L'extraction de données est facile avec Scraping Browser
L'extraction de données, ou "web scraping", consiste à recueillir des informations spécifiques depuis des pages web. Les utilisateurs peuvent ainsi extraire divers types de contenus tels que du texte, des images, des vidéos, des avis, des informations sur des produits, etc. Cette collecte de données est précieuse pour réaliser des études de marché, des analyses de sentiment, des études concurrentielles et pour agréger des informations variées.
Pour des volumes de données modestes, l'extraction manuelle est envisageable. Elle consiste à copier-coller des éléments spécifiques de pages web vers un tableur ou un document. Par exemple, un consommateur souhaitant comparer des avis clients avant un achat peut opter pour cette méthode simple.
Cependant, dès lors que l'on traite de grandes quantités de données, une approche automatisée devient nécessaire. On peut alors développer une solution interne de "scraping" ou recourir à des API spécialisées (API Proxy ou API Scraping).
Ces techniques ne sont pas toujours optimales, car certains sites web se protègent à l'aide de CAPTCHA. De plus, la gestion des bots et des proxys peut s'avérer chronophage et limiter le type de contenu accessible.
Scraping Browser : une solution performante
Pour surmonter ces difficultés, Bright Data propose Scraping Browser, un navigateur tout-en-un. Cet outil permet de collecter des données depuis des sites web réputés difficiles d'accès. Il s'agit d'un navigateur doté d'une interface graphique (GUI), pilotable via les API Puppeteer ou Playwright, ce qui le rend indétectable par les systèmes de détection de bots.
Scraping Browser intègre des fonctionnalités de déblocage qui gèrent automatiquement les obstacles. Le navigateur fonctionne sur les serveurs de Bright Data, évitant ainsi la nécessité d'investir dans une infrastructure interne coûteuse pour des projets de grande envergure.
Les atouts du navigateur Bright Data Scraping
- Déblocage automatique des sites web : Plus besoin de rafraîchir constamment votre navigateur ! Scraping Browser s'adapte de manière autonome pour résoudre les CAPTCHA, contourner les blocages, gérer les empreintes digitales et faire face aux différentes tentatives de protection. Il simule le comportement d'un utilisateur réel.
- Un vaste réseau de proxys : Avec plus de 72 millions d'adresses IP, Scraping Browser vous permet de cibler n'importe quel pays, voire des villes spécifiques ou des opérateurs, en bénéficiant d'une technologie de pointe.
- Évolutivité : La puissance de l'infrastructure Bright Data permet d'ouvrir des milliers de sessions simultanément, gérant ainsi efficacement un grand volume de requêtes.
- Compatibilité avec Puppeteer et Playwright : Ce navigateur offre la possibilité d'effectuer des appels d'API et de gérer un grand nombre de sessions via Puppeteer (Python) ou Playwright (Node.js).
- Gain de temps et de ressources : Scraping Browser automatise la configuration des proxys et fonctionne en arrière-plan. De plus, l'absence de nécessité d'une infrastructure interne permet de réaliser des économies significatives.
Configuration du navigateur de Scraping
- Rendez-vous sur le site web de Bright Data et cliquez sur "Scraping Browser" dans l'onglet "Scraping Solutions".
- Créez un compte. Vous aurez le choix entre "Démarrer l'essai gratuit" et "Démarrer gratuitement avec Google". Pour l'exemple, choisissons "Démarrer l'essai gratuit". Vous pouvez créer un compte manuellement ou utiliser votre compte Google.
- Une fois le compte créé, le tableau de bord offre différentes options. Choisissez "Proxies et infrastructure de scraping".
