Dans l’univers numérique actuel, en constante évolution, les entreprises sont fortement tributaires des données pour assurer leur croissance. Elles collectent régulièrement divers types d’informations, notamment les interactions avec la clientèle, les chiffres de vente, les revenus, les renseignements sur la concurrence, les données issues de leur site web et bien plus encore.
La gestion de cette masse de données peut s’avérer complexe. Et si cette tâche est mal exécutée, les conséquences peuvent être désastreuses.
C’est là qu’intervient l’orchestration des données.
L’orchestration des données constitue un atout précieux pour gérer et organiser efficacement toutes vos données cruciales.
Elle permet aux entreprises d’exploiter le potentiel des données et d’acquérir un avantage concurrentiel sur le marché.
Dans cet article, nous examinerons en détail l’orchestration des données et la manière dont elle peut bénéficier à votre organisation.
Entrons dans le vif du sujet !
Qu’est-ce que l’orchestration des données ?
L’orchestration des données désigne le processus de collecte, de transformation, d’intégration et de gestion structurée des données provenant de sources multiples.
L’objectif primordial de cette approche est de rationaliser le flux de données issues de diverses sources, afin que les entreprises puissent en tirer le meilleur parti. Il s’agit d’un processus essentiel, incontournable dans le monde moderne axé sur les données.
L’orchestration des données vous offre une vision claire de votre entreprise, de votre clientèle, de votre marché et de vos concurrents, ce qui vous aide à prendre des décisions éclairées et à atteindre les résultats souhaités.
En termes plus simples, l’orchestration des données agit comme un chef d’orchestre qui lit et collecte des données à partir de diverses sources. Elle s’assure que toutes les informations contribuent à une vision globale et précise des performances de votre entreprise.
Avantages de l’orchestration des données
L’orchestration des données procure de nombreux avantages aux organisations, comme exposé ci-dessous.
Amélioration de la prise de décision
Grâce à l’orchestration des données, vous disposez d’un ensemble d’informations unifié et bien structuré. Cela facilite la prise de décisions éclairées, car même les données les plus brutes et complexes peuvent être interprétées avec cette technique.
Une meilleure expérience client
Une compréhension approfondie du comportement, des préférences et des retours de vos clients vous permet de mieux les servir. L’orchestration des données vous permet de mener des actions ciblées, menant à une expérience client améliorée.
Efficacité opérationnelle accrue
L’orchestration des données réduit le temps consacré à la collecte et à l’unification manuelle des données. Elle diminue les efforts manuels, minimise les silos de données et rationalise les données de manière automatique et efficace.
Économies
L’orchestration des données basée sur le cloud offre des options flexibles de stockage et de traitement. Ainsi, vous évitez les frais supplémentaires et ne payez que pour ce dont vous avez besoin et ce que vous utilisez.
Un avantage concurrentiel
En exploitant les informations issues de l’orchestration des données, vous êtes en mesure de prendre des décisions plus judicieuses et plus rapides que vos concurrents. Vous pouvez ainsi anticiper les opportunités cachées et répondre de manière proactive aux tendances du marché.
Évolutivité
L’orchestration des données peut gérer l’augmentation des charges de travail à mesure que le volume de données croît. Elle s’adaptera donc de façon fluide à la croissance de votre entreprise.
Comment fonctionne l’orchestration des données ?

Le processus d’orchestration des données implique la gestion et la coordination des données au sein de votre organisation. Cela comprend la collecte de données issues de différentes sources, leur transformation en un format simple et l’automatisation du flux de travail.
L’orchestration des données vous donne les moyens de prendre des décisions commerciales éclairées en utilisant les données comme guide. Elle améliore l’efficacité de vos opérations et facilite la collaboration entre les différentes équipes et départements de votre organisation.
Elle permet un transfert, une analyse et une diffusion fluides des données, vous aidant ainsi à prendre des décisions éclairées.
Phases de l’orchestration des données
L’orchestration des données est un processus complexe qui implique une série d’étapes interdépendantes. Chaque phase est indispensable à la collecte, au traitement et à l’analyse efficaces des données.
Examinons de plus près chacune de ces étapes :
#1. Collecte de données
Le parcours d’orchestration des données débute avec la phase de collecte. Il s’agit de l’étape fondatrice de tout le processus, où les données sont recueillies à partir de nombreuses sources. Ces sources peuvent être aussi variées que des bases de données, des API, des applications et des fichiers externes.

