Comment les voitures autonomes utilisent la technologie CNN
Quand j'étais petit, j'étais captivé par les dessins animés mettant en scène des voitures qui semblaient se mouvoir par elles-mêmes. Je me demandais alors si de telles voitures pouvaient exister réellement et s'il y avait de minuscules robots cachés à l'intérieur qui les conduisaient comme par magie.
Maintenant que nous grandissons, les voitures autonomes deviennent une réalité concrète ! Je suis réellement fasciné par ces véhicules. Comment font-ils pour s'arrêter aux panneaux stop et aux feux rouges ? Peuvent-ils détecter les animaux et les personnes qui se trouvent sur la route ? Et comment gèrent-ils la conduite de nuit ou par temps de pluie ou de neige ?
Parlons donc des voitures autonomes ! Ce sont des véhicules qui peuvent se déplacer seuls sans intervention humaine. Des entreprises comme Tesla et Waymo utilisent des techniques informatiques sophistiquées, comme l'apprentissage profond, pour rendre ces voitures extrêmement intelligentes. L'apprentissage profond permet aux voitures de réaliser des actions impressionnantes, comme la reconnaissance des panneaux de signalisation et la conduite sécurisée, même par mauvais temps. Il s'agit de mettre en œuvre une technologie de pointe pour transformer notre manière de nous déplacer dans l'avenir !
Histoire
L'histoire des véhicules autonomes ressemble à une longue et passionnante aventure. Imaginez les années 1920, lorsque les voitures autonomes n'étaient qu'un rêve pour la plupart. Un inventeur ingénieux, Francis Houdina, a marqué les esprits en créant une voiture qui suivait les lignes de la route. Cependant, cette voiture nécessitait des câbles spécifiques dissimulés sous la chaussée pour la guider.
 Source : theatlantic.com
Source : theatlantic.com
Dans les années 1980 et 1990, les brillants esprits de l'Université Carnegie Mellon ont franchi un cap majeur. Ils ont mis au point des voitures capables de "voir" grâce à des caméras, ce qui leur permettait de naviguer dans les rues animées des villes. Ces voitures étaient comme des explorateurs qui apprenaient à conduire en observant leur environnement.
En 2004, un moment charnière s'est produit lors d'un défi dans le désert. Les voitures autonomes ont fait leur apparition, tentant une course difficile – une course qu'elles n'ont pas gagnée, mais qui a marqué un début. C'était en quelque sorte leur camp d'entraînement pour devenir de meilleurs conducteurs.
Cependant, la véritable percée a eu lieu dans les années 2000 et 2010, lorsque de grandes entreprises comme Tesla, Uber et Google (aujourd'hui Waymo) ont investi dans le secteur automobile. Google a commencé à tester des voitures autonomes en 2009. En 2015, les véhicules Tesla ont introduit une fonction qui leur permettait de se conduire partiellement seules sur certaines routes. Ils pouvaient gérer la direction et le maintien de la trajectoire sans intervention humaine constante.
À mesure que de plus en plus d'entreprises rejoignaient la course, la compétition pour créer des voitures entièrement autonomes s'est intensifiée. Imaginez des équipes d'ingénieurs rivalisant pour concevoir des véhicules capables de se déplacer sans que des humains les dirigent.
Mais l'histoire est en marche. Nous continuons de travailler à la création de voitures capables de se conduire seules, ce qui modifierait notre manière de voyager. Cette aventure est toujours en cours et cela signifie que nous pourrions bientôt bénéficier de trajets plus sûrs et plus simples, à mesure que ces voitures autonomes sophistiquées s'améliorent.
Comment fonctionnent les voitures autonomes ?
Les voitures autonomes sont de véritables experts de la prise de décision ! Elles utilisent des caméras, des LiDAR, des RADAR, des GPS et des capteurs inertiels pour recueillir des informations sur leur environnement. Ensuite, des algorithmes spéciaux, appelés algorithmes d'apprentissage profond, traitent ces données pour comprendre ce qui se passe autour d'elles. En fonction de cette compréhension, ils prennent des décisions importantes pour conduire en toute sécurité et de manière fluide.
 Source : arxiv.org
Source : arxiv.org
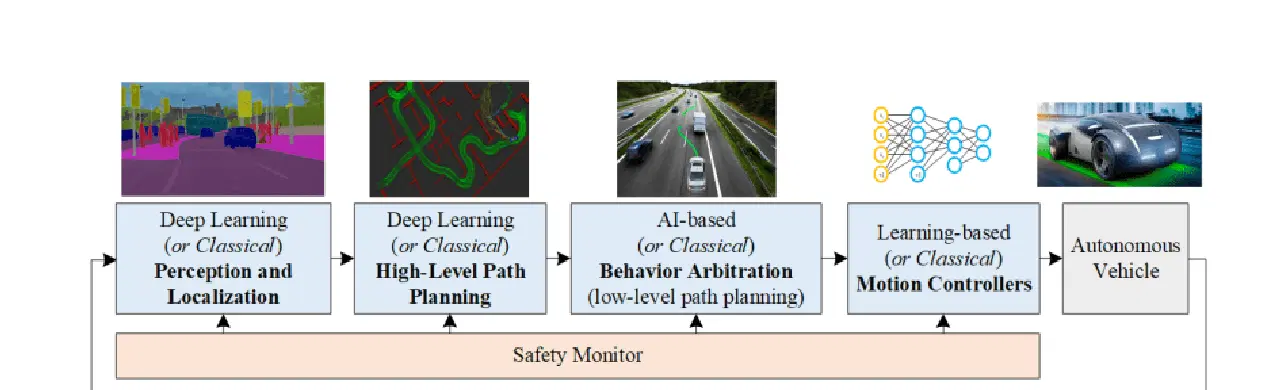
Pour bien comprendre le fonctionnement des voitures autonomes, examinons de plus près ces quatre aspects principaux présentés dans le schéma ci-dessus. C'est comme résoudre un puzzle : comprendre chaque pièce nous aidera à avoir une vision globale du fonctionnement de ces voitures étonnantes :
- Perception
- Localisation
- Prédiction
- Prise de décision
- Planification de la trajectoire globale
- Arbitrage comportemental
- Contrôleur de mouvement
Perception
#1. Caméra
Les caméras sont les yeux d'une voiture autonome : elles sont absolument essentielles ! Elles permettent à la voiture de comprendre ce qui se passe autour d'elle. Ces caméras remplissent plusieurs tâches, telles que l'identification des objets, leur séparation et la détermination de la position de la voiture.
