

Le traitement des mégadonnées est l’une des procédures les plus complexes auxquelles les organisations sont confrontées. Le processus devient plus compliqué lorsque vous disposez d’un grand volume de données en temps réel.
Dans cet article, nous allons découvrir ce qu’est le traitement des données volumineuses, comment cela se fait, et explorer Apache Kafka et Spark – les deux outils de traitement de données les plus célèbres !
Table des matières
Qu’est-ce que le traitement des données ? Comment est-il fait?
Le traitement de données se définit comme toute opération ou ensemble d’opérations, réalisées ou non à l’aide d’un procédé automatisé. Elle peut être considérée comme la collecte, la mise en ordre et l’organisation d’informations selon une disposition logique et appropriée pour l’interprétation.
Lorsqu’un utilisateur accède à une base de données et obtient des résultats pour sa recherche, c’est le traitement des données qui lui fournit les résultats dont il a besoin. Les informations extraites en tant que résultat de la recherche sont le résultat du traitement des données. C’est pourquoi la technologie de l’information est centrée sur le traitement des données.
Le traitement traditionnel des données était effectué à l’aide d’un logiciel simple. Cependant, avec l’émergence du Big Data, les choses ont changé. Le Big Data fait référence à des informations dont le volume peut dépasser une centaine de téraoctets et pétaoctets.
De plus, ces informations sont régulièrement mises à jour. Les exemples incluent les données provenant des centres de contact, des médias sociaux, des données de négociation en bourse, etc. Ces données sont parfois également appelées flux de données – un flux de données constant et incontrôlé. Sa principale caractéristique est que les données n’ont pas de limites définies, il est donc impossible de dire quand le flux commence ou se termine.
Les données sont traitées au fur et à mesure qu’elles arrivent à destination. Certains auteurs l’appellent traitement en temps réel ou en ligne. Une approche différente est le traitement par blocs, par lots ou hors ligne, dans lequel des blocs de données sont traités dans des fenêtres temporelles d’heures ou de jours. Souvent, le lot est un processus qui s’exécute la nuit, consolidant les données de la journée. Il existe des cas de fenêtres temporelles d’une semaine ou même d’un mois générant des rapports obsolètes.
Etant donné que les meilleures plateformes de traitement du Big Data via le streaming sont des sources ouvertes telles que Kafka et Spark, ces plateformes permettent l’utilisation d’autres plateformes différentes et complémentaires. Cela signifie qu’étant open source, ils évoluent plus vite et utilisent plus d’outils. De cette façon, les flux de données sont reçus d’autres endroits à un débit variable et sans aucune interruption.
Maintenant, nous allons examiner deux des outils de traitement de données les plus connus et les comparer :
Apache Kafka
Apache Kafka est un système de messagerie qui crée des applications de streaming avec un flux de données continu. Créé à l’origine par LinkedIn, Kafka est basé sur les journaux ; un journal est une forme de stockage de base car chaque nouvelle information est ajoutée à la fin du fichier.

Kafka est l’une des meilleures solutions pour le big data car sa principale caractéristique est son haut débit. Avec Apache Kafka, il est même possible de transformer le traitement par lots en temps réel,
Apache Kafka est un système de messagerie de publication-abonnement dans lequel une application publie et une application qui s’abonne reçoit des messages. Le temps entre la publication et la réception du message peut être de quelques millisecondes, donc une solution Kafka a une faible latence.
Travail de Kafka
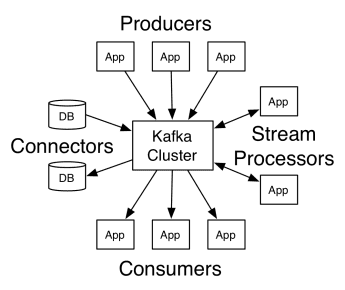
L’architecture d’Apache Kafka comprend les producteurs, les consommateurs et le cluster lui-même. Le producteur est toute application qui publie des messages sur le cluster. Le consommateur est toute application qui reçoit des messages de Kafka. Le cluster Kafka est un ensemble de nœuds qui fonctionnent comme une instance unique du service de messagerie.
