

ETL signifie Extraire, Transformer et Charger. Les outils ETL extraient les données de diverses sources et les transforment en un format intermédiaire adapté aux systèmes cibles ou aux exigences du modèle de données. Et enfin, ils chargent les données dans une base de données cible, un entrepôt de données ou même un lac de données.
Je me souviens d’il y a 15 à 20 ans, lorsque le terme ETL était quelque chose que seuls quelques-uns comprenaient. Lorsque divers travaux par lots personnalisés ont atteint leur apogée sur le matériel sur site.
De nombreux projets ont fait une certaine forme d’ETL. Même s’ils ne le savaient pas, ils devraient l’appeler ETL. Pendant ce temps, chaque fois que j’expliquais une conception qui impliquait des processus ETL, et que je les appelais et les décrivais de cette façon, cela ressemblait presque à une technologie d’un autre monde, quelque chose de très rare.
Mais aujourd’hui, les choses sont différentes. La migration vers le cloud est la priorité absolue. Et les outils ETL sont la pièce très stratégique de l’architecture de la plupart des projets.
Au final, migrer vers le cloud signifie prendre les données sur site comme source et les transformer en bases de données cloud sous une forme aussi compatible que possible avec l’architecture cloud. Exactement le travail de l’outil ETL.
Table des matières
Histoire d’ETL et comment il se connecte au présent
Source : aws.amazon.com
Les fonctions principales d’ETL étaient toujours les mêmes.
Les outils ETL extraient des données de diverses sources (qu’il s’agisse de bases de données, de fichiers plats, de services Web ou, plus récemment, d’applications basées sur le cloud).
Cela signifiait généralement prendre des fichiers sur le système de fichiers Unix en tant qu’entrée et prétraitement, traitement et post-traitement.
Vous pouvez voir le modèle réutilisable des noms de dossier comme :
- Saisir
- Sortir
- Erreur
- Archive
Sous ces dossiers, une autre structure de sous-dossiers, principalement basée sur les dates, existait également.
C’était juste la manière standard de traiter les données entrantes et de les préparer pour le chargement dans une sorte de base de données.
Aujourd’hui, il n’y a pas de systèmes de fichiers Unix (pas de la même manière qu’avant) – peut-être même pas de fichiers. Il existe maintenant des API – des interfaces de programmation d’applications. Vous pouvez, mais vous n’avez pas besoin d’avoir un fichier comme format d’entrée.
Tout peut être stocké dans la mémoire cache. Il peut toujours s’agir d’un fichier. Quoi qu’il en soit, il doit suivre un format structuré. Dans la plupart des cas, cela signifie le format JSON ou XML. Dans certains cas, l’ancien bon format de valeurs séparées par des virgules (CSV) le fera également.
Vous définissez le format d’entrée. Que le processus implique également la création de l’historique des fichiers d’entrée ne dépend que de vous. Ce n’est plus une étape standard.
Transformation
Les outils ETL transforment les données extraites dans un format approprié pour l’analyse. Cela inclut le nettoyage des données, la validation des données, l’enrichissement des données et l’agrégation des données.
Comme c’était le cas auparavant, les données passaient par une logique personnalisée complexe d’étapes procédurales de mise en scène des données Pro-C ou PL/SQL, de transformation des données et de stockage du schéma cible des données. Il s’agissait d’un processus standard aussi obligatoire que celui de séparer les fichiers entrants en sous-dossiers en fonction de l’étape de traitement du fichier.
Pourquoi était-ce si naturel si c’était aussi fondamentalement faux en même temps ? En transformant directement les données entrantes sans stockage permanent, vous perdiez le plus grand avantage des données brutes : l’immuabilité. Les projets ont simplement jeté cela sans aucune chance de reconstruction.
Bien devinez quoi. Aujourd’hui, moins vous effectuez de transformations de données brutes, mieux c’est. Pour le premier stockage de données dans le système, c’est-à-dire. Il se peut que la prochaine étape soit une modification sérieuse des données et une transformation du modèle de données, bien sûr. Mais vous voulez avoir stocké les données brutes dans une structure aussi inchangée et atomique que possible. Un grand changement par rapport aux temps sur site, si vous me demandez.
Charger
Les outils ETL chargent les données transformées dans une base de données ou un entrepôt de données cible. Cela inclut la création de tables, la définition de relations et le chargement de données dans les champs appropriés.
L’étape de chargement est probablement la seule qui suit le même schéma pour les âges. La seule différence est une base de données cible. Alors qu’auparavant, c’était Oracle la plupart du temps, il peut désormais s’agir de tout ce qui est disponible dans le cloud AWS.