Pour s'assurer que la voiture ne rate rien, des caméras sont placées partout : à l'avant, à l'arrière, à gauche et à droite. Ces caméras fonctionnent en synergie pour créer une vue d'ensemble de l'environnement. C'est un peu comme une vision spéciale à 360 degrés pour la voiture !

Ces caméras ne sont pas là pour faire de la figuration. Elles sont intelligentes. Certaines regardent loin, jusqu'à 200 mètres, pour que la voiture puisse anticiper les situations à venir. D'autres se concentrent sur les objets proches afin que la voiture puisse être attentive aux détails. Cette équipe de caméras aide la voiture à tout voir et à tout comprendre, tel un ami qui la guide, afin qu'elle puisse conduire en toute sécurité et prendre les bonnes décisions.
Parfois, les caméras sont particulièrement utiles, comme lors du stationnement, car elles offrent une vue large et aident à choisir les bonnes manœuvres pour conduire prudemment.
Cependant, l'utilisation des caméras seules pour "voir" pose des défis, en particulier par mauvais temps, comme le brouillard, les fortes pluies ou la nuit. Dans ces conditions, les images des caméras peuvent être floues ou déformées, ce qui peut s'avérer très dangereux.
Pour faire face à ces situations difficiles, nous avons besoin de capteurs spéciaux qui fonctionnent même dans l'obscurité totale. Ces capteurs doivent également être capables de mesurer la distance des objets sans avoir recours à la lumière visible. En intégrant ces capteurs aux "yeux" de la voiture (système de perception), cette dernière parvient à mieux conduire par mauvais temps ou dans des conditions de faible visibilité. La voiture peut ainsi conduire de manière plus sûre, ce qui est idéal pour tous les usagers de la route.
#2. LiDAR
Le LiDAR, acronyme de Light Detection And Ranging, est une technologie avancée qui utilise des lasers pour mesurer la distance des objets. Le LiDAR émet des faisceaux laser et mesure le temps qu'ils mettent à revenir après avoir rebondi sur les objets.

Lorsque le LiDAR et les caméras fonctionnent ensemble, ils aident la voiture à mieux comprendre son environnement. Ils créent une carte 3D de l'espace autour du véhicule. Ces informations spécifiques peuvent ensuite être traitées par des programmes informatiques intelligents, qui aident la voiture à anticiper les actions des autres véhicules. Cela s'avère utile dans des situations de conduite complexes, comme les carrefours très fréquentés, car la voiture peut surveiller les autres véhicules et conduire en toute sécurité.
Cependant, le LiDAR a des limites qui peuvent poser des problèmes. Bien qu'il fonctionne bien la nuit et dans l'obscurité, il peut rencontrer des difficultés en cas d'interférences causées par la pluie ou le brouillard, ce qui peut entraîner des imprécisions dans la perception. Pour pallier ces problèmes, nous utilisons simultanément des capteurs LiDAR et RADAR. Ces capteurs fournissent des informations complémentaires qui aident la voiture à mieux appréhender son environnement. La voiture peut ainsi se conduire seule, de manière plus sûre et plus efficace.
#3. RADAR
Le RADAR, acronyme de Radio Detection and Ranging, est utilisé depuis longtemps, aussi bien dans la vie quotidienne que par les militaires. Initialement employé par l'armée pour la détection d'objets, le RADAR calcule les distances en utilisant des ondes radio. De nos jours, le RADAR est un élément essentiel de nombreuses voitures, notamment les voitures autonomes.
Le RADAR est très performant, car il fonctionne par tous les temps et dans toutes les conditions de luminosité. Au lieu d'utiliser des lasers, il utilise des ondes radio, ce qui le rend polyvalent et très pratique. Cependant, le RADAR est considéré comme un capteur "bruyant", ce qui signifie qu'il peut détecter des obstacles même lorsque la caméra n'en voit pas.

Le "cerveau" de la voiture autonome peut être perturbé par tous les signaux supplémentaires émis par le RADAR, que l'on appelle "bruit". Pour régler ce problème, la voiture doit "nettoyer" les informations du RADAR afin de prendre les bonnes décisions.
"Nettoyer" les données consiste à utiliser des techniques spéciales pour distinguer les signaux forts des signaux faibles, en séparant par exemple les informations importantes des informations moins pertinentes. La voiture utilise une technique sophistiquée appelée Transformation de Fourier Rapide (FFT) pour mieux interpréter les données.
Le RADAR et le LiDAR fournissent des informations sur des points uniques, comme des points sur une feuille de papier. Pour mieux comprendre ces points, la voiture utilise une technique de "regroupement". C'est un peu comme rassembler des éléments similaires. La voiture utilise des méthodes statistiques avancées, comme le regroupement euclidien ou le regroupement K-means, pour combiner les points similaires et les interpréter. La voiture est ainsi capable de conduire de manière plus intelligente et plus sûre.
Localisation
Dans les voitures autonomes, les algorithmes de localisation jouent un rôle primordial dans la détermination de la position et de l'orientation du véhicule pendant sa navigation, ce que l'on appelle l'odométrie visuelle (OV). L'OV fonctionne en identifiant et en faisant correspondre les points clés dans des images vidéo successives.
La voiture analyse des points spécifiques dans les données, comme des repères sur une carte. Ensuite, la voiture utilise une méthode statistique appelée SLAM pour identifier la position des objets et leurs mouvements. Cela permet à la voiture de comprendre l'environnement, comme les routes et les piétons.

Pour faire encore mieux, la voiture utilise ce que l'on appelle l'apprentissage profond. C'est en quelque sorte un ordinateur super intelligent.
Grâce à ces méthodes, la voiture est capable de très bien comprendre les informations. Des réseaux neuronaux comme PoseNet et VLocNet++ exploitent les données ponctuelles pour estimer la position et l'orientation 3D des objets. Ces estimations de position et d'orientation 3D peuvent ensuite être utilisées pour déduire la sémantique de la scène, comme le montre l'image ci-dessous. En utilisant des outils mathématiques et informatiques intelligents, la voiture sait où elle se trouve et ce qui l'entoure. Elle peut ainsi se déplacer seule, de manière sûre et fluide.
Prédiction
Comprendre les conducteurs humains est une tâche complexe, car cela implique des émotions et des réactions plutôt qu'une simple logique. Puisque nous ne pouvons pas deviner à l'avance ce que feront les autres conducteurs, il est essentiel pour les voitures autonomes de bien anticiper leurs actions. Cela contribue à garantir la sécurité sur la route.
