Comment récupérer les données d'un site Web avec Google Sheets
L'extraction de données Web, ou "web scraping", se révèle être une méthode performante pour extraire et analyser automatiquement des informations depuis des sites internet. Bien qu'une extraction manuelle soit possible, elle s'avère souvent fastidieuse et chronophage. Les outils de "web scraping" simplifient et accélèrent ce processus, tout en réduisant les coûts.
Il est intéressant de noter que Google Sheets, grâce à sa fonction IMPORTXML, peut devenir un outil unique pour l'extraction de données Web. IMPORTXML permet d'extraire aisément des informations de pages Web et de les utiliser pour diverses tâches telles que l'analyse, la création de rapports ou tout autre usage axé sur les données.
La fonction IMPORTXML dans Google Sheets
Google Sheets intègre une fonction appelée IMPORTXML, qui permet d'importer des données à partir de formats Web tels que XML, HTML, RSS et CSV. Cette fonctionnalité est particulièrement précieuse pour collecter des données Web sans recourir à un codage complexe.
Voici la syntaxe de base d'IMPORTXML :
=IMPORTXML(url, xpath_query)
- url : l'adresse de la page Web à partir de laquelle vous souhaitez extraire les données.
- xpath_query : la requête XPath qui détermine les données à extraire.
XPath (XML Path Language) est un langage utilisé pour naviguer dans les documents XML, incluant le HTML. Il permet de spécifier l'emplacement précis des données au sein de la structure HTML. La maîtrise des requêtes XPath est essentielle pour une utilisation efficace d'IMPORTXML.
Comprendre XPath
XPath offre une variété de fonctions et d'expressions pour parcourir et filtrer les données dans un document HTML. Un exposé détaillé sur XML et XPath dépasse le cadre de cet article, nous allons donc nous concentrer sur quelques notions essentielles :
- Sélection d'éléments : Les symboles / et // permettent de sélectionner des éléments et de définir des chemins. Par exemple, /html/body/div sélectionne tous les éléments div dans le corps d'un document.
- Sélection d'attributs : le symbole @ permet de sélectionner des attributs. Par exemple, //@href sélectionne tous les attributs href de la page.
- Filtres de prédicats : les prédicats entre crochets ([ ]) permettent de filtrer des éléments. Par exemple, /div[@class="container"] sélectionne tous les éléments div ayant la classe "container".
- Fonctions : XPath inclut des fonctions telles que contain(), start-with() et text() pour effectuer des actions spécifiques comme vérifier le contenu du texte ou les valeurs d'attributs.
Maintenant que vous connaissez la syntaxe d'IMPORTXML, l'adresse du site Web et l'élément à extraire, comment trouver le XPath de cet élément ?
Il n'est pas nécessaire de connaître par cœur la structure d'un site Web pour en extraire des données avec IMPORTXML. En réalité, chaque navigateur offre un outil pratique permettant de copier instantanément le XPath de n'importe quel élément.
L'outil "Inspecter l'élément" permet d'extraire le XPath des éléments d'un site Web. Voici comment procéder :
Maintenant que vous avez tout le nécessaire, passons à la pratique et utilisons IMPORTXML pour extraire quelques liens.
Comment extraire des liens d'un site Web avec IMPORTXML
IMPORTXML permet de récupérer divers types de données depuis des sites Web, notamment des liens, des vidéos, des images et pratiquement tous les éléments disponibles. Les liens sont particulièrement importants pour l'analyse Web, car ils donnent des indications sur la structure et le contenu d'un site.
IMPORTXML permet de récupérer rapidement des liens dans Google Sheets, puis de les analyser en détail à l'aide des fonctions proposées par Google Sheets.
1. Extraire tous les liens
Pour extraire tous les liens d'une page Web, utilisez la formule suivante :
=IMPORTXML(url, "//a/@href")
Cette requête XPath sélectionne tous les attributs href d'un élément, ce qui permet d'extraire tous les liens de la page.
