Qu'est-ce que l'apprentissage par renforcement ?
L'apprentissage par renforcement : une exploration approfondie de l'IA
Dans le monde actuel de l'intelligence artificielle (IA), l'apprentissage par renforcement (RL) se démarque comme un domaine de recherche particulièrement fascinant. Les spécialistes de l'IA et de l'apprentissage automatique (ML) consacrent une grande partie de leurs efforts à l'exploration des techniques de RL pour créer des outils et des applications novatrices.
L'apprentissage automatique constitue le socle de toute création d'IA. Les développeurs s'appuient sur diverses approches ML pour perfectionner leurs applications, leurs jeux, et bien d'autres systèmes intelligents. Le ML est un domaine aux multiples facettes, où diverses équipes de développement cherchent sans cesse de nouvelles approches pour l'entraînement des machines.
L'apprentissage par renforcement en profondeur est une de ces méthodes ML prometteuses. Dans ce cadre, les comportements indésirables de la machine sont sanctionnés, tandis que les actions souhaitables sont récompensées. Les experts estiment que cette approche de ML a pour but de pousser l'IA à apprendre à partir de ses propres expériences.
Si vous envisagez de faire carrière dans le domaine de l'intelligence artificielle et de l'apprentissage automatique, il est essentiel de lire ce guide complet sur les méthodes d'apprentissage par renforcement destinées aux applications et aux machines intelligentes.
Qu'est-ce que l'apprentissage par renforcement dans l'apprentissage automatique ?
Le RL consiste à enseigner des modèles d'apprentissage automatique aux programmes informatiques. Par la suite, l'application peut prendre des décisions successives basées sur ces modèles d'apprentissage. Le logiciel apprend à atteindre un but précis dans un environnement qui peut être complexe et incertain. Dans ce type de modèle d'apprentissage automatique, une IA est confrontée à un scénario qui ressemble à un jeu.
L'application IA utilise des essais et des erreurs pour élaborer une solution créative au problème posé. Une fois que l'IA a assimilé les modèles ML appropriés, elle donne l'ordre à la machine qu'elle contrôle d'exécuter certaines tâches précisées par le programmeur.
En fonction de la pertinence de la décision et de l'accomplissement de la tâche, l'IA reçoit une récompense. Cependant, si l'IA fait de mauvais choix, elle encourt des pénalités, par exemple une perte de points de récompense. L'objectif ultime de l'application IA est d'accumuler le maximum de points de récompense pour remporter la partie.
Le programmeur de l'application IA définit les règles du jeu ou la politique de récompenses. Le programmeur fournit aussi le problème que l'IA doit résoudre. Contrairement à d'autres modèles ML, le programme IA ne reçoit aucune indication de la part du développeur.
L'IA doit trouver comment résoudre les défis du jeu pour gagner un maximum de récompenses. L'application peut se servir d'essais et d'erreurs, d'essais aléatoires, de compétences en supercalculateur et de stratégies de réflexion avancées pour trouver une solution.
Il est nécessaire d'équiper le programme d'IA d'une infrastructure informatique performante et de connecter son système de raisonnement à divers scénarios de jeu parallèles et passés. De cette façon, l'IA peut faire preuve d'une créativité critique et de haut niveau que les humains ne peuvent pas imaginer.
Exemples populaires d'apprentissage par renforcement
#1. La défaite du meilleur joueur de go humain
L'IA AlphaGo de DeepMind Technologies, une entité de Google, est un excellent exemple d'apprentissage automatique basé sur le RL. L'IA joue à un jeu de plateau chinois nommé Go. C'est un jeu vieux de 3000 ans axé sur la tactique et la stratégie.
Les développeurs ont utilisé la méthode d'enseignement RL pour AlphaGo. Elle a joué des milliers de parties de Go contre des humains et contre elle-même. Puis, en 2016, elle a vaincu le meilleur joueur de go au monde, Lee Se-dol, dans un match en face-à-face.
#2. La robotique dans le monde réel
Les humains utilisent la robotique depuis longtemps dans les chaînes de production où les tâches sont pré-planifiées et répétitives. Mais, créer un robot polyvalent pour le monde réel où les actions ne sont pas prévues à l'avance représente un défi de taille.
Cependant, l'IA alimentée par l'apprentissage par renforcement pourrait découvrir un itinéraire fluide, navigable et court entre deux emplacements.