ETL dans l’environnement cloud d’aujourd’hui
Si vous envisagez de transférer vos données sur site vers le cloud (AWS), vous avez besoin d’un outil ETL. Cela ne va pas sans elle, c’est pourquoi cette partie de l’architecture cloud est probablement devenue la pièce la plus importante du puzzle. Si cette étape est mauvaise, toute autre chose suivra par la suite, partageant la même odeur partout.
Et bien qu’il existe de nombreuses compétitions, je me concentrerais maintenant sur les trois avec lesquelles j’ai le plus d’expérience personnelle :
- Service de migration de données (DMS) – un service natif d’AWS.
- Informatica ETL – probablement le principal acteur commercial dans le monde ETL, transformant avec succès son activité du sur site au cloud.
- Matillion pour AWS – un acteur relativement nouveau dans les environnements cloud. Non natif d’AWS, mais natif du cloud. Avec rien comme l’histoire comparable à Informatica.
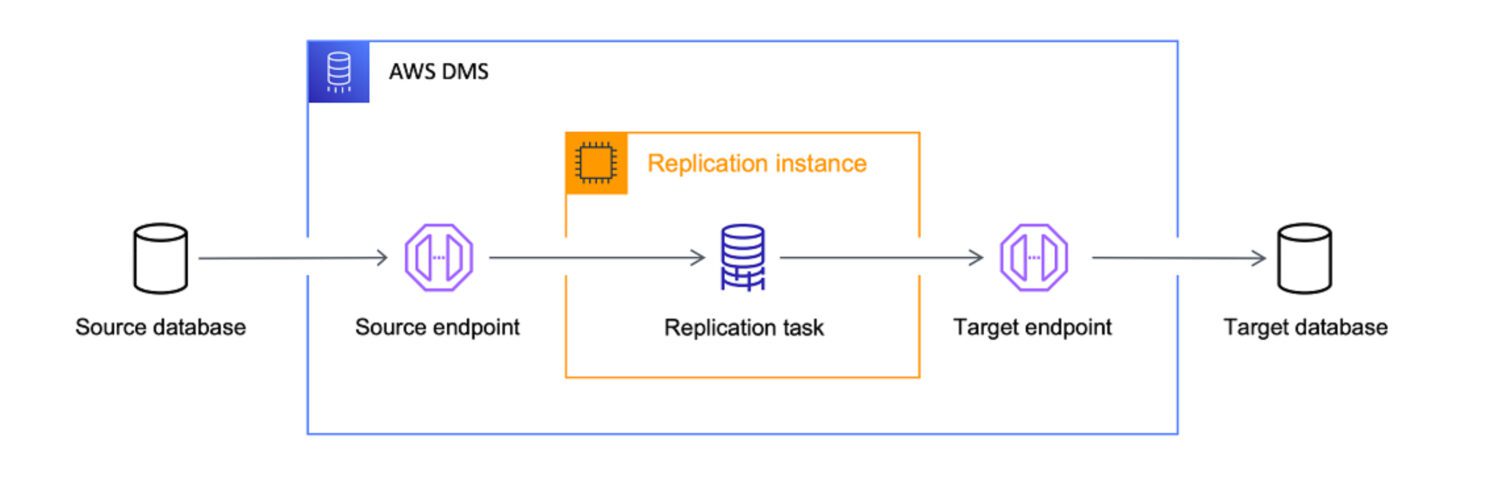
AWS DMS comme ETL
 Source : aws.amazon.com
Source : aws.amazon.com
AWS Data Migration Services (DMS) est un service entièrement géré qui vous permet de migrer des données de différentes sources vers AWS. Il prend en charge plusieurs scénarios de migration.
- Migrations homogènes (par exemple, Oracle vers Amazon RDS pour Oracle).
- Migrations hétérogènes (par exemple, Oracle vers Amazon Aurora).
DMS peut migrer des données provenant de diverses sources, y compris des bases de données, des entrepôts de données et des applications SaaS, vers diverses cibles, notamment Amazon S3, Amazon Redshift et Amazon RDS.
AWS considère le service DMS comme l’outil ultime pour amener les données de n’importe quelle source de base de données vers des cibles cloud natives. Bien que l’objectif principal du DMS soit simplement la copie des données dans le cloud, il transforme également les données en cours de route.
Vous pouvez définir des tâches DMS au format JSON pour automatiser diverses tâches de transformation pour vous tout en copiant les données de la source vers la cible :
- Fusionnez plusieurs tables ou colonnes source en une seule valeur.
