L’emploi de Python dans le domaine de la science des données a connu une expansion fulgurante au cours des dernières années, et cette tendance ne montre aucun signe de ralentissement.
La science des données est un champ d’étude vaste, comprenant de nombreuses spécialisations. L’analyse des données est sans conteste l’une des plus cruciales. Ainsi, il est devenu essentiel, quel que soit votre niveau d’expertise en science des données, de comprendre ou du moins d’avoir une connaissance de base de cette discipline.
Qu’est-ce que l’analyse de données ?
L’analyse de données consiste à nettoyer et à transformer des ensembles de données volumineux, souvent non structurés ou mal organisés, afin d’en extraire des informations pertinentes et des éclairages précieux. Ces informations sont ensuite utilisées pour prendre des décisions éclairées.
Plusieurs outils sont disponibles pour l’analyse des données, tels que Python, Microsoft Excel, Tableau et SAS. Cependant, cet article se concentre sur la manière dont l’analyse des données est réalisée à l’aide de Python, et plus précisément, avec la bibliothèque Pandas.
Qu’est-ce que Pandas ?
Pandas est une bibliothèque Python open source spécialement conçue pour la manipulation et la gestion de données. Elle est reconnue pour sa rapidité et son efficacité, offrant des outils pour charger divers types de données en mémoire. Pandas permet de remodeler, d’étiqueter, d’indexer et même de regrouper des données de différentes formes.
Les structures de données dans Pandas
Pandas propose trois structures de données fondamentales :
- La série (Series)
- Le DataFrame
- Le Panel
Pour mieux comprendre la distinction entre ces structures, on peut imaginer une organisation en piles : un DataFrame est constitué de plusieurs séries empilées, et un Panel, de plusieurs DataFrames empilés.
- Une série est un tableau unidimensionnel.
- L’empilement de plusieurs séries forme un DataFrame, une structure bidimensionnelle.
- L’empilement de plusieurs DataFrames donne naissance à un Panel, une structure tridimensionnelle.
Le DataFrame bidimensionnel est la structure de données la plus fréquemment utilisée et constitue souvent la représentation par défaut de nombreux ensembles de données.
Analyse de données avec Pandas
Pour les besoins de cet article, aucune installation n’est nécessaire. Nous utiliserons un outil en ligne fourni par Google, appelé Colaboratory. Il s’agit d’un environnement Python en ligne, spécialement conçu pour l’analyse de données, l’apprentissage automatique et l’intelligence artificielle. Colaboratory est un Jupyter Notebook basé sur le cloud, pré-équipé de la plupart des packages Python nécessaires aux data scientists.
Rendez-vous sur cette page https://colab.research.google.com/notebooks/intro.ipynb. Vous devriez voir une interface similaire à celle ci-dessous.
Dans le menu de navigation en haut à gauche, cliquez sur « Fichier » puis sélectionnez « Nouveau notebook ». Un nouveau notebook Jupyter sera alors chargé dans votre navigateur. La première étape consiste à importer la bibliothèque Pandas dans notre environnement de travail, ce qui se fait en exécutant la commande suivante :
import pandas as pd
Pour illustrer notre analyse de données, nous utiliserons un ensemble de données relatif aux prix de l’immobilier. Vous pouvez accéder à ce jeu de données ici. La première tâche est de charger ce jeu de données dans notre environnement.
Ceci peut être réalisé à l’aide du code suivant dans une nouvelle cellule :
df = pd.read_csv('https://firebasestorage.googleapis.com/v0/b/ai6-portfolio-abeokuta.appspot.com/o/kc_house_data.csv?alt=media&token=6a5ab32c-3cac-42b3-b534-4dbd0e4bdbc0', sep=',')
La fonction .read_csv permet de lire un fichier CSV. Nous spécifions l’argument sep pour indiquer que les données du fichier CSV sont séparées par des virgules.
Il est important de noter que le fichier CSV chargé est stocké dans une variable nommée df.
Dans un Jupyter Notebook, il n’est pas nécessaire d’utiliser la fonction print(). On peut simplement taper le nom d’une variable dans une cellule, et Jupyter Notebook affichera son contenu.
