
Prometheus est un système de surveillance open source basé sur des métriques. Il collecte les données des services et des hôtes en envoyant des requêtes HTTP sur les points de terminaison des métriques. Il stocke ensuite les résultats dans une base de données de séries chronologiques et les met à disposition pour analyse et alerte.
Table des matières
Pourquoi surveiller ?
- Active les alertes lorsque les choses tournent mal, de préférence avant qu’elles ne tournent mal. Pour que quelqu’un puisse y jeter un œil.
- Il fournit des informations pour permettre l’analyse, le débogage et la résolution du problème.
- Il vous permet de voir les tendances/changements au fil du temps. Par exemple, combien de sessions actives à un moment donné. Cela facilite les décisions de conception et la planification des capacités.
La surveillance porte généralement sur les événements. Un événement peut inclure la réception d’une requête HTTP, l’envoi d’une réponse, la lecture à partir du disque, une connexion utilisateur. La surveillance d’un système peut inclure le profilage, la journalisation, le traçage, les métriques, les alertes et la visualisation.
Surveillance Blackbox vs Whitebox
La surveillance relève de deux catégories principales :
Surveillance de la boîte noire
Dans la surveillance Blackbox, la surveillance se fait au niveau de l’application ou de l’hôte, car ils sont observés de l’extérieur. Cela peut être assez limitant.
Surveillance de la boîte blanche
La surveillance de la boîte blanche signifie surveiller les éléments internes d’un service. Cela exposerait des données sur l’état et les performances des composants internes.
Les quatre signaux d’or
Selon Googlesi vous ne pouvez mesurer que quatre métriques de votre système orienté utilisateur, concentrez-vous sur les quatre suivantes, appelées les quatre signaux d’or :
#1. Latence
Le temps qu’il faut pour servir une demande – réussie ou échouée. Il est important de suivre non seulement les demandes réussies, mais également celles qui ont échoué.
#2. Trafic
Une mesure de la demande placée sur votre système. Pour un service Web, il s’agit généralement de requêtes HTTP par seconde.
#3. les erreurs
Le taux de requêtes qui échouent.
#4. Saturation
À quel point votre service est complet. L’augmentation de la latence est souvent un indicateur important de saturation. De nombreux systèmes voient leurs performances se dégrader bien avant d’atteindre 100 % d’utilisation.
Types de métriques Prometheus
Les métriques Prometheus sont de quatre types principaux :
#1. Compteur
La valeur d’un compteur augmentera toujours. Il ne peut jamais diminuer, mais il peut être remis à zéro. Ainsi, si un scrape échoue, cela signifie uniquement un point de données manqué. L’augmentation cumulée serait disponible à la lecture suivante. Exemples:
- Nombre total de requêtes HTTP reçues
- Le nombre d’exceptions.
#2. Jauge
Une jauge est un instantané à un instant donné. Il peut à la fois augmenter ou diminuer. Si une récupération de données échoue, vous perdez un échantillon ; la prochaine extraction peut afficher une valeur différente : exemples d’espace disque, utilisation de la mémoire.
#3. Histogramme
Un histogramme échantillonne les observations et les compte dans des compartiments configurables. Ils sont utilisés pour des choses comme la durée de la demande ou la taille des réponses. Par exemple, vous pouvez mesurer la durée de la requête pour une requête HTTP spécifique. L’histogramme aura un ensemble de seaux, disons 1 ms, 10 ms et 25 ms. Plutôt que de stocker chaque durée pour chaque requête, Prometheus stockera la fréquence des requêtes qui tombent dans un compartiment particulier.
#4. Sommaire
Similaires aux observations d’échantillons d’histogrammes, demandent généralement des durées ou des tailles de réponse. Il fournira un nombre total d’observations et une somme de toutes les valeurs observées, vous permettant de calculer la moyenne des valeurs observées. Par exemple, en une minute, vous avez eu trois requêtes qui ont pris 2,3,4 secondes. La somme serait de 9 et le compte serait de 3. La latence serait de 3 secondes.
