La reconnaissance d'entités nommées (NER) expliquée en termes simples
L'identification d'entités nommées (IEN) se révèle être une méthode très performante pour décrypter le sens d'une information textuelle. Elle permet de cibler et d'étiqueter des éléments spécifiques dans le texte, ouvrant la voie à diverses applications.
Qu'il s'agisse de classer des noms de personnes, d'indiquer des dates, des organisations ou des lieux, l'IEN se forge un chemin unique pour une compréhension améliorée du langage.
Un grand nombre d'organisations manipulent un volume considérable de données, qu'il s'agisse de contenu textuel, d'informations personnelles, de retours clients, de détails produits et bien plus encore.
Lorsque la nécessité d'accéder rapidement à une information se fait sentir, il faut lancer des recherches pour obtenir le résultat souhaité. Cette démarche peut être chronophage, énergivore et gourmande en ressources, surtout lorsqu'il s'agit de traiter d'importants volumes de données.
L'IEN se présente comme une solution efficace pour les organisations en quête d'optimisation de leurs opérations de recherche et de repérage des données pertinentes.
Dans cet article, nous allons explorer en détail l'IEN, son fondement mathématique, ses diverses utilisations ainsi que d'autres points importants à connaître.
C'est parti !
Qu'est-ce que l'identification d'entités nommées ?
L'identification d'entités nommées (IEN) est une technique de traitement du langage naturel (TLN) permettant d'identifier et de catégoriser les entités au sein de données textuelles non structurées.
Ces entités englobent une grande variété d'informations, telles que des organisations, des lieux, des noms de personnes, des valeurs numériques, des dates, et bien d'autres. L'IEN permet aux machines d'extraire ces entités, ce qui en fait un outil précieux pour des applications telles que la traduction, la réponse aux questions et bien d'autres, dans de nombreux secteurs.
Source: Écailleur
Ainsi, l'IEN vise à localiser et à classer les différentes entités dans un texte non structuré en les regroupant dans des catégories prédéfinies, telles que les organisations, les codes médicaux, les quantités, les noms de personnes, les pourcentages, les sommes d'argent, les expressions temporelles, etc.
Prenons un exemple pour mieux comprendre :
[William] a acquis une propriété auprès de [Z1 Corp.] en [2023]. Ici, les éléments entre crochets sont les entités identifiées par l'IEN. Elles sont classifiées comme suit :
- William – Nom de personne
- Z1 Corp. – Organisation
- 2023 – Date
L'IEN est utilisée dans plusieurs domaines de l'intelligence artificielle, notamment l'apprentissage profond, l'apprentissage automatique (AA) et les réseaux neuronaux. C'est une composante essentielle des systèmes de TLN, comme les outils d'analyse des sentiments, les moteurs de recherche et les chatbots. De plus, elle trouve des applications dans des domaines aussi variés que la finance, le support client, l'enseignement supérieur, la santé, les ressources humaines et l'analyse des médias sociaux.
En d'autres termes, l'IEN identifie, classe et extrait les informations essentielles d'un texte non structuré sans intervention humaine. Elle permet d'extraire rapidement des informations clés à partir d'importants volumes de données.
Par ailleurs, l'IEN fournit à votre organisation des informations primordiales sur les produits, les tendances du marché, les clients et la concurrence. Par exemple, les établissements de santé utilisent l'IEN pour extraire des données médicales cruciales des dossiers patients. De nombreuses entreprises l'emploient pour savoir si elles sont mentionnées dans des publications.
Concepts clés : IEN

Il est crucial de comprendre les concepts de base impliqués dans l'IEN. Examinons quelques termes clés liés à l'IEN qu'il est utile de connaître.
- Entité nommée : tout terme faisant référence à un lieu, une organisation, une personne ou une autre entité.
- Corpus : Ensemble de différents textes servant à analyser les langues et à entraîner les modèles d'IEN.
- Étiquetage POS : Processus consistant à étiqueter le texte en fonction de sa nature grammaticale, comme les adjectifs, les verbes et les noms.
- Chunking : Processus utilisé pour regrouper des mots en phrases significatives en fonction de la structure syntaxique et de la partie du discours.
- Données d'entraînement et de test : Processus utilisé pour entraîner un modèle avec des données étiquetées et évaluer ses performances sur un autre ensemble de données.