Les données collectées peuvent être structurées, suivant un format spécifique, ou non structurées, n’ayant pas de modèle défini. La qualité, l’exactitude et la pertinence des données recueillies à cette étape influencent considérablement les étapes suivantes de l’orchestration des données.
Par conséquent, il est essentiel de disposer de stratégies et d’outils de collecte robustes afin de garantir l’obtention d’informations pertinentes et de haute qualité.
#2. Ingestion des données
La phase d’ingestion des données consiste à importer et à charger les informations collectées dans un espace de stockage centralisé, souvent un entrepôt de données.
Cet emplacement central fait office de point de convergence où les données provenant de différentes sources sont regroupées. Cette consolidation rationalise la gestion et le traitement des informations, ce qui vous permet de les manipuler et de les utiliser efficacement.
Pour assurer un transfert précis de toutes les données pertinentes vers l’espace de stockage central, il est impératif que le processus d’ingestion se déroule de manière fluide et sans erreur.
#3. Intégration et transformation des données
La troisième phase de l’orchestration des données consiste à intégrer et à transformer les données collectées afin de les rendre utilisables pour l’analyse. L’intégration des données regroupe les données issues de diverses sources afin de présenter des informations cohérentes et significatives.

Ce processus est crucial pour éliminer les silos de données et garantir que toutes les informations sont accessibles et exploitables.
Quant à la transformation des données, elle consiste à gérer les valeurs manquantes, à résoudre les incohérences et à convertir les données dans un format standardisé pour faciliter l’analyse. Ce processus essentiel améliore la qualité des données et leur aptitude à l’analyse.
#4. Stockage et gestion des données
Une fois les données intégrées et transformées, l’étape suivante est de les stocker dans un système approprié.
De gros volumes de données peuvent nécessiter des systèmes de stockage distribués, tandis que les données à grande vitesse peuvent exiger des capacités de traitement en temps réel. Le processus de gestion des données comprend la mise en place de contrôles d’accès, la définition de politiques de gouvernance des données et l’organisation des données pour permettre une analyse efficace.
Il est crucial de s’assurer que les données sont stockées de manière sécurisée, organisées de façon adéquate et facilement accessibles pour l’analyse au cours de cette étape.
#5. Traitement et analyse des données
Le traitement et l’analyse des données impliquent l’exécution de flux de données pour effectuer diverses tâches. Ces tâches peuvent inclure le filtrage, le tri, l’agrégation et la fusion d’ensembles de données.

Selon les besoins de votre entreprise, vous avez le choix entre deux types de traitement : les méthodes de traitement par flux en temps réel ou par lots. Une fois traitées, les données sont prêtes à être analysées à l’aide de diverses plateformes, comme l’informatique décisionnelle, les outils de visualisation de données ou l’apprentissage automatique.
Cette étape revêt une importance capitale pour extraire des informations précieuses des données et favoriser la prise de décision basée sur les données.
#6. Mouvement et distribution des données
Selon les besoins de votre entreprise, il peut être nécessaire de déplacer les données vers différents systèmes à des fins spécifiques.
Le déplacement des données implique la transmission ou la réplication sécurisée des informations vers des partenaires externes ou d’autres systèmes au sein de l’organisation. Cette phase garantit que les données sont disponibles là où vous en avez besoin, que ce soit pour un traitement ultérieur, une analyse ou la création de rapports.
#7. Gestion des flux de travail
L’automatisation des flux de travail réduit les interventions manuelles et les erreurs, améliorant ainsi l’efficacité du traitement des données.
La plupart des outils d’orchestration de données offrent des fonctionnalités de surveillance des flux de travail, permettant ainsi des opérations fluides et efficaces. Cette phase joue un rôle crucial pour garantir le bon déroulement de l’ensemble du processus d’orchestration des données.
#8. Sécurité des données

