Data Lake vs Data Warehouse : quelles sont les différences ?
Le rôle crucial des données dans l'entreprise moderne
Aujourd'hui, les entreprises sont résolument tournées vers les données. Elles cherchent constamment des méthodes performantes pour extraire et analyser les informations issues de sources variées, dans le but d'améliorer leurs revenus et leurs bénéfices.
Cependant, une question essentielle se pose : où stocker et intégrer ces données de diverses origines de manière sécurisée et optimale ?
Les lacs de données et les entrepôts de données se présentent comme des solutions populaires pour gérer de vastes volumes d'informations. Leurs différences résident principalement dans la manière dont les organisations ingèrent, conservent et exploitent ces données. Poursuivez votre lecture pour approfondir le sujet.
Qu'est-ce qu'un lac de données ?
Un lac de données est un référentiel centralisé où les données provenant de multiples sources – sous tous types de formats (structurés ou non structurés) – sont stockées dans leur état brut. Il s'apparente à une réserve de données brutes, dont la finalité n'est pas encore définie. Généralement, les entreprises y conservent les informations susceptibles d'être utiles pour des analyses futures.
Principales caractéristiques d'un lac de données :
- Il englobe un mélange de données pertinentes et non pertinentes, nécessitant donc un espace de stockage conséquent.
- Il enregistre à la fois des données en temps réel et par lots. Par exemple, il est possible d'y conserver des données en temps réel provenant d'appareils IoT, de réseaux sociaux ou d'applications cloud, ainsi que des données par lots issues de bases de données ou de fichiers.
- Il présente une architecture plate.
- Puisque les données ne sont traitées qu'au moment de l'analyse, elles doivent être gérées et entretenues avec soin afin d'éviter qu'il ne se transforme en un véritable marécage de données.
Comment extraire rapidement les informations d'un référentiel aussi vaste et apparemment désordonné ? La solution réside dans l'utilisation de balises de métadonnées et d'identifiants.
Qu'est-ce qu'un entrepôt de données ?
Un entrepôt de données est un référentiel plus organisé et structuré, contenant des données prêtes à être analysées. Les données structurées, semi-structurées ou non structurées, issues de sources variées, sont ingérées, intégrées, nettoyées, triées, transformées et adaptées à leur usage.
L'entrepôt de données rassemble de grandes quantités de données passées et actuelles. Elles sont généralement traitées en vue de résoudre un problème commercial spécifique (analyse). Ces informations sont ensuite interrogées par les systèmes de Business Intelligence (BI) à des fins d'analyse, de création de rapports et d'éclaircissement.
Un entrepôt de données se compose généralement des éléments suivants :
- Une base de données (SQL ou NoSQL) pour le stockage et la gestion des données
- Des outils de transformation et d'analyse des données pour leur préparation
- Des outils de BI pour l'exploration de données, l'analyse statistique, le reporting et la visualisation
Étant donné que les entrepôts de données sont conçus pour un objectif précis, les informations qu'ils contiennent sont toujours pertinentes. Vous pouvez également y intégrer des outils supplémentaires pour des fonctionnalités avancées telles que l'intelligence artificielle ou le traitement des données spatiales et graphiques. Les entrepôts de données créés pour un domaine spécifique sont appelés "data marts".
Principales différences entre les lacs de données et les entrepôts de données
Pour résumer, un lac de données contient des informations brutes dont la finalité n'est pas encore déterminée. Un entrepôt de données, quant à lui, comprend des données prêtes à l'emploi, déjà optimisées pour l'analyse.