#3. Les véhicules autonomes
Les chercheurs travaillant sur les véhicules autonomes utilisent abondamment la méthode RL pour enseigner à leurs IA les compétences suivantes :
- Le choix dynamique du chemin
- L'optimisation de la trajectoire
- La planification des déplacements comme le stationnement et le changement de voie
- L'optimisation des contrôleurs (ECUs), des microcontrôleurs (MCUs), etc.
- L'apprentissage basé sur des scénarios sur les autoroutes
#4. Les systèmes de refroidissement automatisés

Les IA basées sur le RL peuvent contribuer à minimiser la consommation d'énergie des systèmes de refroidissement dans les grands immeubles de bureaux, les centres d'affaires, les centres commerciaux et, plus important encore, les centres de données. L'IA collecte des données provenant de milliers de capteurs de chaleur.
Elle recueille également des données sur les activités humaines et mécaniques. À partir de ces informations, l'IA peut anticiper le potentiel futur de génération de chaleur et activer/désactiver les systèmes de refroidissement de manière appropriée pour économiser de l'énergie.
Comment configurer un modèle d'apprentissage par renforcement
Vous pouvez configurer un modèle RL en vous basant sur les méthodes suivantes :
#1. Approche basée sur la politique
Cette approche permet au programmeur d'IA de trouver la politique optimale pour un maximum de récompenses. Ici, le programmeur n'utilise pas la fonction de valeur. Une fois que la méthode basée sur une politique est définie, l'agent d'apprentissage par renforcement essaie d'appliquer cette politique afin que les actions effectuées à chaque étape permettent à l'IA de maximiser les points de récompense.
Il existe principalement deux types de politiques :
#1. Déterministe : la politique peut produire les mêmes actions dans un état donné.
#2. Stochastique : les actions produites sont déterminées par la probabilité d'occurrence.
#2. Approche basée sur la valeur
L'approche basée sur la valeur, au contraire, aide le programmeur à trouver la fonction de valeur optimale, qui représente la valeur maximale sous une politique dans un état donné. Une fois appliquée, l'agent RL s'attend à un rendement à long terme dans un ou plusieurs états dans le cadre de cette politique.
#3. Approche basée sur un modèle
Dans l'approche RL basée sur un modèle, le développeur d'IA crée une représentation virtuelle de l'environnement. Ensuite, l'agent RL évolue dans cet environnement et en tire des enseignements.
Types d'apprentissage par renforcement
#1. Apprentissage par renforcement positif (PRL)
L'apprentissage positif consiste à ajouter des éléments pour augmenter la probabilité que le comportement souhaité se reproduise. Cette approche d'apprentissage influence de façon positive le comportement de l'agent RL. Le PRL renforce également certains comportements de votre IA.
Le renforcement de l'apprentissage de type PRL devrait préparer l'IA à s'adapter aux changements sur le long terme. Cependant, injecter trop d'apprentissage positif peut conduire à une surcharge d'états, ce qui peut nuire à l'efficacité de l'IA.
#2. Apprentissage par renforcement négatif (NRL)
Lorsque l'algorithme RL aide l'IA à éviter ou à stopper un comportement négatif, elle en tire des leçons et améliore ses actions futures. C'est ce que l'on appelle l'apprentissage négatif. Il ne fournit à l'IA qu'une intelligence limitée pour répondre à certaines exigences comportementales.
Applications concrètes de l'apprentissage par renforcement
#1. Les concepteurs de solutions de commerce électronique ont élaboré des outils personnalisés de suggestion de produits ou de services. Vous pouvez relier l'API de l'outil à votre site d'achat en ligne. Ensuite, l'IA apprendra des utilisateurs individuels et proposera des biens et services adaptés.
#2. Les jeux vidéo en monde ouvert offrent des possibilités illimitées. Cependant, un programme d'IA se trouve derrière le jeu, qui apprend à partir des actions des joueurs et ajuste le code du jeu vidéo pour s'adapter à des situations inconnues.
#3. Les plateformes de trading d'actions et d'investissement basées sur l'IA emploient le modèle RL pour apprendre des variations des actions et des indices mondiaux. Par conséquent, elles créent un modèle de probabilité pour suggérer des actions à acquérir ou à négocier.
#4. Les plateformes de partage de vidéos en ligne comme YouTube, Metacafe, Dailymotion, etc. utilisent des robots IA entraînés sur le modèle RL pour proposer des vidéos personnalisées à leurs utilisateurs.
Apprentissage par renforcement vs. Apprentissage supervisé
L'apprentissage par renforcement vise à entraîner l'agent IA à prendre des décisions de manière séquentielle. En d'autres termes, la sortie de l'IA dépend de l'état de l'entrée actuelle. De même, la prochaine entrée de l'algorithme RL dépendra de la sortie des entrées passées.