Imaginez que les voitures autonomes aient des yeux tout autour, offrant une vue à 360 degrés. Elles peuvent ainsi observer tout ce qui se passe. Elles utilisent ensuite ces informations avec l'apprentissage profond. La voiture met en œuvre des techniques avancées pour prédire les actions des autres conducteurs. C'est un peu comme jouer à un jeu dans lequel vous planifiez à l'avance pour réussir.
 Prédiction à l'aide de l'apprentissage profond
Prédiction à l'aide de l'apprentissage profond
Les capteurs spéciaux des voitures autonomes sont comme leurs yeux. Ils aident la voiture à identifier les objets sur les images, à localiser les objets environnants, à déterminer leur position et à anticiper leur destination. Cela permet à la voiture de comprendre son environnement proche et de prendre des décisions éclairées.
Pendant la phase d'apprentissage, les algorithmes d'apprentissage profond modélisent des informations complexes à partir d'images et de nuages de points obtenus grâce aux LiDAR et aux RADAR. Pendant la conduite réelle (inférence), ce même modèle aide la voiture à se préparer à d'éventuels mouvements, notamment le freinage, l'arrêt, le ralentissement, le changement de voie, etc.
L'apprentissage profond est un allié intelligent pour la voiture. Il lui permet de comprendre les situations incertaines, de se localiser avec précision et de conduire de manière optimale. Cela assure une conduite sûre et plus fluide.
Le plus délicat est de choisir la meilleure action parmi plusieurs options. Opter pour la bonne manœuvre exige une réflexion approfondie pour que la voiture puisse rouler correctement et en toute sécurité.
Prise de décision
Les voitures autonomes doivent faire des choix importants dans des situations délicates, ce qui n'est pas une mince affaire. En effet, les capteurs ne sont pas toujours fiables et les usagers de la route peuvent avoir des comportements imprévisibles. La voiture doit donc anticiper ce que feront les autres et se déplacer de manière à éviter les accidents.
Pour prendre les bonnes décisions, la voiture a besoin de nombreuses informations. La voiture collecte ces données grâce à des capteurs, puis utilise des algorithmes d'apprentissage profond pour identifier la position des objets et prédire les situations à venir. La localisation permet à la voiture de connaître sa position de départ, tandis que la prédiction génère diverses actions possibles en fonction de l'environnement.
La question reste : comment la voiture choisit-elle la meilleure action parmi toutes les possibilités anticipées ?
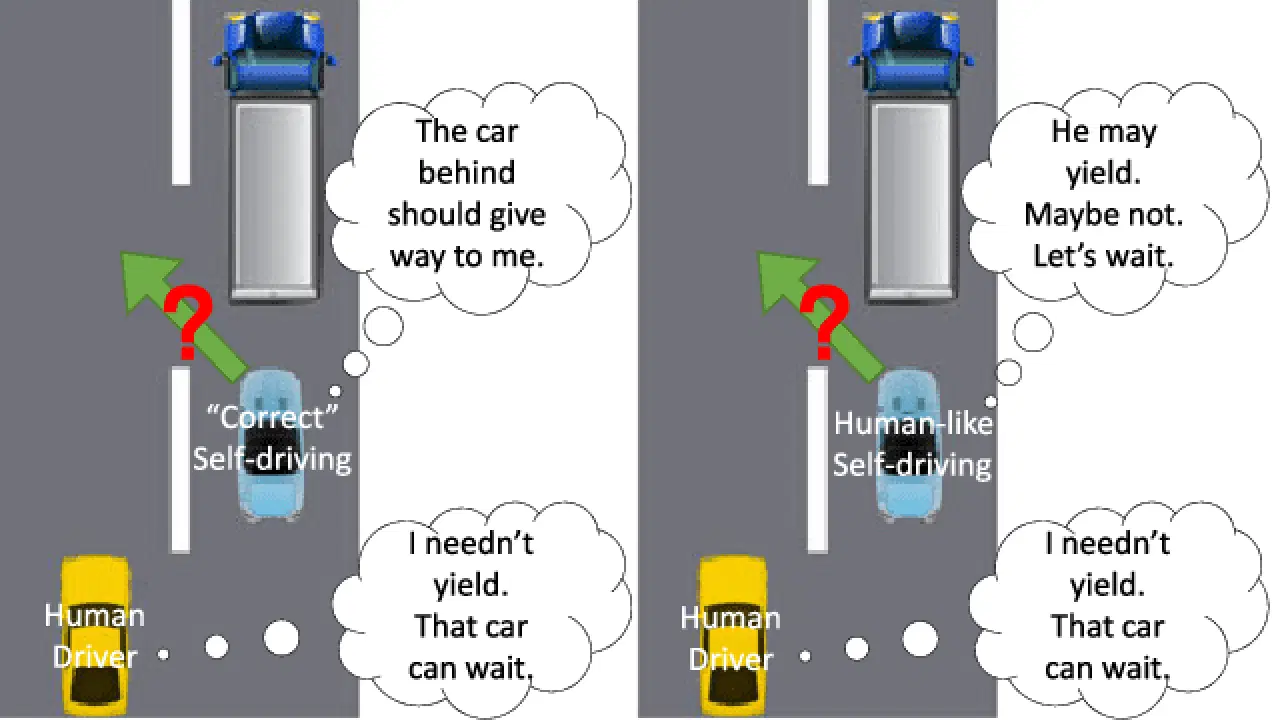 Source : semanticsscholar.org
Source : semanticsscholar.org
L'apprentissage par renforcement profond (DRL) est une technique de prise de décision qui utilise un algorithme appelé Processus de Décision Markovien (PDM). Le PDM est un outil qui permet de deviner comment les usagers de la route pourraient se comporter à l'avenir. Lorsque plusieurs éléments sont en mouvement, la situation devient plus complexe. Cela signifie que la voiture autonome doit envisager encore plus d'actions possibles.
Pour relever le défi de trouver la meilleure solution pour la voiture, le modèle d'apprentissage profond est optimisé grâce à l'optimisation bayésienne. Dans certains cas, un modèle combinant un modèle de Markov caché et une optimisation bayésienne est utilisé pour la prise de décision, ce qui permet à la voiture autonome de naviguer de manière efficace et sûre dans des scénarios complexes.
