Utiliser les outils d'ingénierie du chaos pour vérifier la fiabilité de la production
Examinons comment vous pouvez garantir la fiabilité de votre environnement de production en employant des outils d'ingénierie du chaos.
L'ingénierie du chaos est une pratique où vous menez des expériences sur votre système ou application afin de mettre en lumière ses points faibles et ses vulnérabilités. Il s'agit souvent de situations que vous n'aviez pas anticipées lors de sa conception. Ainsi, vous provoquez intentionnellement des perturbations dans votre système pour identifier ses lacunes, ce qui vous permet de mettre en place des correctifs et d'améliorer la résilience de votre système et de votre application.
De nombreuses entreprises reconnues, telles que Netflix, LinkedIn et Facebook, utilisent l'ingénierie du chaos pour mieux cerner leur architecture de microservices et leurs systèmes distribués. Cela contribue à la détection précoce de problèmes, avant même les signalements des utilisateurs, et permet de prendre les mesures nécessaires pour y remédier. C'est ainsi que ces organisations peuvent servir des millions d'utilisateurs, accroître leur productivité et réaliser des économies considérables 🤑.
Avantages de l'ingénierie du chaos :
- Maîtrise des pertes financières grâce à la détection des problèmes critiques
- Réduction des pannes de système ou d'application
- Amélioration de l'expérience utilisateur avec moins d'interruptions et une haute disponibilité du service
- Renforcement de votre compréhension du système et accroissement de votre confiance
Êtes-vous certain de la solidité de votre environnement de production ? Est-il réellement à l'abri de toute catastrophe ?
Explorons cela à l'aide des outils de test de chaos les plus couramment utilisés.
Chaos Mesh
Chaos Mesh est une solution de gestion de l'ingénierie du chaos qui introduit des anomalies à chaque niveau d'un système Kubernetes. Cela inclut les pods, le réseau, les entrées/sorties système et le noyau. Chaos Mesh peut automatiquement arrêter des pods Kubernetes et simuler des latences. Il peut perturber la communication entre les pods et simuler des erreurs de lecture/écriture. Il permet de programmer des règles pour les expérimentations et de définir leur champ d'application. Ces expérimentations sont configurées à l'aide de fichiers YAML.
Chaos Mesh offre un tableau de bord pour l'analyse des expérimentations. Il fonctionne sur Kubernetes et prend en charge la majorité des plateformes cloud. Il est open-source et a été récemment intégré en tant que projet sandbox CNCF. En appliquant les principes de l'ingénierie du chaos, vous pouvez intégrer Chaos Mesh à votre processus DevOps pour développer des applications robustes.
Caractéristiques de l'ingénierie du chaos :
- Déploiement aisé sur les clusters Kubernetes sans modification de la logique de déploiement
- Aucune dépendance spécifique n'est requise pour le déploiement
- Définition des objets de chaos à l'aide de CustomResourceDefinitions (CRD)
- Fourniture d'un tableau de bord pour le suivi de toutes les expérimentations
Chaos Toolkit est un outil open-source simple pour l'automatisation des expérimentations d'ingénierie du chaos.
Vous pouvez intégrer Chaos ToolKit à votre système en utilisant un ensemble de pilotes ou de plugins compatibles avec AWS, Google Cloud, Slack, Prometheus, etc.

Fonctionnalités de Chaos ToolKit :
- Fourniture d'une API ouverte déclarative pour la création d'expériences chaotiques indépendantes de tout fournisseur ou technologie
- Intégration facile dans les pipelines CICD pour l'automatisation
- Offre un support commercial et d'entreprise via ChaosIQ
ChaosKube
Comme son nom l'indique, il est conçu pour Kubernetes.
Chaoskube est un outil de chaos open-source qui arrête régulièrement des pods aléatoires dans le cluster Kubernetes. Il vous aide à évaluer la réaction de votre système en cas de défaillance d'un pod. Par défaut, il arrête un pod dans n'importe quel espace de noms toutes les 10 minutes. Vous pouvez filtrer les pods ciblés dans Chaoskube à l'aide d'espaces de noms, d'étiquettes, d'annotations, etc. Son installation est simple.

