

Un plan de reprise après sinistre est une mesure primordiale qu’une organisation doit avoir avant qu’un événement inhabituel ne la frappe.
Dans l’industrie informatique, cela commence par la création d’un document formel contenant des plans, des actions et des procédures pour faire face à la catastrophe et à ses séquelles.
Une catastrophe est un événement qui survient soudainement sans préavis et peut être de différents types. Et lorsqu’il atterrit, les individus et les organisations sont confrontés à des difficultés de toutes sortes, y compris des problèmes financiers et l’expérience utilisateur.
Si une attaque se produit, vous devez être prêt à minimiser ses effets et à restaurer vos opérations plus rapidement. C’est là que la préparation d’un plan de reprise après sinistre pratique vous aidera à retenir ou à prévenir la catastrophe. Vous pouvez également réduire ses séquelles en termes d’expérience utilisateur, de coût et de temps d’arrêt.
De plus, vous devez garder vos plans, votre personnel, vos stratégies, votre équipement et vos systèmes prêts à tout remettre en action. Mais pour cela, vous devez comprendre en profondeur la reprise après sinistre.
Dans cet article, j’en discuterai en détail ainsi que les principales terminologies de reprise après sinistre afin que vous puissiez riposter courageusement et sortir plus fort dans des conditions aussi défavorables.
Commençons!
Table des matières
Qu’est-ce qu’une catastrophe ?
Une catastrophe est un événement imprévu qui peut se produire n’importe où, y compris dans l’industrie informatique. Il se produit naturellement ou par des personnes et peut interférer avec les opérations d’une entreprise et perturber le tissu de l’infrastructure.
Par conséquent, une organisation et ses clients, fournisseurs, employés et partenaires sont touchés. Cela exerce une pression sur l’organisation en termes de finances, de réputation de l’industrie, de confiance des clients et de périmètre de sécurité.
Par conséquent, vous devez être prêt à l’avance pour surmonter un tel scénario. Pour cela, vous devez récupérer instantanément toutes les opérations et données. En termes simples, vous devez préparer votre organisation à tout récupérer dans les plus brefs délais pour vos clients.
Les catastrophes sont de plusieurs types, telles que les cyberattaques, le sabotage, les attaques terroristes, les rançongiciels ou les menaces physiques, les ouragans, les tremblements de terre, les incendies, les inondations, les accidents industriels, les pannes de courant et bien plus encore.
Qu’entendez-vous par reprise après sinistre ?

La reprise après sinistre est le processus de reprise des opérations normales après avoir souffert d’un sinistre. Cela implique de reprendre l’accès au matériel, aux logiciels, à l’équipement, à la connectivité, au réseau, à l’alimentation et aux données. Vous devez définir des règles et des procédures dans un processus documenté pour préparer votre organisation avant un sinistre.
Cependant, si les installations de votre organisation sont détruites, vous devez étendre certaines des activités en travaillant sur la communication, le transport, l’approvisionnement, les lieux de travail, etc.
Pourquoi le plan de reprise après sinistre est-il important ?
L’élaboration d’un plan parfait pour se remettre d’une catastrophe, qu’elle soit naturelle ou provoquée par l’homme, est essentielle pour chaque industrie informatique. Assurez-vous d’avoir le bon employé et les bons outils au bon endroit pour mener à bien le plan.
Voyons plus en détail pourquoi la reprise après sinistre est cruciale.
Limiter les dommages
Une catastrophe est imprévisible. Personne ne sait quand ça va et vient. Mais, vous vous préparez à l’avance pour maîtriser les dommages causés à votre infrastructure.
Par exemple, dans les zones inondables, vous pouvez placer vos documents et types d’équipements essentiels au dernier étage pour éviter les dommages.
De même, sauvegardez vos données essentielles avant que les cyberattaques ne puissent violer des données ou les voler.
Rétablissement des services
Si vous préparez un plan solide pour récupérer de la catastrophe, la restauration de tous les services à leur forme normale est simple et rapide. Cela signifie que dans un court intervalle de temps, vous pouvez récupérer presque tous les principaux actifs et services.
