
Cet article mentionne et explique certaines des meilleures bibliothèques Python pour les scientifiques des données et l’équipe d’apprentissage automatique.
Python est un langage idéal utilisé dans ces deux domaines principalement pour les bibliothèques qu’il propose.
Cela est dû aux applications des bibliothèques Python telles que les E/S d’entrée/sortie de données et l’analyse de données, entre autres opérations de manipulation de données que les scientifiques des données et les experts en apprentissage automatique utilisent pour gérer et explorer les données.
Table des matières
Les bibliothèques Python, qu’est-ce que c’est ?
Une bibliothèque Python est une vaste collection de modules intégrés contenant du code précompilé, y compris des classes et des méthodes, éliminant ainsi le besoin pour le développeur d’implémenter du code à partir de zéro.
Importance de Python dans la science des données et l’apprentissage automatique
Python possède les meilleures bibliothèques à utiliser par les experts en apprentissage automatique et en science des données.
Sa syntaxe est simple, ce qui rend efficace la mise en œuvre d’algorithmes complexes d’apprentissage automatique. De plus, la syntaxe simple raccourcit la courbe d’apprentissage et facilite la compréhension.
Python prend également en charge le développement rapide de prototypes et le test fluide des applications.
La grande communauté de Python est pratique pour les scientifiques des données qui recherchent facilement des solutions à leurs requêtes en cas de besoin.
Quelle est l’utilité des bibliothèques Python ?
Les bibliothèques Python jouent un rôle déterminant dans la création d’applications et de modèles dans l’apprentissage automatique et la science des données.
Ces bibliothèques aident grandement le développeur à réutiliser le code. Par conséquent, vous pouvez importer une bibliothèque pertinente qui implémente une fonctionnalité spécifique dans votre programme autre que de réinventer la roue.
Bibliothèques Python utilisées dans l’apprentissage automatique et la science des données
Les experts en science des données recommandent diverses bibliothèques Python que les passionnés de science des données doivent connaître. En fonction de leur pertinence dans l’application, les experts en apprentissage automatique et en science des données appliquent différentes bibliothèques Python classées en bibliothèques pour le déploiement de modèles, l’extraction et le grattage de données, le traitement de données et la visualisation de données.
Cet article identifie certaines bibliothèques Python couramment utilisées en science des données et en apprentissage automatique.
Regardons-les maintenant.
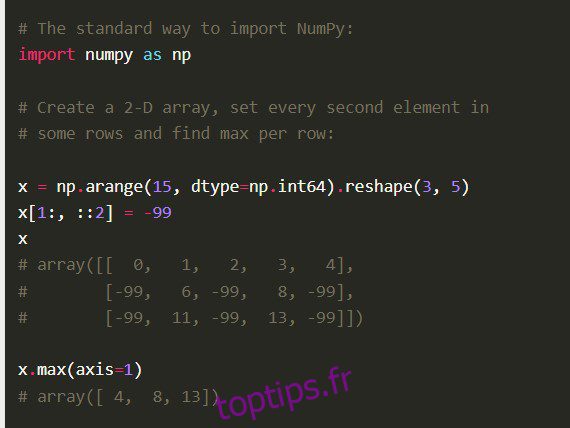
Numpy
La bibliothèque Numpy Python, également le code Python numérique dans son intégralité, est construite avec du code C bien optimisé. Les Data Scientists le préfèrent pour ses calculs mathématiques approfondis et ses calculs scientifiques.