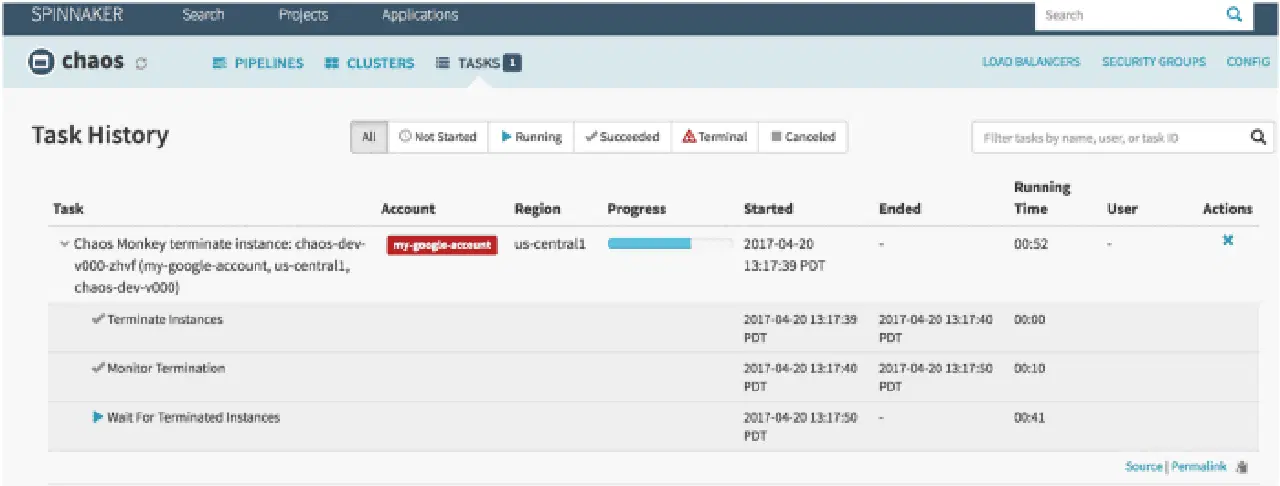
Chaos Monkey
Chaos Monkey est un outil permettant de vérifier la résilience des systèmes cloud en introduisant volontairement des défaillances afin d'en évaluer la réaction. Netflix l'a créé pour tester la robustesse et la capacité de récupération de son infrastructure AWS. Il a été nommé Chaos Monkey car il provoque des perturbations de manière aléatoire, à l'image d'un singe sauvage, afin de tester les défaillances.
De plus, Chaos Monkey est à l'origine de la pratique de l'ingénierie du chaos. Il a été développé sur le principe qu'il vaut mieux subir de petites défaillances répétées pour éviter une panne majeure et soudaine.