Pour garantir la sécurité des données, il est nécessaire de mettre en place des contrôles d’accès et des mécanismes d’authentification. Ces mesures protègent les informations précieuses contre tout accès non autorisé et contribuent à garantir la conformité aux réglementations sur les données et aux politiques internes.
En préservant l’intégrité et la confidentialité des données tout au long de leur cycle de vie, vous assurez un environnement sécurisé pour les informations sensibles. Cette phase est essentielle pour maintenir la confiance des clients et prévenir les intentions malveillantes.
#9. Surveillance et optimisation des performances
Une fois le processus d’orchestration des données mis en place, la surveillance des flux et des performances est essentielle. Cela permet d’identifier les goulets d’étranglement, les problèmes d’utilisation des ressources et les défaillances potentielles.
Cette phase implique l’analyse des mesures de performance et l’optimisation des processus pour améliorer l’efficacité. Cette surveillance et cette optimisation continues contribuent à faire de l’orchestration des données un processus efficace et efficient.
#dix. Rétroaction et amélioration continue
L’orchestration des données est un processus itératif. Elle nécessite de recueillir les commentaires des analystes, des parties prenantes et des utilisateurs finaux pour identifier les points d’amélioration et affiner les flux de données existants.
Cette boucle de rétroaction garantit que le processus d’orchestration évolue et s’améliore en permanence, répondant ainsi aux besoins changeants de votre entreprise.
Cas d’utilisation de l’orchestration des données
L’orchestration des données trouve une application dans divers secteurs pour une variété de cas d’utilisation.
Commerce électronique et vente au détail

L’orchestration des données aide le secteur du commerce électronique et de la vente au détail à gérer de gros volumes de données produits, d’informations d’inventaire et d’interactions avec les clients. Elle les aide également à intégrer les données des boutiques en ligne, des systèmes de point de vente et des plateformes de gestion de la chaîne d’approvisionnement.
Santé et sciences de la vie
L’orchestration des données joue un rôle essentiel dans le secteur de la santé et des sciences de la vie. Elle les aide à gérer, à intégrer et à analyser en toute sécurité les dossiers de santé électroniques, les données sur les dispositifs médicaux et les études de ressources. Elle contribue également à l’interopérabilité des données, au partage des informations sur les patients et aux progrès de la recherche médicale.
Secteur financier
Les services financiers utilisent diverses données financières telles que les enregistrements de transactions, les données de marché, les informations sur les clients, etc. L’orchestration des données permet d’améliorer leur gestion des risques, la détection des fraudes et la conformité réglementaire.
Ressources humaines
Les services RH peuvent utiliser l’orchestration des données pour consolider et analyser les données des employés, les mesures de performance et les informations de recrutement. Elle contribue également à la gestion des talents, à l’engagement des employés et à la planification des effectifs.
Médias et divertissement

Le secteur des médias et du divertissement englobe la diffusion de contenu sur diverses plateformes. L’orchestration des données permet de créer facilement des publicités ciblées, des moteurs de recommandation de contenu et des analyses d’audience.
Gestion de la chaîne logistique
La gestion de la chaîne d’approvisionnement comprend les données des fournisseurs, des prestataires logistiques et des systèmes d’inventaire. L’orchestration des données permet d’intégrer toutes ces informations et d’assurer un suivi en temps réel des produits.
Meilleures plateformes d’orchestration de données
Maintenant que vous avez une idée de l’orchestration des données, parlons des meilleures plateformes disponibles.
#1. Flyte

Flyte est une plateforme complète d’orchestration des flux de travail conçue pour unifier de façon transparente les données, l’apprentissage automatique (ML) et les données d’analyse. Ce système basé sur le cloud pour l’apprentissage automatique et le traitement des données peut vous aider à gérer les informations avec fiabilité et efficacité.
Flyte intègre une programmation open source, structurée et une solution distribuée. Elle vous permet d’utiliser des flux de travail simultanés, évolutifs et faciles à gérer pour les tâches d’apprentissage automatique et de traitement des données.
L’un des aspects uniques de Flyte est son utilisation de tampons de protocole comme langage de spécification pour définir ces flux de travail et ces tâches, ce qui en fait une solution flexible et adaptable pour divers besoins en matière de données.
Principales caractéristiques
- Facilite l’expérimentation rapide à l’aide d’un logiciel de production
- Conçu dans un souci d’évolutivité pour gérer les charges de travail et les besoins en ressources
- Permet aux spécialistes des données et aux scientifiques de créer des flux de travail indépendamment à l’aide du SDK Python
- Fournit des flux de travail extrêmement flexibles, avec un lignage des données de bout en bout et des composants réutilisables
- Offre une plateforme centralisée pour gérer le cycle de vie des flux de travail
- Nécessite une maintenance minimale
- Soutenu par une communauté dynamique
- Offre une gamme d’intégrations pour un processus de développement de flux de travail rationalisé
#2. Préfet
Découvrez Préfet, la solution de gestion des flux de travail à la pointe de la technologie, pilotée par le moteur open source Prefect Core. Elle représente le summum de la gestion des flux de travail, avec ses capacités avancées.