 Source : arxiv.org
Source : arxiv.org
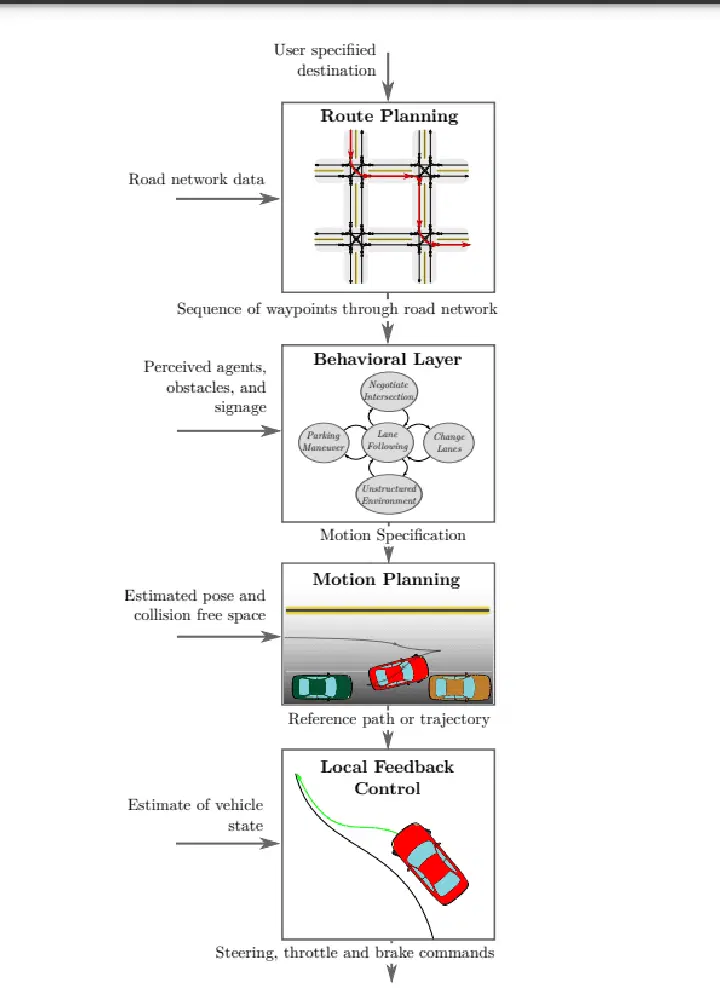
La prise de décision dans les voitures autonomes suit un processus hiérarchique composé de quatre étapes principales :
Planification de l'itinéraire : au début du trajet, la voiture détermine le meilleur itinéraire de sa position actuelle à sa destination. L'objectif est de trouver la solution optimale parmi les différents itinéraires possibles.
Arbitrage comportemental : la voiture doit suivre l'itinéraire une fois qu'il a été planifié. La voiture est consciente des objets statiques comme les routes et les carrefours, mais elle est incapable d'anticiper avec certitude les actions des autres conducteurs. Pour gérer cette incertitude, nous utilisons des méthodes intelligentes telles que les processus de décision markoviens (PDM) pour la planification.
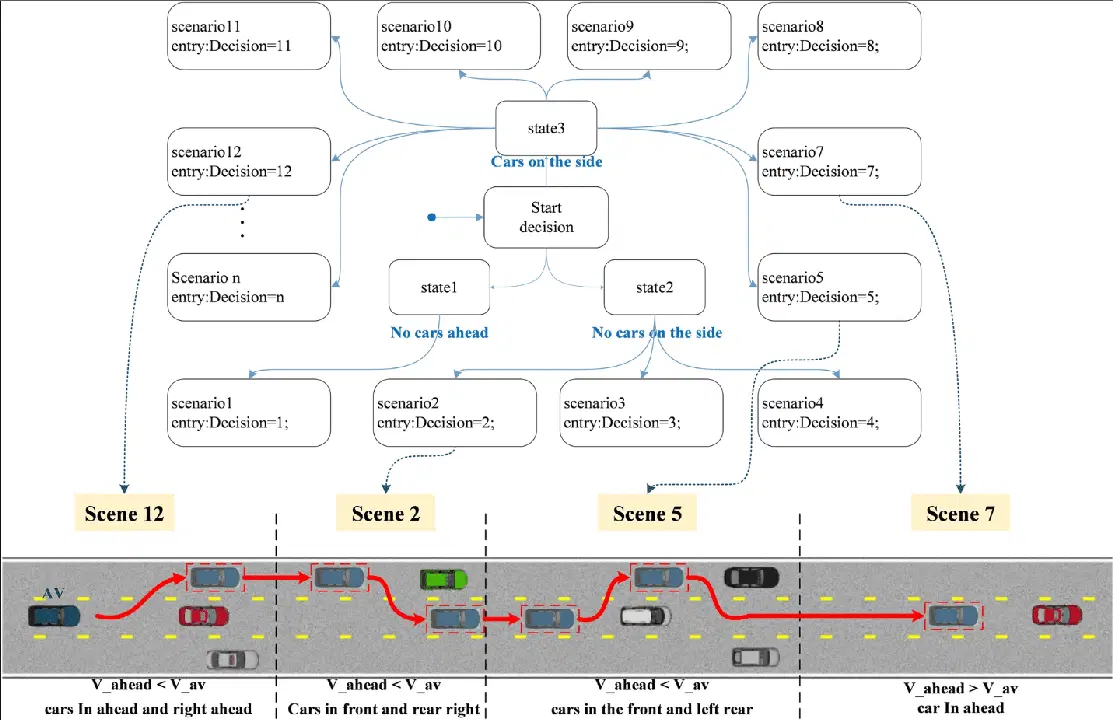 Décision de scénario de la machine à états supérieure
Décision de scénario de la machine à états supérieure
Planification du mouvement : une fois l'itinéraire défini et la couche comportementale ayant déterminé comment l'emprunter, le système de planification du mouvement coordonne les déplacements de la voiture. Il s'agit de veiller à ce que la voiture se déplace de manière sûre et confortable pour les passagers. Il prend en compte des éléments tels que la vitesse, les changements de voie et l'environnement.
Contrôle du véhicule : la dernière étape est le contrôle du véhicule, qui exécute la trajectoire de référence générée par le système de planification du mouvement, en veillant à ce que la voiture suive la trajectoire prévue en douceur et en toute sécurité.
En décomposant la prise de décision en ces différentes étapes, les voitures autonomes sont capables de se déplacer de manière efficace et sûre dans des environnements complexes. Cela garantit un trajet fluide et confortable pour les passagers.
