Machine à vecteurs de support (SVM) dans l'apprentissage automatique
La Machine à Vecteurs de Support (SVM) se distingue comme un algorithme d'apprentissage automatique particulièrement prisé. Sa force réside dans son efficacité, notamment lorsqu'il s'agit de traiter des ensembles de données de taille restreinte. Mais, au juste, de quoi parle-t-on ?
Qu'est-ce qu'une Machine à Vecteurs de Support (SVM) ?
Une Machine à Vecteurs de Support est un algorithme de l'apprentissage automatique qui recourt à l'apprentissage supervisé pour l'élaboration d'un modèle de classification binaire. C'est un concept un peu complexe. Cet exposé vise à éclaircir le concept de SVM et sa relation avec le traitement du langage naturel. Avant d'aller plus loin, examinons en détail le fonctionnement d'une Machine à Vecteurs de Support.
Comment fonctionne une SVM ?
Prenons un problème simple de classification, où nous disposons de données caractérisées par deux attributs, x et y, et une sortie – une classification qui peut être "rouge" ou "bleue". Imaginons un jeu de données qui se présenterait comme suit :
Dans un tel cas de figure, l'objectif serait d'établir une frontière de décision, une ligne qui sépare les deux classes de points de données. Voici ce même ensemble de données, agrémenté d'une frontière de décision :
Une telle frontière de décision nous permet de prédire la classe à laquelle appartient un point donné, en fonction de son positionnement par rapport à cette frontière. L'algorithme de la Machine à Vecteurs de Support crée précisément cette frontière de décision optimale pour la classification des points.
Mais, qu'entend-on par "frontière de décision optimale" ?
La frontière de décision idéale est celle qui maximise sa distance par rapport aux vecteurs de support. Les vecteurs de support sont ces points de données de chaque classe qui se trouvent les plus proches de la classe opposée. Ces points sont les plus susceptibles d'être mal classés en raison de leur proximité avec l'autre classe.
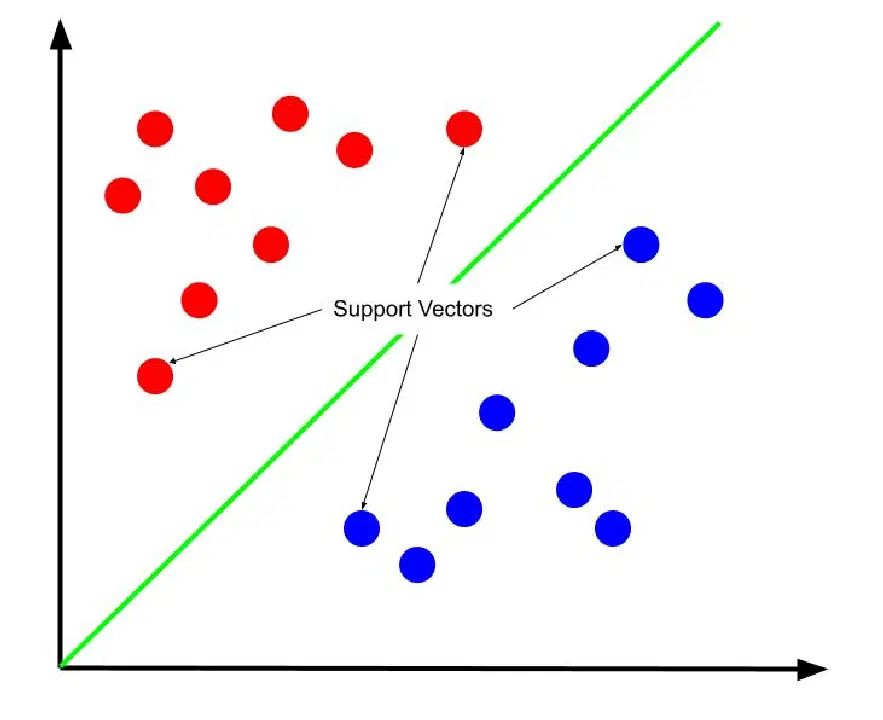
L'apprentissage d'une Machine à Vecteurs de Support consiste donc à identifier une droite qui agrandit au maximum la marge entre les vecteurs de support.
