
Les données sont la pierre angulaire de toute entreprise. C’est la clé du succès et elle est essentielle pour recueillir des renseignements, prendre des décisions et améliorer les opérations.
Une entreprise s’appuie sur ses données et ses applications pour fonctionner au quotidien. Mais que se passe-t-il lorsque l’une de leurs bases de données ou systèmes tombe en panne ?
Toutes les informations et données critiques de l’entreprise pourraient être menacées.
Heureusement, il existe des moyens d’empêcher que cela se produise. L’une des méthodes les plus efficaces pour protéger les données d’entreprise est la réplication de base de données. C’est quelque chose que chaque petite, moyenne et grande entreprise doit s’adapter pour survivre dans la concurrence.
Dans cet article, je vais discuter de ce qu’est la réplication de données, de son fonctionnement et d’autres aspects importants.
Alors, commençons!
Table des matières
Qu’est-ce que la réplication de base de données ?
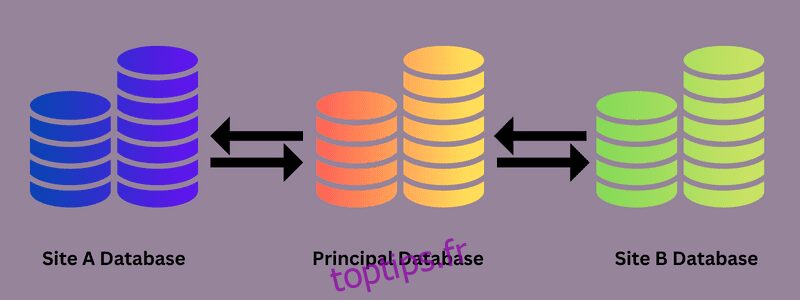
Le transfert de données d’une base de données source vers une ou plusieurs bases de données de destination est appelé réplication de base de données. Cela implique souvent de copier ou de diffuser des données d’une base de données à une autre afin que tous les utilisateurs puissent accéder aux données synchronisées, quel que soit le système qu’ils utilisent pour les visualiser.
Si les données changent, un outil de réplication de données s’assurera que les modifications sont également implémentées dans la base de données de destination. En conséquence, un réseau de stockage de données distribué avec une plus grande disponibilité sur plusieurs sites est créé, permettant à chacun d’accéder rapidement aux données vitales et pertinentes.
En utilisant une solution de réplication de données, vous remarquerez probablement une amélioration de la cohérence des données sur chaque nœud, une redondance des données réduite, une fiabilité des données plus importante et, éventuellement, une augmentation des performances.
La réplication de la base de données peut se produire en temps réel, lorsque les données sont créées, modifiées et détruites sur la base de données source ou dans le cadre d’une opération par lots.
Comment fonctionne la réplication de données ?
La réplication de base de données peut être effectuée une fois ou en tant que processus continu. Il implique toutes les sources de données d’une organisation, et un système de gestion de base de données distribué (DDBMS) est utilisé pour transférer ou distribuer des données à toutes les sources.
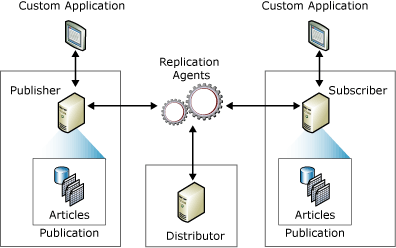
Tous les changements, ajouts et suppressions effectués sur la base de données source sont automatiquement synchronisés avec les autres bases de données cibles si ces changements sont nécessaires. Selon le paradigme logiciel classique éditeur-abonné, un ou plusieurs « éditeurs » et « abonnés » sont impliqués dans le processus de réplication des données.
 Crédit image : Microsoft
Crédit image : Microsoft
Un « éditeur » est un système ou la base de données source sur laquelle des modifications sont apportées, et un « abonné » est un système sur lequel les modifications sont répliquées.
Toutes les modifications effectuées sur un système « éditeur » sont ensuite répliquées sur les bases de données « abonnées ». Les utilisateurs peuvent également apporter des modifications aux bases de données des abonnés, qui sont ensuite répliquées dans la base de données de l’éditeur. Cela distribue les modifications à tous les autres abonnés du réseau si le système est bidirectionnel.
De plus, la plupart des abonnés ont un lien fixe avec l’éditeur, permettant aux modifications ou aux mises à niveau de se produire automatiquement sans intervention manuelle. Ces mises à jour peuvent se produire par lots à intervalles réguliers ou peuvent être déclenchées et appliquées en temps réel.