Minimiser les interruptions
Vous ne pouvez pas savoir ce qui se passera demain ou dans la prochaine étape d’une opération. Mais, avec un plan de récupération parfait, vous n’avez pas à vous soucier beaucoup des conséquences. Votre infrastructure peut poursuivre les opérations avec un minimum d’interruption.
Formation et préparation

Une infrastructure informatique se compose de nombreux employés travaillant sous un même toit. Tous doivent être au courant de la reprise pour agir immédiatement comme requis et prévu en cas d’urgence.
Une bonne préparation réduira également le niveau de stress de toutes les personnes associées à votre organisation. De plus, vous pouvez former vos employés à prendre les mesures nécessaires si un événement inattendu se produit.
Terminologies de reprise après sinistre
Commençons par les terminologies pour comprendre la reprise après sinistre de plus près.
RTO
L’objectif de temps de récupération (RTO) est la durée qu’une organisation fixe en fonction de la nature de l’entreprise pour tolérer une catastrophe sans affecter la croissance financière.
Lors de la définition du RTO, une entreprise doit vérifier les temps d’arrêt qui peuvent affecter votre organisation de plusieurs façons. Il est utilisé pour étudier des stratégies viables pour poursuivre vos opérations commerciales même après une catastrophe. Lorsque les clients sont confrontés à des perturbations dans l’application, ils demandent combien de temps une application prendra pour revenir à l’action. La réponse est RTO pour chaque organisation.
Exemple : Supposons que vous soyez une société de transactions en ligne comme PayPal ou Pioneer confrontée à des événements imprévisibles. Dans ce cas, votre RTO sera assez rapide pour récupérer l’opération.
En d’autres termes, une entreprise fixe son RTO à une heure ou deux pour éviter les conséquences sous forme de finances ou de données.
RPO
Les objectifs de point de récupération (RPO) correspondent à la perte de données qu’une infrastructure informatique peut gérer en termes de temps et de quantité d’informations.
Déroutant?
Prenons l’exemple d’une base de données qui enregistre les transactions d’une banque, y compris les virements, la planification, les paiements, etc. Lorsqu’un sinistre se produit, la base de données est récupérée en temps réel. La différence entre la base de données au moment du sinistre et la récupération de la base de données après un sinistre est nulle dans ce cas.
Pour certaines entreprises, il est acceptable de prendre environ 24 heures pour récupérer toutes les informations de la sauvegarde, mais cela peut parfois être catastrophique. Il est essentiel de configurer votre infrastructure en fonction des exigences RPO. Cela comprend l’amélioration de la fréquence des sauvegardes, l’ajout d’une base de données de secours dans votre architecture, etc.
Basculement
Pensez à une situation où vous voyagez sur une longue distance. Soudain, vous avez un pneu crevé pour une raison inattendue. Vous remerciez la roue de secours disponible dans votre véhicule et les outils pour changer la roue défectueuse.
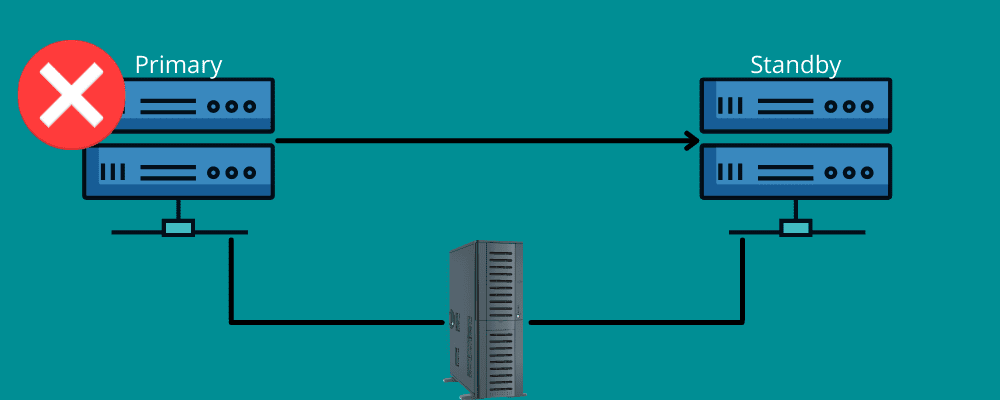
Le basculement fonctionne de la même manière.