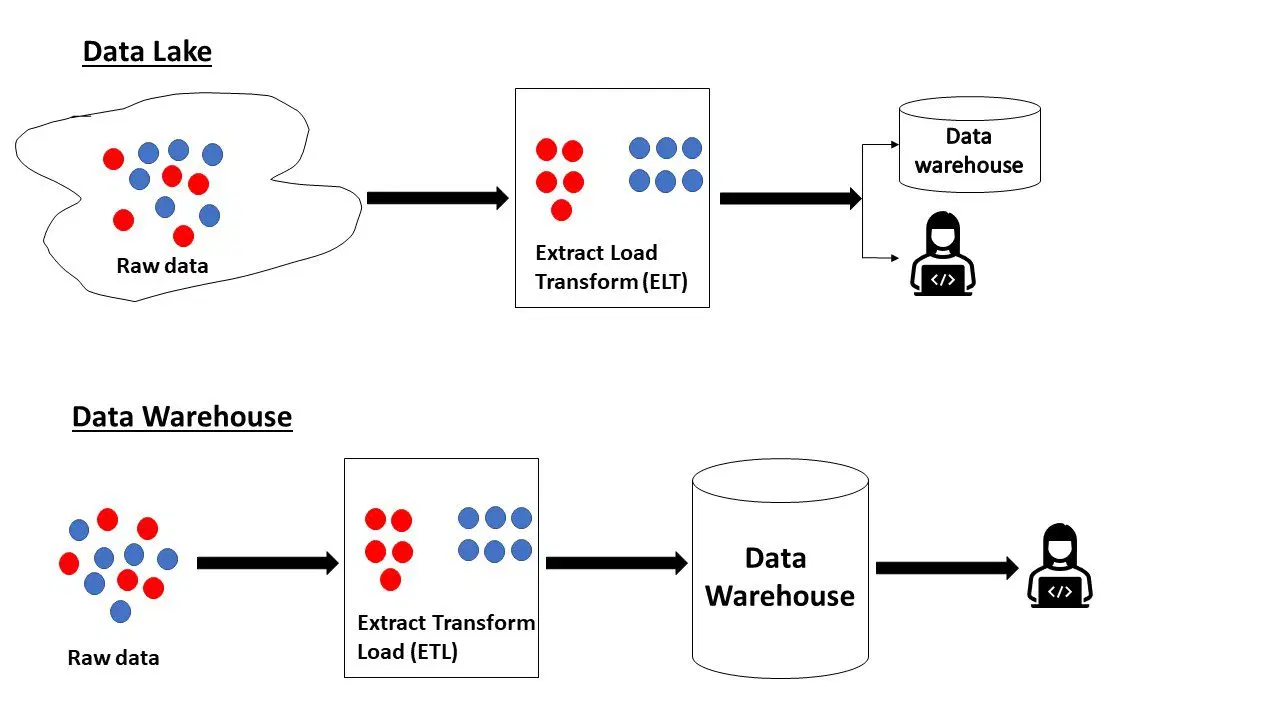
Voici quelques distinctions notables entre les deux :
| Lac de données | Entrepôt de données |
| Les données brutes, dans n'importe quel format, sont ingérées depuis diverses sources. | Les données sont extraites de sources multiples pour l'analyse et la production de rapports. Elles sont structurées. |
| Le schéma est défini à la volée, en fonction des besoins (schéma en lecture). | Le schéma est prédéfini lors de l'écriture dans l'entrepôt (schéma en écriture). |
| De nouvelles données peuvent être ajoutées facilement. | Les données sont prêtes après traitement ; toute modification nécessite donc plus de temps et d'efforts. |
| Les données doivent être mises à jour et gouvernées pour rester pertinentes. | Les données étant déjà optimisées, elles ne nécessitent pas de maintenance particulière. |
| Les volumes de données sont généralement très importants (pétaoctets). | Les volumes de données sont généralement inférieurs à ceux d'un lac de données (téraoctets). L'entrepôt peut contenir des données opérationnelles de toute une organisation, des données analytiques ou des données pertinentes pour un domaine spécifique. |
| Principalement utilisé par les data scientists pour diverses applications telles que l'analyse en continu, l'intelligence artificielle, l'analyse prédictive et divers autres cas d'utilisation. | Principalement utilisé par les analystes commerciaux pour le traitement des transactions (OLTP), l'analyse opérationnelle (OLAP), la création de rapports et de visualisations. |
| Les données peuvent être stockées et archivées sur une longue période afin d'être analysées ultérieurement. | Les données doivent être purgées fréquemment pour faire place aux informations les plus récentes. |
| Le stockage est peu coûteux. | Le stockage et la maintenance des données sont plus coûteux et doivent donc être planifiés avec soin. |
| Les data scientists peuvent explorer les données afin de trouver de nouvelles solutions à des problèmes. | La portée des données est limitée à un problème commercial spécifique. |
| Puisque les données ne sont pas organisées d'une manière particulière, des bases de données relationnelles et non relationnelles peuvent être utilisées pour les stocker. | Les entrepôts de données utilisent principalement des bases de données relationnelles, car les données doivent respecter un format spécifique. |
Cas d'utilisation pour les lacs de données et les entrepôts de données
Il peut être tentant de considérer le lac de données comme la solution la plus pratique en raison de son évolutivité, de sa flexibilité et de sa convivialité. Cependant, l'entrepôt de données peut s'avérer plus judicieux lorsque des données structurées et pertinentes sont nécessaires pour une analyse ciblée.
Voici quelques exemples d'applications typiques d'un lac de données :
#1. Chaîne d'approvisionnement et gestion
La grande quantité de données contenues dans les lacs de données facilite l'analyse prédictive pour le transport et la logistique. En exploitant les données historiques et actuelles, les entreprises peuvent planifier efficacement leurs opérations, suivre les mouvements des stocks en temps réel et optimiser les coûts.