 Travail de Kafka
Travail de Kafka
Un cluster Kafka est composé de plusieurs brokers. Un courtier est un serveur Kafka qui reçoit les messages des producteurs et les écrit sur disque. Chaque courtier gère une liste de sujets, et chaque sujet est divisé en plusieurs partitions.
Après avoir reçu les messages, le courtier les envoie aux consommateurs enregistrés pour chaque sujet.
Les paramètres Apache Kafka sont gérés par Apache Zookeeper, qui stocke les métadonnées du cluster telles que l’emplacement de la partition, la liste des noms, la liste des rubriques et les nœuds disponibles. Ainsi, Zookeeper maintient la synchronisation entre les différents éléments du cluster.
Zookeeper est important car Kafka est un système distribué ; c’est-à-dire que l’écriture et la lecture sont effectuées par plusieurs clients simultanément. En cas de panne, le Zookeeper élit un remplaçant et récupère l’opération.
Cas d’utilisation
Kafka est devenu populaire, notamment pour son utilisation en tant qu’outil de messagerie, mais sa polyvalence va au-delà, et il peut être utilisé dans une variété de scénarios, comme dans les exemples ci-dessous.
Messagerie
Forme de communication asynchrone qui découple les parties qui communiquent. Dans ce modèle, une partie envoie les données sous forme de message à Kafka, de sorte qu’une autre application les consomme plus tard.
Suivi d’activité
Vous permet de stocker et de traiter les données de suivi de l’interaction d’un utilisateur avec un site Web, telles que les pages vues, les clics, la saisie de données, etc. ; ce type d’activité génère généralement un grand volume de données.
Métrique
Implique l’agrégation de données et de statistiques provenant de plusieurs sources pour générer un rapport centralisé.
Agrégation de journaux
Agrége et stocke de manière centralisée les fichiers journaux provenant d’autres systèmes.
Traitement de flux
Le traitement des pipelines de données se compose de plusieurs étapes, où les données brutes sont consommées à partir de sujets et agrégées, enrichies ou transformées en d’autres sujets.
Pour prendre en charge ces fonctionnalités, la plate-forme fournit essentiellement trois API :
- API Streams : elle agit comme un processeur de flux qui consomme les données d’un sujet, les transforme et les écrit dans un autre.
- API de connecteurs : elle permet de connecter des sujets à des systèmes existants, tels que des bases de données relationnelles.
- API producteur et consommateur : elles permettent aux applications de publier et de consommer des données Kafka.
Avantages
Répliqué, partitionné et ordonné
Les messages dans Kafka sont répliqués sur les partitions des nœuds de cluster dans leur ordre d’arrivée pour garantir la sécurité et la rapidité de livraison.
Transformation des données
Avec Apache Kafka, il est même possible de transformer le traitement par lots en temps réel à l’aide de l’API de flux ETL par lots.
Accès séquentiel au disque
Apache Kafka conserve le message sur disque et non en mémoire, car il est censé être plus rapide. En fait, l’accès à la mémoire est plus rapide dans la plupart des situations, en particulier lorsqu’il s’agit d’accéder à des données situées à des emplacements aléatoires dans la mémoire. Cependant, Kafka effectue un accès séquentiel, et dans ce cas, le disque est plus efficace.
Apache Étincelle
Apache Spark est un moteur de calcul Big Data et un ensemble de bibliothèques pour le traitement de données parallèles entre clusters. Spark est une évolution de Hadoop et du paradigme de programmation Map-Reduce. Il peut être 100 fois plus rapide grâce à son utilisation efficace de la mémoire qui ne conserve pas les données sur les disques pendant le traitement.
Spark est organisé à trois niveaux :
- API de bas niveau : ce niveau contient les fonctionnalités de base pour exécuter des tâches et d’autres fonctionnalités requises par les autres composants. Les autres fonctions importantes de cette couche sont la gestion de la sécurité, du réseau, de la planification et de l’accès logique aux systèmes de fichiers HDFS, GlusterFS, Amazon S3 et autres.
- API structurées : le niveau de l’API structurée traite de la manipulation des données via des ensembles de données ou des cadres de données, qui peuvent être lus dans des formats tels que Hive, Parquet, JSON et autres. En utilisant SparkSQL (API qui nous permet d’écrire des requêtes en SQL), nous pouvons manipuler les données comme nous le souhaitons.
