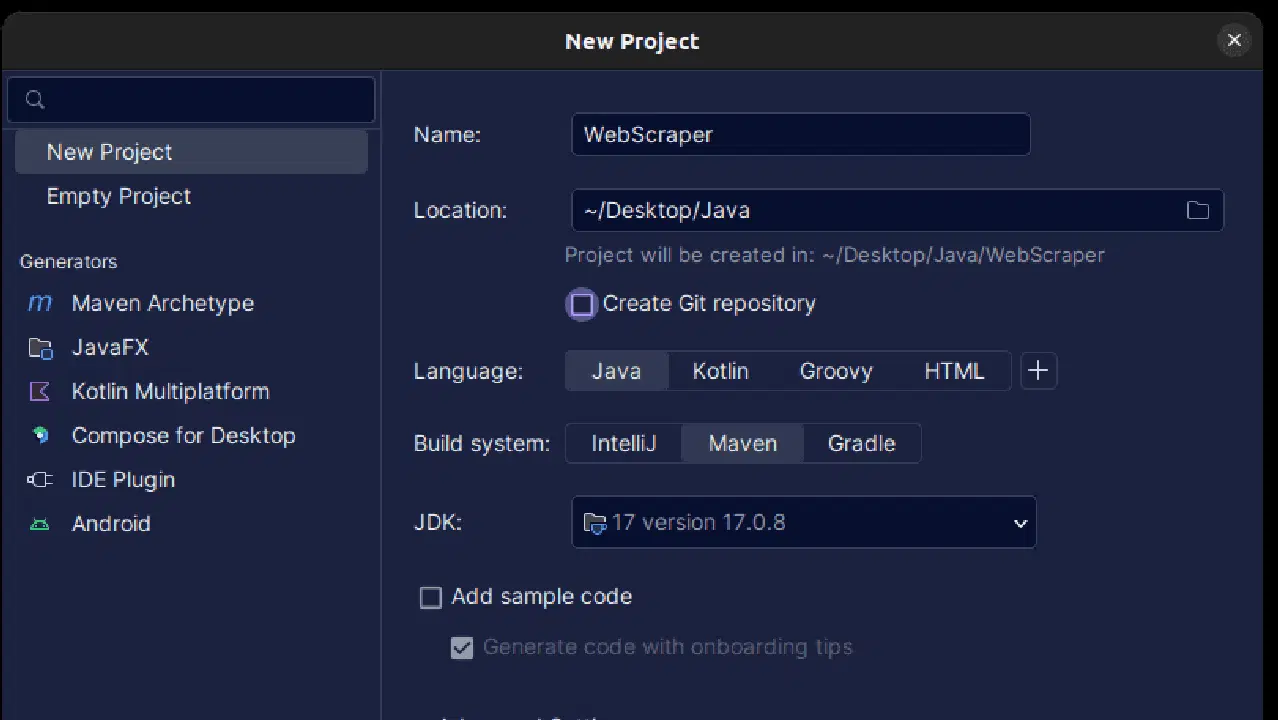
2. Dans la fenêtre "Nouveau projet" qui s'ouvre, remplissez les champs comme indiqué ci-dessous. Assurez-vous que la langue est définie sur "Java" et que le système de construction est "Maven". Vous pouvez donner le nom de votre choix au projet et utiliser "Emplacement" pour spécifier le dossier où vous souhaitez créer le projet. Une fois terminé, cliquez sur "Créer".