Types de réplication de base de données
Certains des types de réplication de base de données sont :
#1. Réplication de table complète
La réplication de table complète crée une copie de la base de données source complète sur le stockage cible. Il déplace les lignes de l’éditeur vers l’abonné, y compris les lignes nouvelles, modifiées et existantes.
Cependant, cette approche de réplication est liée à un coût de maintenance élevé en raison des besoins en puissance de calcul et en bande passante réseau nécessaires pour tout copier. Cela sollicite le réseau et peut créer des retards de réplication, en particulier lorsque le volume de données est plus important.
#2. Réplication d’instantané
Un instantané de la base de données source est utilisé dans cette réplication de base de données pour répliquer les données dans la base de données de destination cible. Il ne prend pas en compte les modifications de données telles que nouvelles, mises à jour ou supprimées ; au lieu de cela, il crée une copie de ce qu’il collecte à ce moment-là.
Lorsque les changements de données sont très peu nombreux, cette technique de réplication est préférable. Elle est nettement plus rapide que la réplication de table complète, mais elle ne conserve pas la trace des données supprimées définitivement.

#3. Réplication de fusion
La réplication de fusion est un processus qui transfère et distribue des objets et des données de base de données d’une base de données à une autre avec une synchronisation de base de données. Il est complexe car ce processus permet aux abonnés et aux éditeurs de modifier la base de données, ce qui entraîne de fréquents conflits de données liés à la version.
Les agents de fusion déployés sur les serveurs synchronisent toutes les modifications et suivent un processus de résolution de conflit prédéfini pour résoudre tout conflit de données.
#4. Réplication incrémentielle basée sur des clés
La réplication incrémentielle basée sur les clés vérifie les clés ou les index dans une base de données pour rechercher des modifications telles que la suppression, la création et la mise à jour. Le mécanisme de réplication copie ensuite uniquement les clés de réplication requises dans la base de données répliquée pour refléter les modifications depuis la dernière mise à jour. Ces clés sont généralement un horodatage, une date ou un entier.
Étant donné que seules les modifications indiquées sont répliquées dans la base de données répliquée, le processus est plus rapide. Malheureusement, cette méthode n’active pas les suppressions définitives car la valeur critique est supprimée en effaçant l’enregistrement de la base de données principale.
#5. Réplication incrémentielle basée sur le journal
Ce type de réplication de base de données duplique les données en fonction du fichier journal binaire de la base de données. Lors de l’inspection du fichier journal binaire, il vous fournira des informations sur les modifications apportées à la base de données principale, par exemple, les mises à jour, les insertions ou les suppressions. Ensuite, les mêmes modifications ou mises à jour sont effectuées dans votre base de données de destination.
C’est l’une des méthodes de réplication de données les plus utilisées car elle est efficace, en particulier pour les bases de données statiques. De plus, la plupart des fournisseurs de bases de données le prennent en charge, notamment Oracle, MongoDB, MySQL et PostgreSQL.
#6. Réplication transactionnelle
Lorsqu’il y a un nouveau développement dans les données source, la réplication transactionnelle déplace toutes les données existantes de la base de données source vers l’emplacement cible. Ensuite, il exécute la même transaction dans les répliques.
Bien qu’il s’agisse d’une méthode de réplication efficace, les modèles sont principalement utilisés dans les activités de lecture et peuvent ne pas autoriser les opérations de création, de suppression ou de mise à jour.
Pourquoi la réplication de base de données est-elle importante ?

La réplication de base de données est importante pour les raisons suivantes :
Fiabilité et disponibilité des données
La réplication des données favorise la disponibilité des données. Il joue un rôle important lorsqu’un serveur tombe en panne dans des circonstances inhabituelles en fournissant des sauvegardes de base de données. De cette façon, cela peut vous faire gagner du temps car les données sont disponibles à d’autres endroits. En outre, il améliore la fiabilité des données en conservant les dernières données pertinentes enregistrées en toute sécurité sur plusieurs serveurs.
reprise après sinistre
La réplication de base de données est utile lors d’un scénario de panne de serveur. C’est une merveilleuse technique de gestion des sinistres et de récupération car elle réplique et stocke les données et les modifications récentes sur d’autres emplacements de serveur au lieu de s’appuyer sur un seul serveur.