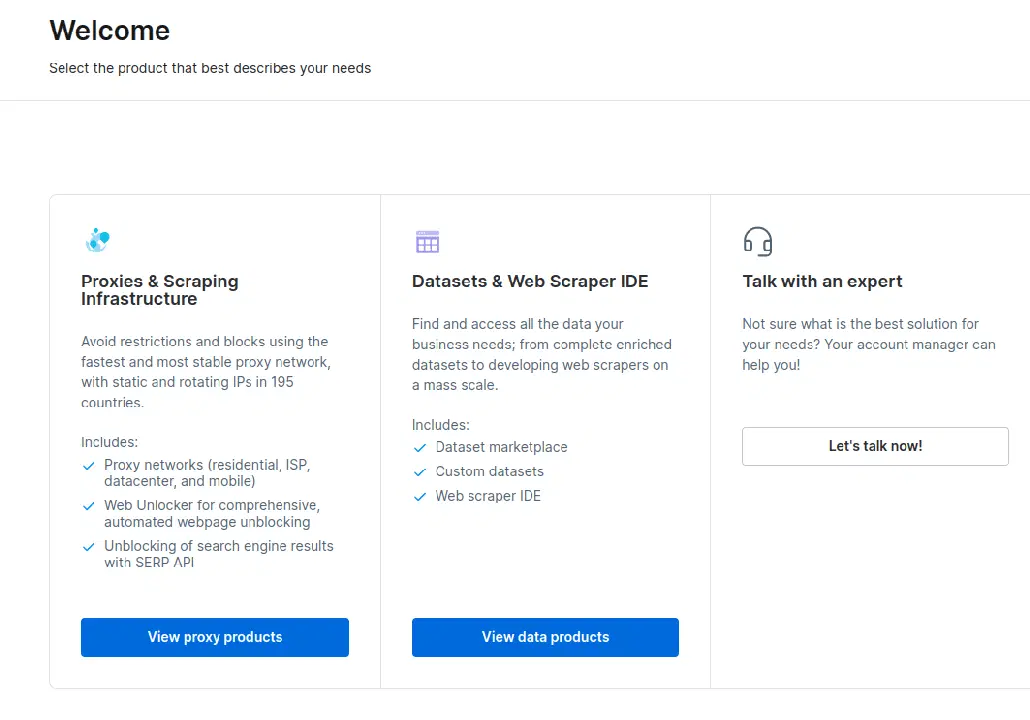
- Dans la fenêtre qui s'ouvre, sélectionnez "Scraping Browser" et cliquez sur "Commencer".
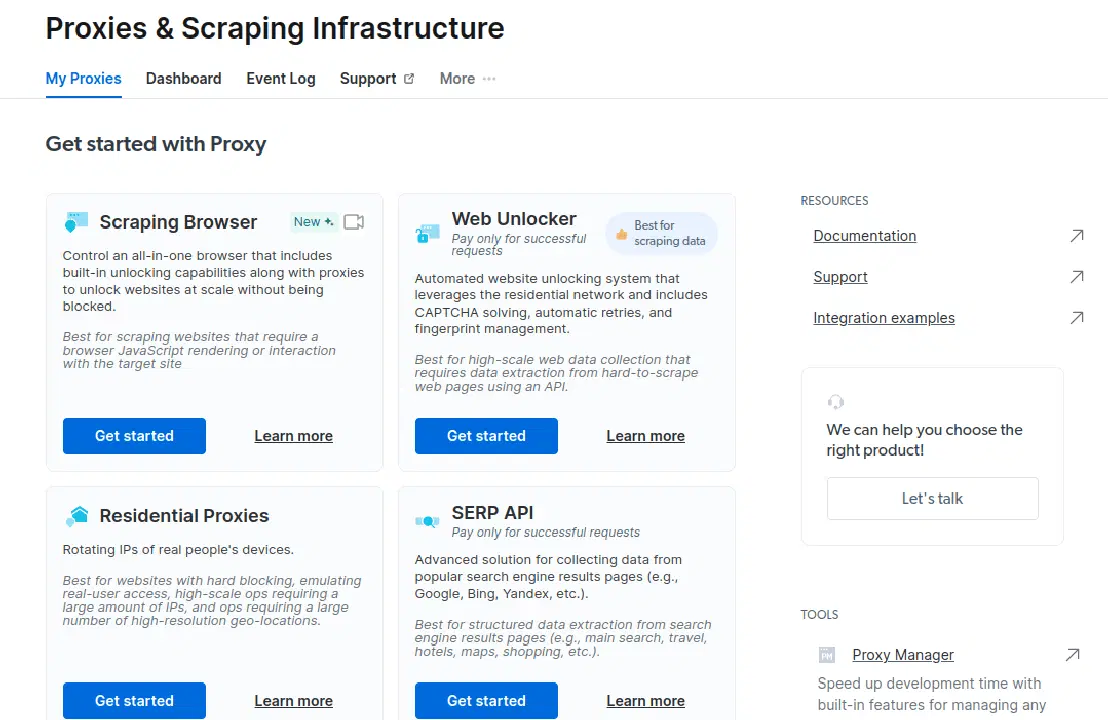
- Enregistrez et activez vos configurations.
