

Dans le monde actuel axé sur les données, la méthode traditionnelle de collecte manuelle des données est obsolète. Un ordinateur avec une connexion Internet sur chaque bureau a fait du Web une énorme source de données. Ainsi, la méthode moderne de collecte de données la plus efficace et la plus rapide est le web scraping. Et en ce qui concerne le web scraping, Python dispose d’un outil appelé Beautiful Soup. Dans cet article, je vais vous guider à travers les étapes d’installation de Beautiful Soup pour commencer avec le web scraping.
Avant d’installer et de travailler avec Beautiful Soup, découvrons pourquoi vous devriez y aller.
Table des matières
Qu’est-ce qu’une Belle Soupe ?
Imaginons que vous recherchiez «l’impact de COVID sur la santé des gens» et que vous avez trouvé quelques pages Web contenant des données pertinentes. Mais que se passe-t-il s’ils ne vous offrent pas une option de téléchargement en un seul clic pour emprunter leurs données ? Voici la belle soupe en jeu.
Beautiful Soup fait partie de l’index des bibliothèques Python pour extraire les données des sites ciblés. Il est plus confortable de récupérer des données à partir de pages HTML ou XML.
Leonard Richardson a mis en lumière l’idée de Beautiful Soup pour gratter le Web en 2004. Mais sa contribution au projet se poursuit encore aujourd’hui. Il met fièrement à jour chaque nouvelle version de Beautiful Soup sur son compte Twitter.
Bien que Beautiful Soup pour le web scraping ait été développé avec Python 3.8, il fonctionne parfaitement avec Python 3 et Python 2.4 également.

Souvent, les sites Web utilisent la protection captcha pour sauver leurs données des outils d’IA. Dans ce cas, quelques modifications de l’en-tête « user-agent » dans Beautiful Soup ou l’utilisation d’API de résolution de Captcha peuvent imiter un navigateur fiable et tromper l’outil de détection.
Cependant, si vous n’avez pas le temps d’explorer Beautiful Soup ou si vous souhaitez que le grattage soit effectué efficacement et facilement, vous ne devriez pas manquer de consulter cette API de grattage Web, où vous pouvez simplement fournir une URL et obtenir les données. tes mains.
Si vous êtes déjà un programmeur, l’utilisation de Beautiful Soup pour le grattage ne sera pas intimidante en raison de sa syntaxe simple pour naviguer dans les pages Web et extraire les données souhaitées en fonction de l’analyse conditionnelle. En même temps, c’est aussi convivial pour les débutants.
Bien que Beautiful Soup ne soit pas destiné au grattage avancé, il est préférable de gratter les données des fichiers écrits dans des langages de balisage.
Une documentation claire et détaillée est un autre point de brownie que Beautiful Soup a mis en sac.
Trouvons un moyen facile d’obtenir une belle soupe dans votre machine.
Comment installer Beautiful Soup pour le Web Scraping ?
Pip – Un gestionnaire de packages Python sans effort développé en 2008 est désormais un outil standard parmi les développeurs pour installer toutes les bibliothèques ou dépendances Python.
Pip est livré par défaut avec l’installation des versions récentes de Python. Ainsi, si vous avez des versions récentes de Python installées sur votre système, vous êtes prêt à partir.
Ouvrez l’invite de commande et tapez la commande pip suivante pour installer la belle soupe instantanément.
pip install beautifulsoup4
Vous verrez quelque chose de similaire à la capture d’écran suivante sur votre écran.
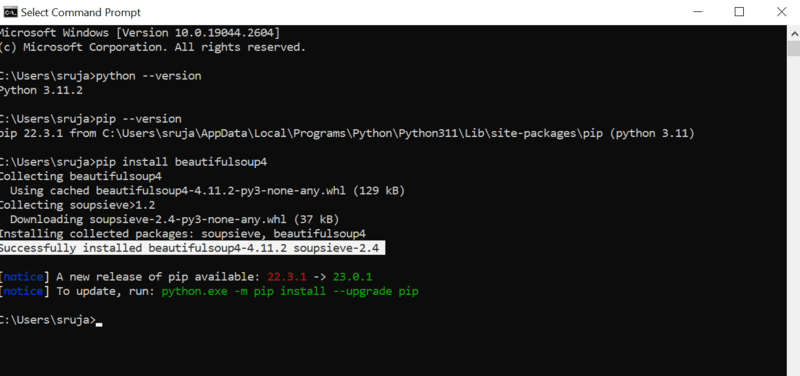
Assurez-vous d’avoir mis à jour le programme d’installation PIP vers la dernière version pour éviter les erreurs courantes.
