Comment utiliser la commande stat sous Linux
La commande `stat` sous Linux offre une profondeur d'information bien supérieure à la simple commande `ls`. Cet outil, à la fois informatif et adaptable, permet d'explorer les détails cachés de votre système de fichiers. Découvrons ensemble comment l'utiliser efficacement.
`stat`, une exploration approfondie
La commande `ls` est parfaite pour ce qu'elle fait – et elle en fait beaucoup – mais Linux offre toujours la possibilité d'aller plus loin, d'examiner ce qui se cache sous la surface. Il ne s'agit pas seulement de soulever un coin du tapis, mais de démonter le plancher, voire de creuser un peu plus profond. On peut véritablement disséquer Linux comme un oignon.
`ls` révèle des informations importantes sur un fichier, telles que ses permissions, sa taille et sa nature (fichier ou lien symbolique). Ces informations sont extraites d'une structure du système de fichiers appelée inode.
Chaque fichier et répertoire possède un inode. L'inode contient des métadonnées sur le fichier, comme les blocs de système de fichiers qu'il occupe et ses horodatages. L'inode est en quelque sorte la carte d'identité d'un fichier. Mais `ls` n'affiche qu'un aperçu. Pour tout voir, c'est la commande `stat` qu'il faut utiliser.
Comme `ls`, `stat` offre de nombreuses options. Cela la rend idéale pour l'utilisation d'alias. Une fois que vous avez déterminé l'ensemble d'options qui produit l'affichage désiré, vous pouvez l'encapsuler dans un alias ou une fonction shell. Cela simplifie son utilisation et évite d'avoir à mémoriser une longue liste d'options.
Comparaison rapide
Utilisons `ls` pour obtenir une liste détaillée (option `-l`) avec des tailles de fichiers lisibles par l'humain (option `-h`):
ls -lh ana.h
Les informations fournies par `ls` sont, de gauche à droite:
Le premier caractère, un tiret "-", indique qu'il s'agit d'un fichier normal et non d'un socket, d'un lien symbolique ou autre.
Les permissions pour le propriétaire, le groupe et les autres utilisateurs sont listées en format octal.
Le nombre de liens physiques pointant vers ce fichier, généralement un.
Le propriétaire du fichier (ici, "Dave").
Le groupe propriétaire du fichier (ici, également "Dave").
La taille du fichier (802 octets dans ce cas).
La date et l'heure de la dernière modification du fichier (ici, vendredi 13 décembre 2015).
Le nom du fichier (ana.c).
Maintenant, regardons ce que donne `stat` :
stat ana.h
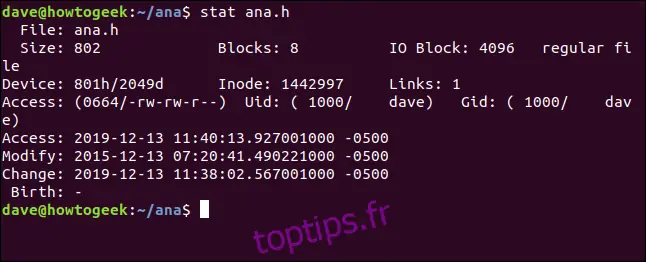
Voici les informations fournies par `stat` :
Fichier: Le nom du fichier. Il est généralement identique à celui que vous avez donné à `stat` sur la ligne de commande, mais peut différer si vous examinez un lien symbolique.
Taille: La taille du fichier, en octets.
Blocs: Le nombre de blocs du système de fichiers nécessaires pour stocker le fichier.
Bloc IO: La taille d'un bloc du système de fichiers.
Type de fichier: Le type d'objet décrit par les métadonnées. Les types courants sont fichiers et répertoires, mais peuvent également inclure liens, sockets, ou tubes nommés.
Périphérique: Le numéro de périphérique en hexadécimal et décimal. Il s'agit de l'ID du disque dur où le fichier est stocké.