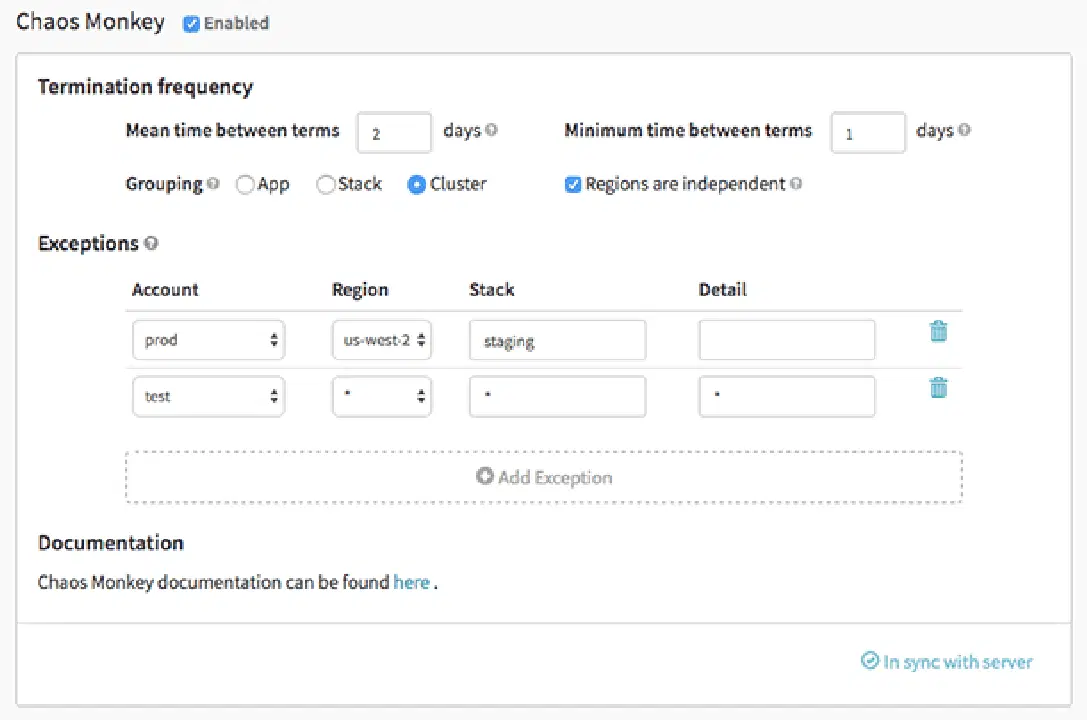
Caractéristiques de Chaos Monkey :
- Vous aide à vous préparer à des défaillances d'instances aléatoires
- Encourage la redondance en cas de pannes imprévues
- Utilise Spinnaker pour assurer la compatibilité inter-cloud
- Offre un calendrier configurable pour la simulation des pannes
- Intégré avec gouverneur pour ajouter de nouvelles dépendances à Chaos Monkey
Simmy
Simmy est un outil d'injection de pannes qui s'intègre au projet de résilience Polly pour .NET. Il vous permet de créer des stratégies d'injection de chaos via Polly, où vos codes s'exécutent. Il propose diverses stratégies, telles que la stratégie d'exceptions pour injecter des exceptions dans le système, la stratégie de comportement pour injecter un nouveau comportement, etc. Ces stratégies sont conçues pour injecter des comportements de manière aléatoire.
Fonctionnalités de Simmy :
- Offre des stratégies de "singe" ou de chaos pour introduire des perturbations
- Facilite le test des défaillances de dépendance
- Permet un retour rapide au modèle de travail et le contrôle de la portée des perturbations.
- Est conçu pour la production.
- Peut également simuler des défaillances basées sur des facteurs externes (par exemple, des défaillances dues à la configuration globale)
Pystol
Pystol est un outil utilisé pour injecter des perturbations dans des environnements cloud natifs. Il surveille les événements dans ETCD via des opérateurs Kubernetes. Lorsqu'une action d'injection de pannes est déclenchée, les opérateurs créent des pods et exécutent certaines collections Ansible. Les développeurs n'ont ainsi pas besoin d'écrire leurs propres actions à réaliser.
Pystol fournit des actions prêtes à l'emploi pour tester le système. Toutefois, si un développeur souhaite créer une nouvelle action, il peut le faire en utilisant GoLang et Python.
Il met à disposition un tableau de bord d'intégration continue qui offre une vue d'ensemble de toutes les opérations en cours. Vous pouvez exécuter Pystol localement ou le déployer dans un conteneur à l'aide de son image docker. Pystol propose deux interfaces, l'une étant une interface utilisateur Web et l'autre via la ligne de commande. L'interface utilisateur Web est généralement préférable.
Muxy
Muxy est un proxy pour évaluer vos modèles de résilience et de tolérance aux pannes face à des défaillances réelles des systèmes distribués. Il peut altérer le niveau transport (couche 4), le niveau de session TCP (couche 5) et le niveau de protocole HTTP (couche 7).
