Comparaison des principales plateformes de messagerie
Apache Kafka et RabbitMQ sont deux outils de courtage de messages très répandus, facilitant la communication découplée entre applications. Mais quelles sont leurs spécificités et comment se distinguent-ils ? Examinons cela de plus près.
RabbitMQ
RabbitMQ est une solution open source de courtage de messages conçue pour les échanges de données entre applications. Son développement en Erlang lui confère légèreté et efficacité. Erlang, créé par Ericsson, est particulièrement adapté aux systèmes distribués.
Considéré comme un courtier de messagerie plus traditionnel, RabbitMQ repose sur un modèle éditeur-abonné, tout en pouvant gérer des communications synchrones ou asynchrones selon la configuration. Il assure l'acheminement et la gestion des messages entre producteurs et consommateurs.
Il prend en charge les protocoles AMQP, STOMP, MQTT, HTTP et WebSocket, et propose trois schémas d'échange : par sujet, diffusion et direct :
- Échange direct et ciblé par sujet ou thème [topic]
- Distribution du message à tous les consommateurs connectés à la file d'attente [fanout]
- Remise d'un message unique à chaque consommateur [direct]
Voici les principaux éléments constitutifs de RabbitMQ :
Producteurs
Les producteurs sont des applications qui génèrent et envoient des messages à RabbitMQ. Toute application capable de se connecter à RabbitMQ et de publier des messages peut jouer ce rôle.
Consommateurs
Les consommateurs sont des applications qui reçoivent et traitent les messages provenant de RabbitMQ. Tout système capable de se connecter à RabbitMQ et de s'abonner aux messages est un consommateur.
Échanges
Les échanges reçoivent les messages des producteurs et les acheminent vers les files d'attente appropriées. Il existe différents types d'échanges (directs, diffusion, par sujet et par en-têtes), chacun ayant ses propres règles de routage.
Files d'attente
Les files d'attente sont des espaces de stockage temporaire où les messages sont conservés jusqu'à leur consommation par les consommateurs. Elles peuvent être créées par les applications ou automatiquement par RabbitMQ lors de la publication d'un message.
Liaisons
Les liaisons définissent les relations entre les échanges et les files d'attente. Elles déterminent les règles de routage des messages utilisées par les échanges pour les diriger vers les bonnes files d'attente.
Architecture de RabbitMQ
RabbitMQ fonctionne selon un modèle de livraison de messages de type "pull". Les consommateurs sollicitent activement les messages auprès du courtier. Les messages sont d'abord envoyés aux échanges, qui les répartissent ensuite vers les files d'attente en fonction de clés de routage.
L'architecture de RabbitMQ, basée sur un modèle client-serveur, se compose de plusieurs éléments qui coopèrent pour offrir une plateforme de messagerie fiable et modulable. Le protocole AMQP définit les composants tels que les échanges, les files d'attente, les liaisons, ainsi que les éditeurs et abonnés. Les éditeurs publient les messages dans les échanges.
Les échanges reçoivent ces messages et les distribuent à un nombre variable de files d'attente, en respectant des règles (liaisons). Les messages conservés dans les files d'attente sont ensuite récupérés par les consommateurs. Un résumé simplifié du fonctionnement de RabbitMQ est le suivant :
Source de l'image : VMware
- Les éditeurs envoient des messages aux échanges.
- Les échanges distribuent les messages aux files d'attente et potentiellement à d'autres échanges.
- À la réception d'un message, RabbitMQ confirme la réception aux expéditeurs.
- Les consommateurs maintiennent des connexions TCP avec RabbitMQ et indiquent les files d'attente depuis lesquelles ils reçoivent des messages.
- RabbitMQ achemine les messages vers les consommateurs.
- Les consommateurs confirment la bonne réception du message ou signalent une erreur.
- En cas de réception réussie, le message est supprimé de la file d'attente.
Apache Kafka
Apache Kafka est une plateforme de messagerie distribuée open source, conçue par LinkedIn en Scala. Elle offre un modèle de publication/abonnement performant et évolutif pour le traitement et le stockage des messages.

