Comment créer un DataFrame dans R pour conserver les données de manière organisée
Les *DataFrames* constituent une structure de données essentielle dans l'environnement R, offrant une base solide pour l'analyse et la manipulation de données. Leur utilité s'étend à divers domaines, allant des statistiques à la science des données, en passant par la prise de décision basée sur les données, quel que soit le secteur d'activité.
Les *DataFrames* garantissent la structuration et l'organisation requises pour extraire des informations pertinentes et prendre des décisions éclairées de manière méthodique et efficace.
Dans R, les *DataFrames* sont conçus comme des tableaux, avec des lignes et des colonnes. Chaque ligne représente une observation unique, tandis que chaque colonne correspond à une variable spécifique. Cette organisation simplifie la gestion et l'exploitation des données. Les *DataFrames* peuvent accueillir différents types de données, tels que des nombres, du texte ou des dates, ce qui leur confère une grande polyvalence.
Cet article détaillera l'importance des *DataFrames* et abordera leur création à l'aide de la fonction `data.frame()`.
Nous examinerons également les différentes méthodes de manipulation des données, la création à partir de fichiers CSV et Excel, la conversion d'autres types de données en *DataFrames*, et l'utilisation de la bibliothèque `tibble`.
Voici quelques raisons fondamentales qui soulignent l'importance des *DataFrames* dans R :
Importance des DataFrames
- **Stockage de données structurées :** Les *DataFrames* fournissent une méthode structurée et tabulaire pour l'organisation des données, similaire à une feuille de calcul. Cette structure facilite la gestion et l'organisation des données.
- **Types de données mixtes :** Les *DataFrames* peuvent gérer différents types de données au sein de la même structure. Vous pouvez avoir des colonnes contenant des valeurs numériques, du texte, des facteurs, des dates, etc. Cette polyvalence est cruciale pour le traitement de données réelles.
- **Organisation des données :** Chaque colonne dans un *DataFrame* correspond à une variable, tandis que chaque ligne représente une observation ou un cas spécifique. Cette présentation structurée favorise la compréhension de l'organisation des données, améliorant ainsi leur lisibilité.
- **Importation et exportation de données :** Les *DataFrames* facilitent l'importation et l'exportation de données depuis divers formats de fichiers, tels que CSV, Excel et les bases de données. Cette fonction simplifie le travail avec des sources de données externes.
- **Interopérabilité :** Les *DataFrames* sont largement pris en charge par les packages et fonctions de R, assurant la compatibilité avec d'autres outils et bibliothèques de statistiques et d'analyse de données. Cette interopérabilité permet une intégration transparente au sein de l'écosystème R.
- **Manipulation de données :** R offre un vaste éventail de packages, dont `dplyr` est un exemple notable, qui facilitent le filtrage, la transformation et la synthèse des données au sein des *DataFrames*. Cette capacité est indispensable pour le nettoyage et la préparation des données.
- **Analyse statistique :** Les *DataFrames* sont le format de données standard pour de nombreuses fonctions statistiques et d'analyse de données dans R. Vous pouvez réaliser efficacement des régressions, des tests d'hypothèses et de nombreuses autres analyses statistiques avec des *DataFrames*.
- **Visualisation :** Les packages de visualisation de données dans R, tels que `ggplot2`, fonctionnent harmonieusement avec les *DataFrames*. Cela facilite la création de tableaux et graphiques informatifs pour l'exploration et la communication des données.
- **Exploration des données :** Les *DataFrames* rendent l'exploration des données plus simple grâce à des statistiques récapitulatives, des visualisations et d'autres méthodes d'analyse. Cela aide les analystes et les scientifiques des données à comprendre les caractéristiques des données et à identifier les tendances ou les valeurs aberrantes.
Comment créer un *DataFrame* dans R
Plusieurs méthodes permettent de créer un *DataFrame* dans R. Voici les plus courantes :
#1. Utilisation de la fonction `data.frame()`
# Chargement de la bibliothèque nécessaire, si ce n'est déjà fait
if (!require("dplyr")) {
install.packages("dplyr")
library(dplyr)
}
# Installation de la bibliothèque "dplyr"
library(dplyr)
# Définition d'une graine aléatoire pour la reproductibilité
set.seed(42)
# Création d'un échantillon de DataFrame de ventes avec des noms de produits réels
sales_data <- data.frame(
OrderID = 1001:1010,
Product = c("Ordinateur portable", "Smartphone", "Tablette", "Casque audio", "Appareil photo", "Téléviseur", "Imprimante", "Machine à laver", "Réfrigérateur", "Four à micro-ondes"),
Quantity = sample(1:10, 10, replace = TRUE),
Price = round(runif(10, 100, 2000), 2),
Discount = round(runif(10, 0, 0.3), 2),
Date = sample(seq(as.Date('2023-01-01'), as.Date('2023-01-10'), by="days"), 10)
)
# Affichage du DataFrame de ventes
print(sales_data)
Décortiquons le code :
- Il vérifie d'abord la disponibilité de la bibliothèque `dplyr`.