- Haut niveau : Au plus haut niveau, nous avons l’écosystème Spark avec diverses bibliothèques, notamment Spark Streaming, Spark MLlib et Spark GraphX. Ils sont chargés de s’occuper de l’ingestion de flux et des processus environnants, tels que la récupération sur incident, la création et la validation de modèles d’apprentissage automatique classiques et la gestion des graphiques et des algorithmes.
Fonctionnement de Spark
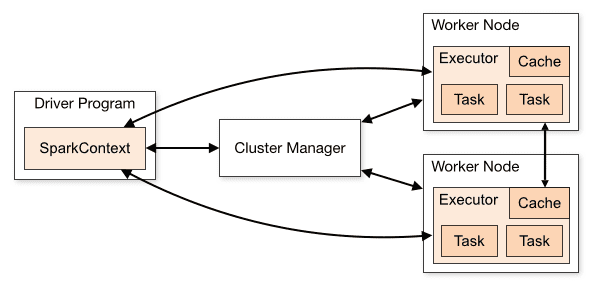
L’architecture d’une application Spark se compose de trois parties principales :
Driver Program : Il est chargé d’orchestrer l’exécution du traitement des données.
Cluster Manager : C’est le composant chargé de gérer les différentes machines d’un cluster. Nécessaire uniquement si Spark s’exécute de manière distribuée.
Nœuds de travail : ce sont les machines qui exécutent les tâches d’un programme. Si Spark est exécuté localement sur votre machine, il jouera un programme pilote et un rôle Workes. Cette façon d’exécuter Spark s’appelle Standalone.
 Présentation du cluster
Présentation du cluster
Le code Spark peut être écrit dans plusieurs langages différents. La console Spark, appelée Spark Shell, est interactive pour apprendre et explorer les données.
L’application dite Spark se compose d’un ou plusieurs Jobs, permettant le support du traitement de données à grande échelle.
Quand on parle d’exécution, Spark a deux modes :
- Client : Le pilote s’exécute directement sur le client, qui ne passe pas par le Resource Manager.
- Cluster : Pilote exécuté sur l’application maître via le gestionnaire de ressources (en mode cluster, si le client se déconnecte, l’application continuera de s’exécuter).
Il est nécessaire d’utiliser Spark correctement afin que les services liés, tels que le gestionnaire de ressources, puissent identifier le besoin de chaque exécution, offrant les meilleures performances. C’est donc au développeur de connaître la meilleure façon d’exécuter ses jobs Spark, en structurant l’appel effectué, et pour cela, vous pouvez structurer et configurer les exécuteurs Spark comme vous le souhaitez.
Les tâches Spark utilisent principalement de la mémoire, il est donc courant d’ajuster les valeurs de configuration Spark pour les exécuteurs de nœud de travail. En fonction de la charge de travail Spark, il est possible de déterminer qu’une certaine configuration Spark non standard fournit des exécutions plus optimales. À cette fin, des tests de comparaison entre les différentes options de configuration disponibles et la configuration Spark par défaut elle-même peuvent être effectués.
Cas d’utilisation
Apache Spark aide à traiter d’énormes quantités de données, qu’elles soient en temps réel ou archivées, structurées ou non structurées. Voici quelques-uns de ses cas d’utilisation populaires.
Enrichissement des données
Souvent, les entreprises utilisent une combinaison de données clients historiques avec des données comportementales en temps réel. Spark peut aider à créer un pipeline ETL continu pour convertir des données d’événements non structurées en données structurées.
Déclencher la détection d’événement
Spark Streaming permet une détection et une réponse rapides à certains comportements rares ou suspects qui pourraient indiquer un problème potentiel ou une fraude.
Analyse de données de session complexe
À l’aide de Spark Streaming, les événements liés à la session de l’utilisateur, tels que ses activités après sa connexion à l’application, peuvent être regroupés et analysés. Ces informations peuvent également être utilisées en continu pour mettre à jour les modèles d’apprentissage automatique.
Avantages
Traitement itératif
Si la tâche consiste à traiter des données de manière répétée, les ensembles de données distribués (RDD) résilients de Spark permettent plusieurs opérations de mappage en mémoire sans avoir à écrire les résultats intermédiaires sur le disque.