Essayons cela en saisissant df dans une nouvelle cellule et en l’exécutant. Toutes les données de notre ensemble de données seront affichées sous forme de DataFrame.
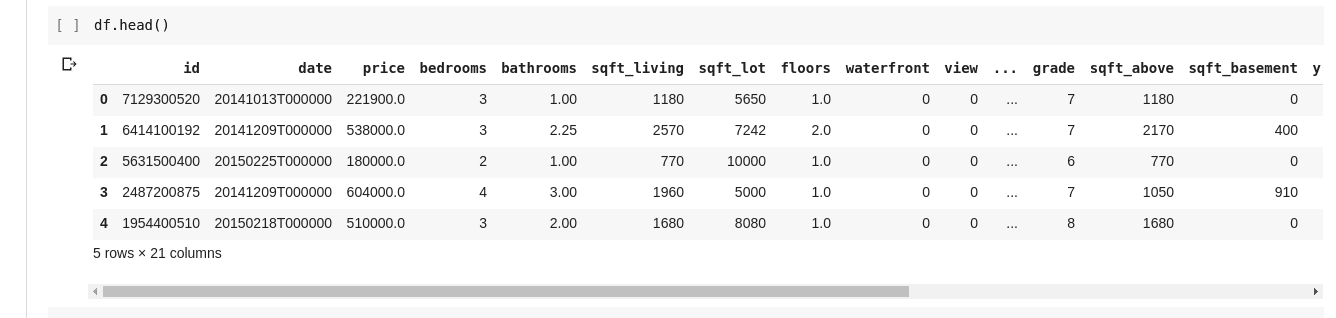
Cependant, nous n’avons pas toujours besoin de consulter l’intégralité des données. Parfois, nous voulons juste visualiser les premières lignes et leurs en-têtes de colonne. Pour cela, on utilise la fonction df.head() pour afficher les cinq premières lignes, et df.tail() pour les cinq dernières. La sortie de l’une ou l’autre de ces fonctions ressemblera à ceci :
Il est souvent utile d’analyser les relations entre les différentes lignes et colonnes de données. La fonction .describe() remplit précisément cette fonction.
L’exécution de df.describe() produit le résultat suivant :
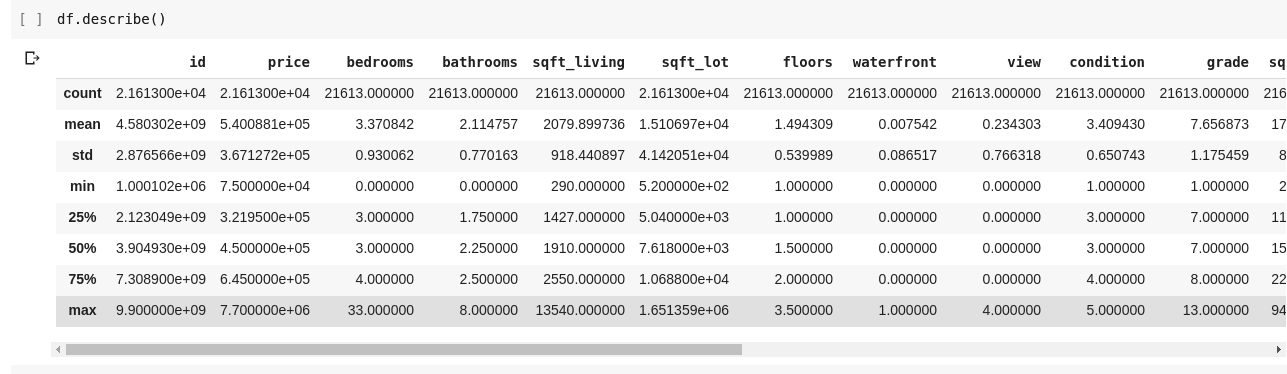
On constate que .describe() nous donne la moyenne, l’écart type, les valeurs minimales et maximales, ainsi que les centiles pour chaque colonne du DataFrame. C’est une information particulièrement précieuse.