La commande pour mettre à jour le programme d’installation de pip vers la dernière version est :
pip install --upgrade pip
Nous avons couvert avec succès la moitié du terrain dans cet article.
Maintenant que Beautiful Soup est installé sur votre machine, voyons comment l’utiliser pour le grattage Web.
Comment importer et travailler avec Beautiful Soup pour le Web Scraping ?
Tapez la commande suivante dans votre IDE python pour importer une belle soupe dans le script python actuel.
from bs4 import BeautifulSoup
Maintenant, la belle soupe est dans votre fichier Python à utiliser pour le grattage.
Regardons un exemple de code pour apprendre à extraire les données souhaitées avec une belle soupe.
Nous pouvons dire à Beautiful Soup de rechercher des balises HTML spécifiques dans le site Web source et de récupérer les données présentes dans ces balises.
Dans cet article, j’utiliserai marketwatch.com, qui met à jour les cours des actions en temps réel de diverses sociétés. Extrayons quelques données de ce site Web pour vous familiariser avec la bibliothèque Beautiful Soup.
Importez le package « requests » qui nous permettra de recevoir et de répondre aux requêtes HTTP et « urllib » pour charger la page Web à partir de son URL.
from urllib.request import urlopen import requests
Enregistrez le lien de la page Web dans une variable afin de pouvoir y accéder facilement ultérieurement.
url="https://www.marketwatch.com/investing/stock/amzn"
La prochaine consisterait à utiliser la méthode « urlopen » de la bibliothèque « urllib » pour stocker la page HTML dans une variable. Passez l’URL à la fonction « urlopen » et enregistrez le résultat dans une variable.
page = urlopen(url)
Créez un objet Beautiful Soup et analysez la page Web souhaitée à l’aide de « html.parser ».
soup_obj = BeautifulSoup(page, 'html.parser')
Désormais, l’intégralité du script HTML de la page Web ciblée est stockée dans la variable ‘soup_obj’.
Avant de continuer, examinons le code source de la page ciblée pour en savoir plus sur le script HTML et les balises.
Faites un clic droit n’importe où sur la page Web avec votre souris. Ensuite, vous trouverez une option d’inspection, comme indiqué ci-dessous.
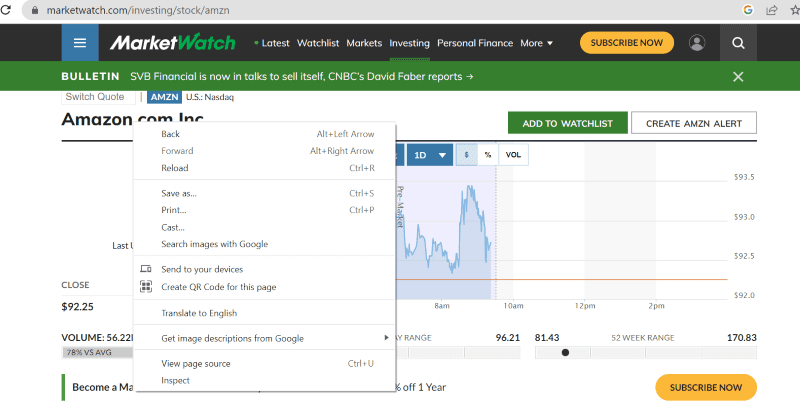
Cliquez sur inspecter pour afficher le code source.
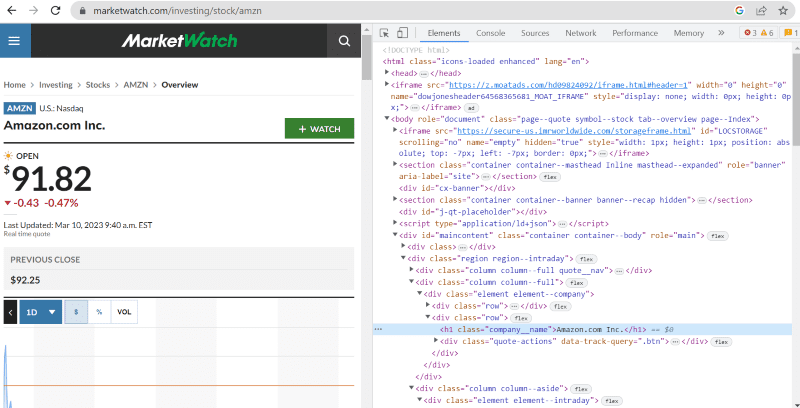
Dans le code source ci-dessus, vous pouvez trouver des balises, des classes et des informations plus spécifiques sur chaque élément visible sur l’interface du site Web.