Les messages sont stockés et répartis entre les nœuds à l'aide de partitions. Kafka combine les modèles d'éditeur-abonné et de file d'attente, et garantit l'ordre des messages pour chaque consommateur.
Kafka est optimisé pour un haut débit de données et une faible latence, ce qui est idéal pour la gestion de flux de données en temps réel. Cela est rendu possible en limitant la logique côté serveur (courtier) et grâce à des optimisations spécifiques.
Par exemple, Kafka n'utilise pas de RAM et écrit directement les données sur le système de fichiers du serveur. L'écriture séquentielle permet des performances de lecture-écriture comparables à celles de la RAM.
Voici les principaux concepts qui rendent Kafka évolutif, performant et résilient :
Sujet
Un sujet est une manière de catégoriser les messages. On peut l'imaginer comme un placard avec des tiroirs, chaque tiroir représentant un sujet. Le placard serait la plateforme Apache Kafka. En plus de la catégorisation, un sujet peut être comparé à une table dans une base de données relationnelle.
Producteur
Un producteur se connecte à la plateforme de messagerie et envoie un ou plusieurs messages dans un sujet spécifique.
Consommateur
Un consommateur se connecte à la plateforme de messagerie et récupère un ou plusieurs messages depuis un sujet spécifique.
Courtier
Le courtier est l'instance de Kafka elle-même, responsable de la gestion des sujets et du stockage des messages, des journaux, etc.
Grappe (Cluster)
Le cluster est un ensemble de courtiers qui communiquent pour améliorer l'évolutivité et la tolérance aux pannes.
Fichier journal
Chaque sujet stocke ses enregistrements dans un journal structuré et séquentiel. Le fichier journal contient les informations d'un sujet.
Partitions
Les partitions permettent de diviser les messages au sein d'un sujet, ce qui assure l'élasticité, la tolérance aux pannes et l'évolutivité d'Apache Kafka. Un sujet peut être divisé en plusieurs partitions stockées à différents endroits.
Architecture d'Apache Kafka
Kafka utilise un modèle de livraison de messages de type "push". Les messages sont activement envoyés aux consommateurs. Les messages sont publiés dans des sujets, qui sont divisés en partitions et réparties entre les courtiers du cluster.
Les consommateurs s'abonnent à un ou plusieurs sujets pour recevoir les messages dès leur publication.
Dans Kafka, chaque sujet est divisé en une ou plusieurs partitions. C'est dans ces partitions que les messages sont stockés.
Dans un cluster avec plusieurs courtiers, les partitions sont réparties uniformément, permettant ainsi de répartir la charge d'écriture et de lecture sur plusieurs courtiers. Kafka utilise ZooKeeper pour la synchronisation.
Kafka reçoit, stocke et distribue les enregistrements. Un enregistrement représente une donnée générée par un nœud du système, comme un événement ou une information. Il est envoyé au cluster et stocké dans une partition d'un sujet.
Chaque enregistrement possède un décalage séquentiel, que le consommateur peut contrôler. Cela permet de retraiter un sujet si nécessaire, en fonction du décalage.