Inode: Le numéro d'inode, l'identifiant unique de cet inode. L'ensemble numéro d'inode et numéro de périphérique identifie un fichier de façon unique.
Liens: Le nombre de liens physiques pointant vers le fichier. Chaque lien physique possède son propre inode. C'est une autre façon de voir combien d'inodes pointent vers ce fichier. Ce nombre augmente ou diminue lorsqu'un lien est créé ou supprimé. S'il atteint zéro, le fichier est supprimé et l'inode est libéré. Pour un répertoire, ce nombre représente le nombre de fichiers qu'il contient, y compris les entrées "." (répertoire actuel) et ".." (répertoire parent).
Accès: Les permissions du fichier, affichées en format octal (rwx) et en format traditionnel (lecture, écriture, exécution).
Uid: L'identifiant utilisateur et le nom du compte du propriétaire.
Gid: L'identifiant du groupe et le nom du groupe du propriétaire.
Accès: L'horodatage de l'accès. Ce n'est pas aussi simple qu'il n'y parait. Les distributions Linux modernes utilisent un schéma appelé `relatime`, qui optimise les accès au disque nécessaires pour mettre à jour l'horodatage d'accès. En résumé, l'heure d'accès est mise à jour si elle est antérieure à l'heure de modification.
Modification: L'horodatage de la dernière modification du contenu du fichier. (Dans ce cas, le contenu de ce fichier a été modifié il y a exactement quatre ans).
Changement: L'horodatage du dernier changement. Il correspond à la dernière modification des attributs ou du contenu du fichier. Si vous modifiez un fichier en changeant ses permissions, l'horodatage de changement sera mis à jour (les attributs du fichier ont changé), mais pas l'horodatage de modification (le contenu du fichier n'a pas été modifié).
Naissance: Champ réservé à la date de création originale du fichier, mais qui n'est pas implémenté sous Linux.
Comprendre les horodatages
Les horodatages sont sensibles au fuseau horaire. La partie "-0500" à la fin de chaque ligne indique que le fichier a été créé sur un ordinateur situé dans un fuseau horaire Temps Universel Coordonné (UTC) qui est en retard de cinq heures par rapport à celui de l'ordinateur actuel. Ainsi, l'ordinateur qui a créé ce fichier a cinq heures d'avance sur l'ordinateur où nous l'examinons. Le fichier a été créé sur un ordinateur au fuseau horaire britannique, et nous l'examinons ici sur un ordinateur situé dans le fuseau horaire de l'est des États-Unis.
Les horodatages de modification et de changement peuvent prêter à confusion car, pour un non-initié, leur nom pourrait suggérer la même chose.
Utilisons `chmod` pour modifier les permissions d'un fichier nommé `ana.c`. Nous allons le rendre accessible en écriture à tous. Ceci n'affectera pas le contenu du fichier, mais ses attributs.
chmod +w ana.c
Maintenant, utilisons `stat` pour examiner les horodatages :
stat ana.c
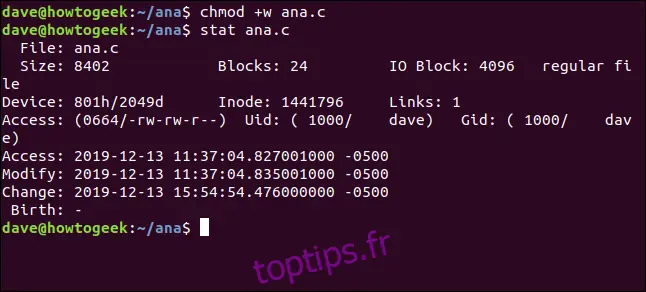
L'horodatage de changement a été mis à jour, mais pas celui de modification.
L'horodatage de modification n'est mis à jour que si le contenu du fichier change. L'horodatage de changement est mis à jour à la fois pour les modifications de contenu et les modifications d'attributs.