3. Une fois votre projet créé, vous devriez avoir un fichier "pom.xml" dans votre projet comme indiqué ci-dessous.
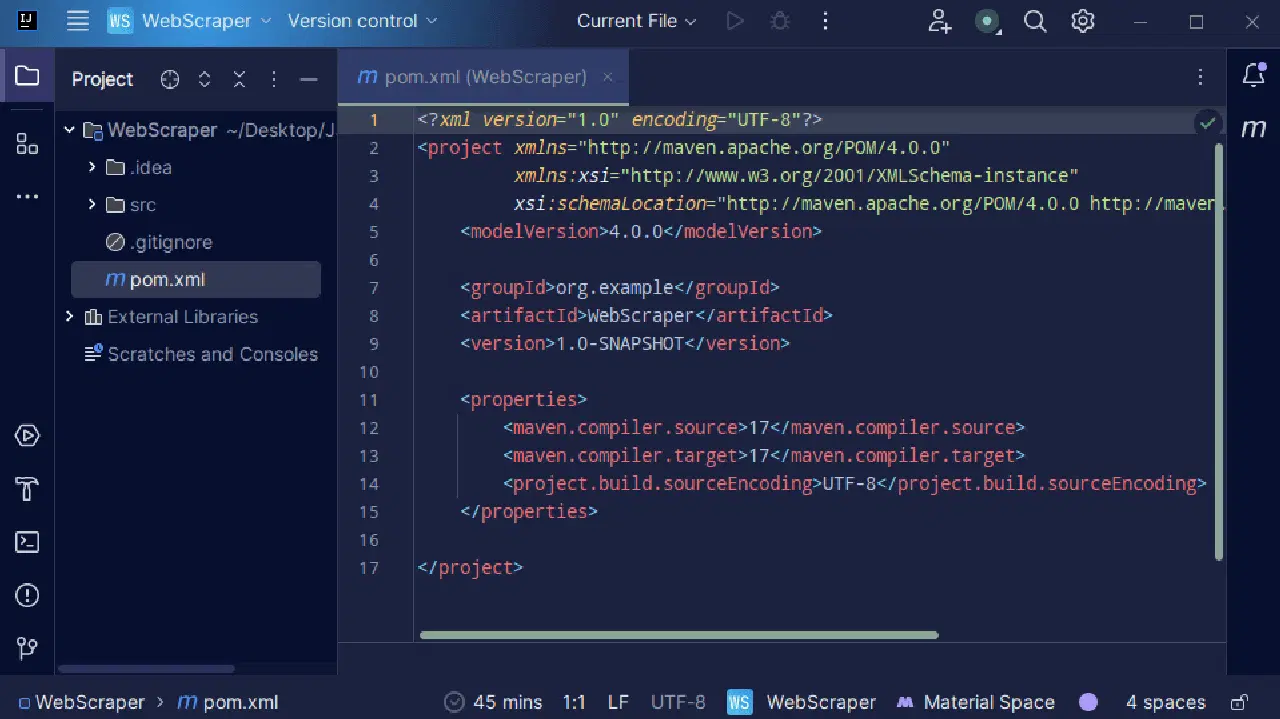
Le fichier "pom.xml" est généré par Maven et contient des informations sur le projet et les détails de configuration utilisés par Maven pour construire le projet. C'est ce fichier que nous utiliserons également pour indiquer que nous allons utiliser des bibliothèques externes.
Pour créer un web scraper, nous utiliserons la bibliothèque jsoup. Nous devons donc l'ajouter comme dépendance dans le fichier "pom.xml" afin que Maven puisse la rendre disponible dans notre projet.
