Comment utiliser Scikit-LLM pour l'analyse de texte avec de grands modèles linguistiques
Scikit-LLM est un module Python qui facilite l'intégration de modèles de langage étendus (LLM) dans l'environnement scikit-learn. Il simplifie les opérations d'analyse textuelle. Si vous êtes familier avec scikit-learn, l'utilisation de Scikit-LLM vous semblera intuitive.
Il est essentiel de souligner que Scikit-LLM n'a pas pour vocation de remplacer scikit-learn. Alors que scikit-learn est une bibliothèque d'apprentissage automatique polyvalente, Scikit-LLM se concentre spécifiquement sur les tâches d'analyse de texte.
Débuter avec Scikit-LLM
Pour commencer à utiliser Scikit-LLM, vous devez installer la bibliothèque et configurer votre clé API. Pour l'installation, ouvrez votre environnement de développement intégré (IDE) et créez un nouvel environnement virtuel. Ceci évitera des conflits potentiels entre les versions des bibliothèques. Ensuite, exécutez la commande suivante dans votre terminal.
pip install scikit-llm
Cette commande installera Scikit-LLM ainsi que toutes les dépendances nécessaires.
La configuration de votre clé API nécessite que vous en obteniez une auprès de votre fournisseur de LLM. Pour obtenir une clé API OpenAI, procédez comme suit :
Rendez-vous sur la page API d'OpenAI. Ensuite, cliquez sur votre profil, situé dans le coin supérieur droit de la fenêtre. Sélectionnez "Afficher les clés API". Vous serez alors dirigé vers la page de gestion des clés API.
Sur la page des clés API, cliquez sur le bouton "Créer une nouvelle clé secrète".
Donnez un nom à votre clé API, puis cliquez sur le bouton "Créer une clé secrète" pour la générer. Après la création, vous devez copier la clé et la sauvegarder dans un lieu sûr, car OpenAI ne la réaffichera pas. En cas de perte, il vous faudra en générer une nouvelle.
Maintenant que vous avez votre clé API, ouvrez votre IDE et importez la classe `SKLLMConfig` depuis la bibliothèque Scikit-LLM. Cette classe vous permet de paramétrer les options de configuration relatives à l'utilisation des grands modèles de langage.
from skllm.config import SKLLMConfig
Cette classe nécessite la définition de votre clé API OpenAI ainsi que les détails de votre organisation.
SKLLMConfig.set_openai_key("Votre clé API")
SKLLMConfig.set_openai_org("Votre ID d'organisation")
L'ID d'organisation et le nom de l'organisation sont distincts. L'ID d'organisation est un identifiant unique de votre organisation. Pour obtenir votre ID d'organisation, rendez-vous sur la page des paramètres de l'organisation OpenAI et copiez-le. Vous avez maintenant établi une connexion entre Scikit-LLM et le grand modèle de langage.
Scikit-LLM exige un forfait de paiement à l'usage. En effet, le compte d'essai gratuit d'OpenAI est limité à trois requêtes par minute, ce qui est insuffisant pour Scikit-LLM.
Toute tentative d'utilisation du compte d'essai gratuit entraînera une erreur similaire à celle ci-dessous lors de l'analyse textuelle.

Pour plus d'informations sur les limites de débit, consultez la page sur les limites de débit d'OpenAI.
OpenAI n'est pas le seul fournisseur de LLM utilisable. Vous pouvez également utiliser d'autres fournisseurs de LLM.
Importer les bibliothèques nécessaires et charger l'ensemble de données
Importez la bibliothèque pandas, qui servira au chargement de l'ensemble de données. Ensuite, importez les classes nécessaires depuis Scikit-LLM et scikit-learn.
import pandas as pd
from skllm import ZeroShotGPTClassifier, MultiLabelZeroShotGPTClassifier
from skllm.preprocessing import GPTSummarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.preprocessing import MultiLabelBinarizer
Ensuite, chargez l'ensemble de données sur lequel vous souhaitez effectuer une analyse textuelle. Cet exemple utilise l'ensemble de données des films IMDB. Vous pouvez, cependant, l'adapter pour utiliser votre propre ensemble de données.
data = pd.read_csv("imdb_movies_dataset.csv")
data = data.head(100)
L'utilisation des 100 premières lignes de l'ensemble de données n'est pas obligatoire. Vous pouvez utiliser l'intégralité de votre ensemble de données.
Ensuite, extrayez les colonnes de caractéristiques et d'étiquettes. Puis, divisez l'ensemble de données en ensembles d'apprentissage et de test.