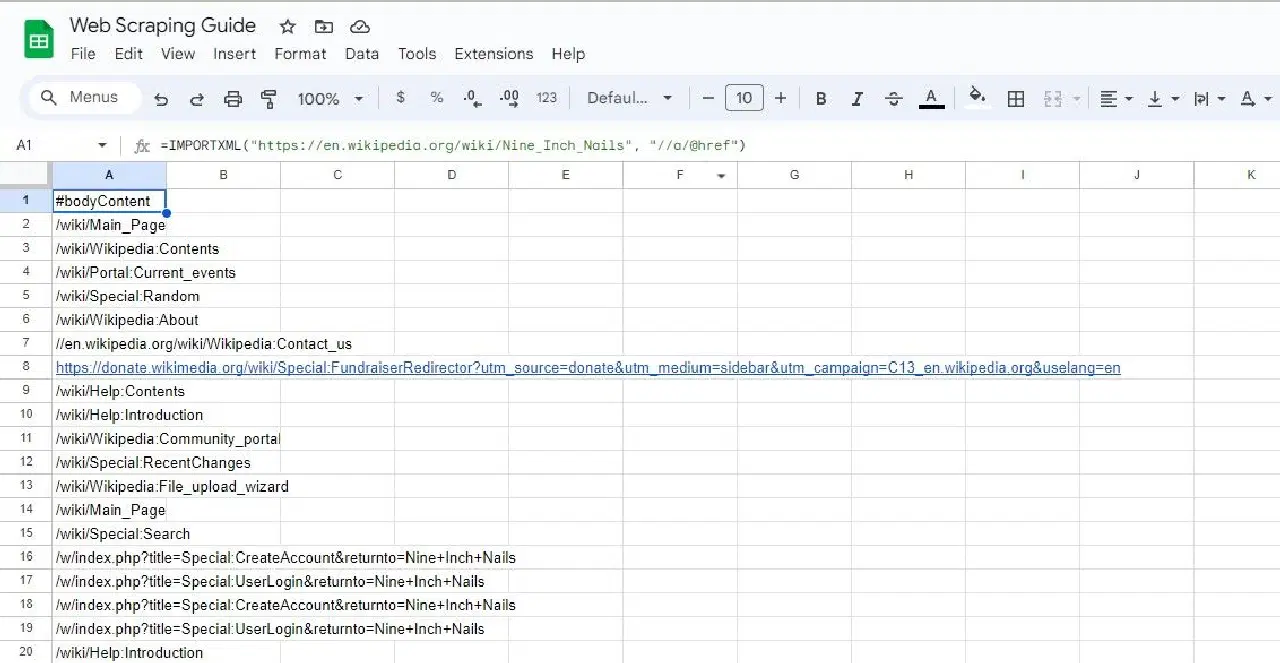
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a/@href")
La formule ci-dessus extrait tous les liens d'un article Wikipédia.
Il est préférable de saisir l'adresse de la page Web dans une cellule distincte, puis de faire référence à cette cellule dans votre formule. Cela évite les formules trop longues et complexes. Vous pouvez faire de même avec la requête XPath.
2. Extraire tous les textes de liens
Pour extraire le texte des liens en plus de leurs URL, utilisez :
=IMPORTXML(url, "//a")
Cette requête sélectionne tous les éléments et permet d'extraire le texte du lien ainsi que les URL associées.
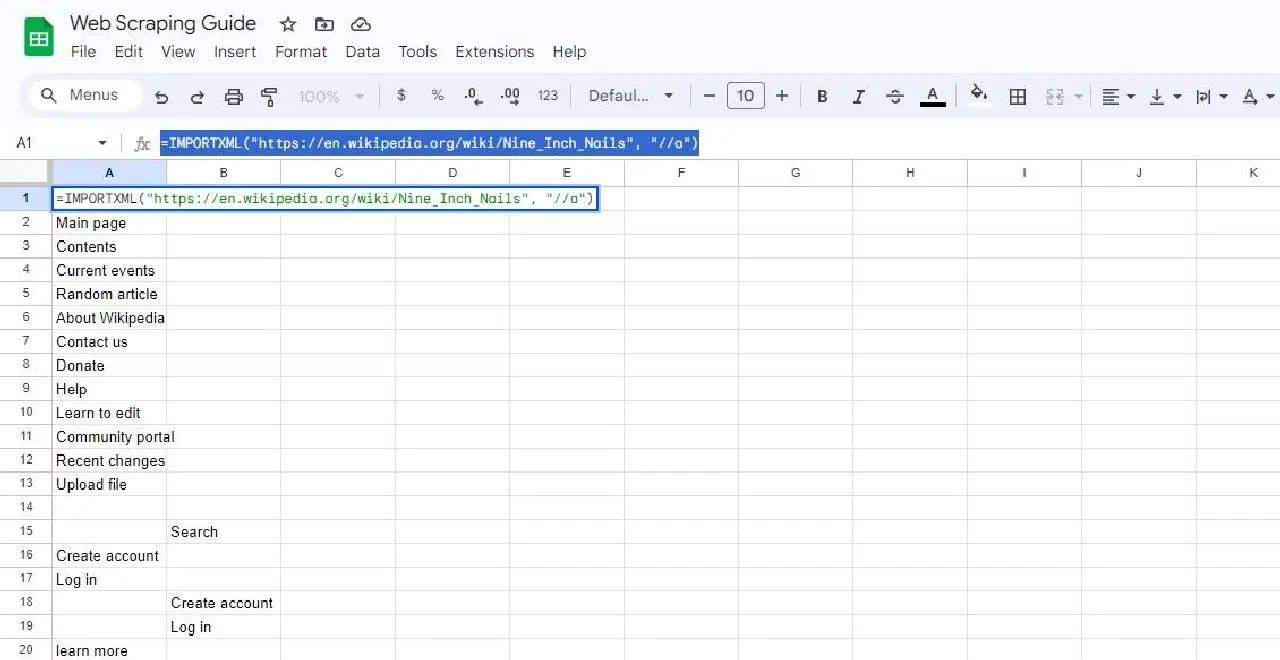
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a")
La formule ci-dessus extrait les textes de liens du même article Wikipédia.
