La commande Linux `look` examine un fichier et affiche toutes les lignes débutant par un terme ou une expression spécifique. Il est essentiel de noter que son fonctionnement peut varier entre les différentes distributions Linux. Ce guide vous expliquera comment l’utiliser efficacement.
Le fonctionnement spécifique de la commande look sur Ubuntu
La commande `look`, bien que simple, m’a été d’une grande aide lors de mes recherches pour cet article. J’ai rencontré deux difficultés principales : la compatibilité et la documentation.
Cet article a été testé sur Ubuntu, Fedora et Manjaro. `look` était disponible sur toutes ces distributions, ce qui est positif. Le problème était que son comportement n’était pas uniforme entre elles. La version d’Ubuntu se distinguait particulièrement. Pourtant, d’après les pages de manuel d’Ubuntu, le fonctionnement devrait être le même.
Après investigation, j’ai compris que `look` utilise traditionnellement un algorithme de recherche binaire, alors que la version d’Ubuntu effectue une recherche linéaire. Les pages de manuel en ligne d’Ubuntu pour Bionic Beaver (18.04), Cosmic Cuttlefish (18.10) et Disco Dingo (19.04) indiquent à tort que la version d’Ubuntu utilise une recherche binaire.
En consultant la page de manuel locale sur Ubuntu, il est clairement indiqué que leur version de `look` emploie une recherche linéaire. Il existe une option en ligne de commande pour forcer l’utilisation d’une recherche binaire. Aucune autre distribution n’offre la possibilité de choisir entre ces méthodes.
man look
En parcourant la page de manuel, une section décrit explicitement que cette version de `look` utilise une recherche linéaire au lieu d’une recherche binaire.
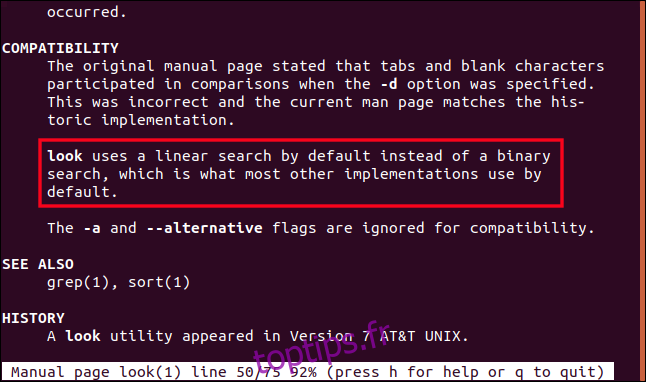
Il est donc crucial de toujours vérifier les pages de manuel locales en premier lieu.
Comparaison entre recherche linéaire et recherche binaire
La recherche binaire est plus rapide et plus efficace que la recherche linéaire, ce qui est particulièrement visible lors de l’utilisation de fichiers volumineux. Cependant, un inconvénient de la recherche binaire est que le fichier doit être trié. Si vous ne souhaitez pas modifier votre fichier original, vous pouvez toujours trier une copie pour l’utiliser avec `look`.
Nous allons illustrer cela plus loin dans l’article. Gardez simplement à l’esprit que sur Fedora, Manjaro et probablement la plupart des autres distributions Linux, vous devrez créer une copie triée de votre fichier et travailler avec celle-ci.
Installation du dictionnaire de mots
`look` peut être utilisé avec n’importe quel fichier texte ou avec le fichier de dictionnaire local nommé « words ».
Sur Manjaro, vous devez installer le fichier « words ». Pour cela, utilisez la commande suivante:
sudo pacman -Syu words

Utilisation de la commande `look`
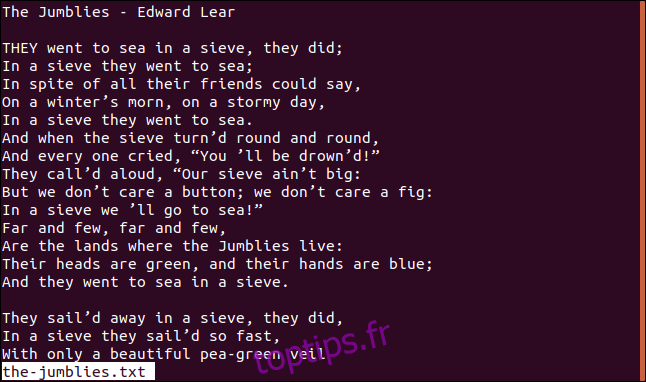
Dans cet article, nous utiliserons un fichier texte du poème « The Jumblies » d’Edward Lear.
Affichons son contenu avec la commande:
less the-jumblies.txt

Voici la première partie du poème. Notez que nous utilisons Ubuntu, donc le fichier n’a pas été trié. Sur Fedora et Manjaro, nous travaillerions avec une copie triée du fichier, ce que nous aborderons ultérieurement.
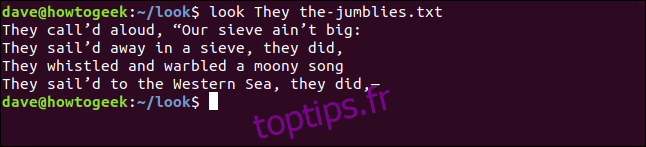
Si nous recherchons les lignes commençant par le mot « Ils », nous trouverons une partie des actions des Jumblies.
look They the-jumblies.txt