Traitement graphique
Le modèle de calcul de Spark avec l’API GraphX est excellent pour les calculs itératifs typiques du traitement graphique.
Apprentissage automatique
Spark a MLlib – une bibliothèque d’apprentissage automatique intégrée qui contient des algorithmes prêts à l’emploi qui s’exécutent également en mémoire.
Kafka contre Spark
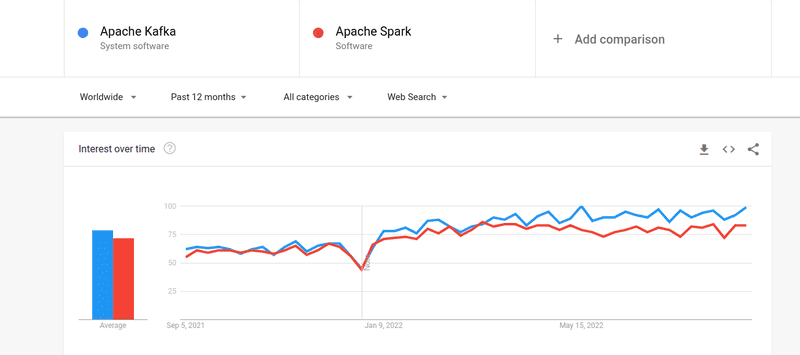
Même si l’intérêt des gens pour Kafka et Spark a été presque similaire, il existe des différences majeures entre les deux ; regardons.
#1. Traitement de l’information
Kafka est un outil de streaming et de stockage de données en temps réel responsable du transfert de données entre les applications, mais cela ne suffit pas pour construire une solution complète. Par conséquent, d’autres outils sont nécessaires pour les tâches que Kafka ne fait pas, comme Spark. Spark, d’autre part, est une plate-forme de traitement de données par lots qui extrait les données des sujets Kafka et les transforme en schémas combinés.
#2. Gestion de la mémoire
Spark utilise des ensembles de données distribués robustes (RDD) pour la gestion de la mémoire. Au lieu d’essayer de traiter d’énormes ensembles de données, il les distribue sur plusieurs nœuds dans un cluster. En revanche, Kafka utilise un accès séquentiel similaire à HDFS et stocke les données dans une mémoire tampon.
#3. Transformation ETL
Spark et Kafka prennent tous deux en charge le processus de transformation ETL, qui copie les enregistrements d’une base de données à une autre, généralement d’une base transactionnelle (OLTP) à une base analytique (OLAP). Cependant, contrairement à Spark, qui est livré avec une capacité intégrée pour le processus ETL, Kafka s’appuie sur l’API Streams pour le prendre en charge.
#4. Persistance des données

L’utilisation de RRD par Spark vous permet de stocker les données dans plusieurs emplacements pour une utilisation ultérieure, alors que dans Kafka, vous devez définir des objets de jeu de données dans la configuration pour conserver les données.
#5. Difficulté
Spark est une solution complète et plus facile à apprendre grâce à sa prise en charge de divers langages de programmation de haut niveau. Kafka dépend d’un certain nombre d’API et de modules tiers différents, ce qui peut rendre difficile son utilisation.
#6. Récupération
Spark et Kafka proposent tous deux des options de récupération. Spark utilise RRD, ce qui lui permet de sauvegarder les données en continu, et en cas de défaillance du cluster, elles peuvent être récupérées.

Kafka réplique en permanence les données à l’intérieur du cluster et la réplication entre les courtiers, ce qui vous permet de passer aux différents courtiers en cas de panne.
Similitudes entre Spark et Kafka
Apache SparkApache KafkaOpenSourceOpenSourceCréer une application de streaming de donnéesCréer une application de streaming de donnéesPrend en charge le traitement avec étatPrend en charge le traitement avec étatPrend en charge SQLPrend en charge SQLSimilarités entre Spark et Kafka
Derniers mots
Kafka et Spark sont tous deux des outils open source écrits en Scala et Java, qui vous permettent de créer des applications de streaming de données en temps réel. Ils ont plusieurs choses en commun, notamment le traitement avec état, la prise en charge de SQL et ETL. Kafka et Spark peuvent également être utilisés comme outils complémentaires pour aider à résoudre le problème de la complexité du transfert de données entre applications.