Nous pouvons également obtenir la forme de notre DataFrame bidimensionnel, c’est-à-dire le nombre de lignes et de colonnes, en utilisant df.shape, qui renvoie un tuple au format (lignes, colonnes).
Pour connaître les noms de toutes les colonnes de notre DataFrame, nous pouvons utiliser df.columns.
Comment sélectionner une colonne unique et récupérer toutes les données qu’elle contient ? Cela se fait de manière similaire au découpage d’un dictionnaire. Saisissez le code suivant dans une nouvelle cellule et exécutez-le :
df['price']
Le code ci-dessus renvoie la colonne contenant les prix. On peut aller plus loin en stockant cette colonne dans une nouvelle variable, comme ceci :
price = df['price']
Nous pouvons maintenant effectuer toutes les opérations réalisables sur un DataFrame sur notre variable price, car il s’agit d’un sous-ensemble d’un DataFrame. Nous pouvons utiliser des fonctions telles que df.head(), df.shape, etc.
Nous pouvons également sélectionner plusieurs colonnes en passant une liste de noms de colonnes à df, comme suit :
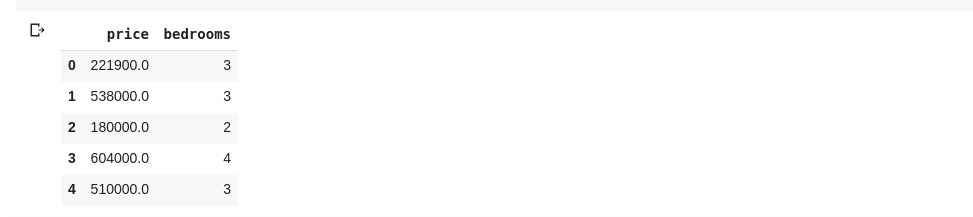
data = df[['price', 'bedrooms']]
La commande ci-dessus sélectionne les colonnes ‘prix’ et ‘chambres’. En exécutant data.head() dans une nouvelle cellule, nous obtiendrons le résultat suivant :
La méthode de découpage des colonnes présentée ci-dessus renvoie tous les éléments de ligne de ces colonnes. Mais que se passe-t-il si nous souhaitons retourner un sous-ensemble de lignes et un sous-ensemble de colonnes de notre jeu de données ? Cela est possible en utilisant .iloc, qui fonctionne de manière similaire à l’indexation des listes Python. On peut par exemple faire quelque chose comme :
df.iloc[50:, 3]
Ceci renvoie la troisième colonne, à partir de la 50ème ligne jusqu’à la fin. Cette méthode est très pratique et similaire au découpage de listes en Python.
Passons maintenant à des manipulations plus intéressantes. Notre jeu de données sur les prix de l’immobilier contient une colonne indiquant le prix d’une maison et une autre colonne indiquant le nombre de chambres à coucher. Le prix de l’immobilier est une variable continue, il est donc possible que deux maisons n’aient pas le même prix. Le nombre de chambres, en revanche, est une variable discrète, ce qui signifie que plusieurs maisons peuvent avoir deux, trois ou quatre chambres, etc.
Que se passe-t-il si nous voulons obtenir toutes les maisons avec le même nombre de chambres et calculer le prix moyen pour chaque nombre de chambres ? C’est relativement facile à faire avec Pandas, comme ceci :
df.groupby('bedrooms')['price'].mean()
La commande ci-dessus regroupe d’abord le DataFrame par le nombre de chambres à l’aide de la fonction df.groupby(), puis indique de ne prendre que la colonne contenant le prix, et d’utiliser la fonction .mean() pour calculer la moyenne des prix pour chaque groupe de maisons ayant le même nombre de chambres.