Cela signifie que vous avez besoin d’une connexion de secours pendant la catastrophe. En un mot, le basculement signifie avoir des réseaux et des systèmes que vous pouvez utiliser au moment d’un sinistre pour transférer vos informations vers le système de récupération.
Le basculement garantit le bon fonctionnement de tous vos services, même en cas de défaillance de l’infrastructure ou du matériel. De cette façon, vous pouvez empêcher votre organisation de perdre des données et des revenus et éviter les interruptions de service pour vos utilisateurs finaux.
Vous pouvez soit le configurer manuellement, soit lui permettre de fonctionner automatiquement pour déplacer les données vers le serveur de secours.
Rétablissement
La restauration informatique est une opération simple où la production d’origine retourne à son emplacement d’origine (système) après la gestion d’un sinistre. Pendant l’attaque, les entreprises suivent une opération de basculement grâce à laquelle toutes les charges de travail sont transférées vers une réplique de machine virtuelle ou un système de sauvegarde.
Cependant, vous ne pouvez pas simplement sauter la prochaine étape du retour. Lorsque vous récupérez tout et reprenez l’action, vous devez transférer toutes les charges de travail vers leurs machines virtuelles ou systèmes d’origine. Ce processus global de retour des charges de travail vers le lieu de travail ou le système d’origine est appelé restauration automatique. Cela signifie que vous revenez « de retour » après l’attaque.
La restauration est également utilisée pour la maintenance planifiée d’une entreprise. Il est vrai que la restauration se produit toujours après le basculement. En d’autres termes, le basculement est la première étape et la restauration est la deuxième étape de la récupération des données essentielles. Il peut être configuré de cloud à cloud, sur site à sur site, sur site à cloud, ou toute combinaison de ceux-ci.
RD
La reprise après sinistre (DR) est le processus dans lequel vous avez des plans prédéfinis pour récupérer vos actifs dans les délais.
DR donne la possibilité à une organisation de réagir rapidement et de récupérer chaque service à la suite d’un événement inattendu. Il fournit également une documentation formelle contenant des instructions sur la prise de mesures immédiates en cas d’incidents imprévus.
PCA
Le plan de continuité des activités (BCP) est l’un des plans de reprise après sinistre les plus acceptables qui permet à l’infrastructure informatique d’élaborer des stratégies afin de gérer les interruptions informatiques des serveurs, des appareils mobiles, des ordinateurs personnels et des réseaux.
Le BCP est légèrement différent de la reprise après sinistre car il aide une organisation à planifier le rétablissement des logiciels d’entreprise et de la productivité pour répondre aux principaux besoins de l’entreprise.
Ici, une entreprise crée un système de récupération pour surmonter les menaces potentielles, telles que les cyberattaques ou les catastrophes naturelles. Il est conçu pour sécuriser les actifs et garantir que tous les services seront de nouveau opérationnels rapidement après la grève.
BCM

La gestion de la continuité des activités (BCM) est un processus de gestion des risques spécialement conçu pour agir comme un bouclier contre les menaces aux processus commerciaux. BCM est la prochaine étape de BCP, où il valide les plans de récupération pour s’assurer que tout le monde dans l’entreprise répond instantanément au plan et récupère tous les éléments essentiels.
BCM agit comme un cadre de gestion pour identifier les risques d’infrastructure lorsqu’il fait face à des menaces externes et/ou internes. Il garantit également que le cadre fonctionne efficacement à l’aide de tests réguliers pour améliorer la prévisibilité, réduire les risques et aligner le plan pour les attaques futures.
BIA
L’analyse d’impact sur l’entreprise (BIA) est le processus d’analyse du taux de survie d’une entreprise en identifiant les systèmes, les opérations et les processus cruciaux. Il raconte l’effet d’une catastrophe sur votre organisation en raison de l’interruption de vos opérations.
BIA prédit les conséquences avant qu’une attaque ne se produise réellement afin de collecter des informations clés qui peuvent aider à créer de puissantes stratégies de récupération. Il identifie également les coûts impliqués en raison des pannes, tels que le coût de remplacement de l’équipement, la perte de trésorerie, les bénéfices, les salaires, etc.
Lors de la création d’un rapport BIA, vous devez tenir compte des processus cruciaux impliqués dans votre entreprise, de l’impact des perturbations sur différentes zones, de la durée acceptable, des zones tolérables, des coûts financiers, etc.