- Divisez la valeur source en plusieurs champs cibles.
- Remplacez les données source par une autre valeur cible.
- Supprimez toutes les données inutiles ou créez des données entièrement nouvelles en fonction du contexte d’entrée.
Cela signifie – oui, vous pouvez certainement utiliser DMS comme outil ETL pour votre projet. Peut-être que ce ne sera pas aussi sophistiqué que les autres options ci-dessous, mais cela fera l’affaire si vous définissez clairement l’objectif dès le départ.
Facteur d’aptitude
Bien que DMS fournisse certaines fonctionnalités ETL, il s’agit principalement de scénarios de migration de données. Cependant, il existe certains scénarios dans lesquels il peut être préférable d’utiliser DMS au lieu d’outils ETL comme Informatica ou Matillion :
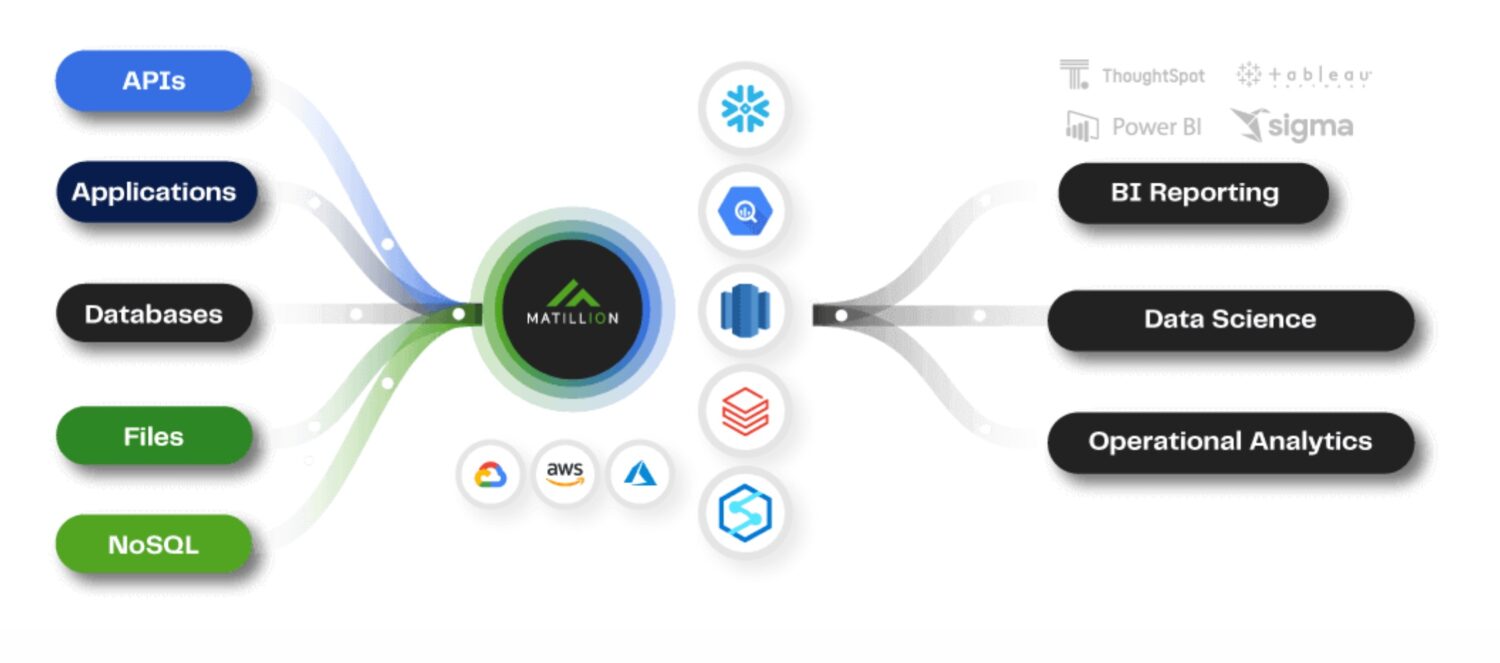
Matillion ETL
 Source : matillion.com
Source : matillion.com
est une solution cloud native, et vous pouvez l’utiliser pour intégrer des données provenant de diverses sources, notamment des bases de données, des applications SaaS et des systèmes de fichiers. Il offre une interface visuelle pour créer des pipelines ETL et prend en charge divers services AWS, notamment Amazon S3, Amazon Redshift et Amazon RDS.