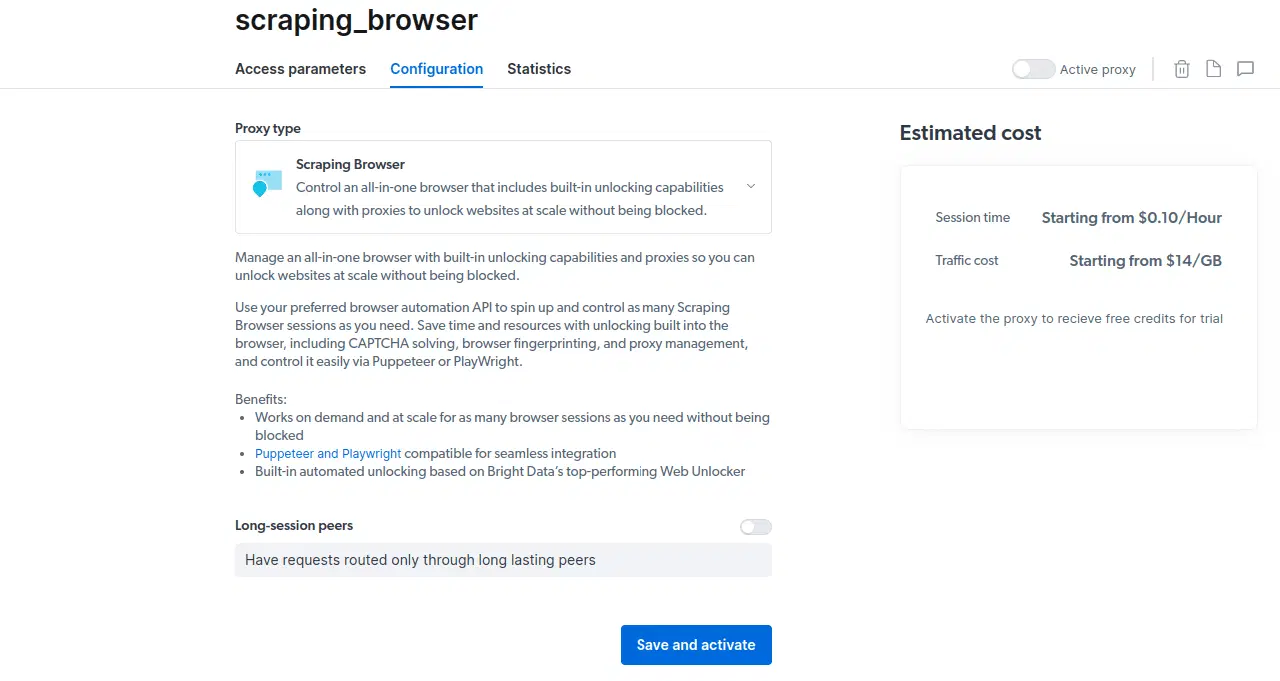
- Activez votre essai gratuit. La première option offre un crédit de 5 $ pour l'utilisation des proxys. La deuxième option, destinée aux utilisateurs intensifs, offre 50 $ de crédit pour un dépôt de 50 $ ou plus. Cliquez sur la première option pour essayer le produit.
