Probablement la meilleure alternative au stockage CSV : Parquet Data
Avantages du format Parquet pour la gestion des données
Le format Apache Parquet surpasse les méthodes traditionnelles comme CSV en matière de stockage et de récupération de données, grâce à ses nombreux atouts.
Conçu pour accélérer le traitement des données complexes, Parquet répond aux exigences croissantes en matière de données. Cet article explore comment ce format s'adapte aux besoins actuels.
Avant d'analyser en détail Parquet, il est utile de comprendre les caractéristiques des données CSV et les limites qu'elles présentent.
Le stockage CSV : une approche classique
Le format CSV (Comma Separated Values) est très répandu pour structurer les données. Les fichiers CSV, enregistrés avec l'extension .csv, sont organisés en lignes. On peut les consulter et les éditer avec des outils comme Excel, Google Sheets, ou n'importe quel éditeur de texte. Une fois ouverts, les données sont facilement accessibles.
Cependant, cette approche simple a ses limites, surtout pour une gestion de base de données.
Lorsque le volume des données augmente, leur interrogation, gestion et récupération deviennent complexes.
Voici un exemple de données dans un fichier .CSV :
EmpId,First name,Last name, Division 2012011,Sam,Butcher,IT 2013031,Mike,Johnson,Human Resource 2010052,Bill,Matthew,Architect 2010079,Jose,Brian,IT 2012120,Adam,James,Solutions
Dans un tableur comme Excel, ces données apparaissent sous forme de tableau, avec des lignes et des colonnes.
Les limitations du stockage CSV
Les systèmes de stockage basés sur les lignes, comme CSV, sont adéquats pour créer, modifier ou supprimer des données.
Mais qu'en est-il de la lecture efficace des données (l'opération R de CRUD)?
Imaginez un fichier .csv contenant un million de lignes. L'ouverture et la recherche d'informations spécifiques prendraient un temps considérable, ce qui est loin d'être idéal. De plus, les fournisseurs de cloud, tels qu'AWS, facturent en fonction du volume de données analysées ou stockées. Les fichiers CSV, gourmands en espace, peuvent entraîner des coûts élevés.
Le format CSV ne permet pas de stocker les métadonnées, ce qui complique l'analyse des informations.
Quelle solution permet d'optimiser les coûts et les performances pour toutes les opérations CRUD ? Examinons le format Parquet.
Le stockage Parquet : une alternative optimisée
Parquet est un format de stockage open-source. Il est très utilisé dans les écosystèmes Hadoop et Spark. Les fichiers Parquet sont enregistrés avec l'extension .parquet.
Parquet offre une structure de données avancée. Il permet d'optimiser le traitement de données brutes complexes, souvent massives dans les lacs de données, réduisant ainsi le temps de requête.
L'efficacité de Parquet réside dans sa combinaison de stockage hybride, basé sur les lignes et les colonnes, divisant les données horizontalement et verticalement. Il minimise également la surcharge d'analyse.
Grâce à cette organisation, le format Parquet réduit le nombre d'opérations d'E/S et, par conséquent, les coûts.
Parquet stocke également les métadonnées (schéma de données, nombre de valeurs, emplacement des colonnes, valeurs min/max, etc.), accélérant ainsi l'accès aux données. Ces informations sont stockées à différents niveaux du fichier.
Contrairement au format CSV, où il faut parcourir chaque ligne pour trouver des valeurs spécifiques, Parquet permet d'accéder directement à toutes les colonnes requises.
En résumé, Parquet :
- Utilise une structure basée sur les colonnes pour le stockage.
- Est optimisé pour stocker de grands volumes de données complexes.
- Intègre diverses méthodes de compression et d'encodage.
- Réduit le temps d'analyse, le temps de requête, et l'espace disque par rapport au format CSV.
- Minimise les opérations d'E/S, réduisant les coûts de stockage et d'exécution des requêtes.
- Inclut des métadonnées qui facilitent la recherche de données.
- Est open source.
Structure du format Parquet
Avant de présenter un exemple, examinons comment les données sont organisées dans le format Parquet :
Un fichier Parquet peut contenir plusieurs partitions horizontales, appelées groupes de lignes. Chaque groupe est ensuite divisé verticalement en blocs de colonnes. Les données sont stockées sous forme de pages à l'intérieur des blocs de colonnes, avec leurs métadonnées et valeurs codées. Les métadonnées globales du fichier sont enregistrées dans son pied de page.