Prefect est spécialement conçu pour vous aider à gérer de manière transparente les tâches complexes impliquant des données, avec la simplicité et l’efficacité comme piliers. Avec Prefect à votre disposition, organisez sans effort vos fonctions Python en unités de travail gérables, tout en bénéficiant de capacités de surveillance et de coordination complètes.
L’une des caractéristiques remarquables de Prefect est sa capacité à créer des flux de travail robustes et dynamiques, vous permettant de vous adapter en douceur aux changements de leur environnement. En cas d’événements imprévus, Prefect récupère gracieusement, assurant une gestion transparente des données.
Cette adaptabilité fait de Prefect un choix idéal pour les situations où la flexibilité est cruciale. Avec les tentatives automatiques, l’exécution distribuée, la planification, la mise en cache et plus encore, Prefect devient un outil indispensable, capable de relever tous les défis liés aux données.
Principales caractéristiques
- Automatisation pour une observabilité et un contrôle en temps réel
- Une communauté dynamique pour le soutien et le partage des connaissances
- Documentation complète pour la création d’applications de données puissantes
- Forum de discussion pour les questions relatives à Prefect
#3. Control-M
Control-M est une solution robuste qui connecte, automatise et orchestre les flux de travail d’applications et de données dans des environnements cloud sur site, privés et publics.
Cet outil garantit que les tâches sont exécutées de manière cohérente et dans les délais, ce qui en fait une solution fiable si vous avez besoin d’une gestion des données cohérente et efficace. Avec une interface uniforme et une vaste gamme de modules, les utilisateurs peuvent facilement gérer toutes leurs opérations, y compris les transferts de fichiers, les applications, les sources de données et l’infrastructure.