Utilisation de l'IEN en TLN

L'IEN possède de multiples applications en TLN, telles que l'analyse des sentiments, les systèmes de recommandation, la réponse aux questions, l'extraction d'informations, etc.
- Analyse des sentiments : l'IEN permet de détecter le sentiment exprimé dans une phrase ou un paragraphe envers une entité nommée spécifique, comme un produit ou un service. Ces données permettent d'améliorer l'expérience client et d'identifier les axes d'amélioration.
- Systèmes de recommandation : l'IEN sert à identifier les préférences et les centres d'intérêt des utilisateurs en fonction des entités nommées mentionnées lors d'interactions en ligne ou de requêtes de recherche. Ces informations sont utilisées pour améliorer l'expérience des utilisateurs en leur proposant des recommandations personnalisées.
- Réponse aux questions : l'IEN est employée pour détecter certaines entités dans un texte, ce qui permet ensuite de répondre à une requête ou une question précise. Cette technique est souvent utilisée pour les assistants virtuels et les chatbots.
- Extraction d'informations : l'IEN permet d'extraire des informations essentielles d'un ensemble plus large de textes non structurés. Cela inclut les publications sur les réseaux sociaux, les avis en ligne, les articles de presse, etc. Ces données sont utilisées pour générer des informations précieuses et prendre des décisions éclairées.
Concepts mathématiques : IEN
Le processus d'IEN fait appel à différents concepts mathématiques, tels que l'apprentissage automatique, l'apprentissage profond, la théorie des probabilités, etc. Voici quelques techniques mathématiques utilisées :
- Modèles de Markov cachés : les modèles de Markov cachés (MMC) sont une approche statistique pour séquencer les tâches de classification, comme l'IEN. Ils consistent à représenter une séquence de mots dans le texte comme différents états, chaque état représentant une entité nommée spécifique. En analysant les probabilités, il est possible d'identifier les entités nommées dans le texte.
- Apprentissage profond : des techniques d'apprentissage profond telles que les réseaux neuronaux sont utilisées dans les tâches d'IEN. Elles permettent d'identifier et de catégoriser les entités nommées de manière efficace et précise.
- Champs aléatoires conditionnels : ils relèvent d'un modèle graphique utilisé dans les tâches d'étiquetage de séquence. Ils proposent une modélisation probabiliste conditionnelle de chaque étiquette contenant la séquence de mots. Cela permet d'identifier les entités nommées dans un texte.
Comment fonctionne l'IEN ?
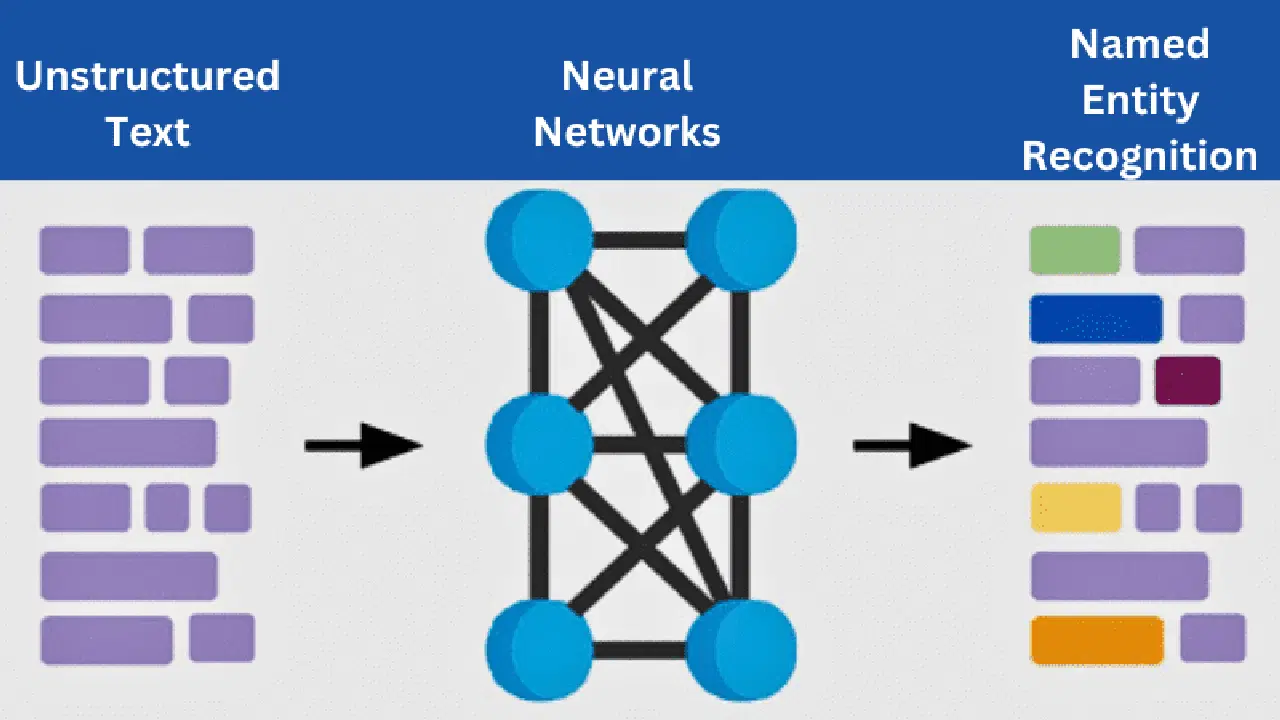 Source: Publications de l'AEC
Source: Publications de l'AEC
L'identification d'entités nommées (IEN) fonctionne comme une extraction d'informations. Son fonctionnement peut être décomposé en différentes étapes clés :
#1. Prétraitement du texte