La méthode « find » dans Beautiful Soup nous permet de rechercher les balises HTML demandées et de récupérer les données. Pour ce faire, nous donnons le nom de la classe et les balises à la méthode qui extrait des données spécifiques.
Par exemple, « Amazon.com Inc. » affiché sur la page Web porte le nom de la classe : ‘company__name’ tagué sous ‘h1’. Nous pouvons entrer ces informations dans la méthode ‘find’ pour extraire l’extrait de code HTML pertinent dans une variable.
name = soup_obj.find('h1', attrs={'class': 'company__name'})Sortons le script HTML stocké dans la variable « nom » et le texte requis à l’écran.
print(name) print(name.text)

Vous pouvez voir les données extraites imprimées à l’écran.
Web Scrape le site Web IMDb
Beaucoup d’entre nous recherchent des classements de films sur le site d’IMBb avant de regarder un film. Cette démonstration vous donnera une liste des films les mieux notés et vous aidera à vous habituer à la belle soupe pour le grattage Web.
Étape 1 : Importez les magnifiques bibliothèques Soup et Requests.
from bs4 import BeautifulSoup import requests
Étape 2 : Attribuons l’URL que nous voulons récupérer à une variable appelée « url » pour un accès facile dans le code.
Le package « requests » est utilisé pour obtenir la page HTML à partir de l’URL.
url = requests.get('https://www.imdb.com/search/title/?count=100&groups=top_1000&sort=user_rating')Étape 3 : Dans l’extrait de code suivant, nous allons analyser la page HTML de l’URL actuelle pour créer un objet de belle soupe.
soup_obj = BeautifulSoup(url.text, 'html.parser')
La variable « soup_obj » contient maintenant l’intégralité du script HTML de la page Web souhaitée, comme dans l’image suivante.
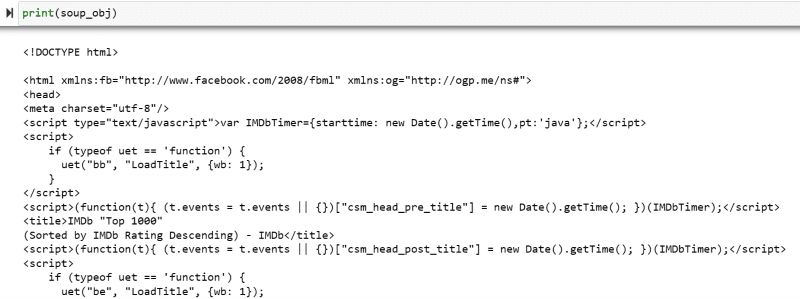
Inspectons le code source de la page Web pour trouver le script HTML des données que nous voulons récupérer.
Passez le curseur sur l’élément de la page Web que vous souhaitez extraire. Ensuite, cliquez dessus avec le bouton droit de la souris et accédez à l’option d’inspection pour afficher le code source de cet élément spécifique. Les visuels suivants vous guideront au mieux.
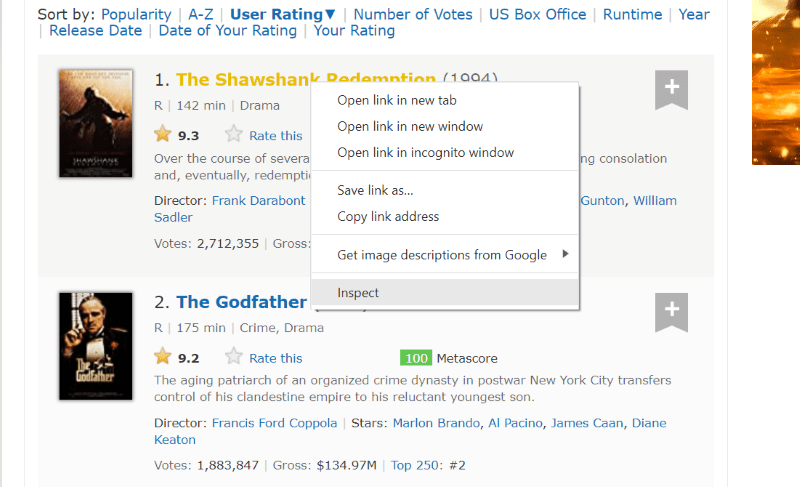
La classe ‘lister-list’ contient toutes les données les mieux notées liées au film sous forme de sous-divisions dans des balises div successives.