`stat` avec plusieurs fichiers
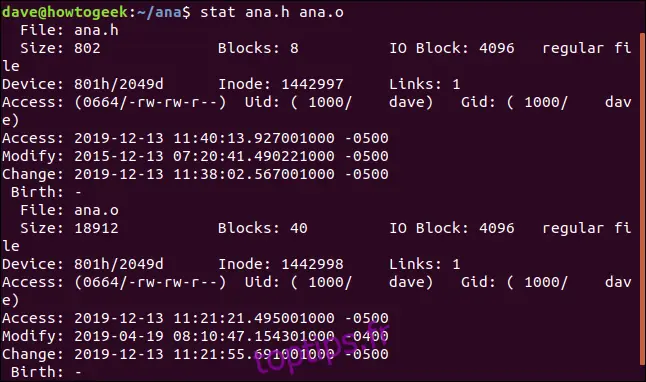
Pour obtenir des statistiques sur plusieurs fichiers en une seule fois, il suffit de transmettre leurs noms à `stat` sur la ligne de commande :
stat ana.h ana.o
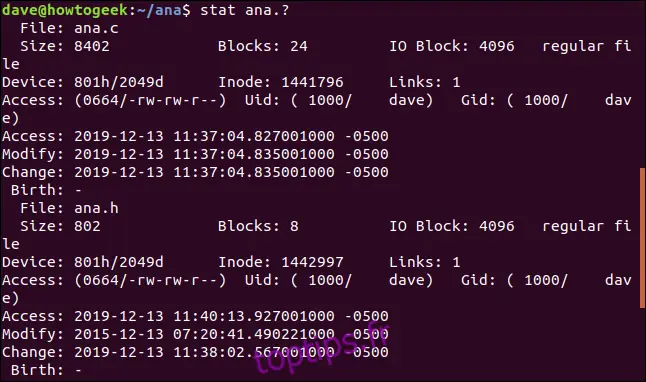
Pour utiliser `stat` avec un ensemble de fichiers, vous pouvez utiliser des caractères génériques. Le point d'interrogation "?" représente n'importe quel caractère unique, et l'astérisque "*" représente n'importe quelle chaîne de caractères. Par exemple, pour demander à `stat` de fournir des informations sur tous les fichiers appelés "ana" suivi d'une seule extension, vous pouvez utiliser cette commande :
stat ana.?
`stat` pour les systèmes de fichiers
`stat` peut aussi fournir des informations sur l'état des systèmes de fichiers, en plus de celles sur les fichiers. L'option `-f` (système de fichiers) indique à `stat` de rapporter les informations du système de fichiers où réside le fichier. Vous pouvez également passer un répertoire, tel que "/", à `stat` à la place d'un nom de fichier.
stat -f ana.c
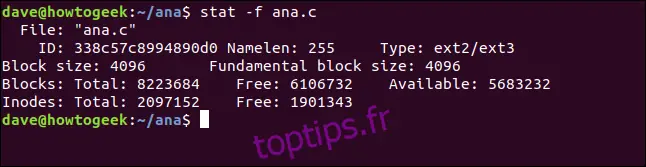
Les informations fournies sont :
Fichier: Le nom du fichier.
ID: L'identifiant du système de fichiers en notation hexadécimale.
Namelen: La longueur maximale autorisée pour les noms de fichiers.
Type: Le type de système de fichiers.
Taille de bloc: La quantité de données pour optimiser les requêtes de lecture.
Taille de bloc fondamentale: La taille d'un bloc dans le système de fichiers.
Blocs:
Total: Le nombre total de blocs du système de fichiers.
Free: Le nombre de blocs libres dans le système de fichiers.
Disponible: Le nombre de blocs disponibles pour les utilisateurs non-root.
Inodes:
Total: Le nombre total d'inodes dans le système de fichiers.
Free: Le nombre d'inodes libres dans le système de fichiers.