Dans cette première étape, l'IEN consiste à préparer les informations textuelles en vue de leur analyse. Cela passe généralement par des opérations comme la tokenisation. Ici, le texte est d'abord divisé en jetons avant que l'IEN ne commence à identifier les entités.
Par exemple, "Bill Gates a fondé Microsoft" peut être divisé en différents jetons tels que "Bill", "Gates", "a fondé" et "Microsoft".
#2. Identification des entités
Les entités nommées potentielles peuvent être détectées à l'aide de méthodes statistiques ou de règles linguistiques. Cette étape implique la reconnaissance de motifs, comme des formats spécifiques (dates) ou l'utilisation de majuscules dans les noms ("Bill Gates"). Une fois la fonction de prétraitement terminée, les algorithmes d'IEN scannent le texte pour identifier les mots ou séquences de mots qui correspondent à des entités.
#3. Classification des entités
Une fois que l'IEN a identifié les entités, elle les classe en types, classes ou groupes. Les catégories courantes sont l'organisation, la date, le lieu, la personne, etc. Cette classification est effectuée grâce à des modèles d'apprentissage automatique entraînés sur des données étiquetées.
Par exemple, "Bill Gates" serait reconnu comme une "personne" et "Microsoft" comme une "organisation".
#4. Analyse contextuelle
L'IEN ne se limite pas à la reconnaissance et à la classification des entités. Elle prend souvent en compte le contexte pour améliorer la précision. Cette étape tient compte du contexte dans lequel les entités apparaissent pour assurer une catégorisation précise.
Par exemple, dans la phrase "Bill Gates a fondé Microsoft", le contexte permet au système d'identifier "Bill" comme le nom d'une personne et non comme une facture.
#5. Post-traitement
Après une identification et une catégorisation initiales, un post-traitement est nécessaire pour affiner les résultats. Cela inclut de résoudre les ambiguïtés, d'utiliser des bases de connaissances, de fusionner des entités multi-jetons, etc., pour améliorer les données des entités.
L'atout majeur de l'IEN est sa capacité à interpréter et à comprendre du texte non structuré, qui contient les données nécessaires à votre entreprise. Elle extrait une part essentielle des données issues d'articles de presse, de pages web, de documents de recherche, de publications sur les réseaux sociaux, etc.
En reconnaissant et en catégorisant les entités nommées, l'IEN ajoute une couche supplémentaire de sens et de structure au contenu textuel.
Méthodes d'IEN

Les méthodes les plus couramment utilisées sont les suivantes :
#1. Méthode basée sur l'apprentissage automatique supervisé
Cette méthode utilise des modèles d'apprentissage automatique entraînés sur des textes pré-étiquetés par des humains avec des catégories d'entités nommées.
Cette approche utilise des algorithmes, notamment l'entropie maximale et les champs aléatoires conditionnels, pour obtenir des modèles de langage statistique complexes. Elle est efficace pour résoudre les subtilités linguistiques et autres complexités, mais elle nécessite un grand volume de données d'entraînement pour fonctionner.