Dans le script HTML de chaque carte de film, sous la classe ‘lister-item mode-advanced’, nous avons une balise ‘h3’ qui stocke le nom, le classement et l’année de sortie du film, comme indiqué dans l’image ci-dessous.
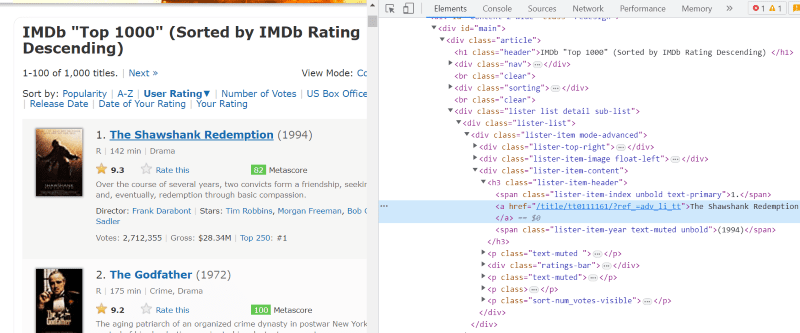
Remarque : La méthode « find » dans Beautiful Soup recherche la première balise qui correspond au nom d’entrée qui lui est attribué. Contrairement à « find », la méthode « find_all » recherche toutes les balises qui correspondent à l’entrée donnée.
Étape 4 : Vous pouvez utiliser les méthodes « find » et « find_all » pour enregistrer le script HTML du nom, du classement et de l’année de chaque film dans une variable de liste.
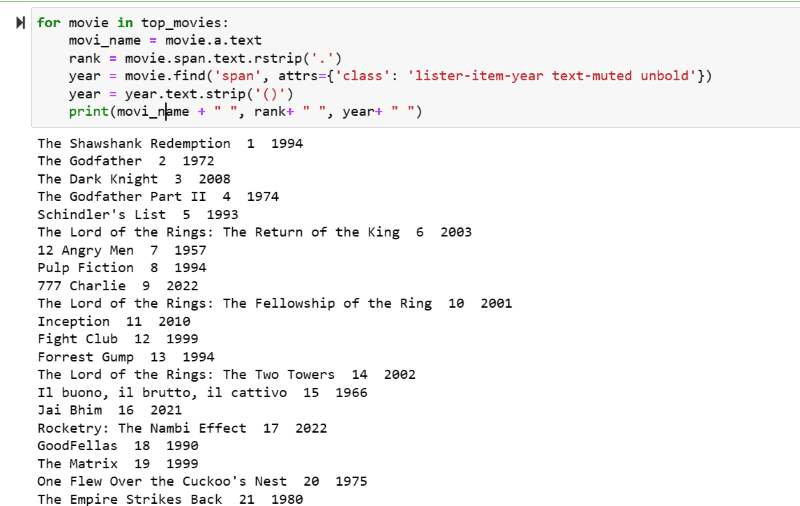
top_movies = soup_obj.find('div',attrs={'class': 'lister-list'}).find_all('h3')Étape 5 : Parcourez la liste des films stockés dans la variable : « top_movies » et extrayez le nom, le classement et l’année de chaque film au format texte à partir de son script HTML à l’aide du code ci-dessous.
for movie in top_movies:
movi_name = movie.a.text
rank = movie.span.text.rstrip('.')
year = movie.find('span', attrs={'class': 'lister-item-year text-muted unbold'})
year = year.text.strip('()')
print(movi_name + " ", rank+ " ", year+ " ")Dans la capture d’écran de sortie, vous pouvez voir la liste des films avec leur nom, leur rang et leur année de sortie.
Vous pouvez facilement déplacer les données imprimées dans une feuille Excel avec du code python et l’utiliser pour votre analyse.
Derniers mots
Cet article vous guide dans l’installation d’une belle soupe pour le grattage Web. De plus, les exemples de grattage que j’ai montrés devraient vous aider à démarrer avec Beautiful Soup.
Comme vous êtes intéressé par la façon d’installer Beautiful Soup pour le grattage Web, je vous recommande fortement de consulter ce guide compréhensible pour en savoir plus sur le grattage Web à l’aide de Python.