Déréférencement des liens symboliques
Si vous utilisez `stat` sur un fichier qui est en fait un lien symbolique, il donnera les informations du lien lui-même. Pour obtenir les informations du fichier vers lequel pointe le lien, utilisez l'option `-L` (déréférencement). Le fichier `code.c` est un lien symbolique pointant vers `ana.c`. Regardons ce qui se passe sans l'option `-L` :
stat code.c
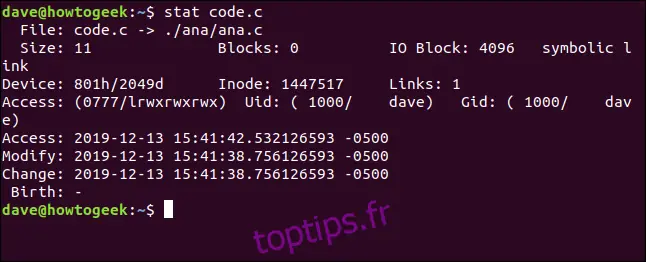
Le nom du fichier montre que `code.c` pointe vers (->) `ana.c`. La taille du fichier n'est que de 11 octets. Il n'y a pas de blocs réservés pour stocker ce lien. Le type de fichier est indiqué comme étant un lien symbolique.
Clairement, nous n'avons pas ici les informations du fichier cible. Réessayons en ajoutant l'option `-L` :
stat -L code.c
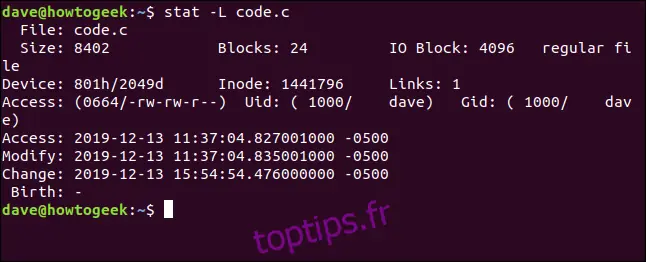
Cette fois, nous obtenons les détails du fichier vers lequel pointe le lien. Notez cependant que le nom de fichier est toujours indiqué comme `code.c`. Il s'agit du nom du lien, et non du fichier cible. C'est logique, car c'est le nom que nous avons donné à `stat` sur la ligne de commande.
Le rapport succinct
L'option `-t` (laconique) demande à `stat` de fournir un résumé condensé :
stat -t ana.c

Il n'y a aucune indication fournie. Pour comprendre sa signification – jusqu'à ce que vous ayez mémorisé la séquence des champs – vous devez comparer cette sortie avec une sortie complète de `stat`.
Formats de sortie personnalisés
Une meilleure façon d'obtenir un ensemble différent d'informations avec `stat` est d'utiliser un format personnalisé. Il existe une longue liste de jetons, appelés "séquences de format". Chacun de ces éléments représente une information. Sélectionnez ceux que vous souhaitez inclure dans la sortie et créez une chaîne de format. Lorsque vous appelez `stat` et lui donnez cette chaîne, la sortie n'inclura que les éléments de données que vous avez demandés.
Il existe différents ensembles de séquences de format pour les fichiers et les systèmes de fichiers. La liste pour les fichiers est :
%a: les droits d'accès en octal.
%A: les droits d'accès sous forme lisible par l'humain (rwx).
%b: le nombre de blocs alloués.
%B: la taille en octets de chaque bloc.
%d: le numéro de périphérique en décimal.
%D: le numéro de périphérique en hexadécimal.
%f: le mode brut en hexadécimal.
%F: le type de fichier.
%g: l'ID de groupe du propriétaire.
%G: le nom du groupe du propriétaire.
%h: le nombre de liens physiques.
%i: le numéro d'inode.
%m: le point de montage.
%n: le nom du fichier.
%N: le nom du fichier cité, avec un nom de fichier déréférencé s'il s'agit d'un lien symbolique.
%o: l'indice de taille de transfert d'E/S optimal.