Et si nous voulions visualiser ce résultat ? Il serait utile de vérifier comment le prix moyen varie en fonction du nombre de chambres. Il suffit pour cela de chaîner le code précédent à une fonction .plot(), comme suit :
df.groupby('bedrooms')['price'].mean().plot()
On obtient alors une sortie ressemblant à ceci :
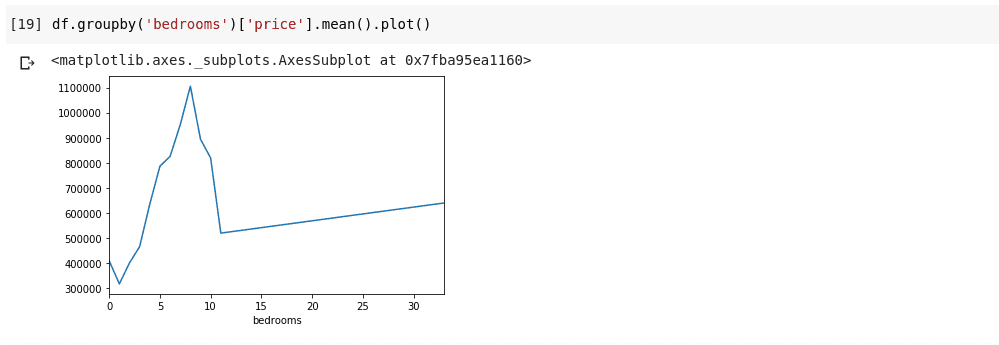
Cette visualisation permet de faire ressortir certaines tendances dans les données. L’axe horizontal représente le nombre de chambres distinct (il est important de noter que plusieurs maisons peuvent avoir le même nombre de chambres), tandis que l’axe vertical affiche le prix moyen par rapport au nombre de chambres correspondant. On peut constater que les maisons ayant entre 5 et 10 chambres sont significativement plus chères que celles ayant 3 chambres. Il est également frappant de remarquer que les maisons ayant environ 7 ou 8 chambres sont plus chères que celles qui en ont 15, 20 ou même 30.
Des informations comme celles ci-dessus soulignent l’importance de l’analyse des données. Elle permet de faire émerger des informations utiles, qui ne sont pas immédiatement apparentes ou impossibles à identifier sans analyse.
Données Manquantes
Supposons que vous participiez à une enquête composée de plusieurs questions, et que vous diffusiez un lien vers cette enquête auprès de milliers de personnes. Votre but est d’effectuer une analyse des données afin d’en extraire des informations pertinentes.
Plusieurs problèmes peuvent survenir : certains répondants peuvent hésiter à répondre à certaines questions et laisser les champs vides. De nombreuses personnes pourraient faire de même pour diverses questions de votre enquête. Cela pourrait sembler anodin, mais imaginez que vous collectez des données numériques dans votre enquête et que vous devez effectuer des opérations arithmétiques telles que des sommes ou des moyennes. La présence de valeurs manquantes pourrait engendrer des erreurs considérables dans votre analyse. Il est donc nécessaire de trouver un moyen de localiser et de remplacer ces valeurs manquantes par des valeurs qui s’en approchent au mieux.
Pandas fournit une fonction nommée isnull(), qui permet de détecter les valeurs manquantes dans un DataFrame.
La fonction isnull() peut être utilisée comme ceci :
df.isnull()
Cette commande retourne un DataFrame de valeurs booléennes, indiquant si les données initialement présentes étaient véritablement manquantes. La sortie est similaire à ceci :
Il est important de pouvoir remplacer ces valeurs manquantes. Souvent, on choisit de les remplacer par zéro. Dans certains cas, il peut être judicieux de les remplacer par la moyenne de toutes les autres données, ou par la moyenne des données voisines, en fonction des besoins spécifiques de l’analyse et des choix du data scientist.
Pour remplacer toutes les valeurs manquantes dans un DataFrame, on utilise la fonction .fillna(), comme ceci :
df.fillna(0)
Dans l’exemple ci-dessus, toutes les valeurs vides sont remplacées par la valeur zéro. On pourrait tout aussi bien utiliser n’importe quelle autre valeur spécifiée.
L’importance des données est indéniable : elles permettent de trouver des réponses directement à partir des données elles-mêmes. Certains considèrent l’analyse des données comme le nouveau pétrole des économies numériques.
Tous les exemples utilisés dans cet article sont disponibles ici.
Pour approfondir vos connaissances, vous pouvez consulter ce cours en ligne sur l’analyse de données avec Python et Pandas.