X = data['Description']y = data['Genre']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
La colonne "Genre" contient les étiquettes que vous souhaitez prédire.
Classification de texte Zero-Shot avec Scikit-LLM
La classification de texte Zero-shot est une fonctionnalité des grands modèles de langage. Elle permet de classer le texte dans des catégories prédéfinies sans nécessiter d'apprentissage explicite sur des données étiquetées. Cette fonctionnalité est particulièrement utile pour les tâches où vous devez classer du texte dans des catégories qui n'étaient pas prévues lors de l'entraînement du modèle.
Pour effectuer une classification de texte Zero-shot avec Scikit-LLM, utilisez la classe `ZeroShotGPTClassifier`.
zero_shot_clf = ZeroShotGPTClassifier(openai_model="gpt-3.5-turbo")
zero_shot_clf.fit(X_train, y_train)
zero_shot_predictions = zero_shot_clf.predict(X_test)
print("Rapport de classification de texte Zero-Shot:")
print(classification_report(y_test, zero_shot_predictions))
Voici le résultat obtenu :
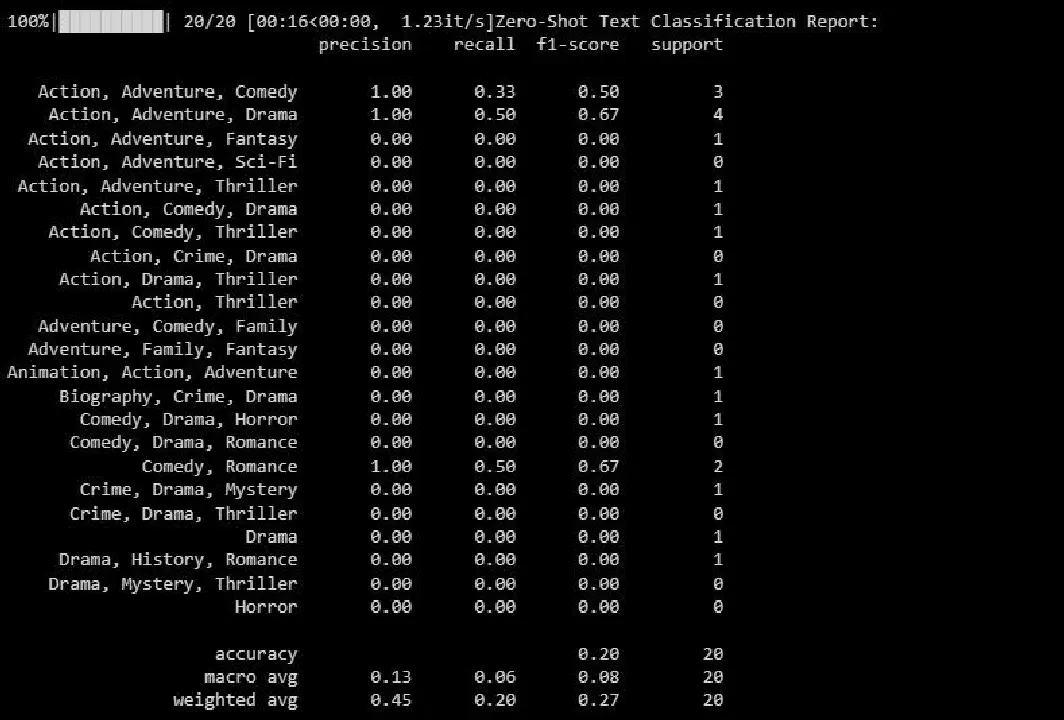
Le rapport de classification fournit des métriques pour chaque étiquette que le modèle tente de prédire.
Classification de texte multi-étiquettes Zero-Shot avec Scikit-LLM
Dans certaines situations, un même texte peut appartenir à plusieurs catégories simultanément. Les modèles de classification traditionnels peinent à gérer cela. Scikit-LLM, en revanche, rend cette classification possible. La classification de texte multi-étiquettes Zero-shot est essentielle pour attribuer plusieurs étiquettes descriptives à un seul échantillon de texte.