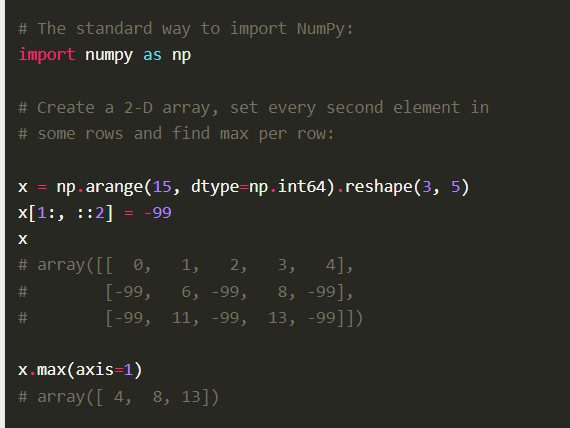
Fonctionnalités
Numpy est livré avec d’autres fonctionnalités complètes telles que la vectorisation des opérations mathématiques, l’indexation et les concepts clés dans la mise en œuvre de tableaux et de matrices.
Pandas
Pandas est une célèbre bibliothèque d’apprentissage automatique qui fournit des structures de données de haut niveau et de nombreux outils pour analyser des ensembles de données massifs sans effort et efficacement. Avec très peu de commandes, cette bibliothèque peut traduire des opérations complexes avec des données.
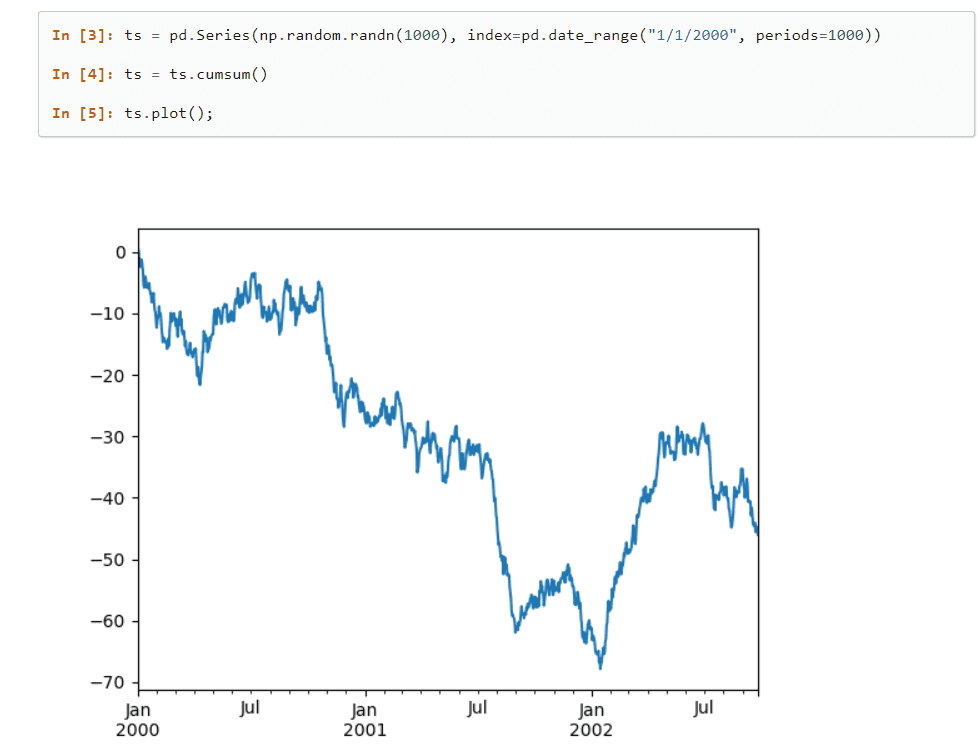
De nombreuses méthodes intégrées qui peuvent regrouper, indexer, récupérer, diviser, restructurer les données et filtrer les ensembles avant de les insérer dans des tables unidimensionnelles et multidimensionnelles ; compose cette bibliothèque.
Principales fonctionnalités de la bibliothèque Pandas
Il est très efficace pour sa bonne fonctionnalité d’analyse de données et sa grande flexibilité.
Matplotlib
La bibliothèque graphique Python Matplotlib 2D peut facilement gérer des données provenant de nombreuses sources. Les visualisations qu’il crée sont statiques, animées et interactives sur lesquelles l’utilisateur peut zoomer, ce qui le rend efficace pour les visualisations et la création de graphiques. Il permet également la personnalisation de la mise en page et du style visuel.