Comment extraire des liens spécifiques d'un site Web avec IMPORTXML
Parfois, il est nécessaire d'extraire des liens spécifiques en fonction de certains critères. Par exemple, vous pouvez être intéressé par les liens contenant un mot-clé particulier ou situés dans une partie spécifique de la page.
Avec une bonne connaissance de XPath, vous pouvez identifier précisément n'importe quel élément recherché.
1. Extraire les liens contenant un mot-clé
Pour extraire les liens contenant un mot-clé spécifique, utilisez la fonction XPath contain() :
=IMPORTXML(url, "//a[contains(@href, 'mot-clé')]/@href")
Cette requête sélectionne les attributs href des éléments dont le href contient le mot-clé indiqué.
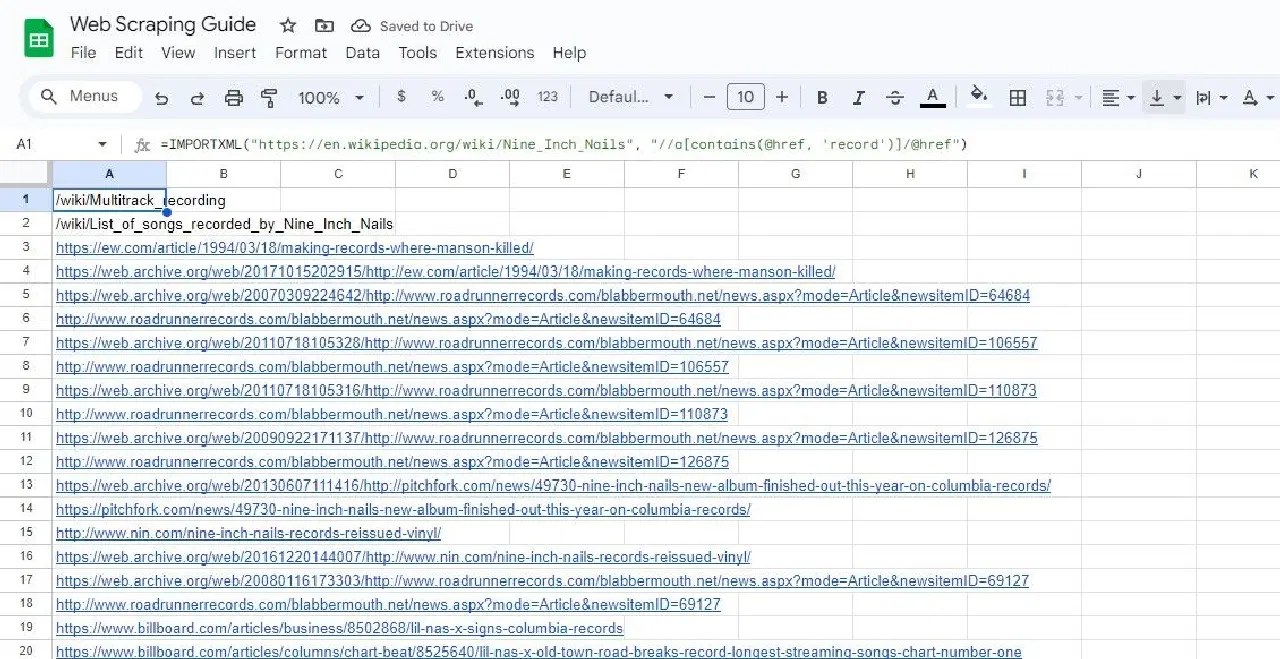
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a[contains(@href, 'record')]/@href")
La formule ci-dessus extrait tous les liens contenant le mot "record" dans leur texte à partir d'un exemple d'article Wikipédia.