Une machine robotisée basée sur l'IA qui joue une partie d'échecs contre un joueur humain est un exemple du modèle d'apprentissage automatique RL.
En revanche, dans l'apprentissage supervisé, le programmeur entraîne l'agent IA à prendre des décisions en fonction des données d'entrée fournies au début ou d'autres données initiales. Les IA de conduite automobile autonome qui reconnaissent des éléments de l'environnement sont un excellent exemple d'apprentissage supervisé.
Apprentissage par renforcement vs. Apprentissage non supervisé
Jusqu'à présent, vous avez compris que la méthode RL pousse l'agent IA à apprendre des politiques du modèle d'apprentissage automatique. Essentiellement, l'IA n'effectuera que les actions pour lesquelles elle obtient le maximum de points de récompense. Le RL aide une IA à s'améliorer par essais et erreurs.
D'un autre côté, dans l'apprentissage non supervisé, le programmeur d'IA fournit au logiciel d'IA des données non étiquetées. De plus, l'instructeur ML ne donne aucune information à l'IA sur la structure des données ou sur ce qu'il faut rechercher dans les données. L'algorithme apprend diverses décisions en classant ses propres observations sur les ensembles de données inconnus donnés.
Formations en apprentissage par renforcement
Maintenant que vous avez appris les bases, voici quelques cours en ligne pour approfondir votre connaissance de l'apprentissage par renforcement. Vous obtiendrez également un certificat que vous pourrez mettre en avant sur LinkedIn ou d'autres plateformes sociales :
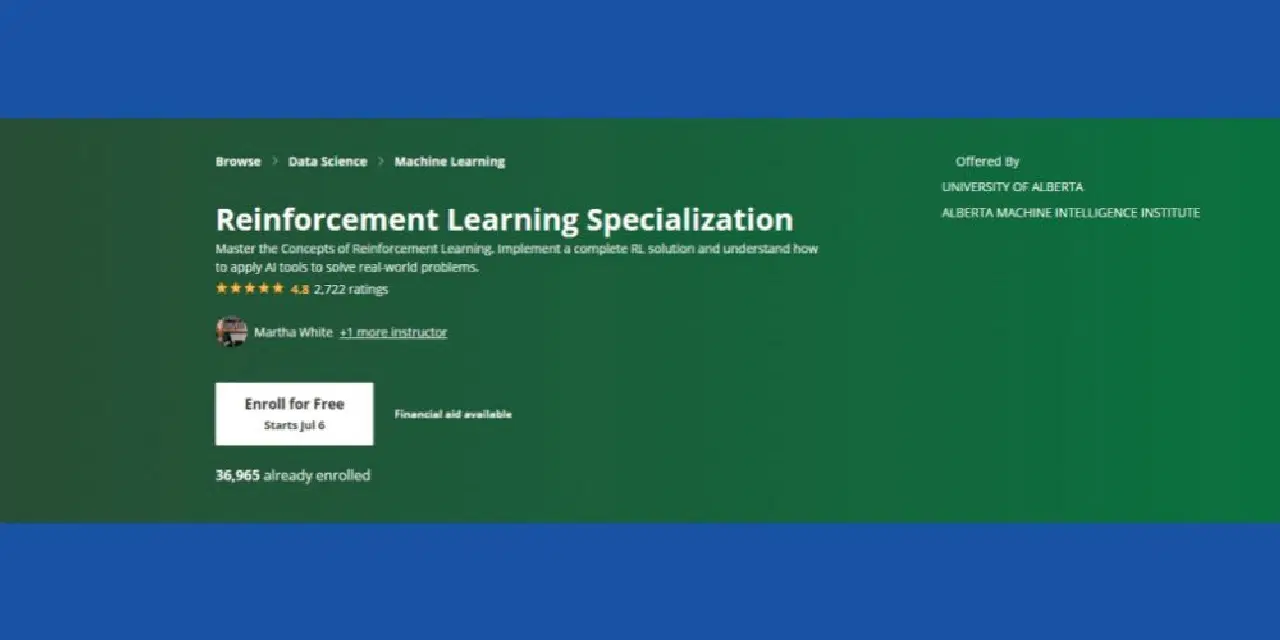
Spécialisation en apprentissage par renforcement : Coursera
Vous souhaitez maîtriser les concepts fondamentaux de l'apprentissage par renforcement dans un contexte de ML ? Vous pouvez essayer ce cours Coursera RL, qui est disponible en ligne et qui propose une option d'apprentissage à votre rythme et de certification. Ce cours vous conviendra si vous possédez les compétences suivantes :
- Connaissances en programmation Python
- Concepts statistiques fondamentaux
- Capacité à transformer des pseudo-codes et des algorithmes en codes Python
- Deux à trois ans d'expérience dans le développement logiciel
- Les étudiants en deuxième année de licence en informatique sont également admissibles
Le cours a une note de 4,8 étoiles et plus de 36 000 étudiants s'y sont déjà inscrits. De plus, une aide financière est proposée, sous réserve que le candidat réponde à certains critères d'éligibilité de Coursera.