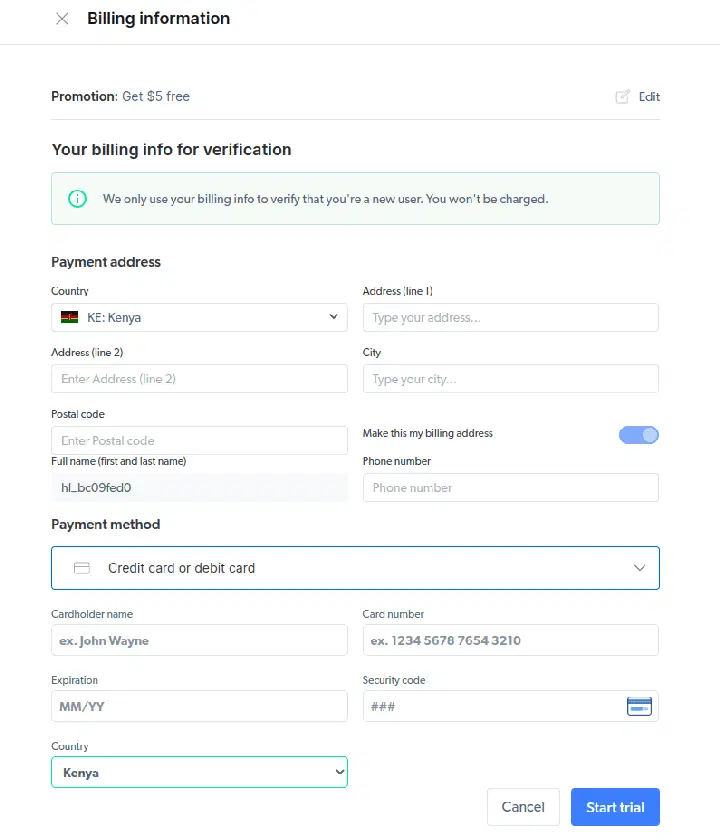
- Saisissez vos informations de facturation. Soyez assuré, la plateforme ne vous facturera rien pour cet essai. Ces informations sont utilisées pour vérifier que vous êtes un nouvel utilisateur et non un fraudeur cherchant à cumuler les essais gratuits.
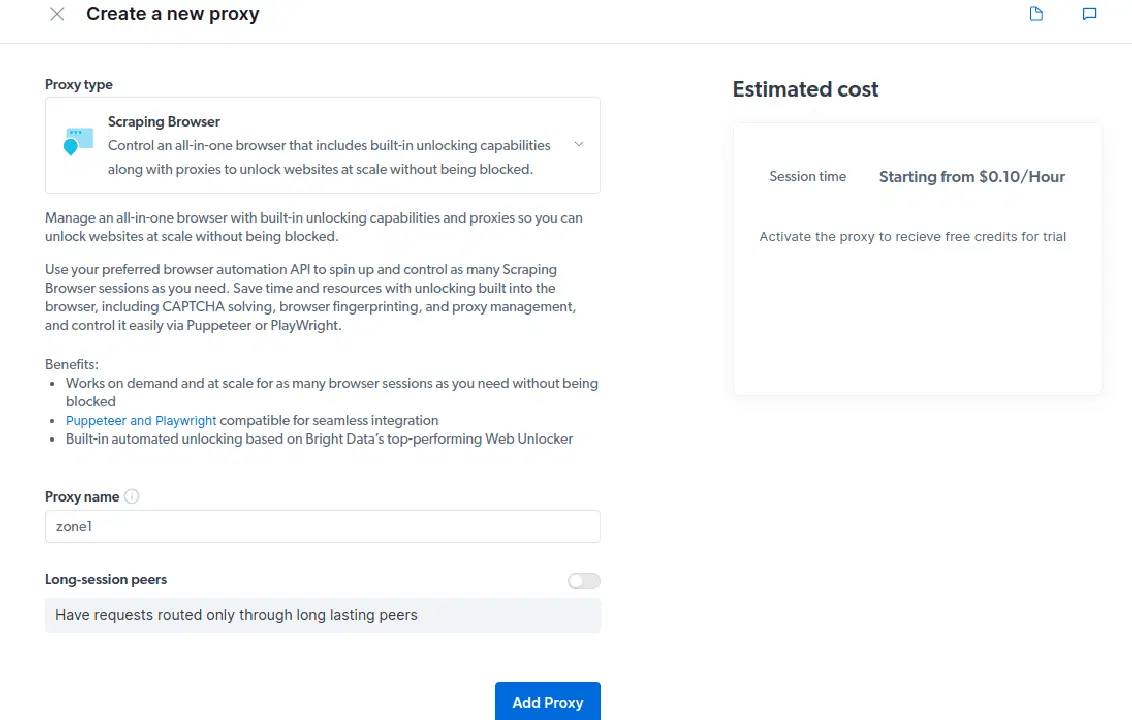
- Créez un nouveau proxy. Une fois vos informations de facturation enregistrées, vous pouvez créer un nouveau proxy. Cliquez sur l'icône "+" et choisissez "Scraping Browser" comme type de proxy. Cliquez sur "Ajouter un proxy" et passez à l'étape suivante.