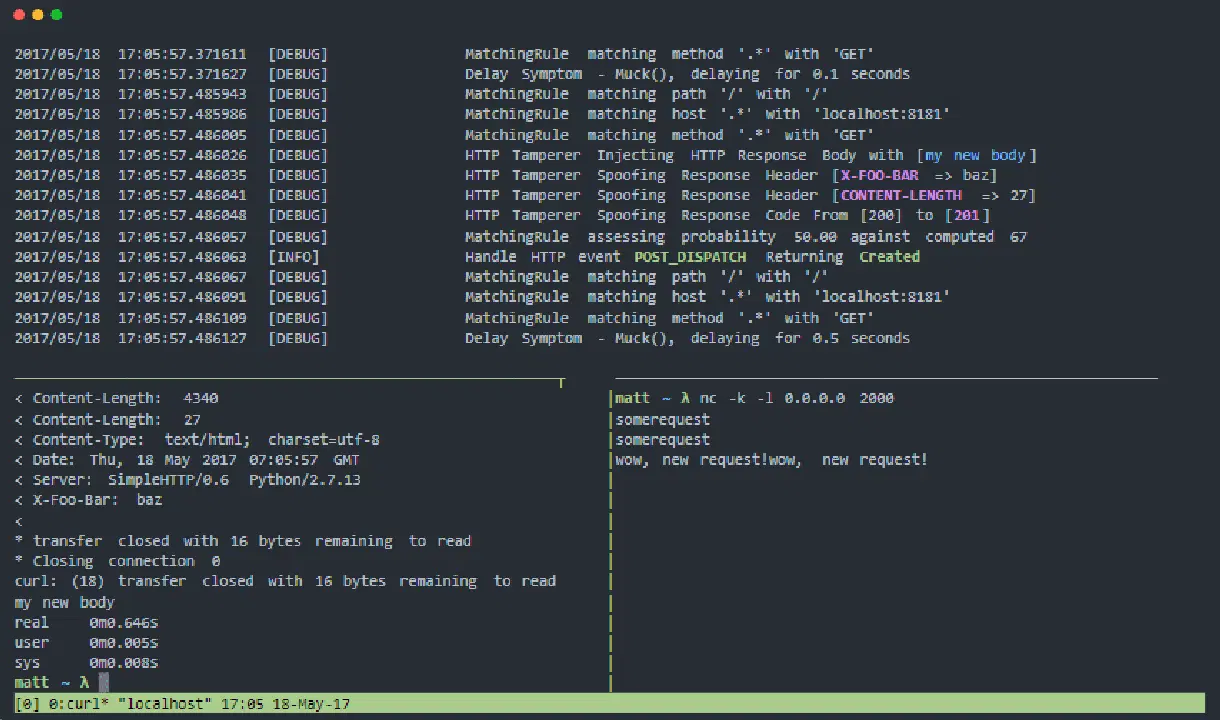
Fonctionnalités de Muxy :
- Architecture modulaire et facilement extensible
- Dispose d'un conteneur docker officiel
- Installation simple, sans dépendance requise
- Idéal pour les tests de résilience en continu
- Simule des problèmes de connectivité réseau pour les systèmes distribués et les appareils mobiles
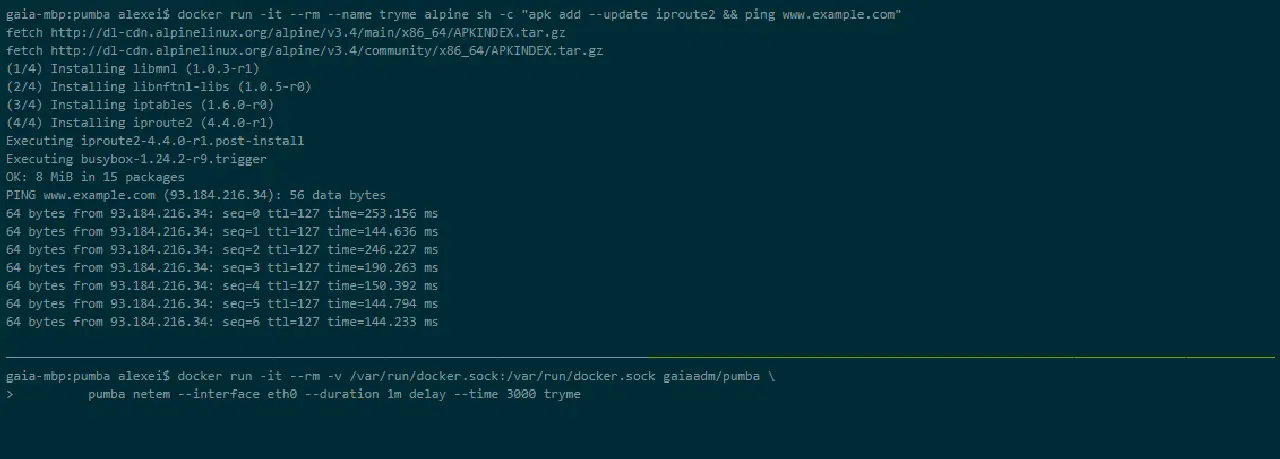
Pumba
Pumba est un outil en ligne de commande qui effectue des tests de chaos pour les conteneurs Docker. Avec Pumba, vous stoppez volontairement les conteneurs Docker de l'application afin d'observer la réaction du système. Vous pouvez également effectuer des tests de résistance sur les ressources du conteneur telles que le processeur, la mémoire, le système de fichiers, les entrées/sorties, etc.