4. Ajoutez la dépendance jsoup dans le fichier "pom.xml" en copiant le code ci-dessous et en l'ajoutant à votre fichier "pom.xml" :
<dependencies>
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.16.1</version>
</dependency>
</dependencies>
Le résultat devrait être similaire à celui-ci :
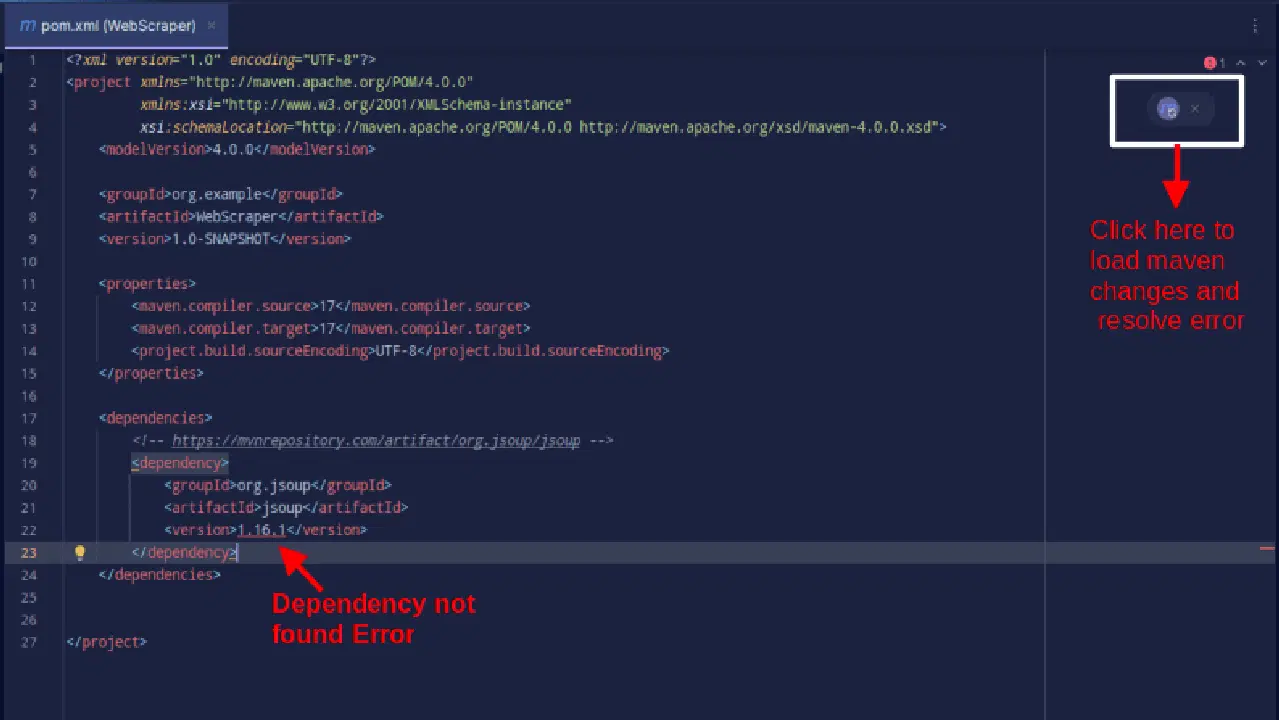
Si vous rencontrez une erreur indiquant que la dépendance est introuvable, cliquez sur l'icône indiquée pour que Maven charge les modifications apportées, charge la dépendance et supprime l'erreur.
Avec cela, votre environnement est entièrement configuré.
Scraping Web avec Java
Pour le web scraping, nous allons récupérer les données de Scrape This Site, qui fournit un espace d'expérimentation où les développeurs peuvent s'exercer au web scraping sans rencontrer de problèmes juridiques.
Pour scraper un site web en utilisant Java :
1. Dans la barre de menu de gauche d'IntelliJ, ouvrez le répertoire "src", puis le répertoire "main", situé à l'intérieur du répertoire "src". Le répertoire "main" contient un répertoire appelé "java". Faites un clic droit dessus, sélectionnez "Nouveau", puis "Classe Java".
