
Sous Linux, awk est une dynamo de manipulation de texte en ligne de commande, ainsi qu’un puissant langage de script. Voici une introduction à certaines de ses fonctionnalités les plus intéressantes.
Comment awk a obtenu son nom
La commande awk a été nommée en utilisant les initiales des trois personnes qui ont écrit la version originale en 1977: Alfred Aho, Peter Weinberger, et Brian Kernighan. Ces trois hommes appartenaient au légendaire AT&T Laboratoires Bell Panthéon Unix. Avec les contributions de beaucoup d’autres depuis lors, awk a continué d’évoluer.
C’est un langage de script complet, ainsi qu’une boîte à outils complète de manipulation de texte pour la ligne de commande. Si cet article vous met en appétit, vous pouvez découvrez chaque détail sur awk et ses fonctionnalités.
Règles, modèles et actions
awk fonctionne sur des programmes contenant des règles composées de modèles et d’actions. L’action est exécutée sur le texte qui correspond au modèle. Les motifs sont entourés d’accolades ({}). Ensemble, un modèle et une action forment une règle. Le programme awk entier est entouré de guillemets simples (‘).
Jetons un coup d’œil au type le plus simple de programme awk. Il n’a pas de modèle, donc il correspond à chaque ligne de texte qui y est insérée. Cela signifie que l’action est exécutée sur chaque ligne. Bien utilisez-le sur la sortie de le qui commande.
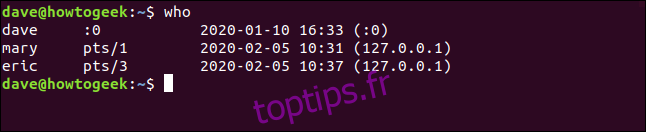
Voici la sortie standard de who:
who
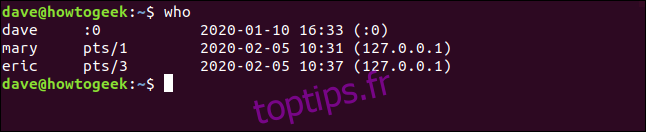
Peut-être que nous n’avons pas besoin de toutes ces informations, mais plutôt que nous voulons simplement voir les noms sur les comptes. Nous pouvons diriger la sortie de who dans awk, puis dire à awk de n’imprimer que le premier champ.
Par défaut, awk considère un champ comme une chaîne de caractères entourée d’espaces, le début d’une ligne ou la fin d’une ligne. Les champs sont identifiés par un signe dollar ($) et un nombre. Ainsi, $ 1 représente le premier champ, que nous utiliserons avec l’action d’impression pour imprimer le premier champ.
Nous tapons ce qui suit:
who | awk '{print $1}'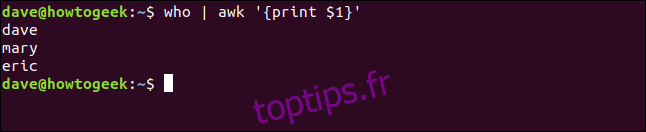
awk imprime le premier champ et rejette le reste de la ligne.
Nous pouvons imprimer autant de champs que nous le souhaitons. Si nous ajoutons une virgule comme séparateur, awk imprime un espace entre chaque champ.
Nous tapons ce qui suit pour imprimer également l’heure à laquelle la personne s’est connectée (champ quatre):
who | awk '{print $1,$4}'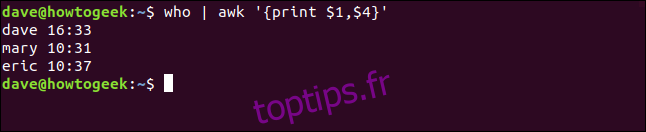
Il existe quelques identificateurs de champ spéciaux. Ceux-ci représentent la ligne entière de texte et le dernier champ de la ligne de texte:
$ 0: représente la ligne entière de texte.
$ 1: représente le premier champ.
$ 2: représente le deuxième champ.
$ 7: représente le septième champ.
45 $: représente le 45e champ.
$ NF: signifie «nombre de champs» et représente le dernier champ.
Nous allons taper ce qui suit pour faire apparaître un petit fichier texte contenant une courte citation attribuée à Dennis Ritchie:
cat dennis_ritchie.txt

Nous voulons qu’awk imprime le premier, le deuxième et le dernier champ du devis. Notez que bien qu’il soit enveloppé dans la fenêtre du terminal, il ne s’agit que d’une seule ligne de texte.
Nous tapons la commande suivante:
awk '{print $1,$2,$NF}' dennis_ritchie.txt
Nous ne connaissons pas cette «simplicité». est le 18e champ dans la ligne de texte, et nous ne nous en soucions pas. Ce que nous savons, c’est que c’est le dernier champ, et nous pouvons utiliser $ NF pour obtenir sa valeur. La période est juste considérée comme un autre personnage de la