Performances du serveur
L’accès aux données est beaucoup plus rapide lorsque les données sont traitées et exploitées sur plusieurs serveurs. De plus, les administrateurs peuvent libérer des cycles de traitement sur le serveur d’origine pour des opérations d’écriture plus gourmandes en ressources en dirigeant toutes les opérations de lecture de données vers une réplique.
Meilleures performances réseau
La conservation de plusieurs copies des mêmes données à différents emplacements peut réduire la latence d’accès aux données, car vous pouvez récupérer les données pertinentes à partir de l’emplacement où la transaction est exécutée.
Par exemple, les utilisateurs des pays européens peuvent ressentir des problèmes de latence lorsqu’ils accèdent aux données des centres de données australiens. Ainsi, placer une réplique de ces données à proximité de l’utilisateur peut améliorer les temps d’accès tout en équilibrant la charge du réseau.
Amélioration des performances du système de test

La réplication de base de données rationalise la distribution et la synchronisation des données pour les systèmes de test qui nécessitent un accès rapide pour une prise de décision plus rapide.
Sauvegarde de base de données vs réplication de base de données
La sauvegarde de la base de données et la réplication de la base de données varient de plusieurs manières. Certains d’entre eux sont les suivants :
- Les sauvegardes de base de données doivent être reconstruites et restaurées avant de pouvoir être utilisées. Contrairement aux sauvegardes de base de données, la réplication de données ne nécessite pas de reconstruction et peut être utilisée immédiatement.
- Les sauvegardes de base de données se composent de fichiers ou de dossiers, de fichiers de données de base de données et de fichiers d’application, selon les protocoles de sauvegarde-restauration de l’organisation. En revanche, la réplication de base de données est souvent utilisée pour dupliquer des volumes complets ou des systèmes de fichiers, des bases de données et des applications.
- La sauvegarde et la réplication sont toutes deux des mesures de protection des données. Le premier concerne la réduction des objectifs de point de récupération (RPO) et la prévention de la perte de données. Alors que ce dernier est conçu pour réduire les objectifs de temps de récupération (RTO), assurer la continuité des activités et minimiser les temps d’arrêt.
- La sauvegarde de la base de données est une méthode peu coûteuse pour éviter la perte totale de données. Elle est indispensable à la conformité et ne garantit pas la continuité opérationnelle. Au contraire, la réplication garantit que les applications et les processus métier sont toujours disponibles, même après une panne de courant.
- La sauvegarde de la base de données concerne la conformité et la récupération granulaire, comme le stockage à long terme des enregistrements de l’entreprise. D’autre part, la réplication et la récupération de bases de données se concentrent sur la reprise après sinistre, la reprise rapide et facile des opérations après une panne ou une corruption.
- La sauvegarde de base de données est couramment utilisée sur le lieu de travail pour tout, des serveurs de production aux ordinateurs de bureau. Au contraire, la réplication de base de données est fréquemment utilisée pour les applications critiques qui doivent toujours être disponibles.
Techniques de réplication de bases de données

Les organisations peuvent répliquer des données en suivant une technique précise pour déplacer les données. Ces stratégies diffèrent des types de réplication décrits ci-dessus.
#1. Réplication complète de la base de données
La réplication complète de la base de données réplique une base de données entière pour une utilisation sur différents hôtes. Cela garantit la quantité la plus importante de redondance et de disponibilité des données. Pour les entreprises mondiales, cela permet aux utilisateurs en Asie d’accéder aux mêmes données que leurs homologues en Amérique du Nord à la même vitesse. Si le serveur asiatique échoue, les utilisateurs peuvent utiliser leurs serveurs européens ou nord-américains comme sauvegarde.
Cependant, l’inconvénient de cette technique est la lenteur de la procédure de mise à jour. Il est également difficile de conserver la cohérence de chaque emplacement de fichier, ce qui est important si les données changent en permanence.
#2. Réplication partielle de la base de données
La réplication partielle de base de données est le processus par lequel les données d’une base de données sont séparées en morceaux et enregistrées à différents endroits, en fonction de la pertinence de chaque site.
Les experts en sinistres, les conseillers financiers et les professionnels de la vente profitent d’une réplication partielle. Ces employés peuvent transporter les bases de données partielles sur d’autres appareils ou ordinateurs portables et les synchroniser régulièrement avec un serveur central.