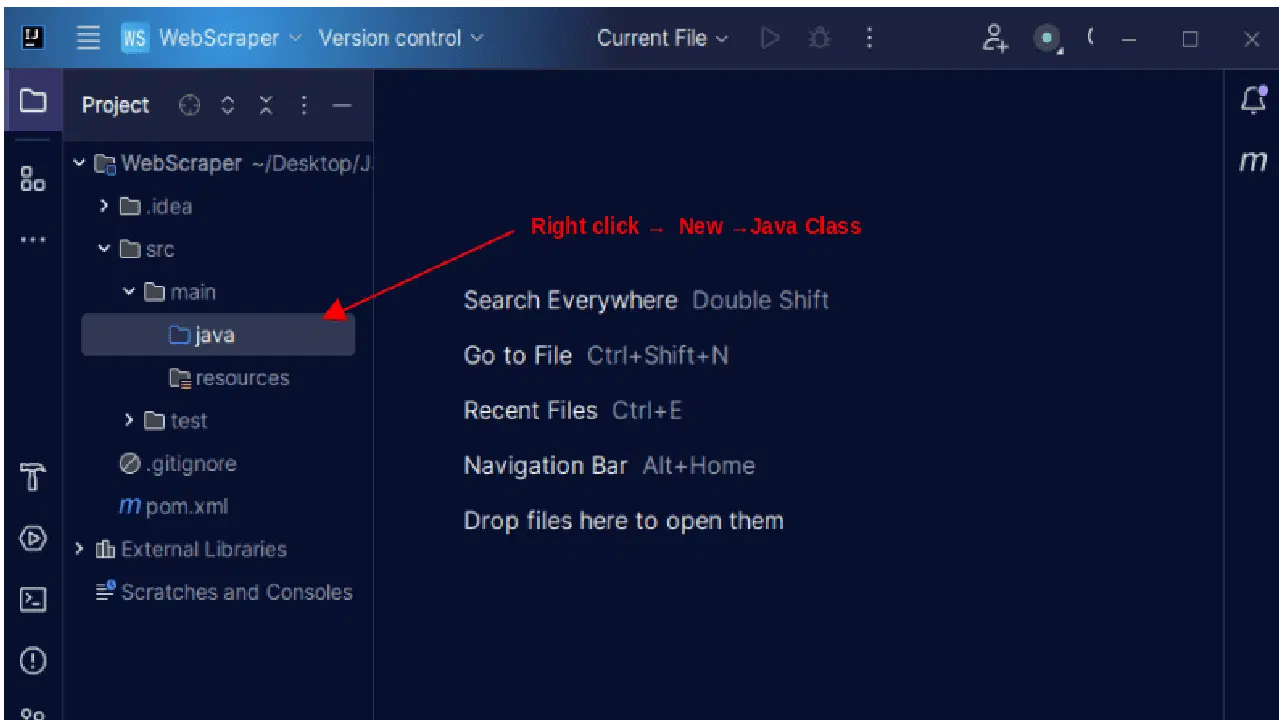
Nommez la classe comme vous le souhaitez, par exemple "WebScraper", puis appuyez sur "Entrée" pour créer une nouvelle classe Java.
Ouvrez le fichier nouvellement créé contenant la classe Java que vous venez de créer.
2. Le web scraping consiste à récupérer des données à partir de sites web. Par conséquent, nous devons spécifier l'URL à partir de laquelle nous souhaitons extraire les données. Une fois l'URL spécifiée, nous devons nous connecter à cette URL et effectuer une requête GET pour récupérer le contenu HTML de la page.
Le code qui effectue cette opération est présenté ci-dessous :
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import java.io.IOException;
public class WebScraper {
public static void main(String[] args) {
String url = "https://www.scrapethissite.com/pages/simple/";
try {
Document doc = Jsoup.connect(url).get();
System.out.println(doc);
} catch (IOException e) {
System.out.println("An IOException occurred. Please try again.");
}
}
}
Sortie :
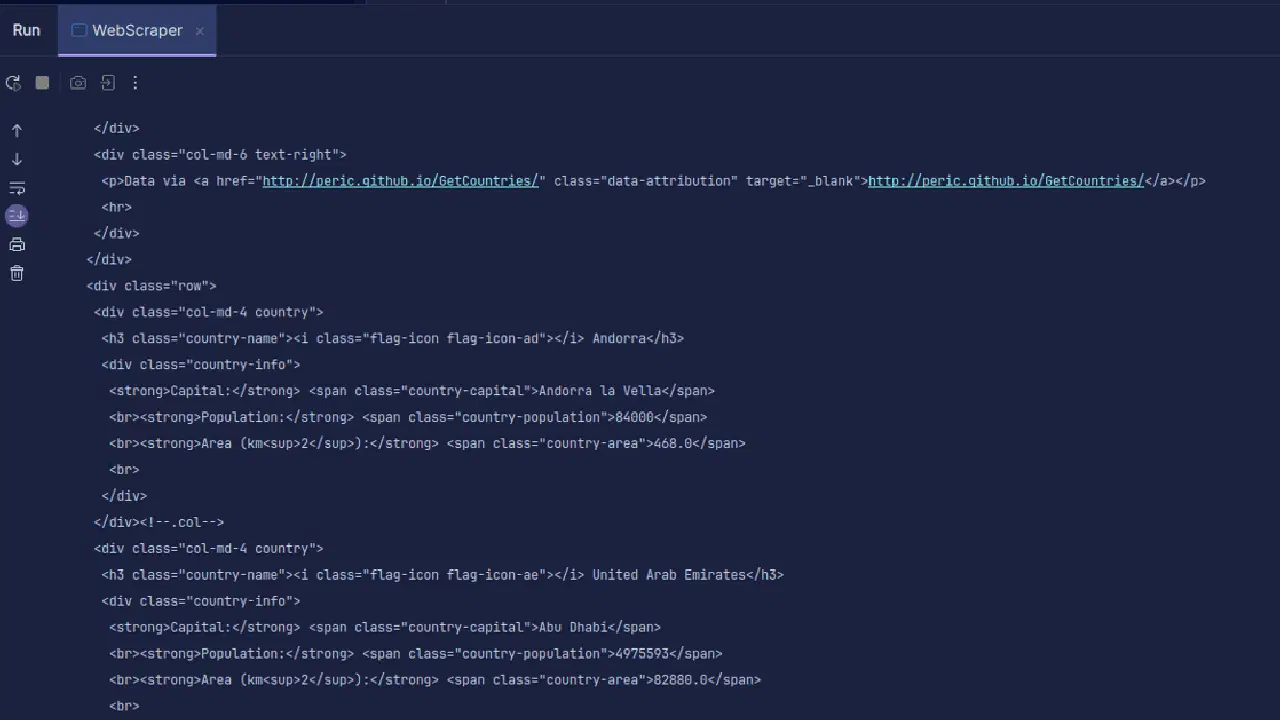
Comme vous pouvez le voir, le code HTML de la page est renvoyé et c'est ce que nous affichons. Lors du scraping, l'URL que vous spécifiez peut être erronée et la ressource que vous essayez de scraper peut ne pas exister. C'est pourquoi il est important d'encapsuler notre code dans un bloc try-catch.