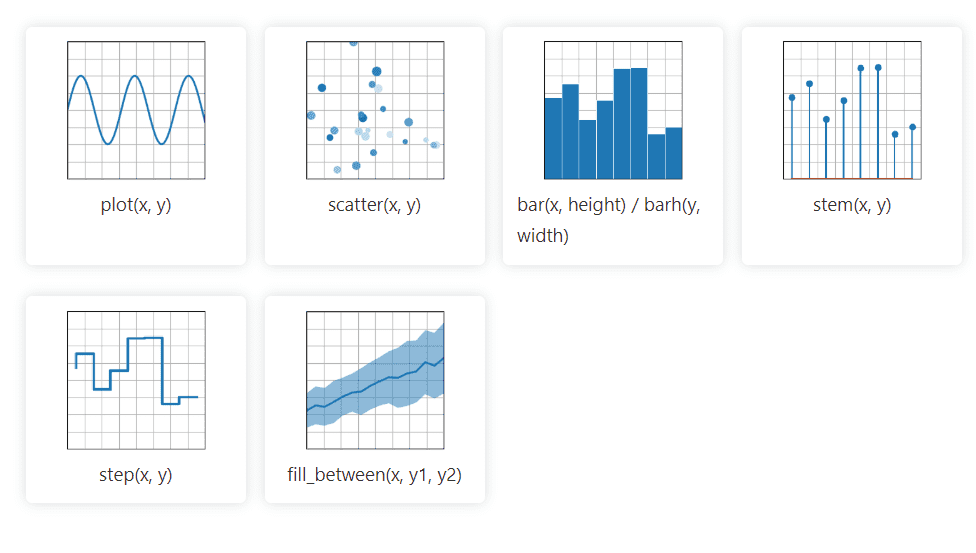
Sa documentation est open source et offre une vaste collection d’outils nécessaires à la mise en œuvre.
Matplotlib importe des classes d’assistance pour implémenter l’année, le mois, le jour et la semaine, ce qui facilite la manipulation des données de séries chronologiques.
Scikit-apprendre
Si vous envisagez une bibliothèque pour vous aider à travailler avec des données complexes, Scikit-learn devrait être votre bibliothèque idéale. Les experts en machine learning utilisent largement Scikit-learn. La bibliothèque est associée à d’autres bibliothèques telles que NumPy, SciPy et matplotlib. Il propose des algorithmes d’apprentissage supervisés et non supervisés qui peuvent être utilisés pour des applications de production.

Fonctionnalités de la bibliothèque Scikit-learn Python
La bibliothèque Scikit-learn est efficace dans l’extraction de caractéristiques à partir d’ensembles de données texte et image. De plus, il est possible de vérifier l’exactitude des modèles supervisés sur des données invisibles. Ses nombreux algorithmes disponibles rendent possible l’exploration de données et d’autres tâches d’apprentissage automatique.
SciPy
SciPy (Scientific Python Code) est une bibliothèque d’apprentissage automatique qui fournit des modules appliqués aux fonctions mathématiques et aux algorithmes largement applicables. Ses algorithmes résolvent les équations algébriques, l’interpolation, l’optimisation, les statistiques et l’intégration.