Pour les analystes, il peut être plus économique de conserver des données européennes en Europe, des données australiennes en Australie, etc. Cela signifie garder les données proches des consommateurs tout en conservant un ensemble de données complet au siège pour une analyse de haut niveau.
Inconvénients de la réplication de base de données

Bien que la réplication des données puisse apporter une valeur significative à votre travail et à votre entreprise, elle présente également les inconvénients suivants :
Coûts plus élevés
Lorsque les données sont répliquées et stockées à plusieurs endroits, elles nécessitent plus d’espace de stockage et de ressources informatiques. Cette demande accrue de ressources matérielles et informatiques peut entraîner des coûts plus élevés, notamment l’achat et la maintenance de périphériques de stockage, de serveurs et d’infrastructures réseau supplémentaires.
Contraintes de temps
La réplication de données est un processus complexe qui implique la copie de données d’un emplacement vers plusieurs autres emplacements et le maintien de la cohérence entre toutes les copies. Ce processus peut prendre beaucoup de temps, en particulier pour les organisations qui doivent répliquer de grandes quantités de données.
Bande passante
À mesure que le volume de données répliquées augmente, les besoins en bande passante augmentent également, ce qui peut peser sur les ressources du réseau.
Données incohérentes
Lors de la réplication de données dans un environnement distribué, il existe un risque de désynchronisation des données si les mises à jour ne sont pas effectuées de manière cohérente sur toutes les répliques. Cela peut entraîner des données incohérentes et peut nécessiter des efforts supplémentaires pour résoudre.
Cas d’utilisation de la réplication de base de données

Il existe de nombreux cas où la réplication de données peut être utilisée, tels que :
L’équilibrage de charge
En répliquant les données sur plusieurs serveurs, la charge est répartie sur ces serveurs pour améliorer ses performances. Ainsi, l’équilibrage de charge garantit qu’un seul serveur n’est pas submergé par trop de requêtes et que le système reste disponible et réactif même pendant les périodes de fort trafic.
Entreposage de données
Un entrepôt de données est un référentiel centralisé pour stocker de grandes quantités de données provenant de plusieurs sources. La réplication des données de ces sources vers l’entrepôt de données permet aux organisations d’analyser et de générer des rapports sur leurs données de manière centralisée et organisée.
Déploiement interrégional
La réplication des données dans plusieurs régions permet aux organisations d’améliorer l’accessibilité et la redondance des données. Si une région subit une panne, les données sont toujours accessibles depuis une autre région. De plus, le fait de disposer de données dans plusieurs régions peut aider à améliorer la vitesse d’accès pour les utilisateurs dans différentes parties du monde.
Sauvegarde et archivage
La réplication des données vers un stockage secondaire aide les organisations à conserver une copie à long terme de leurs données. Cela leur permet d’accéder facilement aux données et garantit qu’elles ne seront pas perdues même en cas de défaillance du stockage principal.
Synchronisation des données
La réplication des données entre plusieurs systèmes permet de garantir que les données restent synchronisées, cohérentes et à jour partout. Ceci est important pour des applications telles que le commerce électronique, où les mêmes données doivent être accessibles à partir de plusieurs systèmes.
Collaboration multi-sites
La réplication des données entre plusieurs sites permet aux organisations de partager des données en temps réel, permettant la collaboration et une productivité accrue. Ceci est particulièrement utile pour les organisations avec des équipes sur plusieurs sites ou pour les entreprises qui ont besoin de partager des données avec des partenaires ou des clients.
Ressources d’apprentissage
Voici quelques ressources d’apprentissage pour vous aider à mieux comprendre le sujet :
#1. Réplication de base de données par Bettina Kemme
Ce livre vous aidera à comprendre les différents mécanismes de contrôle de la concurrence et des répliques et les problèmes qui les concernent.
#2. Réplication de base de données : un guide complet :
Ce livre vous préparera à relever les défis de la réplication de bases de données en expliquant et en répondant à vos questions.
Conclusion
La réplication des données est une stratégie sous-estimée dans le monde d’aujourd’hui en pleine croissance et axé sur les données. Donc, si vous êtes propriétaire d’une entreprise, vous seriez surpris par ses avantages.
Cependant, à mesure que le nombre de sources et de destinations augmente, les entreprises doivent être prêtes à relever les défis qui en découlent. C’est pourquoi une stratégie de réplication de données fiable et évolutive peut vous être utile.
Vous pouvez également explorer certains logiciels de surveillance de base de données utiles pour analyser les performances.