La division des données en blocs de colonnes facilite l'ajout de nouvelles données. Ces nouvelles valeurs sont codées dans un nouveau bloc et fichier, puis les métadonnées sont mises à jour en conséquence, faisant de Parquet un format flexible.
Parquet supporte la compression de données, avec des techniques de compression de page et d'encodage de dictionnaire. Voici un exemple simple de compression de dictionnaire :
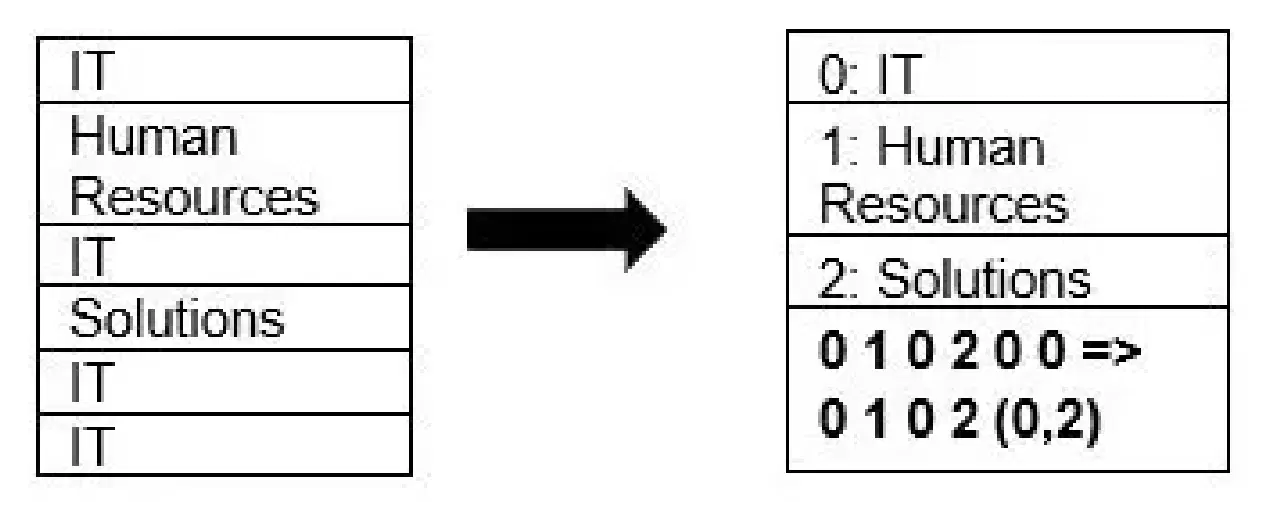
Dans l'exemple ci-dessus, la division "IT" apparaît 4 fois. Le format Parquet remplace "IT" par une valeur plus facile à stocker (0, 1, 2…) et enregistre le nombre de répétitions, ce qui permet de gagner de l'espace. L'interrogation de données compressées est plus rapide.
Comparaison : CSV vs Parquet
Maintenant que nous connaissons bien les formats CSV et Parquet, voici une comparaison directe :
| CSV | Parquet |
| Format de stockage basé sur les lignes. | Hybride de formats basés sur les lignes et les colonnes. |
| Consomme beaucoup d'espace (pas de compression par défaut). Un fichier de 1 To occupera 1 To sur Amazon S3. | Compresse les données lors du stockage, réduisant l'espace. Un fichier de 1 To en Parquet peut n'occuper que 130 Go. |
| Temps d'exécution de requête lent (recherche basée sur les lignes). | Temps de requête environ 34 fois plus rapide (stockage basé sur les colonnes et métadonnées). |
| Nécessite l'analyse de plus de données par requête. | Analyse environ 99% de données en moins pour l'exécution de la requête. |
| Coûts de stockage élevés (facturation basée sur l'espace). | Coûts de stockage réduits (données compressées). |
| Schéma du fichier doit être inféré (source d'erreurs) ou fourni (fastidieux). | Schéma du fichier stocké dans les métadonnées. |
| Adapté aux types de données simples. | Adapté aux types complexes (schémas imbriqués, tableaux, dictionnaires). |
Conclusion
Parquet est plus performant que CSV en termes de coût, de flexibilité et de performances. Il est idéal pour stocker et récupérer des données, en particulier dans un environnement cloud où l'optimisation de l'espace est cruciale. Les principales plateformes comme Azure, AWS et BigQuery supportent le format Parquet.