Vous pouvez également exécuter Pumba sur un cluster Kubernetes. Vous devez utiliser DaemonSets pour déployer Pumba sur les nœuds Kubernetes. Vous pouvez utiliser plusieurs conteneurs Pumba pour exécuter plusieurs commandes Pumba dans le même DaemonSet.
ChaosBlade
ChaosBlade est un outil open-source pour injecter des expérimentations dans les systèmes d'Alibaba. Il teste tous les types de défaillances rencontrés par Alibaba au cours des dix dernières années et met en œuvre les meilleures pratiques pour les éviter. Il respecte les principes de l'ingénierie du chaos pour vérifier la tolérance aux pannes des systèmes distribués.
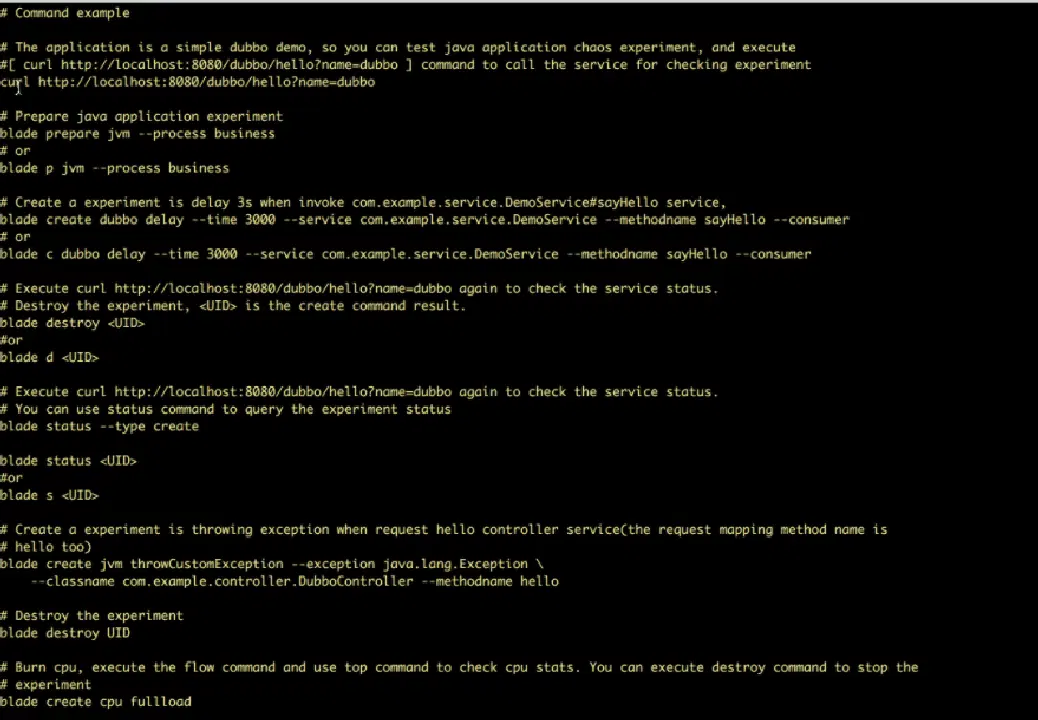
Caractéristiques de Chaos Blade :
- Fournit des scénarios expérimentaux pour diverses ressources telles que le processeur, le réseau, la mémoire, le disque, etc.