#2. Systèmes basés sur des règles
Cette méthode utilise différentes règles pour collecter des informations. Elle comprend les titres ou les majuscules, par exemple "M.". Dans cette méthode, une intervention humaine importante est nécessaire pour donner son avis, surveiller et modifier les règles. Cette méthode peut ne pas prendre en compte les variations textuelles qui ne sont pas incluses dans les annotations d'entraînement. C'est pourquoi les systèmes basés sur des règles ne sont pas capables de gérer la complexité et les modèles d'apprentissage automatique.
#3. Systèmes basés sur un dictionnaire
Dans cette méthode, un dictionnaire contenant un grand nombre de synonymes et de vocabulaire est utilisé pour identifier et faire correspondre les identités nommées. Cette méthode rencontre des difficultés pour catégoriser les entités nommées qui présentent diverses variantes orthographiques.
Il existe également de nombreuses autres méthodes d'IEN émergentes. Examinons-les également :
#4. Systèmes d'apprentissage automatique non supervisés
Ces systèmes d'AA utilisent des modèles d'apprentissage automatique qui ne sont pas pré-entraînés sur les données textuelles. Les modèles d'apprentissage non supervisés sont plus aptes à exécuter des tâches complexes que les modèles supervisés.
#5. Systèmes d'amorçage
Les systèmes d'amorçage, aussi appelés systèmes auto-supervisés, catégorisent les entités nommées en fonction de caractéristiques grammaticales, notamment les parties du discours, l'utilisation de majuscules et d'autres catégories pré-entraînées.
Un humain modifie ensuite le système d'amorçage en étiquetant les prédictions du système comme incorrectes ou correctes et en ajoutant les bonnes au nouvel ensemble d'entraînement.
#6. Systèmes de réseaux neuronaux
Ils construisent le modèle d'identification d'entités nommées en utilisant des modèles d'apprentissage d'architecture bidirectionnelle (représentations d'encodeur bidirectionnel à partir de transformateurs), des réseaux neuronaux et des techniques d'encodage. Cette méthode réduit au minimum les interactions humaines.
#7. Systèmes statistiques
Cette méthode utilise des modèles probabilistes formés sur des relations et des motifs textuels. Elle permet de prédire facilement les entités nommées à partir de nouvelles données textuelles.
#8. Systèmes d'étiquetage des rôles sémantiques
Ce système pré-entraîne un modèle d'identification d'entités nommées en utilisant les techniques d'apprentissage sémantique qui enseignent la relation entre les catégories et le contexte.
#9. Systèmes hybrides
Cette méthode est intéressante car elle utilise les aspects de plusieurs approches de manière combinée.
Avantages de l'IEN
Les modèles d'IEN offrent de nombreux avantages.
- L'IEN automatise le processus d'extraction de données pour de grands volumes de données.
- Elle est utilisée dans tous les secteurs pour extraire des informations clés d'un texte non structuré.
- Elle peut vous faire gagner du temps, ainsi qu'à vos employés, lors de l'exécution des tâches d'extraction de données.
- Elle peut améliorer la précision des processus et des tâches de TLN.
- Elle garantit la sécurité des données en hébergeant des modèles d'IEN personnalisés, éliminant ainsi le besoin de partager des informations sensibles avec des fournisseurs tiers.
- Elle s'adapte à de nouveaux types d'entités et terminologies au fur et à mesure de l'évolution du domaine.
Les défis de l'IEN
- Ambigüité : De nombreux mots utilisés dans le texte peuvent être trompeurs. Par exemple, le mot "Amazon" peut faire référence à une entreprise, une rivière ou une forêt. Son sens peut être déterminé grâce au contexte spécifique. C'est ce qui rend la reconnaissance d'entités plus délicate.
- Dépendance au contexte : les mots dérivés du contexte environnant ont des sens différents ; par exemple, "Apple" dans un texte technologique fait référence à l'entreprise, tandis que dans un texte sur l'environnement, il fait référence aux fruits. Il n'est pas simple de reconnaître une entité précise.
- Rareté des données : pour les méthodes d'IEN basées sur l'apprentissage automatique, la disponibilité de données étiquetées est essentielle. Cependant, l'extraction de telles données, en particulier pour des domaines spécialisés ou des langues moins courantes, peut s'avérer difficile.
- Variations linguistiques : les langues humaines présentent différentes formes en fonction de leurs dialectes, des différences régionales et de leur argot. Il est donc difficile d'extraire un texte en langue étrangère.