%s: la taille totale, en octets.
%t: le type de périphérique majeur en hexadécimal, pour les fichiers spéciaux de périphérique caractère/bloc.
%T: le type de périphérique mineur en hexadécimal, pour les fichiers spéciaux de périphérique caractère/bloc.
%u: l'ID utilisateur du propriétaire.
%U: le nom d'utilisateur du propriétaire.
%w: l'heure de naissance du fichier, lisible par l'humain, ou un tiret "-" si inconnu.
%W: l'heure de naissance du fichier, en secondes depuis l'époque ; 0 si inconnu.
%x: l'heure du dernier accès, lisible par l'humain.
%X: l'heure du dernier accès, en secondes depuis l'époque.
%y: l'heure de la dernière modification des données, lisible par l'humain.
%Y: l'heure de la dernière modification des données, en secondes depuis l'époque.
%z: l'heure du dernier changement d'état, lisible par l'humain.
%Z: l'heure du dernier changement d'état, en secondes depuis l'époque.
L'"époque" est l'époque Unix, qui a eu lieu le 1970-01-01 00:00:00 +0000 (UTC).
Pour les systèmes de fichiers, les séquences de format sont :
%a: le nombre de blocs disponibles pour les utilisateurs réguliers (non root).
%b: le nombre total de blocs de données dans le système de fichiers.
%c: le total des inodes dans le système de fichiers.
%d: le nombre d'inodes libres dans le système de fichiers.
%f: le nombre de blocs libres dans le système de fichiers.
%i: l'ID du système de fichiers en hexadécimal.
%l: la longueur maximale des noms de fichiers.
%n: le nom du fichier.
%s: la taille du bloc (la taille d'écriture optimale).
%S: la taille des blocs du système de fichiers (pour le nombre de blocs).
%t: le type de système de fichiers en hexadécimal.
%T: le type de système de fichiers sous une forme lisible par l'humain.
Deux options permettent d'utiliser les chaînes de séquences de format : `--format` et `--printf`. La différence entre les deux est que `--printf` interprète les séquences d'échappement de style C telles que `\n` (nouvelle ligne) et `\t` (tabulation), et il n'ajoute pas automatiquement de caractère de nouvelle ligne à sa sortie.
Créons une chaîne de format et passons-la à `stat`. Les séquences de format utilisées sont `%n` pour le nom du fichier, `%s` pour la taille du fichier et `%F` pour le type de fichier. Nous allons ajouter la séquence d'échappement `\n` à la fin de la chaîne pour que chaque fichier soit traité sur une nouvelle ligne. Notre chaîne de format sera :
"File %n is %s bytes, and is a %F\n"
Nous allons passer cela à `stat` en utilisant l'option `--printf`. Nous allons demander à `stat` de rapporter un fichier nommé `code.c` et un ensemble de fichiers correspondant à `ana.?`. Voici la commande complète. Notez le signe égal "=" entre `--printf` et la chaîne de format :
stat --printf="File %n is %s bytes, and is a %F\n" code.c ana/ana.?
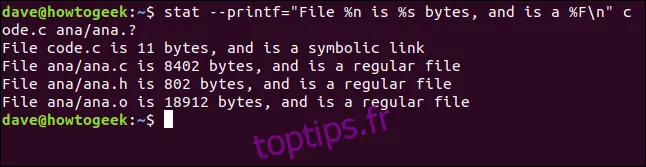
Le rapport de chaque fichier est listé sur une nouvelle ligne, comme nous l'avions demandé. Le nom du fichier, sa taille, et son type nous sont donnés.
Les formats personnalisés vous donnent accès à encore plus d'informations que la sortie standard de `stat`.
Un contrôle précis
Comme vous pouvez le voir, il existe de nombreuses façons d'extraire précisément les informations qui vous intéressent. Vous comprenez sans doute maintenant pourquoi nous vous recommandons d'utiliser des alias pour les commandes les plus longues et complexes.