Composants de l’écosystème Prometheus
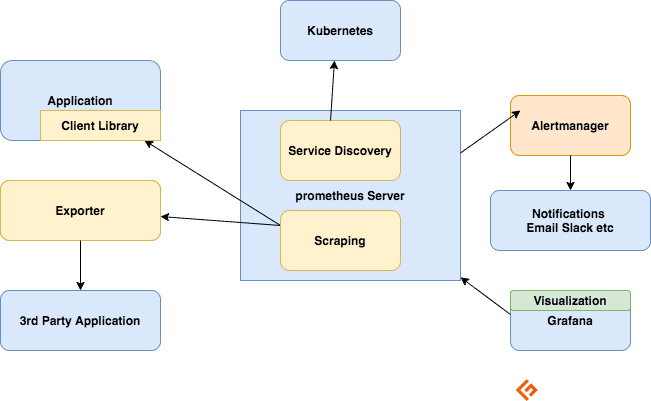
Le serveur Prometheus
Collecte des métriques, les stocke et les rend disponibles pour les requêtes, envoie des alertes en fonction des métriques collectées.
Grattage
Prométhée est un système basé sur la traction. Pour récupérer les métriques, Prometheus envoie une requête HTTP appelée scrape. Il envoie des éraflures aux cibles en fonction de sa configuration.
Chaque cible (définie statiquement ou découverte dynamiquement) est extraite à intervalle régulier (intervalle de grattage). Chaque scrape lit le point de terminaison HTTP /metrics pour obtenir l’état actuel des métriques client et conserve les valeurs dans la base de données de séries temporelles Prometheus.
Il existe d’autres bases de données de séries chronologiques pour les solutions de surveillance que vous voudrez peut-être explorer.
Bibliothèques clientes
Pour surveiller un service, vous devez ajouter une instrumentation à votre code. Il existe des bibliothèques clientes disponibles pour tous les langages et runtimes populaires. En utilisant ces bibliothèques, une fois que vous avez ajouté quelques lignes de code, votre code peut commencer à émettre des métriques. C’est ce qu’on appelle l’instrumentation directe. Ces bibliothèques vous permettent de définir des métriques internes et également de les exposer via un point de terminaison HTTP. Lorsque Prometheus récupère le point de terminaison HTTP des métriques, la bibliothèque cliente envoie les métriques au serveur.
Les bibliothèques clientes officielles sont proposées par Prometheus pour Go, Java, Python et Ruby. Prometheus a un écosystème ouvert. Il existe également des bibliothèques clientes créées par la communauté pour C, PHP, Node.js, C#/.NET et bien d’autres.
Exportateurs
De nombreuses applications exposent des métriques dans un format non Prometheus. Pour ceux-ci et pour les applications que vous ne possédez pas ou pour lesquelles vous n’avez pas accès au code, vous ne pouvez pas ajouter d’instrumentation directement. Par exemple, MySQL, Kafka, JMX, HAProxy et serveur NGINX. Dans ces scénarios, vous utilisez exportateurs.
Un exportateur est un outil que vous déployez avec l’application dont vous souhaitez obtenir des métriques. Un exportateur agit comme un proxy entre l’application et Prometheus. Il recevra les requêtes du serveur Prometheus, collectera les données des journaux d’accès, des journaux d’erreurs de l’application, les transformera au format correct et reviendra enfin au serveur Prometheus.
Certains des exportateurs populaires sont :
- les fenêtres – pour les métriques de serveur Windows
- Nœud – pour les métriques de serveur Linux
- Boîte noire – pour les mesures de performance DNS et site Web
- JMX – pour les métriques d’application basées sur Java
Une fois que les applications ont été instrumentées ou que les exportateurs sont en place, vous devez indiquer à Prometheus où ils se trouvent. Cela peut être fait en utilisant une configuration statique. Dans le cas d’environnements dynamiques, cela ne peut pas être fait ; par conséquent, la découverte de service est utilisée.
Alerte
L’alerte avec Prometheus se compose de deux parties –
Les règles d’alerte envoient des alertes à Alertmanager.