Utilisez `MultiLabelZeroShotGPTClassifier` pour prédire quelles étiquettes sont appropriées pour chaque échantillon de texte.
candidate_labels = ["Action", "Comedy", "Drama", "Horror", "Sci-Fi"]
multi_label_zero_shot_clf = MultiLabelZeroShotGPTClassifier(max_labels=2)
multi_label_zero_shot_clf.fit(X_train, candidate_labels)
multi_label_zero_shot_predictions = multi_label_zero_shot_clf.predict(X_test)
mlb = MultiLabelBinarizer()
y_test_binary = mlb.fit_transform(y_test)
multi_label_zero_shot_predictions_binary = mlb.transform(multi_label_zero_shot_predictions)
print("Rapport de classification de texte multi-étiquettes Zero-Shot:")
print(classification_report(y_test_binary, multi_label_zero_shot_predictions_binary))
Dans le code ci-dessus, vous définissez les étiquettes candidates auxquelles votre texte peut appartenir.
Le résultat est le suivant :
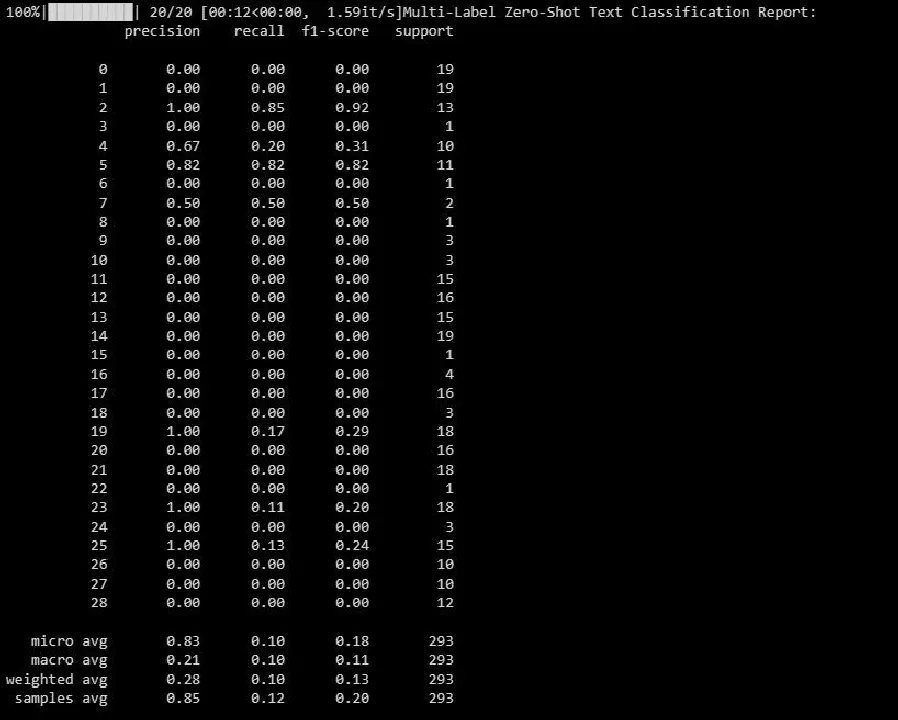
Ce rapport vous aide à évaluer les performances de votre modèle pour chaque étiquette dans la classification multi-étiquettes.
Vectorisation de texte avec Scikit-LLM
La vectorisation de texte consiste à convertir des données textuelles en un format numérique que les modèles d'apprentissage automatique peuvent comprendre. Scikit-LLM propose le `GPTVectorizer` pour cela. Il permet de transformer du texte en vecteurs de dimension fixe en utilisant des modèles GPT.
Vous pouvez obtenir cela en utilisant la fréquence des termes et la fréquence inverse des documents (TF-IDF).