2. Extraire les liens d'une section
Pour extraire les liens d'une section spécifique de la page, spécifiez le XPath de cette section. Par exemple :
=IMPORTXML(url, "//div[@class="section"]//a/@href")
Cette requête sélectionne les attributs href des éléments à l'intérieur des éléments div ayant la classe "section".
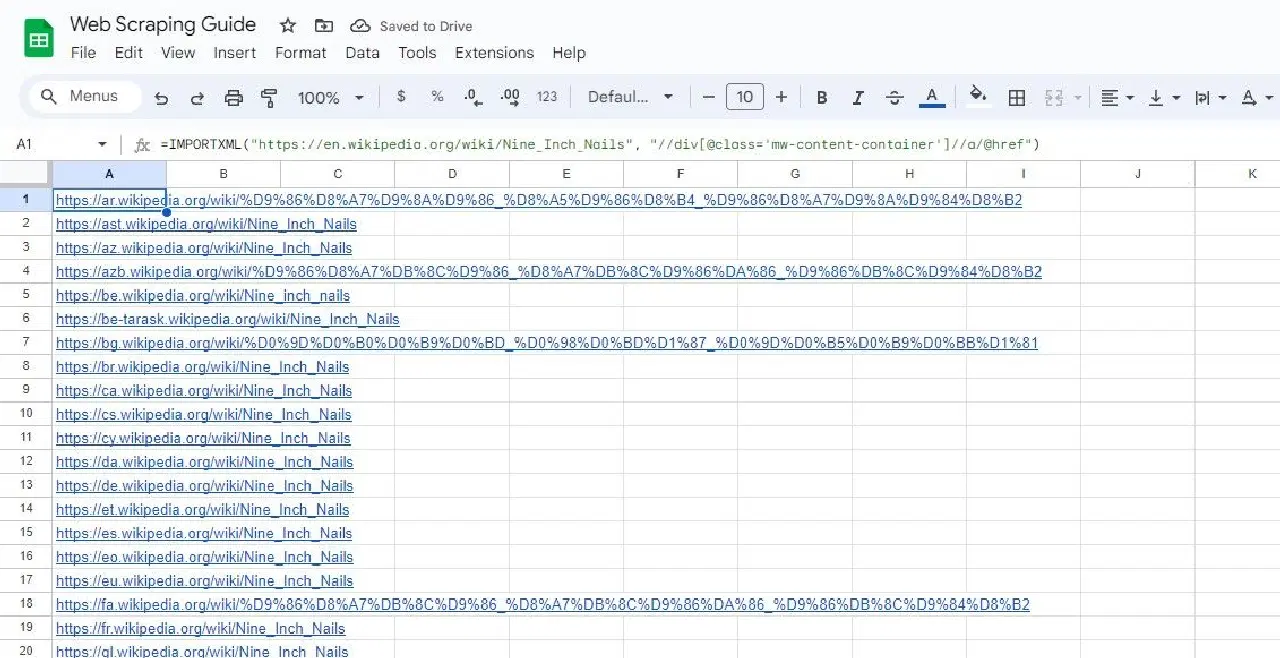
De même, la formule ci-dessous sélectionne tous les liens de la classe div qui possèdent la classe "mw-content-container" :
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//div[@class="mw-content-container"]//a/@href")
Il est important de souligner qu'IMPORTXML ne se limite pas au simple "web scraping". Vous pouvez utiliser la famille de fonctions IMPORT pour importer des tableaux de données depuis des sites Web vers Google Sheets.
Bien que Google Sheets et Excel partagent de nombreuses fonctions, la famille de fonctions IMPORT est exclusive à Google Sheets. L'importation de données depuis des sites Web vers Excel nécessitera donc des méthodes différentes.
Simplifiez l'extraction de données Web avec Google Sheets
L'extraction de données Web via Google Sheets et la fonction IMPORTXML se présente comme une méthode accessible et polyvalente pour la collecte d'informations à partir de sites Web.
En maîtrisant XPath et en apprenant à construire des requêtes efficaces, vous pouvez exploiter pleinement le potentiel d'IMPORTXML et obtenir des informations précieuses depuis des sources Web. Alors, n'hésitez pas à commencer votre extraction et à améliorer significativement votre analyse Web !