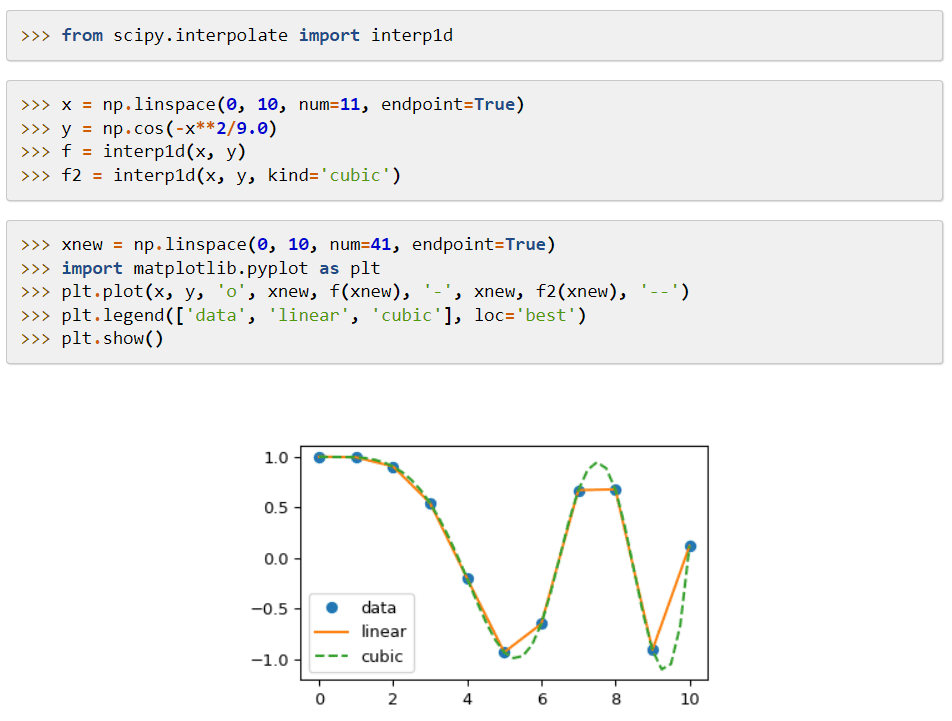
Sa principale caractéristique est son extension à NumPy, qui ajoute des outils pour résoudre les fonctions mathématiques et fournit des structures de données comme des matrices creuses.
SciPy utilise des commandes et des classes de haut niveau pour manipuler et visualiser les données. Ses systèmes de traitement de données et de prototypes en font un outil encore plus efficace.
De plus, la syntaxe de haut niveau de SciPy facilite son utilisation par les programmeurs de tout niveau d’expérience.
Le seul inconvénient de SciPy est qu’il se concentre uniquement sur les objets numériques et les algorithmes ; donc incapable d’offrir une fonction de traçage.
TorchePy
Cette bibliothèque d’apprentissage automatique diversifiée implémente efficacement des calculs de tenseur avec accélération GPU, créant des graphiques de calcul dynamiques et des calculs de gradients automatiques. La bibliothèque Torch, une bibliothèque d’apprentissage automatique open source développée sur C, construit la bibliothèque PyTorch.

Les fonctionnalités clés incluent :
Vous pouvez utiliser PyTorch pour développer des applications NLP.
Keras
Keras est une bibliothèque Python open source d’apprentissage automatique utilisée pour expérimenter les réseaux de neurones profonds.
Il est célèbre pour offrir des utilitaires prenant en charge des tâches telles que la compilation de modèles et la visualisation de graphiques, entre autres. Il applique Tensorflow pour son backend. Alternativement, vous pouvez utiliser Theano ou des réseaux de neurones comme CNTK dans le backend. Cette infrastructure backend l’aide à créer des graphes de calcul utilisés pour mettre en œuvre des opérations.
Principales caractéristiques de la bibliothèque
Les applications de Keras incluent des blocs de construction de réseaux neuronaux tels que des couches et des objectifs, entre autres outils qui facilitent le travail avec des images et des données textuelles.
Né en mer
Seaborn est un autre outil précieux de visualisation de données statistiques.