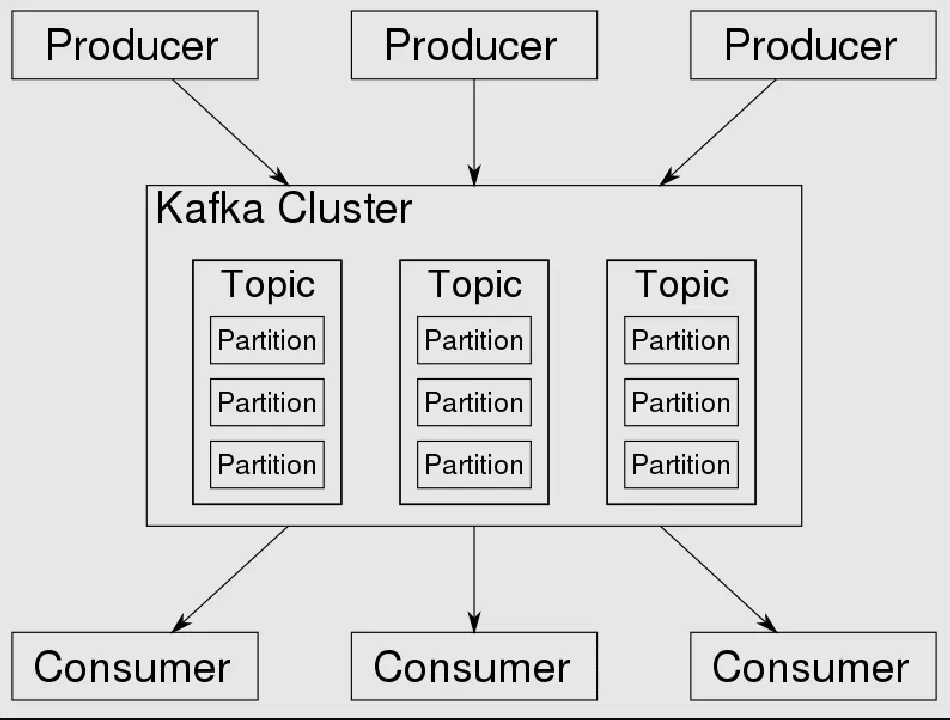 Source de l'image : Wikipédia
Source de l'image : Wikipédia
La logique, telle que la gestion du dernier identifiant de message lu par un consommateur ou la détermination de la partition pour les nouvelles données, est gérée par le client (producteur ou consommateur).
Outre les producteurs et les consommateurs, les concepts clés sont les sujets, les partitions et la réplication.
Un sujet décrit une catégorie de messages. Kafka assure la tolérance aux pannes en répliquant les données dans un sujet et améliore l'évolutivité en répartissant le sujet sur plusieurs serveurs.
RabbitMQ contre Kafka
Les principales différences entre Apache Kafka et RabbitMQ résident dans leurs modèles de livraison de messages.
Kafka fonctionne selon un principe de "pull" : les consommateurs récupèrent eux-mêmes les messages dont ils ont besoin depuis le sujet.
RabbitMQ, en revanche, implémente un modèle "push" en envoyant les messages aux destinataires. Voici les principales différences qui en découlent :
#1. Architecture
Une des différences majeures réside dans l'architecture. RabbitMQ utilise une architecture de file d'attente de messages traditionnelle basée sur un courtier, tandis que Kafka emploie une architecture de plateforme de streaming distribuée.
De plus, RabbitMQ utilise un modèle de livraison de messages "pull", tandis que Kafka utilise un modèle "push".
#2. Stockage des messages
RabbitMQ place le message dans une file d'attente FIFO (premier entré, premier sorti) et suit l'état de ce message dans la file d'attente. Kafka ajoute le message au journal (écrit sur le disque), laissant au récepteur le soin de récupérer les informations nécessaires du sujet.
RabbitMQ supprime le message une fois qu'il a été remis au destinataire, tandis que Kafka le conserve jusqu'à ce qu'il soit programmé de nettoyer le journal.
Kafka enregistre les états actuels et précédents du système et peut être utilisé comme source fiable de données historiques, contrairement à RabbitMQ.
#3. Équilibrage de charge
Le modèle de livraison "pull" de RabbitMQ réduit la latence. Cependant, les destinataires peuvent être submergés si les messages arrivent plus vite qu'ils ne peuvent les traiter.
Dans RabbitMQ, chaque récepteur demande et télécharge un nombre différent de messages, ce qui peut entraîner une répartition inégale du travail, des retards et une perte de l'ordre des messages.
Pour éviter cela, chaque récepteur RabbitMQ configure une limite de prélecture, limitant le nombre de messages accumulés sans accusé de réception. Dans Kafka, l'équilibrage de charge est automatisé en répartissant les destinataires entre les partitions du sujet.
#4. Routage
RabbitMQ offre quatre options de routage vers différents échanges pour la mise en file d'attente, permettant ainsi des modèles de messagerie puissants et flexibles. Kafka n'implémente qu'une seule manière d'écrire des messages sur le disque sans routage.