L’Alertmanager gère ensuite ces alertes. Il envoie des notifications à l’aide de nombreuses intégrations prêtes à l’emploi telles que la messagerie électronique, Slack, Hipchat et PagerDuty. L’Alertmanager peut également effectuer le silence ou l’agrégation pour réduire le nombre de notifications.
Voici le guide pour surveiller le serveur Linux à l’aide de Prometheus et du tableau de bord.
Visualisation avec des tableaux de bord
Prometheus dispose d’un certain nombre d’API à l’aide desquelles les requêtes PromQL peuvent produire des données brutes pour les visualisations.
Bien que Prometheus inclue un navigateur d’expressions qui peut être utilisé pour des requêtes ad hoc, le meilleur outil disponible est Grafana. Grafana s’intègre entièrement à Prometheus et peut produire une grande variété de tableaux de bord.
Vous devrez configurer Prometheus comme source de données pour Grafana.
Vous pouvez ajouter des tableaux de bord en :
- Importation de tableaux de bord créés par la communauté
- Construire le vôtre
- Utilisation d’un tableau de bord prédéfini.
Voici à quoi ressemble un tableau de bord d’exportateur de nœud prédéfini :
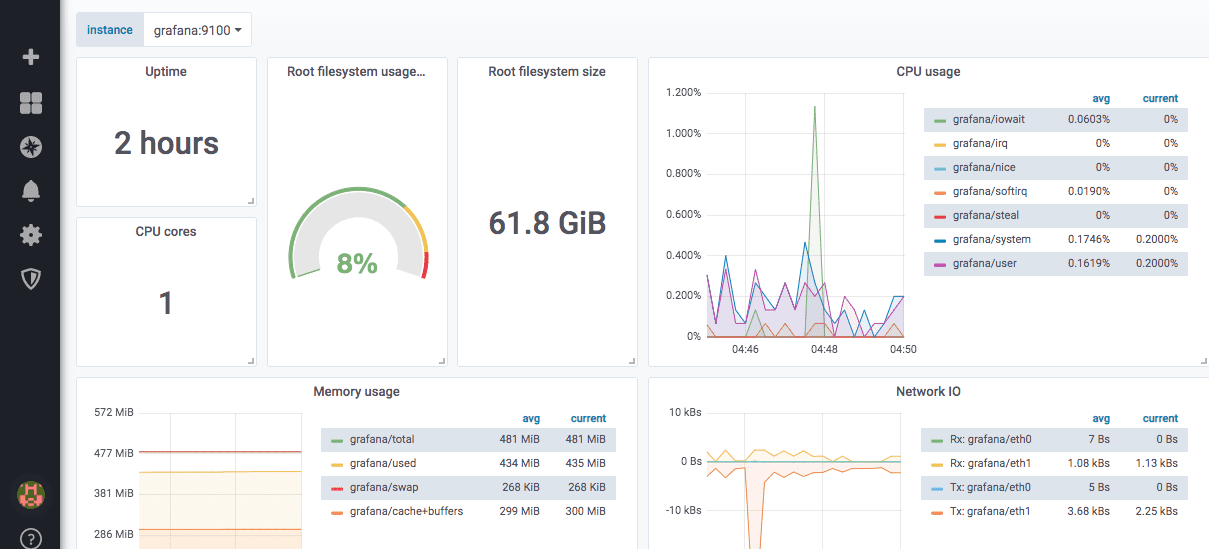
Grafana dispose d’un module worldPing qui vous permet de surveiller les métriques de performance du site et du DNS dans le monde entier.
Sommaire
Prometheus a très peu d’exigences. Il peut être assez simple à exécuter car il s’agit d’un seul binaire avec un fichier de configuration. Il peut gérer des milliers de cibles et ingérer des millions d’échantillons par seconde. Prometheus est conçu pour suivre le système global, la santé et le comportement du système.
Grafana est le meilleur outil disponible pour la visualisation des métriques et s’intègre parfaitement avec Prométhée.