tfidf_vectorizer = TfidfVectorizer(max_features=1000)
X_train_tfidf = tfidf_vectorizer.fit_transform(X_train)
X_test_tfidf = tfidf_vectorizer.transform(X_test)
print("Fonctionnalités vectorisées TF-IDF (5 premiers échantillons):")
print(X_train_tfidf[:5])
Voici le résultat :
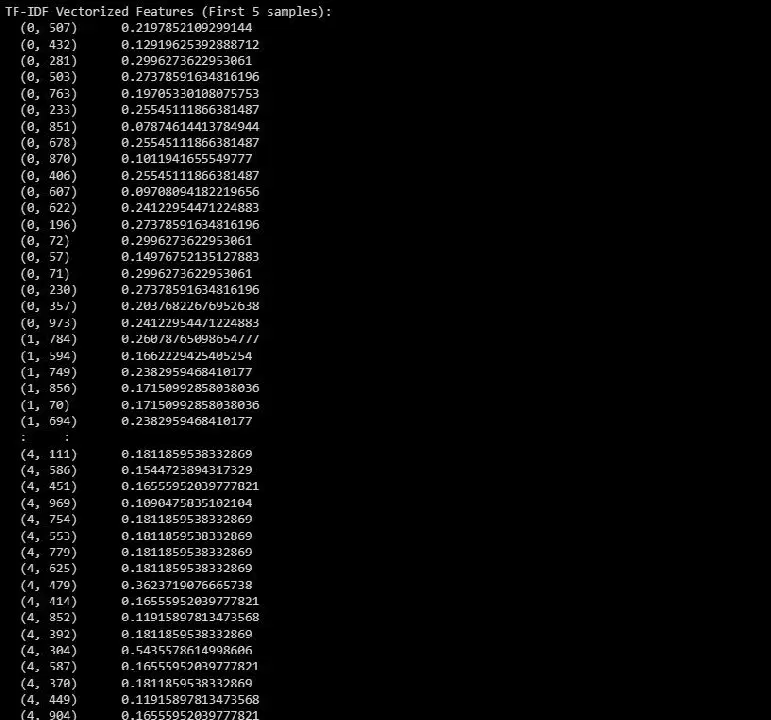
La sortie représente les caractéristiques vectorisées TF-IDF pour les 5 premiers échantillons de l'ensemble de données.
Résumé de texte avec Scikit-LLM
Le résumé de texte permet de condenser un texte tout en préservant les informations essentielles. Scikit-LLM propose le `GPTSummarizer`, qui utilise les modèles GPT pour générer des résumés concis de texte.
summarizer = GPTSummarizer(openai_model="gpt-3.5-turbo", max_words=15)
summaries = summarizer.fit_transform(X_test)
print(summaries)
Le résultat est le suivant :
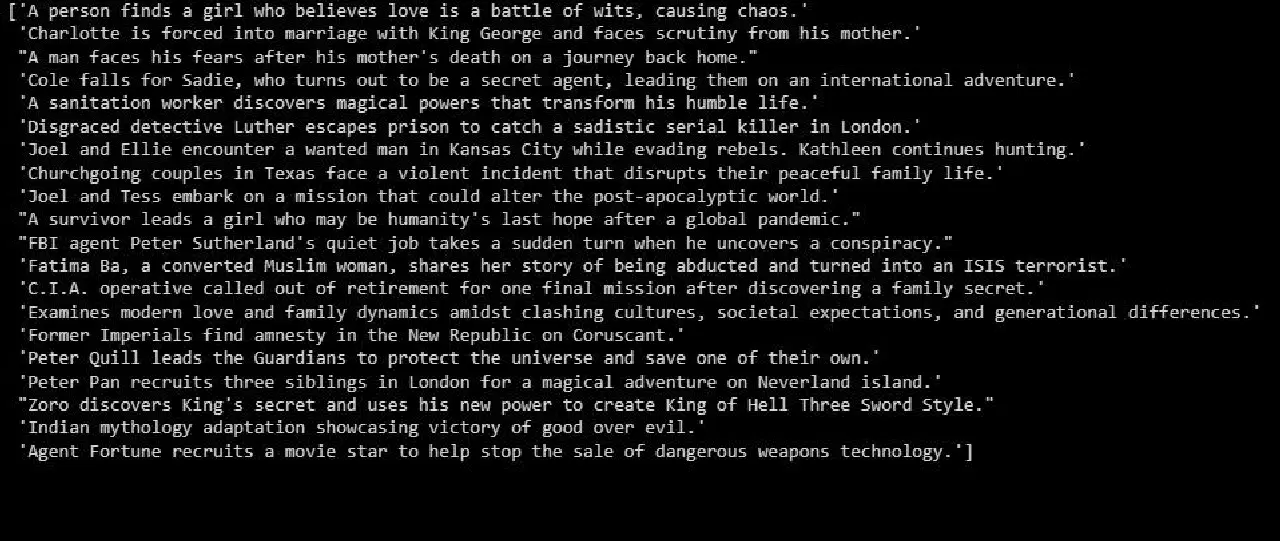
Ceci est un résumé des données de test.
Créer des applications avec des LLM
Scikit-LLM offre un large éventail de possibilités pour l'analyse de texte avec des grands modèles de langage. Il est essentiel de comprendre la technologie derrière les grands modèles de langage. Cette compréhension vous aidera à évaluer leurs forces et leurs faiblesses, ce qui peut vous aider à créer des applications efficaces basées sur cette technologie de pointe.