#5. Ordre des messages
RabbitMQ permet de maintenir un ordre relatif dans des ensembles d'événements, tandis qu'Apache Kafka fournit un moyen simple de maintenir l'ordre et l'évolutivité en écrivant les messages de manière séquentielle dans un journal répliqué (sujet).
| Fonctionnalité | RabbitMQ | Kafka |
| Enregistrement des messages | Messages stockés en mémoire et sur disque | Architecture de plateforme de diffusion distribuée |
| Modèle de livraison | Basé sur le "pull" | Basé sur le "push" |
| Stockage des messages | Impossible d'enregistrer les messages | Maintient l'ordre en écrivant dans un sujet |
| Équilibrage de charge | Configure une limite de prélecture | Effectué automatiquement par sujet |
| Processus externes | Ne nécessite pas | Nécessite l'exécution de l'instance Zookeeper |
| Plugins | Plusieurs plugins | Prise en charge limitée des plugins |
RabbitMQ et Kafka sont tous deux des systèmes de messagerie largement utilisés, chacun ayant ses propres avantages et cas d'utilisation. RabbitMQ est un système flexible, fiable et évolutif, idéal pour la mise en file d'attente de messages et les applications nécessitant une livraison de messages fiable.
Kafka est une plateforme de streaming distribuée, conçue pour le traitement en temps réel et à haut débit de gros volumes de données, ce qui en fait un excellent choix pour les applications nécessitant un traitement et une analyse de données en temps réel.
Principaux cas d'utilisation de RabbitMQ :
Commerce électronique

RabbitMQ est utilisé dans les applications de commerce électronique pour gérer le flux de données entre différents systèmes, tels que la gestion des stocks, le traitement des commandes et des paiements. Il gère de gros volumes de messages et assure une livraison fiable et ordonnée.
Santé
Dans le secteur de la santé, RabbitMQ sert à échanger des données entre différents systèmes, tels que les dossiers de santé électroniques (DSE), les dispositifs médicaux et les systèmes d'aide à la décision clinique. Il améliore les soins aux patients et réduit les erreurs en garantissant la disponibilité des bonnes informations au bon moment.
Services financiers
RabbitMQ facilite la messagerie en temps réel entre les systèmes, comme les plateformes de trading, la gestion des risques et les passerelles de paiement, garantissant des transactions rapides et sécurisées.
Systèmes IoT
RabbitMQ est utilisé dans les systèmes IoT pour gérer le flux de données entre les appareils et les capteurs. Il assure la transmission efficace et sécurisée des données, même dans des environnements à faible bande passante et connectivité intermittente.
Kafka est une plateforme de streaming distribuée, conçue pour gérer de gros volumes de données en temps réel.
Principaux cas d'utilisation de Kafka
Analyse en temps réel

Kafka est utilisé dans les applications d'analyse en temps réel pour traiter et analyser les données dès leur génération, permettant aux entreprises de prendre des décisions basées sur des informations à jour. Il gère de gros volumes de données et s'adapte aux besoins des applications les plus exigeantes.
Agrégation de journaux
Kafka permet d'agréger les journaux de différents systèmes et applications, facilitant la surveillance et la résolution de problèmes en temps réel. Il permet également de stocker les journaux pour des analyses et des rapports à long terme.
Apprentissage automatique
Kafka est utilisé pour diffuser des données vers des modèles d'apprentissage automatique en temps réel, permettant aux entreprises de faire des prédictions et d'agir sur la base d'informations à jour, améliorant ainsi la précision et l'efficacité des modèles.
Mon opinion sur RabbitMQ et Kafka
Les capacités étendues de RabbitMQ pour la gestion des files d'attente de messages se traduisent par une consommation accrue de ressources et une dégradation des performances sous des charges importantes. Cependant, dans la majorité des cas de systèmes complexes, Apache Kafka s'avère être l'outil le plus approprié.
Par exemple, pour la collecte et l'agrégation d'événements provenant de plusieurs systèmes, en tenant compte de la géo-localisation, des métriques clients, des fichiers journaux et des analyses, avec l'objectif d'augmenter les sources d'informations, je préférerais utiliser Kafka. Toutefois, si une messagerie rapide et simple est requise, RabbitMQ fera parfaitement l'affaire !
Vous pouvez également consulter des guides sur l'installation d'Apache Kafka sous Windows et Linux.