Réseaux de neurones convolutifs
Les réseaux de neurones convolutifs (CNN) sont largement utilisés dans les voitures autonomes en raison de leur aptitude à modéliser des informations spatiales, notamment les images. Les CNN excellent dans l'extraction de caractéristiques à partir d'images, ce qui les rend utiles pour de nombreuses applications différentes.
Dans un CNN, à mesure que la profondeur du réseau augmente, différentes couches capturent différents schémas. Les premières couches détectent des caractéristiques simples, telles que les bords, tandis que les couches plus profondes reconnaissent des caractéristiques plus complexes, comme les formes d'objets (les feuilles des arbres ou les pneus des véhicules, par exemple). Cette adaptabilité fait des CNN un algorithme fondamental dans les voitures autonomes.
Le composant principal d'un CNN est la couche convolutive, qui utilise un noyau convolutif (matrice de filtrage) pour traiter les zones locales de l'image d'entrée.
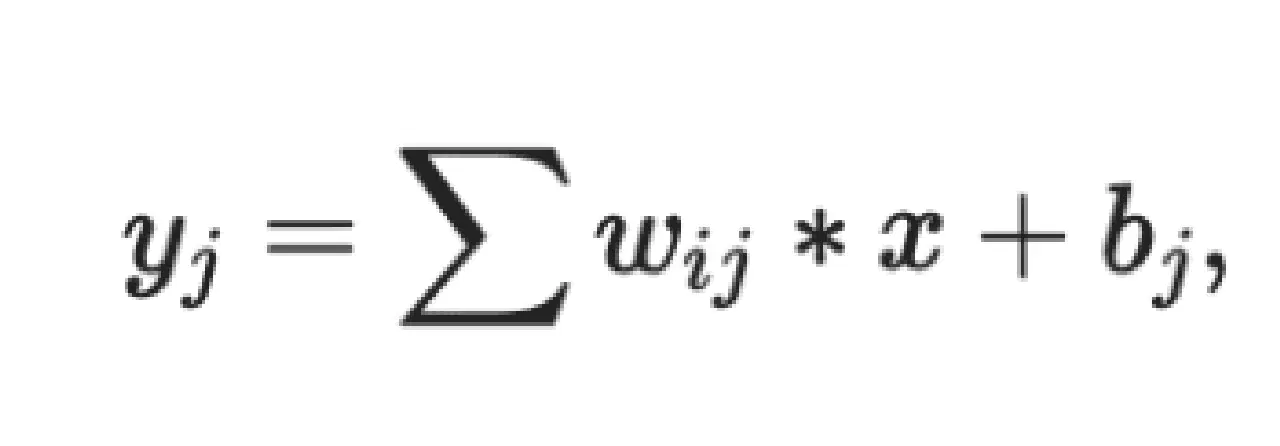
La matrice de filtrage est mise à jour pendant l'apprentissage pour obtenir des poids pertinents. Une propriété fondamentale des CNN est le partage de poids, où les mêmes paramètres de poids sont utilisés pour représenter différentes transformations, ce qui permet de gagner de l'espace de traitement et de réaliser diverses représentations de caractéristiques.
La sortie de la couche convolutive est généralement traitée par une fonction d'activation non linéaire, comme Sigmoid, Tanh ou ReLU. ReLU est souvent privilégiée, car elle converge plus rapidement que les autres. De plus, le résultat passe souvent par une couche de "pooling" maximal. Cela permet de conserver les détails importants de l'image, comme l'arrière-plan et les textures.
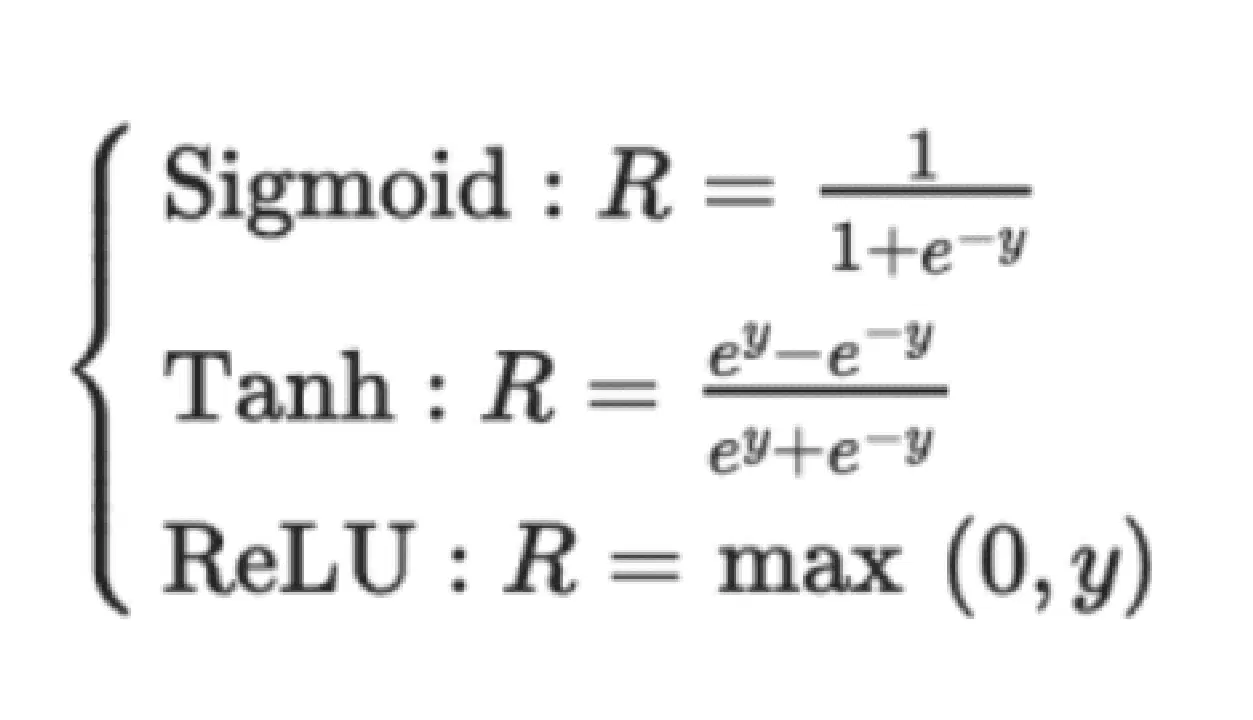
Trois propriétés essentielles des CNN les rendent polyvalents et fondamentaux dans les voitures autonomes :
- Champs récepteurs locaux
- Poids partagés
- Échantillonnage spatial
Ces propriétés réduisent le surapprentissage et stockent des représentations et des caractéristiques essentielles pour la classification, la segmentation, la localisation, etc.