Il est crucial de noter que, étant donné que la frontière de décision est définie par rapport aux vecteurs de support, ce sont eux qui déterminent la position de cette frontière. Les autres points de données sont, de ce fait, superflus. L'apprentissage ne requiert donc que les vecteurs de support.
Dans l'exemple présenté, la frontière de décision prend la forme d'une droite. Ceci est dû au fait que le jeu de données ne comporte que deux caractéristiques. Lorsque le jeu de données possède trois caractéristiques, la frontière de décision se transforme en un plan, plutôt qu'une droite. Et lorsqu'il y a quatre caractéristiques ou plus, la frontière de décision est désignée comme un hyperplan.
Données non linéairement séparables
L'exemple précédent traitait de données simples, pouvant être séparées, après leur représentation graphique, par une frontière de décision linéaire. Examinons un cas où la représentation graphique des données est la suivante :
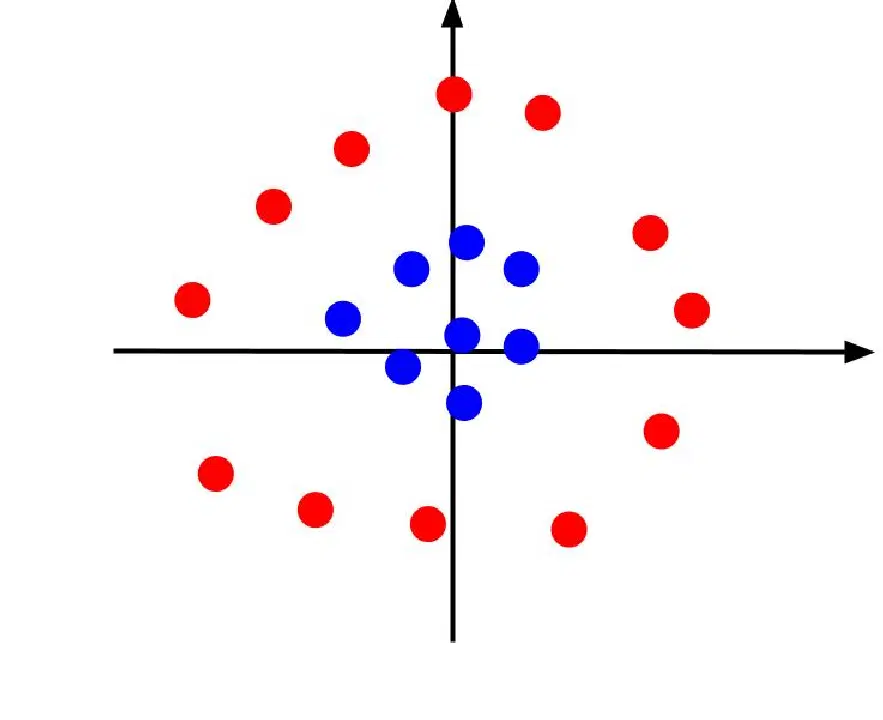
Dans cette situation, il est impossible de séparer les données par une simple droite. Toutefois, nous avons la possibilité de créer une autre caractéristique, appelée z. Cette dernière peut être définie par l'équation : z = x^2 + y^2. Il est possible d'ajouter z comme un troisième axe au plan, le faisant passer en trois dimensions.