Enfin, l'Alberta Machine Intelligence Institute de l'Université d'Alberta propose ce cours (sans attribution de crédits). Des professeurs renommés dans le domaine de l'informatique seront les instructeurs du cours. Vous recevrez un certificat Coursera à l'issue de la formation.
Apprentissage par renforcement de l'IA en Python : Udemy
Si vous travaillez dans le secteur financier ou le marketing numérique et que vous souhaitez développer des outils logiciels intelligents pour ces domaines, vous devriez jeter un coup d'œil à ce cours Udemy sur le RL. En plus des fondamentaux du RL, le contenu de la formation vous expliquera comment créer des solutions RL pour la publicité en ligne et le trading d'actions.

Voici quelques-uns des sujets importants abordés par le cours :
- Un aperçu général du RL
- La programmation dynamique
- Les méthodes de Monte-Carlo
- Les méthodes d'approximation
- Un projet de bourse avec le RL
Plus de 42 000 étudiants ont suivi ce cours à ce jour. Cette ressource d'apprentissage en ligne affiche actuellement une note de 4,6 étoiles, ce qui est plutôt impressionnant. De plus, le cours vise à répondre aux besoins d'une communauté d'étudiants internationaux, car le contenu est disponible en français, anglais, espagnol, allemand, italien et portugais.
Apprentissage par renforcement approfondi en Python : Udemy
Si vous êtes curieux et que vous avez des connaissances de base sur l'apprentissage approfondi et l'intelligence artificielle, vous pouvez essayer cet outil avancé cours RL en Python d'Udemy. Avec une note de 4,6 étoiles attribuée par les étudiants, il s'agit d'un autre cours populaire pour apprendre le RL dans le contexte de l'IA/ML.

Le cours comporte 12 sections et couvre les sujets essentiels suivants :
- OpenAI Gym et les techniques de base du RL
- TD Lambda
- A3C
- Les bases de Théano
- Les principes fondamentaux de TensorFlow
- Le codage Python pour les débutants
L'ensemble du cours nécessitera un investissement en temps de 10 heures et 40 minutes. Outre les textes, il comprend également 79 séances de conférences données par des experts.
Expert en apprentissage par renforcement profond : Udacity
Vous désirez apprendre l'apprentissage automatique avancé auprès des leaders mondiaux de l'IA/ML comme Nvidia Deep Learning Institute et Unity ? Udacity vous permet de réaliser ce rêve. Jetez un œil à ce cours d'apprentissage par renforcement profond pour devenir un expert en ML.

Cependant, vous devez avoir une formation en Python avancé, en statistiques intermédiaires, en théorie des probabilités, en TensorFlow, en PyTorch et en Keras.
Il faudra un apprentissage soutenu pouvant aller jusqu'à 4 mois pour terminer le cours. Tout au long du programme, vous découvrirez des algorithmes RL essentiels comme Deep Deterministic Policy Gradients (DDPG), Deep Q-Networks (DQN), etc.
Dernières réflexions
L'apprentissage par renforcement est la prochaine étape du développement de l'IA. Les agences de développement de l'IA et les entreprises informatiques investissent dans ce domaine pour établir des méthodologies de formation à l'IA fiables et efficaces.
Bien que le RL ait fait d'énormes progrès, il existe encore des opportunités de développement. Par exemple, des agents RL distincts ne partagent pas leurs connaissances entre eux. Ainsi, si vous entraînez une application à conduire une voiture, le processus d'apprentissage sera lent, car les agents RL comme la détection d'objets et le respect du code de la route ne mettront pas leurs données en commun.
Il existe des possibilités d'investir votre créativité et votre expertise en ML dans ce type de défis. L'inscription à des cours en ligne vous permettra d'approfondir votre compréhension des méthodes RL avancées et de leurs applications dans des projets réels.
Une autre piste d'exploration intéressante pour vous concerne les différences entre l'IA, l'apprentissage automatique et l'apprentissage profond.