Voici deux réseaux CNN utilisés par les entreprises pionnières dans le domaine des voitures autonomes :
- HydraNet de Tesla
- ChauffeurNet de Google Waymo
Pour en savoir plus sur les réseaux de neurones convolutifs.
#1. HydraNet de Tesla
HydraNet est une architecture dynamique présentée par Ravi et al. en 2018, principalement développée pour la segmentation sémantique des voitures autonomes. Son objectif principal est d'améliorer l'efficacité des calculs lors de l'inférence.
Le principe d'HydraNet est de disposer de différents réseaux CNN, appelés branches, affectés à des tâches spécifiques. Chaque branche reçoit des données d'entrée différentes, et le réseau peut choisir de manière sélective quelles branches exécuter pendant l'inférence, en agrégeant ensuite les sorties des différentes branches pour prendre une décision finale.
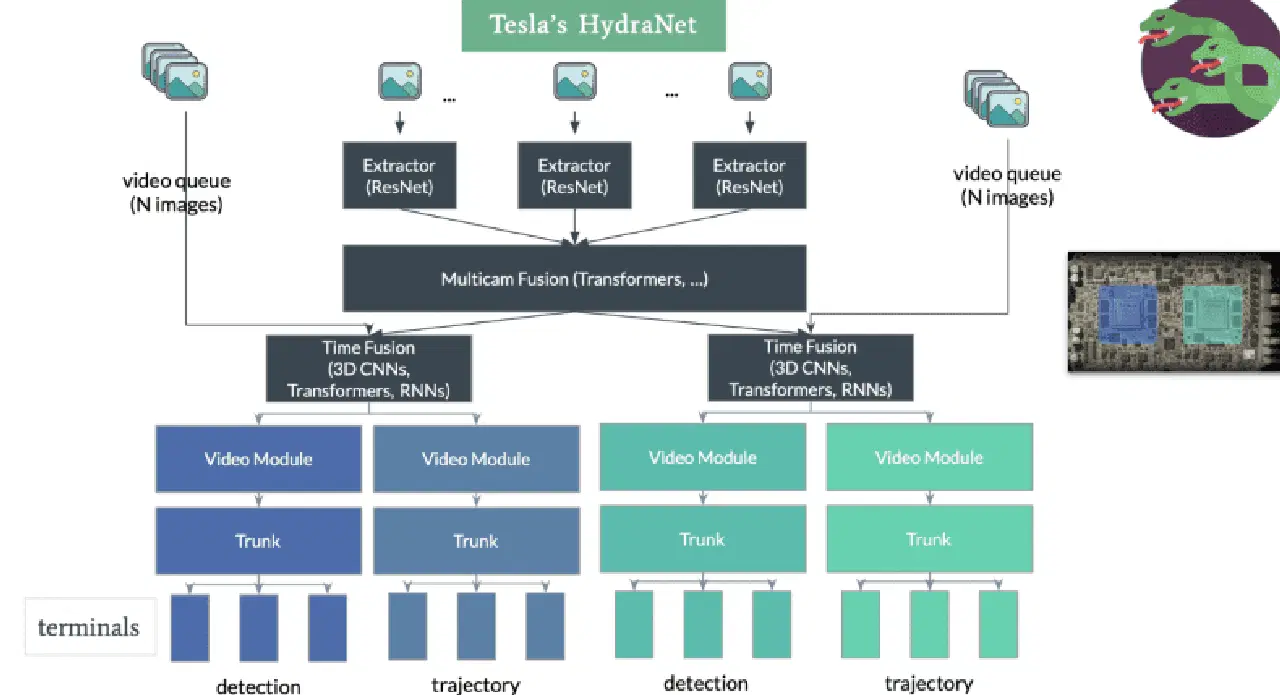
Dans le contexte des voitures autonomes, les données d'entrée peuvent représenter différents aspects de l'environnement, comme les objets statiques (arbres et barrières routières), les routes et voies, les feux de circulation, etc. Ces données sont traitées dans des branches distinctes. Lors de l'inférence, le mécanisme de porte décide quelles branches activer, et le combinateur rassemble leurs sorties pour prendre la décision finale.
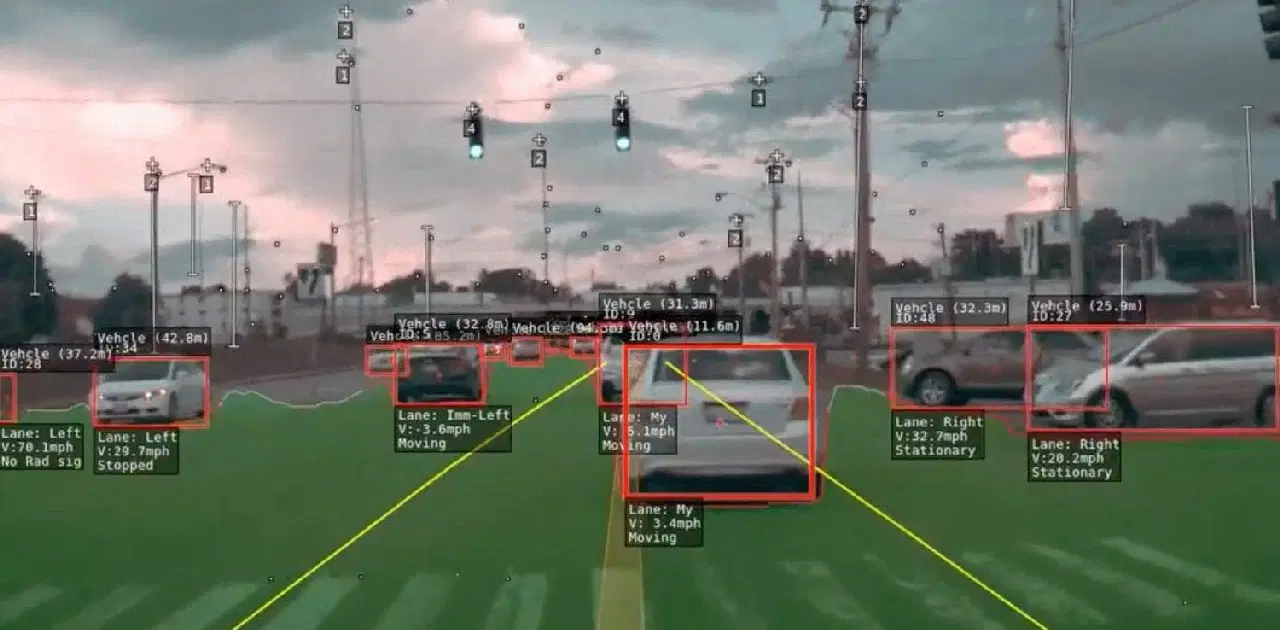 Détection de vitesse, de voie et de mouvement
Détection de vitesse, de voie et de mouvement
Tesla a adapté l'architecture HydraNet, en intégrant une structure partagée pour surmonter les difficultés liées à la séparation des données pour chaque tâche lors de l'inférence. La structure partagée, généralement constituée de blocs ResNet-50 modifiés, permet au réseau d'être entraîné sur les données de tous les objets. Les têtes spécifiques à chaque tâche, basées sur une architecture de segmentation sémantique comme U-Net, permettent au modèle de prédire les résultats spécifiques à chaque tâche.