En observant le tracé 3D, avec l'axe x à l'horizontale et l'axe z à la verticale, nous obtenons une représentation qui ressemble à ceci :
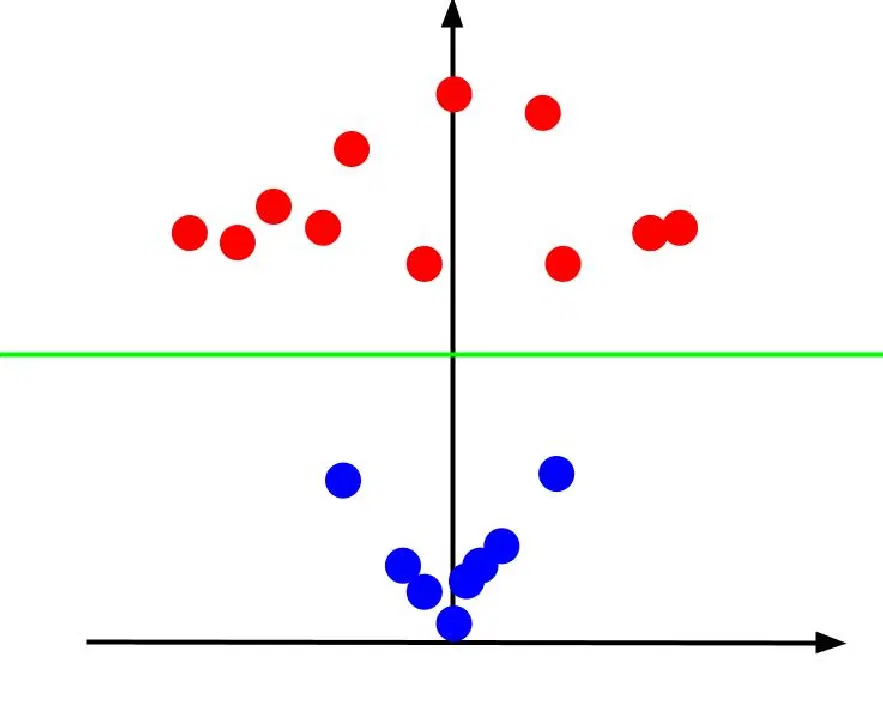
La valeur z symbolise la distance entre un point et l'origine par rapport aux autres points de l'ancien plan XY. Les points bleus, plus proches de l'origine, ont des valeurs z faibles.
À l'inverse, les points rouges, plus éloignés de l'origine, affichent des valeurs z plus élevées. Leur représentation en fonction de ces valeurs z révèle une classification nette, pouvant être délimitée par une frontière de décision linéaire, comme l'illustre l'image.
C'est une idée puissante, centrale dans le fonctionnement des machines à vecteurs de support. Plus globalement, il s'agit de projeter les dimensions dans un espace de plus grande dimension, afin que les points de données puissent être séparés par une frontière linéaire. Ce sont les fonctions de noyau qui se chargent de cette transformation. Il existe de nombreuses fonctions de noyau, telles que sigmoïde, linéaire, non linéaire et RBF.
Pour faciliter cette transformation de caractéristiques, la SVM utilise une astuce appelée "astuce du noyau".
La SVM dans l'apprentissage automatique
La Machine à Vecteurs de Support est un outil parmi d'autres, utilisé dans l'apprentissage automatique, au même titre que les arbres de décision et les réseaux neuronaux. Sa popularité tient à son efficacité, même avec des données moins abondantes que d'autres algorithmes. Elle est fréquemment mise à contribution pour réaliser les tâches suivantes :
- Classification de texte : catégorisation de données textuelles, comme des commentaires ou des avis, en une ou plusieurs catégories
- Détection de visage : analyse d'images dans le but d'identifier des visages, pour des applications telles que l'ajout de filtres en réalité augmentée
- Classification d'images : la Machine à Vecteurs de Support peut classifier des images avec efficacité, par rapport à d'autres approches.
Le défi de la classification de texte
Internet regorge de données textuelles. Une grande part de ces informations est cependant non structurée et non étiquetée. Afin de tirer le meilleur parti de ces données textuelles et d'en améliorer la compréhension, il est nécessaire de procéder à une classification. Voici quelques illustrations de cas où le texte est classé :
- Les tweets sont classés par thèmes, afin que les utilisateurs puissent suivre les sujets de leur choix.
- Les courriels sont classés en catégories : Réseaux sociaux, Promotions ou Spam.