La commande `look` affiche ces lignes:
Ignorer la casse des caractères
Pour que `look` ignore la différence entre les majuscules et les minuscules, utilisez l’option `-f` (ignorer la casse). Nous utilisons à nouveau « ils » comme mot de recherche, mais cette fois en minuscules.
look -f they the-jumblies.txt

Cette fois, les résultats incluent une ligne supplémentaire.
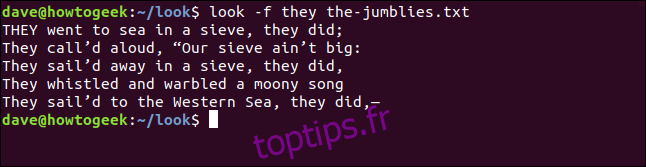
La ligne commençant par « ILS » n’a pas été trouvée lors de la première recherche car elle est en majuscules et ne correspondait pas au terme de recherche « Ils ».
Ignorer la casse permet à `look` de l’inclure dans les résultats.
Utilisation de `look` avec un fichier trié
Si votre distribution Linux utilise une version de `look` qui suit le comportement traditionnel de la recherche binaire, vous devez soit trier votre fichier, soit travailler avec une copie triée de celui-ci.
Réitérons la commande pour rechercher « Ils », mais cette fois sur Manjaro.

Comme vous pouvez le constater, aucun résultat n’a été renvoyé. Pourtant, nous savons qu’il y a des vers dans le poème qui commencent par le mot « Ils ».
Créons une copie triée du fichier. Si vous comptez utiliser les options `-f` (ignorer la casse) ou `-d` (alphanumérique et espaces uniquement) avec `look`, vous devez les utiliser lors du tri du fichier.
L’option `-o` (sortie) permet de spécifier le nom du fichier où les lignes triées seront enregistrées. Dans cet exemple, nous l’avons nommé « sorted.txt ».
sort -f -d the-jumblies.txt -o sorted.txt

Examinons le fichier sorted.txt puis utilisons les options `-f` et `-d`.
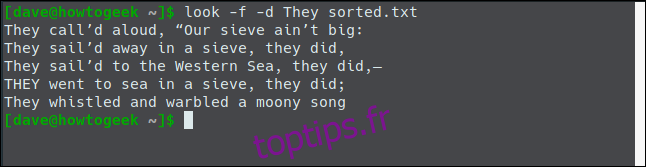
Nous obtenons maintenant les résultats attendus.
Limiter la recherche aux caractères alphanumériques et aux espaces
Pour ignorer tout ce qui n’est pas un caractère alphanumérique ou un espace, utilisez l’option `-d` (alphanumérique).
Cherchons s’il y a des mots qui commencent par « Oh ».
look -f oh the-jumblies.txt

`look` ne renvoie aucun résultat.
Réessayons en indiquant à `look` d’ignorer tout sauf les caractères alphanumériques et les espaces. Cela implique que les caractères et symboles tels que la ponctuation seront ignorés.
look -f -d oh the-jumblies.txt

Cette fois, nous obtenons un résultat. Nous n’avions pas trouvé cette ligne auparavant car les guillemets et le point d’exclamation perturbaient la recherche.

Définition du caractère de fin
Vous pouvez indiquer à `look` d’utiliser un caractère spécifique comme délimiteur de fin. Habituellement, les espaces et la fin des lignes sont utilisés comme tels.
L’option `-t` (caractère de fin) permet de spécifier le caractère que nous souhaitons utiliser. Dans cet exemple, nous utiliserons l’apostrophe. Il est nécessaire de l’échapper avec une barre oblique inverse pour que `look` comprenne que nous ne voulons pas ouvrir une chaîne.
Nous encadrons également le terme de recherche de guillemets car il inclut un espace. Nous recherchons donc deux mots.
look -f -t \' "they call" the-jumblies.txt

Les résultats correspondent au terme de recherche, se terminant par l’apostrophe que nous avons spécifiée.

Utilisation de `look` sans fichier
Si aucun nom de fichier n’est indiqué en ligne de commande, `look` utilise le fichier de mots.
La commande:

donne ces résultats:
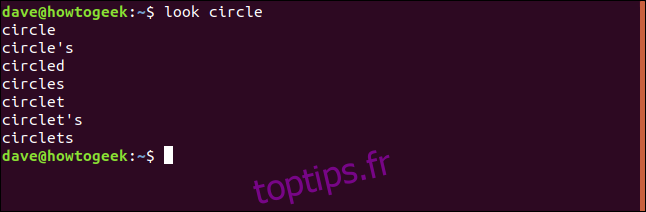
Il s’agit de tous les mots du fichier qui commencent par « cercle ».
Conclusion
Voilà, vous savez l’essentiel sur la commande `look`.
Son utilisation est assez simple une fois que vous avez compris que son comportement peut varier entre les distributions Linux, et que vous avez déterminé si votre version effectue une recherche binaire ou linéaire.