L'HydraNet de Tesla se distingue par sa capacité à projeter une vue plongeante, en créant une représentation 3D de l'environnement sous tous les angles. Cette dimensionnalité améliorée améliore la navigation de la voiture. Il est remarquable que Tesla parvienne à ce résultat sans utiliser de capteurs LiDAR. Il s'appuie uniquement sur deux capteurs : une caméra et un radar. L'efficacité de l'HydraNet de Tesla lui permet de traiter les informations de huit caméras et de générer une perception de la profondeur, démontrant ainsi des capacités impressionnantes sans avoir recours à la technologie LiDAR supplémentaire.
#2. ChauffeurNet de Google Waymo
ChauffeurNet est un réseau neuronal basé sur RNN utilisé par Google Waymo pour entraîner des voitures autonomes grâce à l'apprentissage par imitation. Bien qu'il repose principalement sur un RNN pour générer les trajectoires de conduite, il comprend également un composant CNN appelé FeatureNet.
Ce réseau de caractéristiques convolutives extrait des représentations de caractéristiques contextuelles partagées par d'autres réseaux, et sert à extraire les caractéristiques du système de perception.
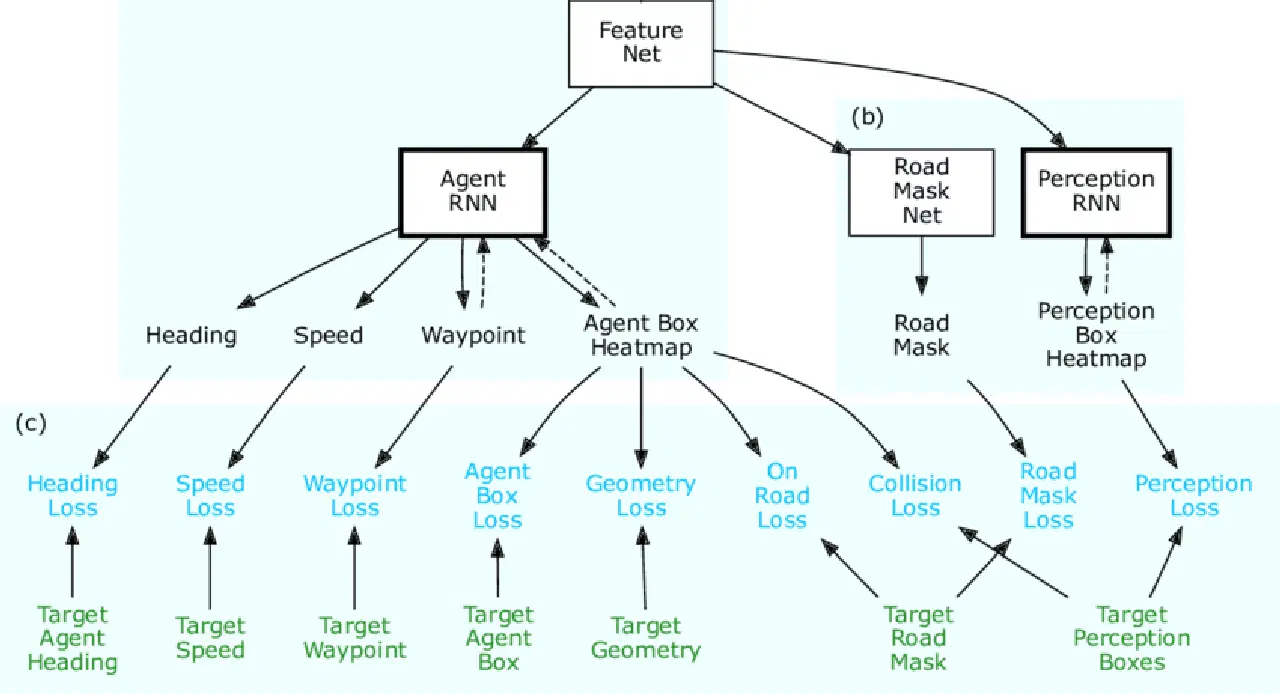 Source : Porte de la recherche
Source : Porte de la recherche
Le principe de ChauffeurNet est d'entraîner la voiture autonome en imitant le comportement de conducteurs expérimentés grâce à l'apprentissage par imitation. Pour pallier les lacunes des données d'apprentissage réelles, les auteurs de l'article "ChauffeurNet : Apprendre à conduire en imitant le meilleur et en synthétisant le pire" ont introduit des données synthétiques.
Ces données synthétiques introduisent des variations telles que la perturbation de la trajectoire, l'ajout d'obstacles et la création de scènes artificielles. Il s'est avéré que l'entraînement de la voiture avec des données synthétiques est plus efficace que l'utilisation exclusive de données réelles.
Dans ChauffeurNet, le système de perception ne fait pas partie du processus de bout en bout, mais il sert de système de niveau intermédiaire. Cela permet au réseau de traiter diverses variations des données d'entrée du système de perception. Le réseau observe une représentation de niveau intermédiaire de la scène à partir des capteurs et, en utilisant ces données ainsi que des données synthétiques, il imite le comportement de conduite d'un expert.