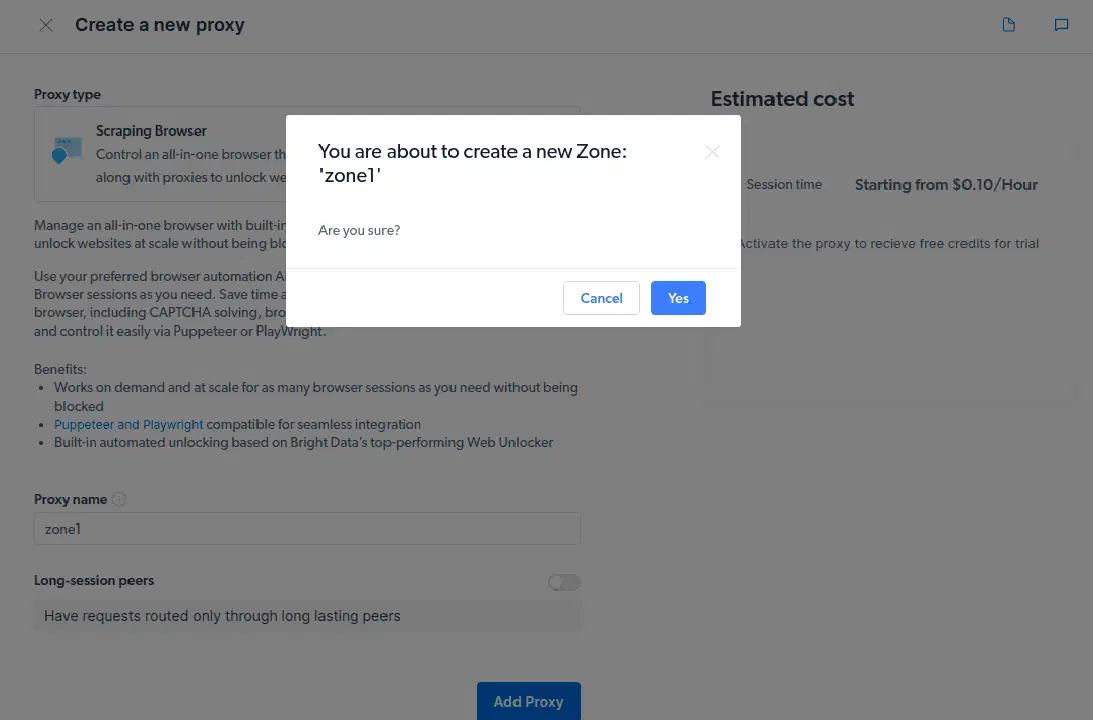
- Créez une nouvelle "zone". Une fenêtre contextuelle vous demandera si vous souhaitez créer une nouvelle zone. Cliquez sur "Oui" pour continuer.
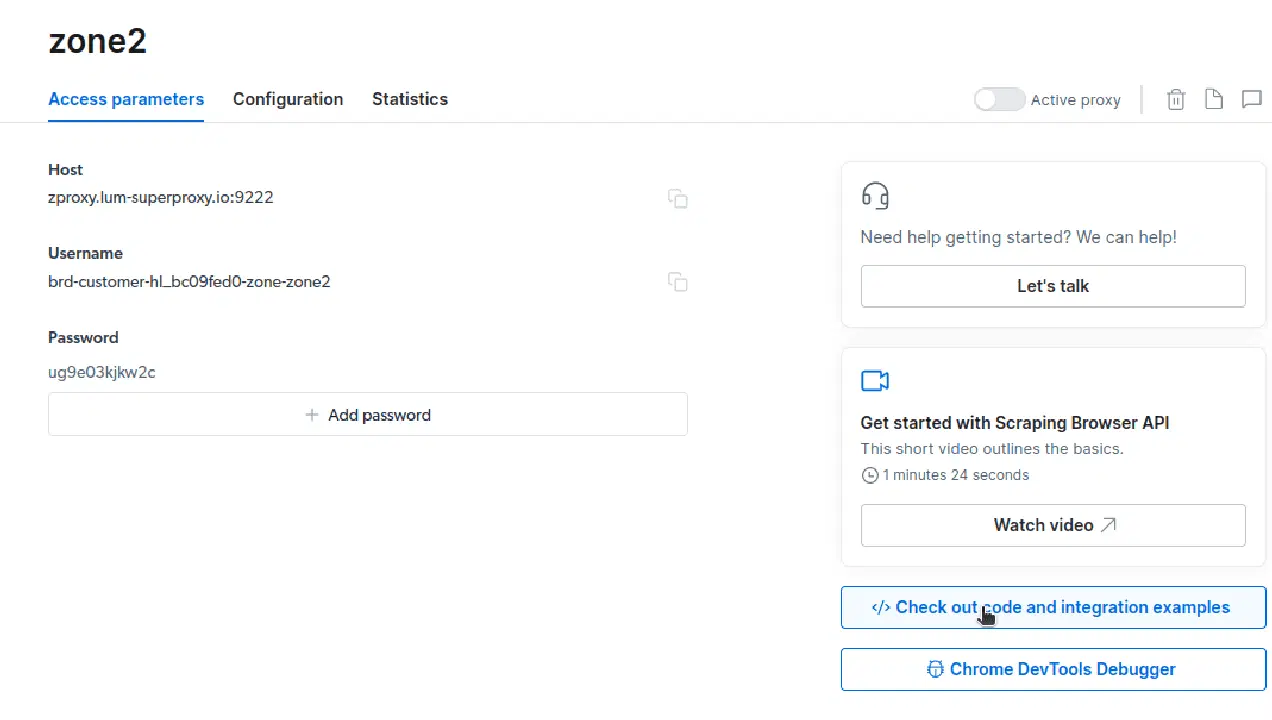
- Cliquez sur "Consulter les exemples de code et d'intégration". Vous aurez accès à des exemples d'intégration de proxy pour extraire des données de votre site web cible. Vous pouvez utiliser Node.js ou Python.
Vous avez maintenant tout le nécessaire pour extraire des données d'un site web. Nous allons utiliser notre site web, toptips.fr.com, comme exemple pour démontrer le fonctionnement de Scraping Browser. Nous utiliserons node.js pour cette démonstration. Vous pouvez reproduire cette opération si vous avez installé node.js.
Suivez ces étapes :
const puppeteer = require('puppeteer-core');
// devrait ressembler à 'brd-customer--zone-:'
const auth="USERNAME:PASSWORD";
async function run(){
let browser;
try {
browser = await puppeteer.connect({browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2*60*1000);
await page.goto('https://example.com');
const html = await page.evaluate(() => document.documentElement.outerHTML);
console.log(html);
}
catch(e) {
console.error('run failed', e);
}
finally {
await browser?.close();
}
}
if (require.main==module)
run();
Modifions le code à la ligne 10 comme suit :
`await page.goto('https://toptips.fr.com/authors/');`
Voici notre code final :
const puppeteer = require('puppeteer-core');
// devrait ressembler à 'brd-customer--zone-:'
const auth="brd-customer-hl_bc09fed0-zone-zone2:ug9e03kjkw2c";
async function run(){
let browser;
try {
browser = await puppeteer.connect({browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2*60*1000);
await page.goto('https://toptips.fr.com/authors/');
const html = await page.evaluate(() => document.documentElement.outerHTML);
console.log(html);
}
catch(e) {
console.error('run failed', e);
}
finally {
await browser?.close();
}
}
if (require.main==module)
run();
node script.js
Vous devriez voir quelque chose de similaire dans votre terminal.
Comment exporter les données
Plusieurs options s'offrent à vous pour exporter les données, en fonction de leur utilisation future. Dans l'exemple suivant, nous exporterons les données vers un fichier HTML en modifiant le script pour créer un fichier nommé data.html au lieu d'afficher les résultats dans la console.