La ligne :
Document doc = Jsoup.connect(url).get();
est utilisée pour se connecter à l'URL que vous souhaitez récupérer. La méthode "get()" effectue une requête GET et récupère le HTML de la page. Le résultat renvoyé est ensuite stocké dans un objet "Document" JSOUP, nommé "doc". Stocker le résultat dans un document JSOUP vous permet d'utiliser l'API JSOUP pour manipuler le code HTML renvoyé.
3. Allez sur Scrape This Site et inspectez la page. Dans le HTML, vous devriez observer une structure similaire à celle-ci :
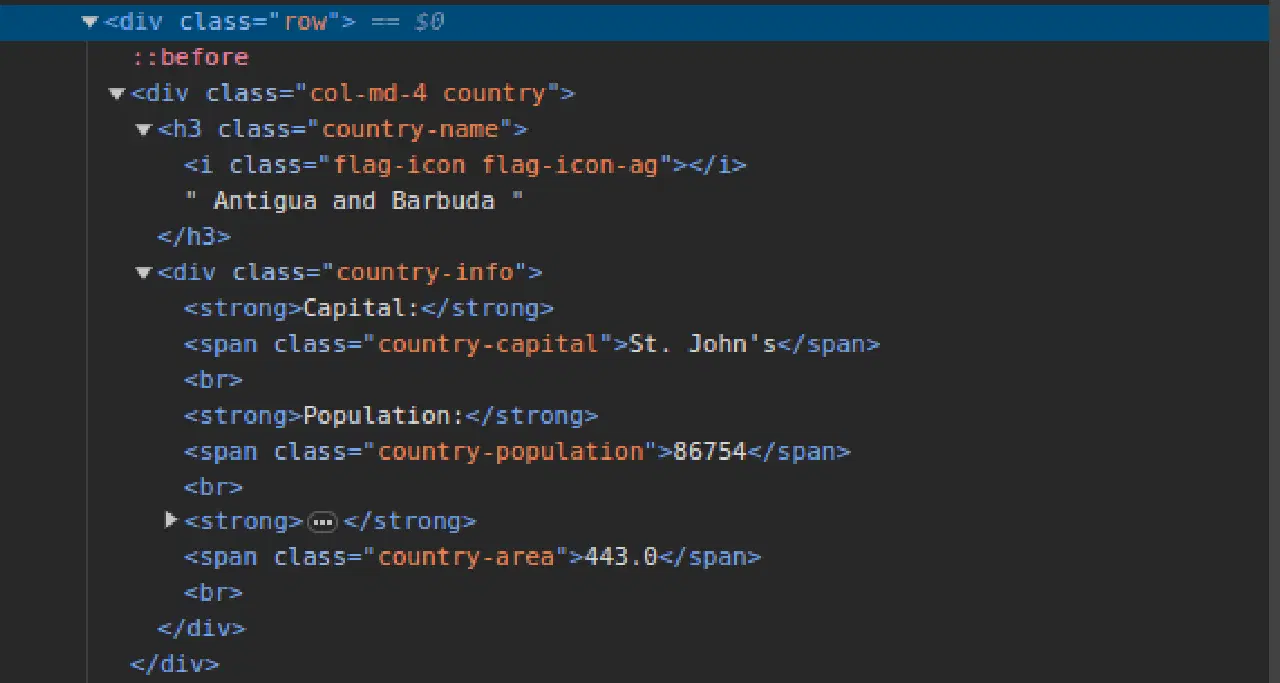
Notez que tous les pays de la page sont stockés sous une structure similaire. Il y a une div avec une classe appelée "country", un élément h3 avec une classe "country-name" contenant le nom de chaque pays de la page.
À l'intérieur de la div principale, il y a une autre div avec une classe "country-info" qui contient des informations telles que la capitale, la population et la superficie du pays. Nous pouvons utiliser ces noms de classe pour sélectionner les éléments HTML et extraire les informations.
4. Extrayez le contenu spécifique du HTML de la page en utilisant les lignes suivantes :
Elements countries = doc.select(".country");
for (Element country : countries) {
String countryName = country.select(".country-name").text();
String capitalCity = country.select(".country-capital").text();
String population = country.select(".country-population").text();
System.out.println(countryName + " - " + capitalCity + " Population - " + population);
}
Nous utilisons la méthode "select()" pour sélectionner les éléments du HTML de la page qui correspondent au sélecteur CSS spécifique que nous transmettons. Dans notre cas, nous transmettons les noms de classe. En inspectant la page, nous avons remarqué que toutes les informations relatives aux pays sont stockées dans une div avec la classe "country".
Chaque pays a sa propre div avec la classe "country", qui contient des informations comme le nom du pays, la capitale et la population.
Par conséquent, nous sélectionnons d'abord tous les pays de la page en utilisant la classe ".country". Nous stockons cela dans une variable appelée "country" de type "Elements", qui fonctionne comme une liste. Nous utilisons ensuite une boucle "for" pour parcourir les pays, extraire le nom, la capitale et la population, et afficher le résultat.