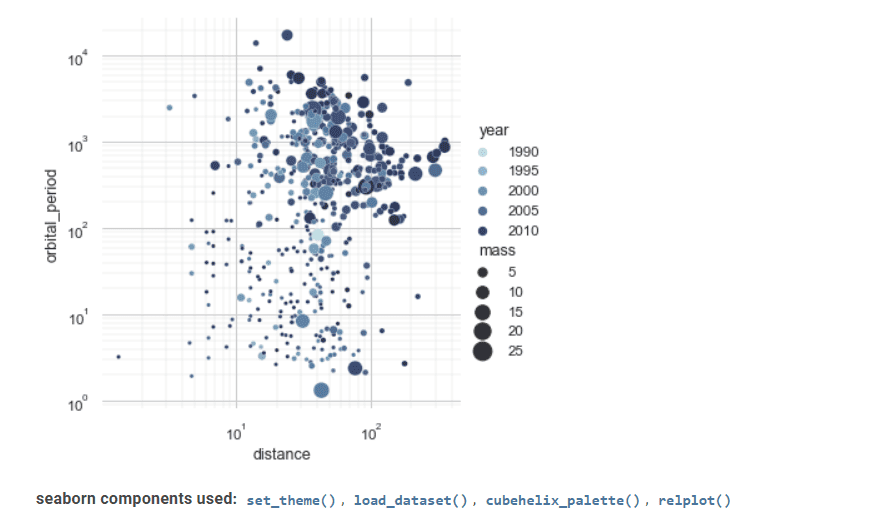
Son interface avancée peut mettre en œuvre des dessins graphiques statistiques attrayants et informatifs.
comploter
Plotly est un outil de visualisation Web 3D basé sur la bibliothèque Plotly JS. Il prend largement en charge divers types de graphiques tels que les graphiques linéaires, les nuages de points et les graphiques sparkline de type boîte.
Son application comprend la création de visualisations de données basées sur le Web dans des blocs-notes Jupyter.
Plotly convient à la visualisation car il peut signaler les valeurs aberrantes ou les anomalies dans le graphique avec son outil de survol. Vous pouvez également personnaliser les graphiques selon vos préférences.
L’inconvénient de Plotly, c’est que sa documentation est obsolète ; par conséquent, l’utiliser comme guide peut être difficile pour l’utilisateur. De plus, il dispose de nombreux outils que l’utilisateur doit apprendre. Il peut être difficile de garder une trace de chacun d’eux.
Fonctionnalités de la bibliothèque Plotly Python
SimpleITK
SimpleITK est une bibliothèque d’analyse d’images qui offre une interface à Insight Toolkit (ITK). Il est basé sur C++ et est open-source.
Fonctionnalités de la bibliothèque SimpleITK
Son interface simplifiée est disponible dans divers langages de programmation tels que R, C#, C++, Java et Python.
Modèle de statistiques
Statsmodel estime des modèles statistiques, implémente des tests statistiques et explore des données statistiques à l’aide de classes et de fonctions.
La spécification des modèles utilise des formules de style R, des tableaux NumPy et des trames de données Pandas.
Scrapy
Ce package open source est un outil privilégié pour récupérer (gratter) et explorer les données d’un site Web. Il est asynchrone et donc relativement rapide. Scrapy a une architecture et des fonctionnalités qui le rendent efficace.
D’un autre côté, son installation diffère selon les systèmes d’exploitation. De plus, vous ne pouvez pas l’utiliser sur des sites Web construits sur JS. De plus, il ne peut fonctionner qu’avec Python 2.7 ou des versions ultérieures.
Les experts en science des données l’appliquent dans l’exploration de données et les tests automatisés.
Fonctionnalités
Oreiller
Pillow est une bibliothèque d’imagerie Python qui manipule et traite des images.
Il ajoute aux fonctionnalités de traitement d’image de l’interpréteur Python, prend en charge divers formats de fichiers et offre une excellente représentation interne.
Les données stockées dans des formats de fichiers de base sont facilement accessibles grâce à Pillow.
Conclusion💃
Cela résume notre exploration de certaines des meilleures bibliothèques Python pour les scientifiques des données et les experts en apprentissage automatique.
Comme le montre cet article, Python propose des packages d’apprentissage automatique et de science des données plus utiles. Python a d’autres bibliothèques que vous pouvez appliquer dans d’autres domaines.
Vous voudrez peut-être connaître certains des meilleurs cahiers de science des données.
Bon apprentissage!