- Les commentaires sont classés en fonction de leur contenu : insultant ou non, sur les forums publics.
Fonctionnement de la SVM avec la classification en langage naturel
La Machine à Vecteurs de Support est utilisée pour classifier le texte, en distinguant ceux qui se rapportent à un sujet donné, de ceux qui n'y appartiennent pas. Cela est réalisé en convertissant d'abord les données textuelles, et en les représentant dans un ensemble de données doté de plusieurs caractéristiques.
Pour ce faire, on peut créer des caractéristiques pour chaque mot de l'ensemble de données. Ensuite, pour chaque point de données textuelles, on enregistre le nombre d'occurrences de chaque mot. Ainsi, s'il y a des mots uniques dans l'ensemble de données, autant de fonctionnalités seront présentes dans le jeu de données.
De plus, on fournit des classifications pour ces points de données. Bien que ces classifications soient sous forme textuelle, la plupart des implémentations de SVM s'attendent à recevoir des étiquettes numériques.
Par conséquent, il est nécessaire de transformer ces étiquettes en chiffres avant l'apprentissage. Une fois le jeu de données préparé, en utilisant ces caractéristiques comme des coordonnées, un modèle SVM peut être utilisé pour classifier le texte.
Création d'une SVM en Python
Pour créer une Machine à Vecteurs de Support (SVM) en Python, vous pouvez faire appel à la classe SVC de la bibliothèque sklearn.svm. Voici un exemple de l'utilisation de la classe SVC pour élaborer un modèle SVM en Python :
from sklearn.svm import SVC
# Charger le jeu de données
X = ... y = ...
# Diviser les données en ensembles d'apprentissage et de test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=19)
# Créer un modèle SVM
model = SVC(kernel="linear")
# Entraîner le modèle sur les données d'apprentissage
model.fit(X_train, y_train)
# Évaluer le modèle sur les données de test
accuracy = model.score(X_test, y_test)
print("Précision : ", accuracy)
Dans cet exemple, nous importons d'abord la classe SVC depuis la bibliothèque sklearn.svm. Ensuite, nous chargeons l'ensemble de données et le divisons en ensembles d'apprentissage et de test.
Puis, nous créons un modèle SVM en instanciant un objet SVC et en spécifiant le paramètre du noyau comme "linéaire". Nous entraînons ensuite le modèle sur les données d'apprentissage grâce à la méthode d'ajustement, et évaluons le modèle sur les données de test via la méthode de score. La méthode de score retourne la précision du modèle, que nous affichons dans la console.
Il est également possible de spécifier d'autres paramètres pour l'objet SVC, tels que le paramètre C, qui contrôle la force de la régularisation, et le paramètre gamma, qui contrôle le coefficient de noyau pour certains noyaux.
Les avantages de la SVM
Voici une liste non exhaustive des avantages que présente l'utilisation des Machines à Vecteurs de Support (SVM) :
- Efficacité : les SVM sont généralement efficaces à l'entraînement, en particulier lorsque le nombre d'échantillons est important.
- Résistance au bruit : les SVM sont relativement insensibles au bruit présent dans les données d'apprentissage, car ils recherchent le classificateur à marge maximale, moins sensible au bruit que d'autres classificateurs.
- Efficacité en matière de mémoire : les SVM ne nécessitent en mémoire qu'un sous-ensemble des données d'entraînement à un instant donné, ce qui les rend plus efficaces en matière de gestion de la mémoire que d'autres algorithmes.
- Efficacité dans les espaces de grande dimension : les SVM peuvent conserver des performances satisfaisantes, même quand le nombre de caractéristiques dépasse le nombre d'échantillons.
- Polyvalence : les SVM peuvent être utilisées pour des tâches de classification et de régression, et peuvent traiter divers types de données, qu'elles soient linéaires ou non linéaires.
À présent, explorons quelques-unes des meilleures ressources pour se familiariser avec la Machine à Vecteurs de Support (SVM).