Le code complet est présenté ci-dessous :
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import org.jsoup.nodes.Element;
import java.io.IOException;
public class WebScraper {
public static void main(String[] args) {
String url = "https://www.scrapethissite.com/pages/simple/";
try {
Document doc = Jsoup.connect(url).get();
Elements countries = doc.select(".country");
for (Element country : countries) {
String countryName = country.select(".country-name").text();
String capitalCity = country.select(".country-capital").text();
String population = country.select(".country-population").text();
System.out.println(countryName + " - " + capitalCity + " - Population - " + population);
}
} catch (IOException e) {
System.out.println("An IOException occurred. Please try again.");
}
}
}
Sortie :
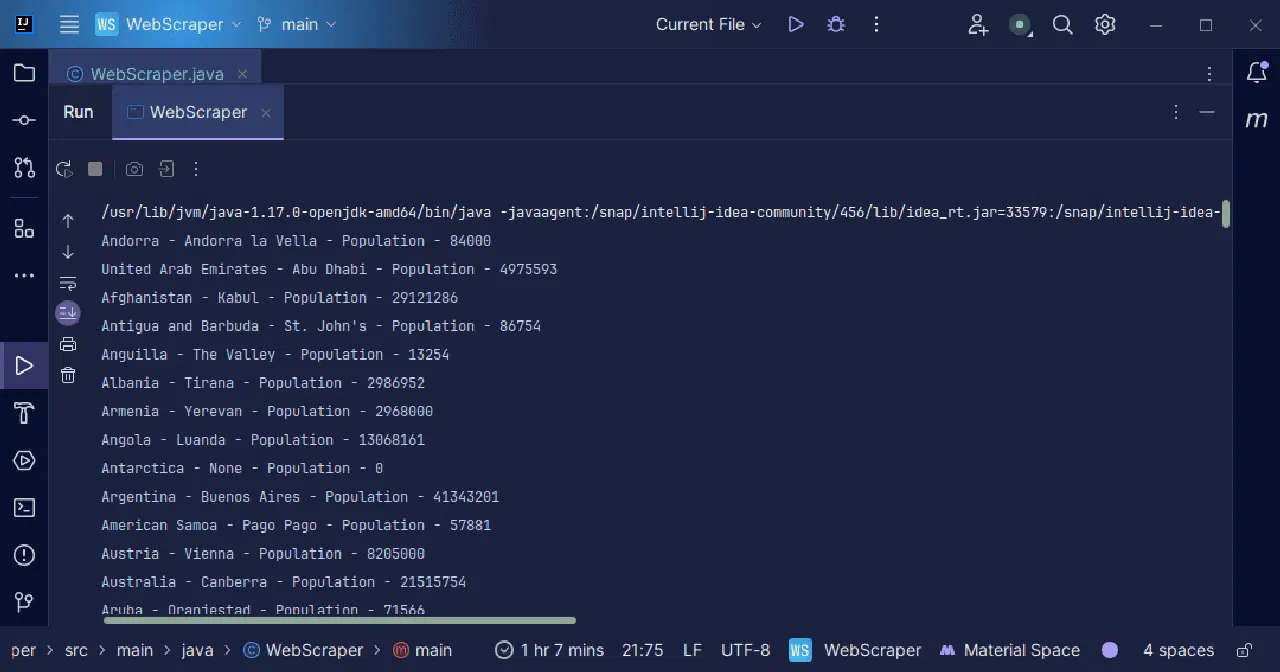
Avec les informations que nous récupérons de la page, nous pouvons faire diverses choses, comme les afficher comme nous venons de le faire, ou les stocker dans un fichier au cas où nous souhaiterions effectuer des traitements supplémentaires.
Conclusion
Le web scraping est un excellent moyen d'extraire des données non structurées de sites web, de les structurer et de les traiter pour en extraire des informations significatives. Toutefois, il est important de faire preuve de prudence lors de l'extraction de données, car certains sites web n'autorisent pas cette pratique.
Par mesure de sécurité, utilisez des sites web proposant des bacs à sable pour vous exercer au scraping. Sinon, vérifiez toujours le fichier robots.txt de chaque site web que vous souhaitez scraper afin de savoir s'il autorise cette pratique.
Lors du développement de web scrapers, Java est un excellent langage, car il fournit des bibliothèques qui rendent l'extraction de données plus facile et plus efficace. En tant que développeur Java, créer un web scraper vous aidera à approfondir vos compétences en programmation. N'hésitez pas à créer votre propre web scraper ou à modifier celui utilisé dans l'article pour extraire différents types d'informations. Bon codage !
Vous pouvez également explorer des solutions populaires de web scraping basées sur le cloud.