Arbre d’appel
Un arbre d’appel est un processus de conservation d’une liste d’employés à appeler en cas d’urgence. C’est une procédure qui suit une structure arborescente.
Par exemple, lors d’une catastrophe, une personne contactera un petit groupe de membres avec un message urgent, ces membres du personnel appellent chaque groupe séparément. De cette façon, tout le personnel sera informé pendant la menace et commencera son travail assigné pour récupérer chaque fonction et processus à temps. Faire une liste est simple mais sa mise en œuvre en temps réel crée de la confusion.
Vous devez effectuer des activités d’appel régulières pour préparer chaque membre du personnel d’urgence à rester vigilant. Des tests réguliers peuvent également aider à identifier les numéros modifiés ou manquants qui peuvent avoir un impact important sur les performances.
Un arbre d’appel contient des informations à utiliser en cas d’urgence pour fournir des instructions. Cela peut également être fait manuellement, mais les gens utilisent l’automatisation pour accélérer le processus et informer les membres dans le monde numérique d’aujourd’hui.
Centre de commandement/Centre de contrôle
Il s’agit d’une installation virtuelle ou physique spécialement préparée pour assurer le commandement ou le contrôle des plans de reprise en cas de crise. Il communique avec l’équipe pour gérer les systèmes et les fonctions pendant la catastrophe.
Traditionnellement, l’infrastructure dépend du centre de commandement qui traite les crises sans aucune approche appropriée. De nos jours, les organisations ont parfaitement conçu leur centre de contrôle, ce qui transforme la réponse immédiate en compétence de base.
Une fois qu’il détecte une catastrophe, le centre de commandement se dirige rapidement vers la phase de récupération. De plus, il sert de point de signalement dans le cas des services, de la presse, des livraisons, etc. Il rassemble également des personnes de plusieurs disciplines lors de tels scénarios.
Réponse aux incidents

La réponse à incident est un type de réponse donnée pour faire face à une attaque. Cela se fait avec l’aide des procédures et du personnel appropriés pour préserver efficacement la sécurité du réseau et des données au bon moment.
Si une organisation dispose d’un plan d’incident avant l’événement inattendu, elle peut sécuriser ses données contre les menaces en temps réel. Les spécialistes de la réponse aux incidents restent toujours attentifs aux problèmes et agissent naturellement lors d’un incident. Ils prennent certaines mesures pour éviter les failles de sécurité, en veillant à ne pas sauter une seule étape lors de la reprise après sinistre.
Au début, vous devez déterminer les données critiques et les stocker dans le cloud ou dans un emplacement distant pour garantir la sécurité. Répondez aux besoins actuels en matière d’infrastructure et à l’évolution des cybermenaces en mettant régulièrement à jour les plans de réponse aux incidents.
Sauvegarde
Les solutions de sauvegarde aident une infrastructure informatique à conserver des copies des données et à les stocker en toute sécurité au bon moment. Si vous êtes confronté à la corruption de la base de données, à la suppression accidentelle de toutes les données ou à tout autre problème, vous devez être prêt avec la sauvegarde pour restaurer les données instantanément et continuer avec les services.

Il s’agit de répliquer les fichiers et de les stocker dans un emplacement sécurisé pour accéder facilement à toutes les données après un événement inhabituel. Cela vous aidera si vous sauvegardez vos données à plusieurs endroits pour vous assurer de pouvoir les restaurer même en cas de défaillance d’un site.
Résilience
La capacité des communautés, des États, des organisations et des individus à résister à une catastrophe sans compromettre les services et les systèmes est connue sous le nom de résilience aux catastrophes.
Une organisation doit être prête à retenir une grande quantité de stress en raison des dangers. Assurez-vous d’avoir les capacités de minimiser vos pertes avec une meilleure planification au lieu d’attendre que quelqu’un vienne vous secourir. Cela vous aidera à faire face aux sinistres et à récupérer efficacement votre infrastructure informatique.
Ici, l’objectif principal est de préserver et de restaurer les fonctions et structures essentielles au bon moment chaque fois que nécessaire. Pour devenir une organisation résiliente aux catastrophes, vous devez vous préparer à l’avance et avoir la capacité d’anticiper les risques, de vous adapter aux changements, de partager et d’apprendre, d’intégrer divers secteurs et de gérer les niveaux de risque.