#2. Santé
Le lac de données centralise toutes les informations des patients, passées et actuelles. Cela s'avère très utile pour la recherche, l'identification de modèles, la mise en place de traitements améliorés, l'automatisation des diagnostics et l'obtention de détails précis sur l'état de santé d'un patient.
#3. Données en continu et IoT
Les lacs de données peuvent recevoir en continu des flux d'informations soumis à des pipelines d'analyse, pour des rapports continus et la détection d'activités inhabituelles. Cela est possible grâce à la capacité du lac à recueillir des données en temps (quasi) réel.
Voici quelques exemples d'applications typiques d'un entrepôt de données :
#1. Finance
Les informations financières d'une entreprise conviennent particulièrement bien à un entrepôt de données. Les employés peuvent facilement accéder à des données organisées et structurées sous forme de graphiques et de rapports pour gérer les processus financiers, maîtriser les risques et prendre des décisions stratégiques.
#2. Marketing et segmentation clientèle
L'entrepôt de données crée une source unique de "vérité" sur les clients, en consolidant des données provenant de diverses sources. Les entreprises peuvent analyser ces informations pour comprendre les comportements des clients, proposer des offres personnalisées, segmenter les clients en fonction de leurs préférences et générer de nouveaux prospects.
#3. Tableaux de bord et rapports d'entreprise
De nombreuses entreprises utilisent les entrepôts de données CRM et ERP pour extraire des données sur les clients internes et externes. Ces données, toujours pertinentes et fiables, permettent de générer des rapports et des visualisations de qualité.
#4. Migration de données à partir de systèmes hérités
En utilisant les capacités ETL des entrepôts de données, les entreprises peuvent transformer les données des systèmes hérités en un format plus utilisable, compatible avec les nouveaux systèmes d'analyse. Cela permet aux organisations de mieux comprendre les tendances historiques et de prendre des décisions commerciales éclairées.
Exemples d'outils pour lacs de données
Voici quelques-uns des principaux fournisseurs de solutions de lacs de données :
- Microsoft Azure – Azure peut stocker et analyser des pétaoctets de données. Il facilite le débogage et l'optimisation des programmes de Big Data.
- Google Cloud – Google Cloud propose une solution économique pour l'ingestion, le stockage et l'analyse de volumes considérables de données, quel que soit leur format. Il s'intègre également avec des outils d'analyse tels qu'Apache Spark, BigQuery et d'autres accélérateurs d'analyse.
- Atlas MongoDB – Le lac de données Atlas est une solution entièrement gérée. Il offre des moyens rentables de stocker des données à grande échelle et d'exécuter des requêtes hautes performances en consommant moins de puissance de calcul, ce qui permet de gagner du temps et de l'argent.
- AmazonS3 – Le cloud AWS fournit les outils nécessaires pour créer un lac de données flexible, sécurisé et rentable. Il propose une console interactive pour gérer les utilisateurs du lac de données et contrôler leur accès.
Exemples d'outils pour entrepôts de données
Voici quelques-uns des principaux fournisseurs de solutions d'entrepôt de données :
- SAP – L'entrepôt de données SAP permet aux utilisateurs d'accéder de manière sémantique à des données riches issues de sources diverses. Les entreprises peuvent partager des informations et des modèles en toute sécurité, accélérer la prise de décision et combiner des données externes et internes.
- ClicData – L'entrepôt de données intelligent et intégré de ClicData garantit l'intégrité, la qualité et la facilité de reporting des données. ClicData propose des systèmes de planification et des API en temps réel pour que vous puissiez obtenir des données mises à jour à tout moment.
- Redshift d'Amazon – L'un des entrepôts de données les plus utilisés, Redshift utilise SQL pour analyser tous les types de données présentes dans diverses bases de données, lacs de données ou autres entrepôts. Il offre un excellent équilibre entre coût et performance.
- Entrepôt IBM Db2 – IBM propose des solutions d'entreposage de données internes, cloud et intégrées. Il intègre des outils d'apprentissage automatique et d'intelligence artificielle pour une analyse approfondie des données et partage un moteur SQL commun pour simplifier les requêtes.
- Entrepôt de données Oracle Cloud – Oracle utilise une base de données en mémoire et propose des fonctionnalités graphiques, d'apprentissage automatique et spatiales pour une analyse de données rapide et enrichie.
Derniers mots
Les lacs de données et les entrepôts de données ont chacun leurs propres avantages et cas d'utilisation idéaux. Si les lacs de données sont plus évolutifs et flexibles, les entrepôts de données offrent des informations structurées et fiables. La mise en œuvre des lacs de données est relativement récente, tandis que les entrepôts de données représentent un concept établi, utilisé par de nombreuses organisations pour gérer efficacement leurs données internes et externes.