Ressources d'apprentissage
Une introduction aux Machines à Vecteurs de Support
Cet ouvrage intitulé "Une introduction aux machines à vecteurs de support" présente une approche complète et progressive des méthodes d'apprentissage basées sur le noyau.
Il fournit de solides fondations sur la théorie des machines à vecteurs de support.
Applications des machines à vecteurs de support
Contrairement au précédent, qui abordait l'aspect théorique des machines à vecteurs de support, cet ouvrage intitulé "Applications des machines à vecteurs de support" se concentre sur leurs applications concrètes.
Il explore en détail comment les SVM sont utilisées dans le traitement d'images, la détection de motifs et la vision par ordinateur.
Machines à Vecteurs de Support (Science de l'information et Statistiques)
Le but de cet ouvrage sur les Machines à Vecteurs de Support (Science de l'information et Statistiques) est de proposer une vue d'ensemble des principes qui justifient l'efficacité des Machines à Vecteurs de Support (SVM) dans une grande diversité d'applications.
Les auteurs mettent en évidence plusieurs facteurs qui contribuent au succès des SVM, notamment leur capacité à bien fonctionner avec un nombre limité de paramètres ajustables, leur résistance à différents types d'erreurs et d'anomalies, ainsi que leurs performances de calcul efficaces par rapport à d'autres méthodes.
Apprendre avec les noyaux
"Apprendre avec les noyaux" est un ouvrage qui initie les lecteurs aux Machines à Vecteurs de Support (SVM) et aux techniques de noyau associées.
Il a pour objectif de donner aux lecteurs une compréhension de base des mathématiques et les connaissances nécessaires pour commencer à utiliser les algorithmes du noyau dans l'apprentissage automatique. Ce livre vise à fournir une introduction complète, mais accessible, aux SVM et aux méthodes du noyau.
Les Machines à Vecteurs de Support avec Sci-kit Learn
Ce cours en ligne intitulé "Machines à Vecteurs de Support avec Sci-kit Learn", proposé par le réseau de projets Coursera, enseigne comment implémenter un modèle SVM à l'aide de la célèbre bibliothèque d'apprentissage automatique Sci-Kit Learn.

De plus, vous vous familiariserez avec la théorie sous-jacente des SVM, et vous en déterminerez les forces et les faiblesses. Le cours s'adresse aux débutants et dure environ 2,5 heures.
Les Machines à Vecteurs de Support en Python : concepts et code
Ce cours en ligne payant sur les Machines à Vecteurs de Support en Python, dispensé par Udemy, comprend jusqu'à 6 heures de cours vidéo et s'accompagne d'une certification.

Il aborde les SVM, et la manière de les implémenter avec robustesse en Python. De plus, il traite des applications commerciales des Machines à Vecteurs de Support.
Apprentissage automatique et IA : Machines à Vecteurs de Support en Python
Dans ce cours sur l'apprentissage automatique et l'IA, vous apprendrez comment utiliser les Machines à Vecteurs de Support (SVM) dans différentes applications concrètes, notamment la reconnaissance d'images, la détection de spam, le diagnostic médical et l'analyse de régression.

Vous ferez appel au langage de programmation Python pour implémenter des modèles d'apprentissage automatique pour ces applications.
Conclusion
Dans cet exposé, nous avons fait une brève incursion dans la théorie des machines à vecteurs de support. Nous avons exploré leur utilisation dans l'apprentissage automatique et le traitement du langage naturel.
Nous avons également vu à quoi ressemble leur mise en œuvre à l'aide de scikit-learn. De plus, nous avons évoqué les applications concrètes et les avantages des machines à vecteurs de support.
Bien que cet article ne soit qu'une introduction, les ressources supplémentaires recommandées vous permettront d'approfondir le sujet et d'en apprendre davantage sur les machines à vecteurs de support. Compte tenu de leur polyvalence et de leur efficacité, les SVM méritent d'être comprises pour progresser dans le domaine de la science des données et de l'ingénierie de l'apprentissage automatique.
Vous pouvez ensuite consulter les meilleurs modèles d'apprentissage automatique.