Vous pouvez rapidement configurer Control-M sur le cloud, en utilisant les capacités des services basés sur le cloud. Cela en fait une solution polyvalente et adaptable pour divers besoins en matière de données.
Principales caractéristiques
- Capacités opérationnelles avancées pour le développement et les opérations
- Gestion proactive des SLA avec analyse prédictive intelligente
- Prise en charge robuste des audits, de la conformité et de la gouvernance
- Stabilité éprouvée pour passer de quelques dizaines à des millions de tâches sans aucun temps d’arrêt
- Approche « Jobs-as-Code » pour faire évoluer la collaboration entre Dev et Ops
- Flux de travail simplifiés dans les environnements hybrides et multi-cloud
- Mouvement et visibilité sécurisés, intégrés et intelligents des fichiers
#4. Datacoral
Datacoral est l’un des principaux fournisseurs d’une pile complète d’infrastructures de données pour le Big Data. Il peut collecter des données provenant de diverses sources en temps réel, sans effort manuel. Une fois collectées, il organise automatiquement ces informations dans un moteur de requête de votre choix.
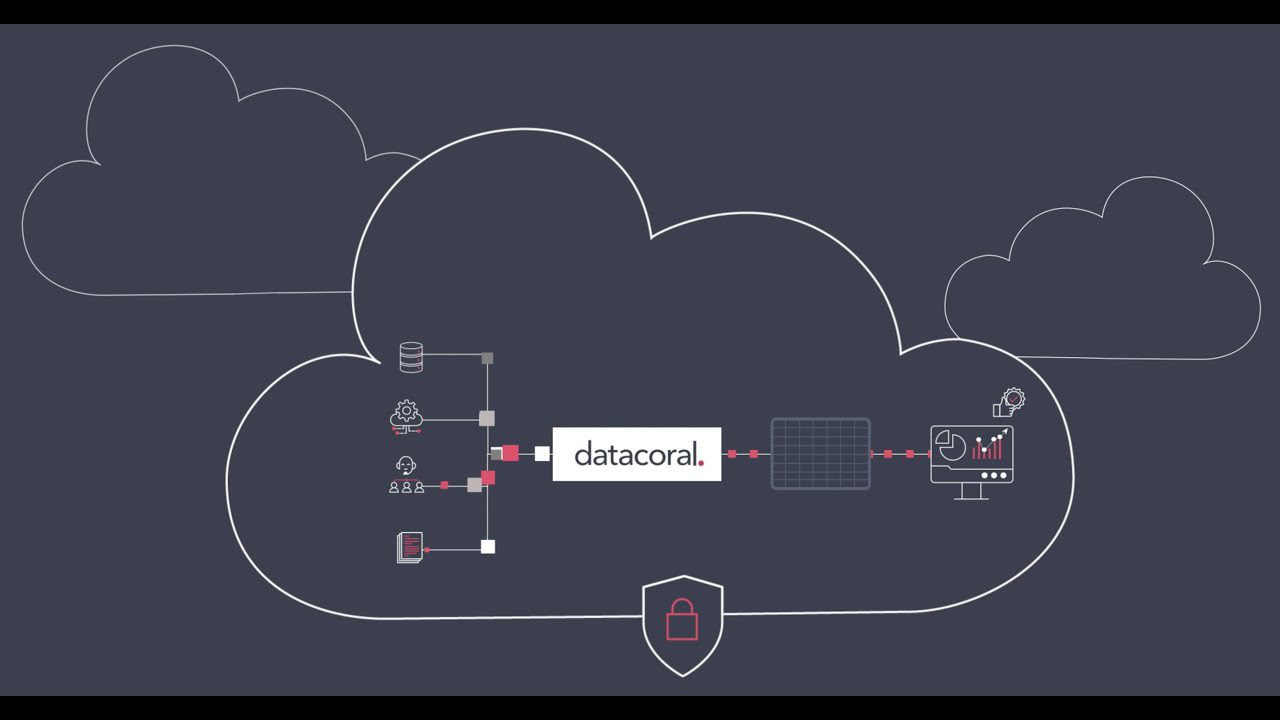
Après avoir obtenu des informations précieuses, vous pouvez utiliser les données à des fins diverses. Le langage est axé sur les données, permettant un accès en temps réel aux sources de données pour n’importe quel moteur de requête. Il sert également d’outil pour surveiller la fraîcheur des données et assurer leur intégrité, ce qui en fait une solution idéale si vous avez besoin d’une gestion fiable et efficace des données.
Principales caractéristiques
- Connecteurs de données sans code pour un accès sécurisé et fiable
- Architecture axée sur les métadonnées pour une vision globale des données
- Extraction de données personnalisable avec une visibilité totale sur la fraîcheur et la qualité des données
- Installation sécurisée dans votre VPC
- Vérifications de la qualité des données prêtes à l’emploi
- Connecteurs CDC pour les bases de données telles que PostgreSQL et MySQL
- Conçu pour évoluer avec un cadre simplifié pour les intégrations de données et les pipelines basés sur le cloud
#5. Dagster
Dagster est une plateforme d’orchestration open source de nouvelle génération pour le développement, la production et la surveillance des actifs de données.

L’outil aborde l’ingénierie des données de A à Z, couvrant l’ensemble du cycle de vie du développement, du développement initial, au déploiement et à la surveillance continue. Dagster est une solution complète et globale si vous avez besoin d’une gestion de données efficace et fiable.
Principales caractéristiques
- Fournit une lignée et une observabilité intégrées
- Utilise un modèle de programmation déclaratif pour faciliter la gestion du flux de travail
- Offre la meilleure testabilité de sa catégorie pour des flux de travail fiables et précis
- Dagster Cloud pour les déploiements sans serveur ou hybrides, la ramification native et la CI/CD prête à l’emploi
- S’intègre aux outils que vous utilisez déjà et peut être déployé sur votre infrastructure
Conclusion
L’orchestration des données est un excellent moyen de rationaliser et d’optimiser l’ensemble du processus de gestion des données. Elle simplifie la façon dont les entreprises gèrent leurs informations, de la collecte et de la préparation à l’analyse et à l’utilisation efficaces.
Elle permet aux entreprises de collaborer de manière fluide avec différentes sources de données, applications et équipes. Par conséquent, vous constaterez une prise de décision plus rapide et plus précise, une productivité améliorée et une amélioration des performances globales.
Par conséquent, choisissez l’un des outils d’orchestration de données ci-dessus en fonction de vos préférences et de vos exigences, et profitez de leurs avantages.
Vous pouvez également explorer certains outils d’orchestration de conteneurs pour DevOps