Matillion est facile à utiliser et peut être un bon choix pour les organisations qui découvrent les outils ETL ou qui ont des besoins d’intégration de données moins complexes.
D’autre part, Matillion est une sorte de tabula rasa. Il a des fonctionnalités potentielles prédéfinies, mais vous devez le coder sur mesure pour lui donner vie. Vous ne pouvez pas vous attendre à ce que Matillion fasse le travail pour vous dès le départ, même si la capacité est là par définition.
Matillion s’est également souvent décrit comme un ELT plutôt que comme un outil ETL. Cela signifie qu’il est plus naturel pour Matillion d’effectuer un chargement avant la transformation.
Facteur d’aptitude
En d’autres termes, Matillion est plus efficace pour transformer les données qu’une fois qu’elles sont déjà stockées dans la base de données qu’auparavant. La raison principale en est l’obligation de script personnalisé déjà mentionnée. Étant donné que toutes les fonctionnalités spéciales doivent être codées en premier, l’efficacité dépendra ensuite fortement de l’efficacité du code personnalisé.
Il est naturel de s’attendre à ce que cela soit mieux géré dans le système de base de données cible et à ne laisser sur Matillion qu’une simple tâche de chargement 1: 1 – beaucoup moins de possibilités de le détruire avec du code personnalisé ici.
Bien que Matillion fournisse une gamme de fonctionnalités pour l’intégration de données, il se peut qu’il n’offre pas le même niveau de qualité des données et de fonctionnalités de gouvernance que certains autres outils ETL.
Matillion peut évoluer à la hausse ou à la baisse en fonction des besoins de l’organisation, mais il peut ne pas être aussi efficace pour gérer de très gros volumes de données. Le traitement parallèle est assez limité. À cet égard, Informatica est certainement un meilleur choix car il est à la fois plus avancé et riche en fonctionnalités.
Cependant, pour de nombreuses organisations, Matillion pour AWS peut fournir une évolutivité et des capacités de traitement parallèle suffisantes pour répondre à leurs besoins.
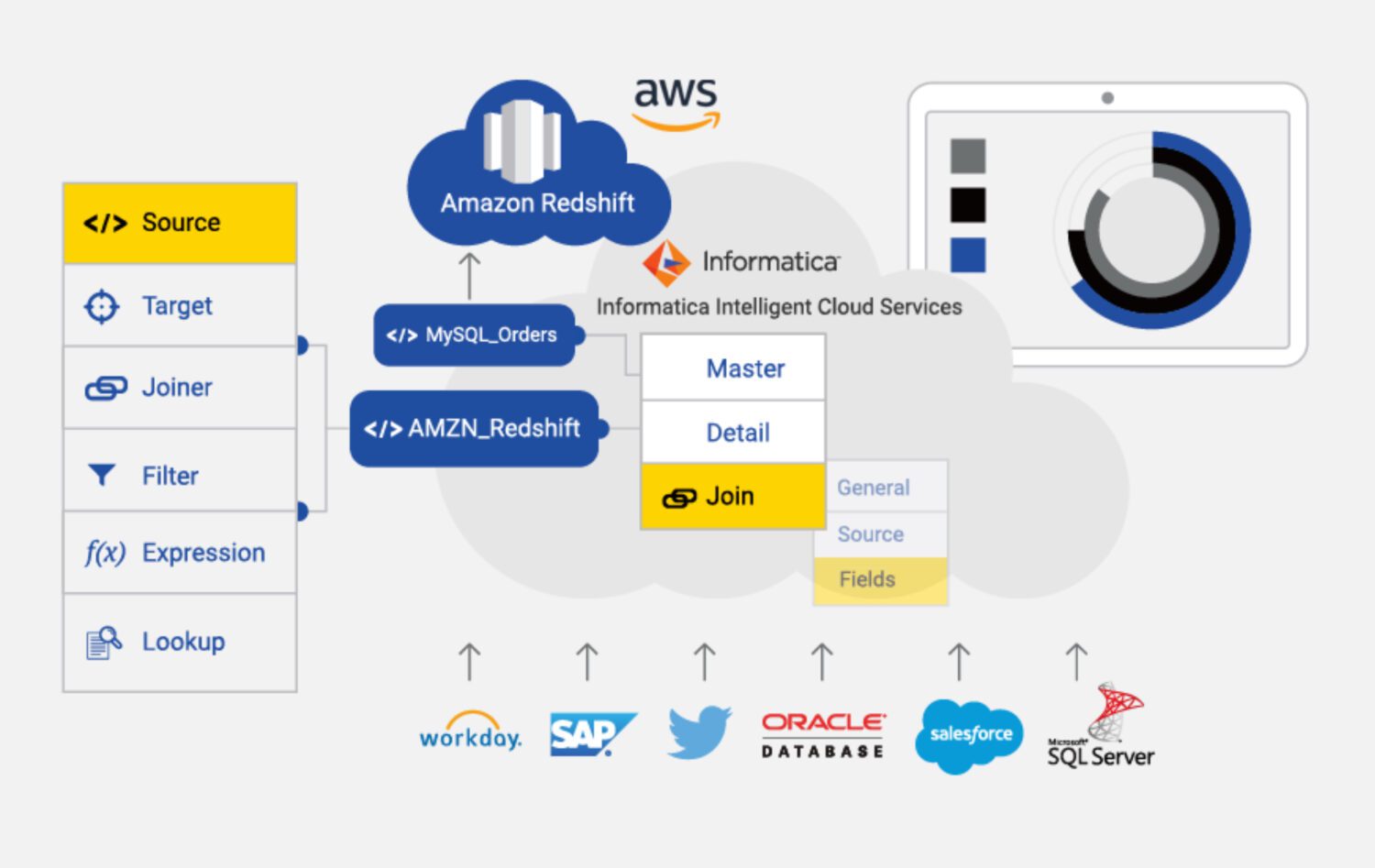
ETL Informatica
 Source : informatica.com
Source : informatica.com
Informatica pour AWS est un outil ETL basé sur le cloud conçu pour faciliter l’intégration et la gestion des données sur diverses sources et cibles dans AWS. Il s’agit d’un service entièrement géré qui fournit une gamme de fonctionnalités et de capacités pour l’intégration des données, y compris le profilage des données, la qualité des données et la gouvernance des données.
Certaines des principales caractéristiques d’Informatica pour AWS incluent :