En tenant compte de la tâche de perception et en créant une vue d'ensemble de l'environnement, ChauffeurNet facilite un apprentissage par transfert plus simple, ce qui permet au réseau de prendre de meilleures décisions en se basant à la fois sur des données réelles et simulées. Le réseau génère des trajectoires de conduite en prédisant de manière itérative des points successifs sur la trajectoire, en se basant sur les représentations de niveau intermédiaire. Cette approche s'est avérée prometteuse pour former plus efficacement les voitures autonomes, ouvrant la voie à des systèmes de conduite autonome plus sûrs et plus fiables.
#3. Processus de décision de Markov partiellement observable utilisé pour les voitures autonomes
Le processus de décision de Markov partiellement observable (POMDP) est un cadre mathématique utilisé dans le contexte des voitures autonomes pour prendre des décisions dans des conditions d'incertitude. Dans les scénarios du monde réel, les voitures autonomes ne disposent souvent que d'informations limitées sur leur environnement, en raison du bruit des capteurs, des occultations ou des systèmes de perception imparfaits. Le POMDP est conçu pour gérer cette observabilité partielle et pour prendre des décisions optimales en tenant compte à la fois de l'incertitude et des données disponibles.
Dans un POMDP, l'agent décideur opère dans un environnement dont les états ne sont que partiellement observables. L'agent agit, et l'environnement évolue de manière probabiliste vers de nouveaux états. Cependant, l'agent ne reçoit que des observations partielles ou des informations bruitées sur l'état réel de l'environnement. L'objectif est de trouver une stratégie qui maximise la récompense cumulée attendue au fil du temps, tout en tenant compte de l'incertitude de l'environnement et des données de l'agent.
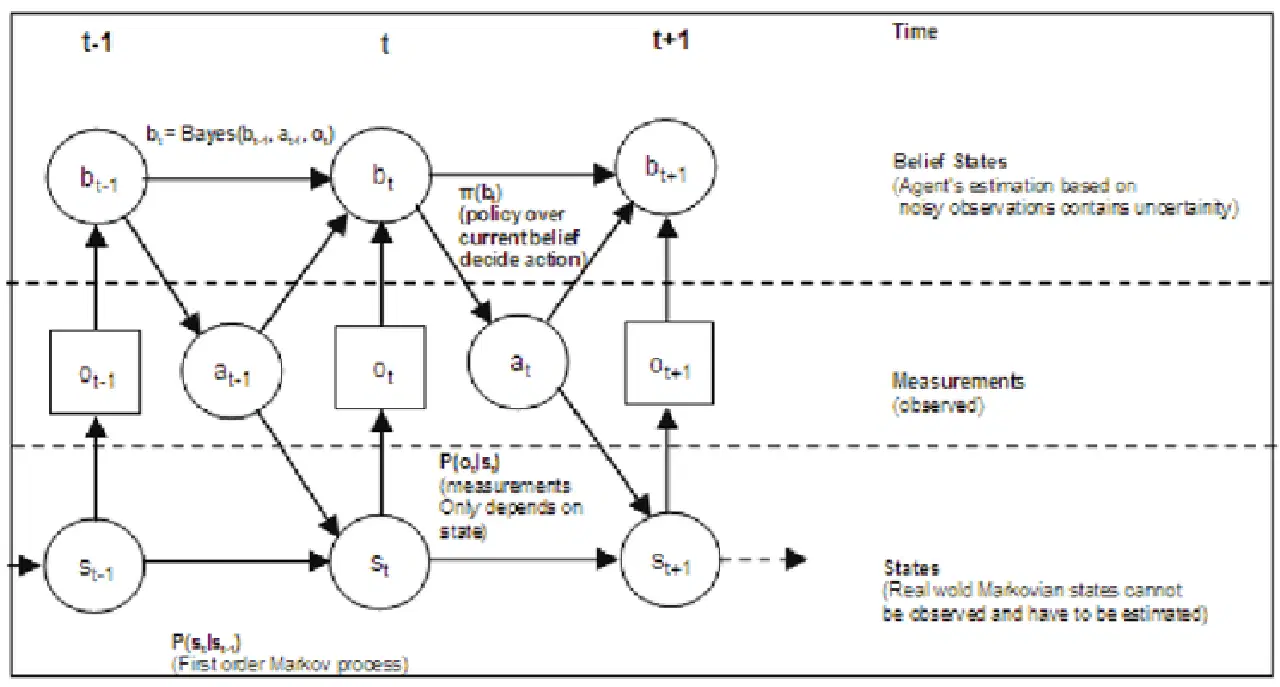 Source : Porte de la recherche
Source : Porte de la recherche
Dans le contexte des voitures autonomes, le POMDP est particulièrement utile pour des tâches telles que la planification du mouvement, la prédiction de la trajectoire et l'interaction avec les autres usagers de la route. La voiture autonome peut utiliser le POMDP pour prendre des décisions concernant les changements de voie, les ajustements de vitesse et les interactions avec les piétons et les autres véhicules, tout en tenant compte de l'incertitude de l'environnement.
Un POMDP est composé de six éléments et peut être noté ainsi : POMDP
M : = (I, S, A, R, P, γ)
où,
I : Observations
S : Ensemble fini d'états
A : Ensemble fini d'actions
R : fonction de récompense
P : fonction de probabilité de transition
γ : facteur d'actualisation pour les récompenses futures.
Les POMDP peuvent être difficiles à calculer en raison de la nécessité de prendre en compte plusieurs états et observations possibles. Cependant, des algorithmes avancés, tels que la planification de l'espace de croyance et les méthodes de Monte Carlo, sont souvent utilisés pour se rapprocher de la stratégie optimale et permettre une prise de décision en temps réel dans les voitures autonomes.
En intégrant les POMDP dans leurs algorithmes de prise de décision, les voitures autonomes sont capables de naviguer dans des environnements complexes et incertains de manière plus efficace et plus sûre, en tenant compte de l'incertitude des données des capteurs et en prenant des décisions éclairées pour atteindre leurs objectifs.
La voiture autonome, en tant qu'agent, apprend en interagissant avec l'environnement grâce à l'apprentissage par renforcement (RL), une forme d'apprentissage automatique. L'état, l'action et la récompense sont les trois variables clés de l'apprentissage par renforcement profond (DRL).
État : Il décrit la situation actuelle de la voiture autonome à un moment donné, comme sa position sur la route.
Action : Elle représente toutes les actions possibles que la voiture peut effectuer, notamment des décisions comme les changements de voie ou les ajustements de vitesse.
Récompense : Elle fournit un retour d'information à la voiture chaque fois qu'elle effectue une action spécifique. La récompense peut être positive ou négative, et l'objectif du DRL est de