- Offre des scénarios expérimentaux pour les nœuds, les réseaux et les pods sur la plateforme Kubernetes
- Fournit des commandes CLI simples pour l'exécution des expérimentations
Litmus
Litmus est basé sur les principes de l'ingénierie du chaos native du cloud. L'objectif de cet outil est de fournir un cadre complet pour identifier les points faibles de vos systèmes Kubernetes et de vos applications en cours d'exécution sur Kubernetes.
Il dispose d'un opérateur de chaos et de CRD (CustomResourceDefinitions) associés, offrant une capacité plug-and-play. Il s'agit de placer votre logique de chaos dans une image docker, de l'intégrer dans un cadre Litmus et de l'orchestrer à l'aide des CRD.
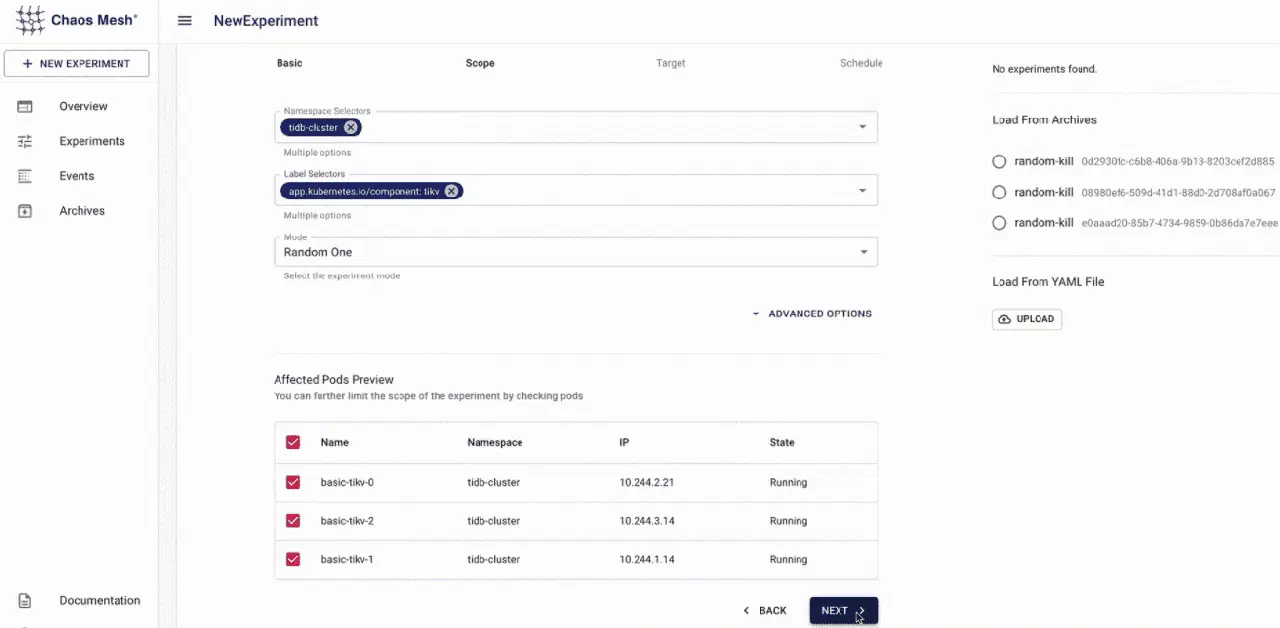
Caractéristiques de Litmus :
- Aide les ingénieurs et les développeurs responsables de la fiabilité des sites à détecter les vulnérabilités des systèmes Kubernetes
- Offre des expérimentations génériques prêtes à l'emploi
- Fournit l'API Chaos pour la gestion du flux de travail chaotique
- Litmus SDK prend en charge Go, Python et Ansible pour la création de vos propres expérimentations.