Voici le code modifié :
const puppeteer = require('puppeteer-core');
const fs = require('fs');
// devrait ressembler à 'brd-customer--zone-:'
const auth="brd-customer-hl_bc09fed0-zone-zone2:ug9e03kjkw2c";
async function run() {
let browser;
try {
browser = await puppeteer.connect({ browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222` });
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2 * 60 * 1000);
await page.goto('https://toptips.fr.com/authors/');
const html = await page.evaluate(() => document.documentElement.outerHTML);
// Écrire le contenu HTML dans un fichier
fs.writeFileSync('data.html', html);
console.log('Data export complete.');
} catch (e) {
console.error('run failed', e);
} finally {
await browser?.close();
}
}
if (require.main == module) {
run();
}
Vous pouvez maintenant exécuter le code avec cette commande :
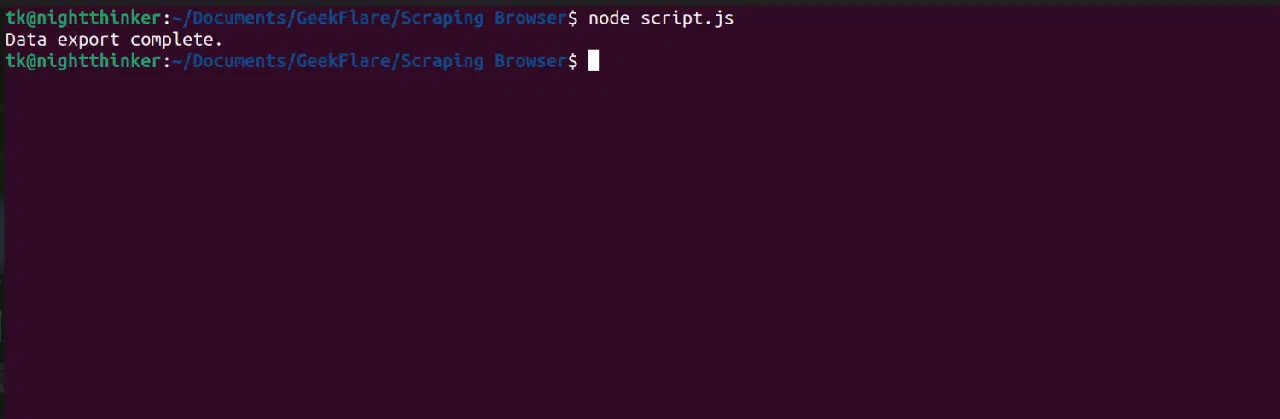
node script.js
Comme vous pouvez le voir sur la capture d'écran suivante, le terminal affiche le message "Data export complete".
Si nous examinons notre dossier de projet, nous pouvons désormais voir un fichier nommé data.html contenant des milliers de lignes de code.
Nous avons ici exploré les bases de l'extraction de données avec Scraping Browser. Il est possible d'aller beaucoup plus loin, par exemple en sélectionnant et en extrayant uniquement les noms des auteurs et leurs descriptions.
Pour utiliser Scraping Browser efficacement, identifiez les données que vous souhaitez extraire et adaptez le code en conséquence. Vous pouvez extraire du texte, des images, des vidéos, des métadonnées, des liens, en fonction du site web cible et de la structure du fichier HTML.
FAQ
L'extraction de données et le "web scraping" sont-ils légaux ?
Le "web scraping" est un sujet controversé, certains le considérant comme contraire à l'éthique, tandis que d'autres l'estiment acceptable. La légalité du "scraping" dépend de la nature du contenu extrait et de la politique du site web cible.
En général, l'extraction de données personnelles comme des adresses ou des informations financières est considérée comme illégale. Avant d'extraire des données, vérifiez les directives du site cible et assurez-vous de ne pas récupérer de données qui ne sont pas publiquement accessibles.
Scraping Browser est-il un outil gratuit ?
Non. Scraping Browser est un service payant. L'essai gratuit offre un crédit de 5 $. Les forfaits payants commencent à 15 $/Go + 0,1 $/h. L'option "Pay As You Go" est également proposée à 20 $/Go + 0,1 $/h.
Quelle est la différence entre les navigateurs Scraping et les navigateurs sans tête ?
Scraping Browser est un navigateur dit "intelligent" car il possède une interface graphique (GUI). Les navigateurs sans tête n'ont pas d'interface graphique. Les navigateurs sans tête comme Selenium sont utilisés pour automatiser le "web scraping", mais ils sont parfois limités car ils doivent gérer les CAPTCHA et la détection de robots.
En résumé
Scraping Browser simplifie considérablement l'extraction de données depuis les pages web. Son utilisation est plus intuitive que des outils comme Selenium, et même les personnes sans connaissances techniques peuvent l'utiliser grâce à son interface conviviale et sa documentation claire. Les fonctionnalités de déblocage exclusives font de cet outil une solution efficace pour automatiser les processus d'extraction de données.
Vous pouvez également découvrir comment empêcher les plugins ChatGPT d'extraire le contenu de votre site web.