SLA

L’accord de niveau de service (SLA) est un plan d’urgence dans lequel vous mentionnez aux utilisateurs finaux le temps que vous pouvez prendre pour rétablir les services en cas d’urgence.
SLA garantit aux clients que leurs données sont en sécurité et non compromises ou partagées avec des tiers. C’est le point de contact unique pour les problèmes des utilisateurs finaux.
Chaque infrastructure informatique donne à ses clients l’assurance d’un SLA. Assurez-vous donc de communiquer au préalable avec vos utilisateurs finaux.
SPOF
Un point de défaillance unique (SPOF) est un équipement, un individu, une ressource ou une application auquel de nombreux autres systèmes ou applications sont connectés.
Si un tel équipement ou ressource tombe en panne, toutes les pièces essentielles connectées au système tombent en panne avec lui. Ainsi, l’ensemble du processus et du fonctionnement de l’entreprise sera affecté.
Par conséquent, vous devez avoir une stratégie pour gérer un tel problème afin que votre organisation continue de fonctionner. La toute première chose que vous pouvez faire est d’identifier l’équipement ou le système qui peut avoir un impact plus important. Ensuite, exécutez une analyse d’impact sur l’entreprise et obtenez un score d’évaluation des risques pour être au courant des scènes qui vont se produire. Creusez et trouvez-les avant l’événement.
Une fois que vous avez répertorié tous les SPOF, classez-les en fonction du processus de récupération. Mettez chacun des SPOF dans trois catégories différentes :
- Récupérez facilement et directement avec moins de temps et de budget.
- La récupération serait difficile, mais un processus fiable pourrait être développé pour restaurer.
- Rien ne peut être fait pour récupérer une fois qu’il tombe en panne.
Vous pouvez agir en conséquence en fonction de la catégorie.
Récupération du système
Lors d’une défaillance matérielle, vous devez exécuter un processus de récupération pour récupérer le système ou le serveur particulier dans sa forme d’origine. Et pour récupérer l’intégralité du système, vous devez être prêt avec les exigences de récupération, les sauvegardes, la compatibilité du micrologiciel et la compatibilité matérielle.
La récupération du système est un processus qui réinitialise la machine dans ses paramètres précédents ou dans le même état qu’elle était lorsqu’elle était neuve. Cela effacera toutes les infections virales dues aux logiciels ou applications installés sur votre système.
Ce processus comprend la planification de la reprise d’une infrastructure informatique qui définit et suit certaines procédures pour garantir la disponibilité des données contre les perturbations d’origine humaine ou naturelle.
Restauration du système
La restauration du système est un outil de récupération qui vous permet de restaurer certains fichiers et informations à leur état précédent au bon moment.
Avec la restauration du système, vous pouvez récupérer les clés de registre, les programmes installés, les pilotes, les fichiers système, etc., à leur version précédente. Cela agit comme une bouée de sauvetage dans de nombreuses catastrophes.
Plan de test
Il fait référence à un document qui stocke des informations sur une stratégie de test, des estimations, des ressources, des délais, des objectifs et des calendriers. Il fonctionne comme un modèle qui exécute des tests pour garantir la sécurité du matériel et des logiciels.
Celui-ci comprend différents tests selon les procédures et les étapes prévues pour gérer les séquelles du sinistre. Effectuez les tests réguliers afin de vous préparer, vous et votre organisation, à ne pas sauter une seule étape au cours de l’action. De cette façon, une infrastructure informatique peut comprendre les lacunes et être prête pour le combat.
Conclusion
Personne ne sait quand une catastrophe se produira. Par conséquent, des mesures de sûreté et de sécurité appropriées sont essentielles pour chaque entreprise.
Les terminologies de reprise après sinistre vous aideront à comprendre comment réagir aux attaques et aux catastrophes. Cela vous aidera également à vous préparer à l’avance afin de pouvoir protéger votre infrastructure lors d’un événement inattendu. Vous serez en mesure de créer une stratégie de reprise après sinistre efficace et en temps réel pour économiser des millions de dollars et retenir la confiance des clients.