Gremlin
Gremlin aide les ingénieurs à créer des logiciels plus robustes. Il propose une plateforme pour exécuter des expérimentations d'ingénierie du chaos de manière sûre, sécurisée et simple.

Vous pouvez intelligemment introduire des perturbations dans les hôtes ou les conteneurs avec Gremlin, quel que soit leur emplacement, qu'il s'agisse du cloud public ou de votre propre centre de données.
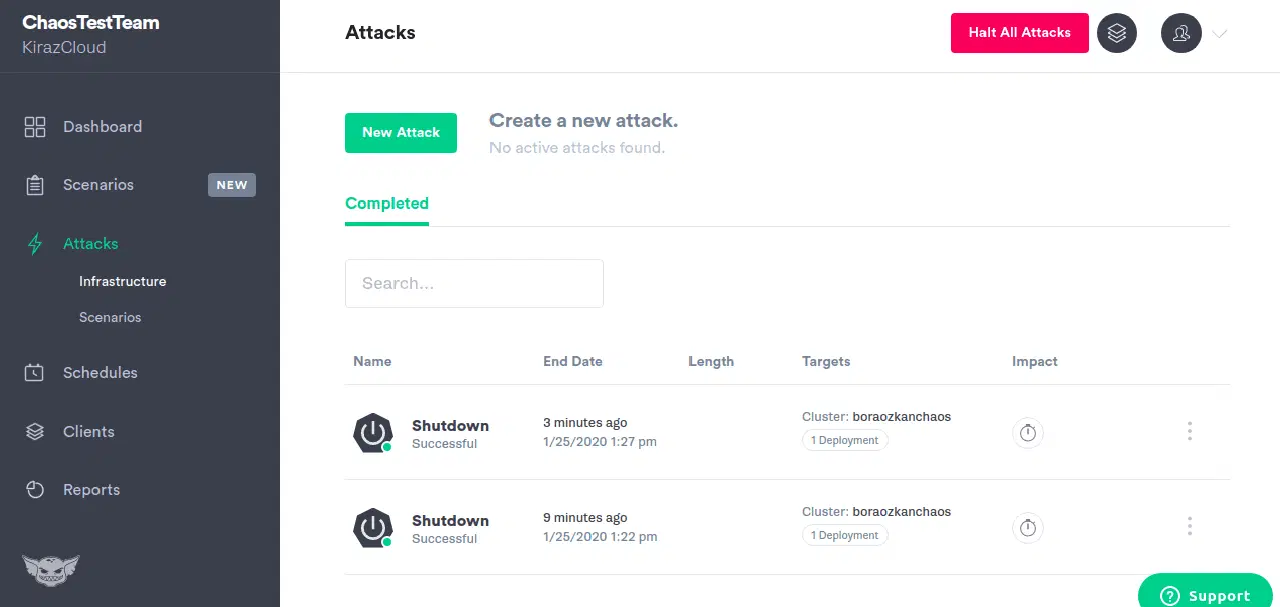
Fonctionnalités de Gremlin :
- Installe un agent léger sur vos hôtes ou conteneurs pour introduire les perturbations
- Propose plus de 10 modes d'attaque d'infrastructure différents
- Les "gremlins" d'état vous permettent de manipuler l'heure du système, d'arrêter ou de redémarrer des hôtes et de bloquer des processeurs
- Les "gremlins" de réseau peuvent introduire une latence, provoquer une perte de paquets ou supprimer du trafic
- Les attaques de la bibliothèque Alfi de Gremlin peuvent être configurées, lancées et arrêtées via l'application Web, l'API ou la ligne de commande
- Vous permet de cibler avec précision le rayon d'action que vous souhaitez attaquer
- Permet d'arrêter toutes les attaques et de rétablir le système à un état stable
Steadybit
Steadybit vise à réduire les temps d'arrêt de manière proactive et offre une visibilité sur les problèmes du système. Vous pouvez exécuter cet outil localement sur votre infrastructure ou en tant que service cloud (SaaS).