Facteur d’aptitude
De toute évidence, Informatica est l’outil ETL le plus riche en fonctionnalités de la liste. Cependant, il peut être plus coûteux et complexe à utiliser que certains des autres outils ETL disponibles dans AWS.
Informatica peut être coûteux, en particulier pour les petites et moyennes entreprises. Le modèle de tarification est basé sur l’utilisation, ce qui signifie que les organisations peuvent devoir payer plus à mesure que leur utilisation augmente.
Il peut également être complexe à installer et à configurer, en particulier pour ceux qui découvrent les outils ETL. Cela peut nécessiter un investissement important en temps et en ressources.
Cela nous amène également à quelque chose que nous pouvons appeler une « courbe d’apprentissage complexe ». Cela peut être un inconvénient pour ceux qui ont besoin d’intégrer rapidement des données ou qui ont des ressources limitées à consacrer à la formation et à l’intégration.
De plus, Informatica peut ne pas être aussi efficace pour intégrer des données provenant de sources non AWS. À cet égard, DMS ou Matillion pourraient être une meilleure option.
Enfin, Informatica est un système très fermé. Il n’y a qu’une capacité limitée à l’adapter aux besoins spécifiques du projet. Il vous suffit de vivre avec la configuration qu’il fournit prête à l’emploi. Cela limite donc en quelque sorte la flexibilité des solutions.
Derniers mots
Comme cela se produit dans de nombreux autres cas, il n’existe pas de solution unique, même comme l’outil ETL dans AWS.
Vous pouvez choisir la solution la plus complexe, la plus riche en fonctionnalités et la plus coûteuse avec Informatica. Mais il est logique de faire le plus si :
- Le projet est assez important et vous êtes sûr que l’ensemble de la solution future et les sources de données se connectent également à Informatica.
- Vous pouvez vous permettre de faire appel à une équipe de développeurs et de configurateurs Informatica compétents.
- Vous pouvez apprécier la solide équipe de support derrière vous et payer pour cela.
Si quelque chose d’en haut ne va pas, vous pouvez donner une chance à Matillion :
- Si les besoins du projet ne sont pas si complexes en général.
- Si vous devez inclure des étapes très personnalisées dans le traitement, la flexibilité est une exigence clé.
- Si cela ne vous dérange pas de créer la plupart des fonctionnalités à partir de zéro avec l’équipe.
Pour tout ce qui est encore moins compliqué, le choix évident est le DMS pour AWS en tant que service natif, qui peut probablement bien servir votre objectif.
Ensuite, découvrez les outils de transformation des données pour mieux gérer vos données.