- Généralisation du modèle : les modèles d'IEN peuvent exceller dans la classification des entités dans un seul domaine, mais peuvent rencontrer des difficultés lorsqu'il s'agit de généraliser leurs capacités à un autre domaine. Ainsi, les modèles d'IEN peuvent se comporter différemment selon les domaines.
Ces défis peuvent être relevés grâce à une combinaison d'algorithmes avancés, d'expertise linguistique et de données de qualité. L'IEN étant en constante évolution, les équipes de recherche et développement doivent affiner diverses techniques pour faire face à ces défis.
Cas d'utilisation de l'IEN
#1. Catégoriser le contenu

Les maisons d'édition et de presse génèrent un volume important de contenu en ligne. Il est donc crucial de le gérer efficacement pour tirer le meilleur parti d'un article ou d'une actualité.
L'identification d'entités nommées analyse automatiquement l'intégralité du contenu et extrait des données telles que les noms d'organisations, de lieux et de personnes utilisés dans le contenu. Connaître les étiquettes nécessaires pour chaque article aide à classer les articles dans la hiérarchie définie, ce qui améliore la diffusion du contenu.
#2. Algorithmes de recherche
Supposons que vous ayez un algorithme de recherche interne pour votre éditeur en ligne, contenant des millions d'articles. Pour chaque requête de recherche, votre algorithme de recherche interne finit par rassembler tous les mots de ces articles. C'est un processus qui prend du temps.
Désormais, si vous utilisez l'IEN pour votre éditeur en ligne, l'outil obtiendra facilement les entités essentielles de tous les articles et les stockera séparément. Cela accélérera votre processus de recherche.
#3. Recommandations de contenu
L'automatisation du processus de recommandation est un cas d'utilisation majeur de l'IEN. Les systèmes de recommandation orientent la découverte de nouvelles idées et de nouveaux contenus.
Netflix en est le parfait exemple. C'est la preuve qu'un système de recommandation efficace vous aide à susciter plus d'intérêt et d'engagement lors d'événements.
Pour les éditeurs de presse, l'IEN fonctionne efficacement en recommandant des articles similaires. Cela peut se faire en collectant les étiquettes d'un article spécifique et en recommandant d'autres contenus ayant des entités similaires.
#4. Service client

Pour toute organisation, le support client est un élément majeur. C'est pourquoi il existe plusieurs façons de faciliter la gestion des retours clients. L'IEN en fait partie. Prenons un exemple pour comprendre :
Supposons qu'un client donne son avis : "Le personnel du magasin Adidas de San Diego manque de détails plus fins sur les chaussures de sport." Ici, l'IEN retire les étiquettes "San Diego" (lieu) et "chaussures de sport" (produit).
Ainsi, l'IEN est utilisée pour classer chaque plainte et l'envoyer au service compétent au sein de l'organisation pour traiter le problème. Vous pouvez créer une base de données composée de retours classés par départements et analyser chaque retour.
#5. Documents de recherche
Une publication en ligne ou un site web de revue contient de nombreux articles scientifiques et documents de recherche. Il existe des centaines d'articles sur des sujets similaires, avec de légères modifications. Organiser toutes ces données de manière structurée peut donc s'avérer une tâche compliquée.
Pour éviter un processus fastidieux, vous pouvez séparer ces documents en fonction des étiquettes pertinentes.
Par exemple, il existe des milliers d'articles sur l'apprentissage automatique. Pour trouver celui qui mentionne l'utilisation de réseaux de neurones convolutifs (CNN), vous devez y ajouter des entités. Cela vous aidera à trouver rapidement l'article dont vous avez besoin.
Conclusion
L'identification d'entités nommées (IEN), une technique de TLN, facilite l'identification d'entités nommées dans un texte non structuré et la catégorisation de ces entités en groupes prédéfinis comme des lieux, des noms de personnes, des produits, etc.
L'objectif principal de l'IEN est de collecter des informations structurées à partir d'un texte non structuré et de les représenter dans un format lisible. Elle implique différents modèles et processus et apporte de nombreux avantages aux professionnels et aux entreprises. Elle est également utilisée dans diverses applications autres que la TLN.
J'espère que cette explication de cette technique vous a permis de mieux la comprendre, afin que vous puissiez l'appliquer dans votre entreprise et obtenir des informations pertinentes et précieuses en temps voulu.
Vous pouvez également explorer quelques-uns des meilleurs cours de TLN pour vous familiariser avec le traitement du langage naturel.