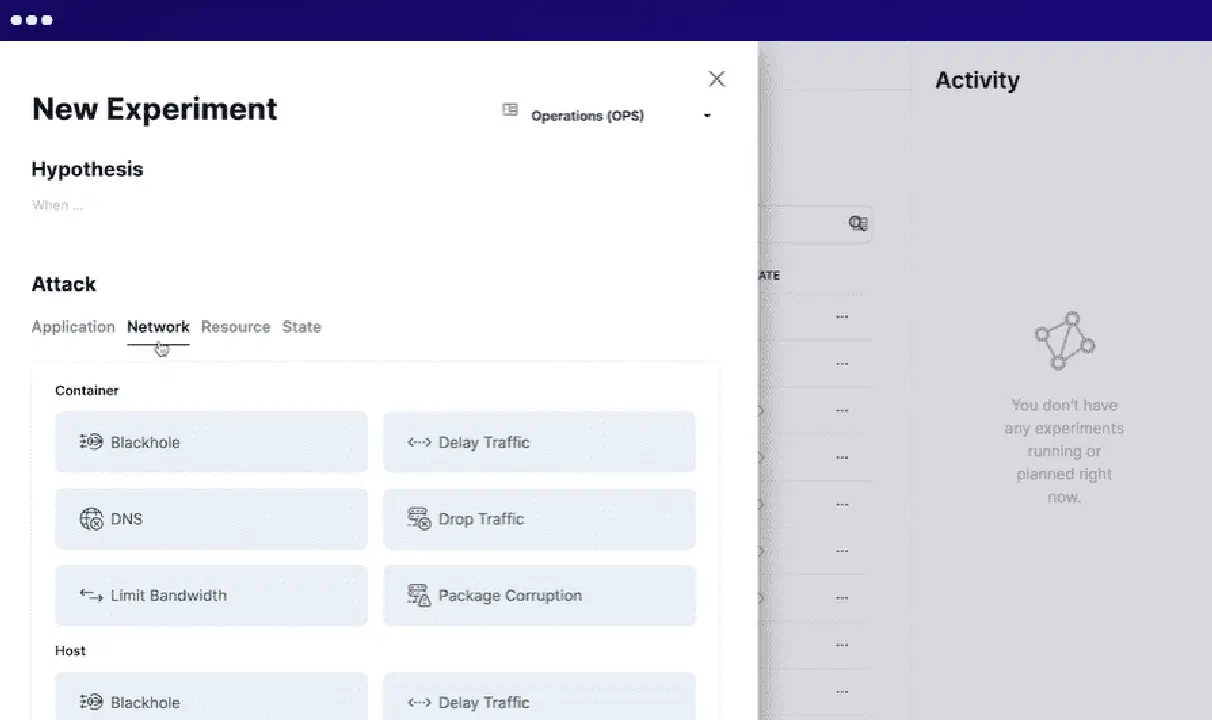
Pour utiliser Steadybit, vous devez définir le contexte, simuler les expérimentations, exécuter les expérimentations simulées en production et automatiser toutes les expérimentations. Il utilise des agents intelligents sur votre système pour découvrir les problèmes et les vulnérabilités potentiels. Il s'intègre facilement avec de nombreux systèmes.
Conclusion
N'hésitez pas à appliquer les principes de l'ingénierie du chaos et à tester votre production avec les outils mentionnés ci-dessus. Ces outils vous aideront à déceler diverses faiblesses insoupçonnées dans votre système et à améliorer sa résilience.