- Si `dplyr` n'est pas disponible, il l'installe et la charge.
- Il définit une graine aléatoire pour garantir la reproductibilité des résultats.
- Ensuite, il crée un exemple de *DataFrame* de ventes avec nos données.
- Enfin, il affiche le *DataFrame* de ventes dans la console.
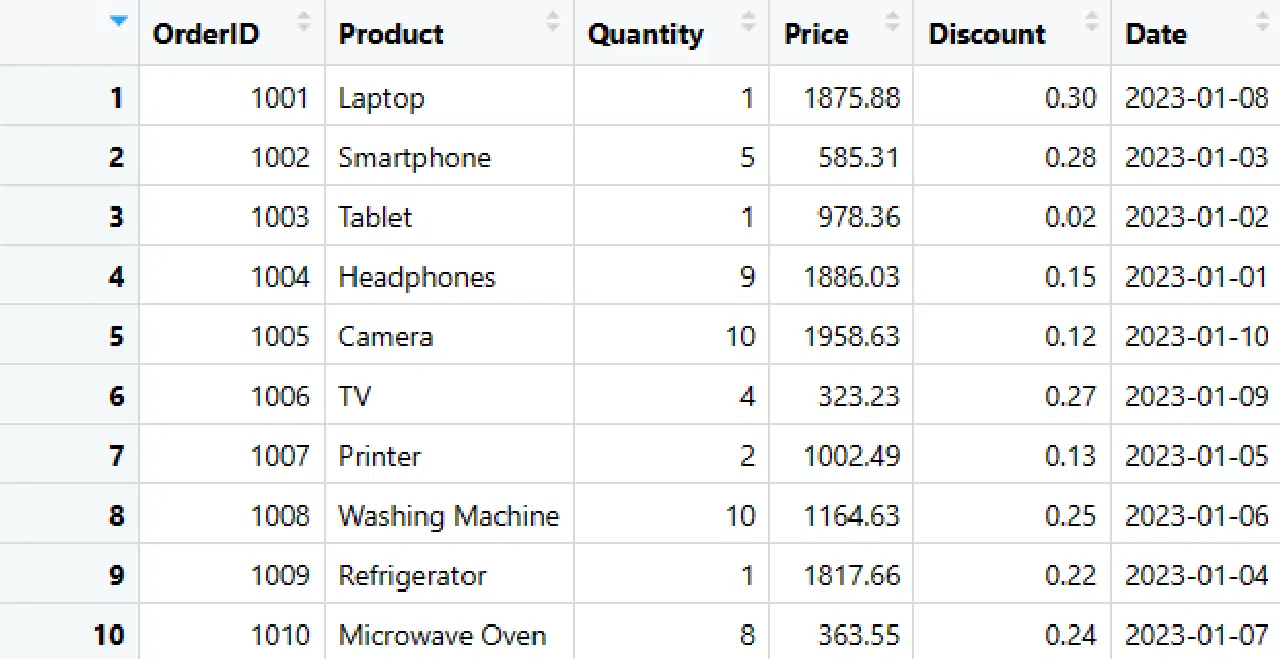 *DataFrame* des ventes
*DataFrame* des ventes
C'est l'une des méthodes les plus simples pour créer un *DataFrame* dans R. Nous allons également voir comment extraire, ajouter, supprimer et sélectionner des colonnes ou des lignes spécifiques, et comment résumer les données.
Extraire les colonnes
Il existe deux approches pour extraire des colonnes spécifiques de notre *DataFrame* :
- L'indexation permet d'extraire les trois dernières colonnes.
- L'opérateur `$` permet d'accéder aux colonnes individuelles en spécifiant leur nom.
Nous les examinerons ensemble pour gagner du temps :
# Extraction des trois dernières colonnes (Discount, Price et Date)
last_three_columns <- sales_data[, c("Discount", "Price", "Date")]
# Affichage des colonnes extraites
print(last_three_columns)
############################################# OU #########################################################
# Extraction des trois dernières colonnes (Discount, Price et Date) avec l'opérateur $
discount_column <- sales_data$Discount
price_column <- sales_data$Price
date_column <- sales_data$Date
# Création d'un nouveau DataFrame avec les colonnes extraites
last_three_columns <- data.frame(Discount = discount_column, Price = price_column, Date = date_column)
# Affichage des colonnes extraites
print(last_three_columns)
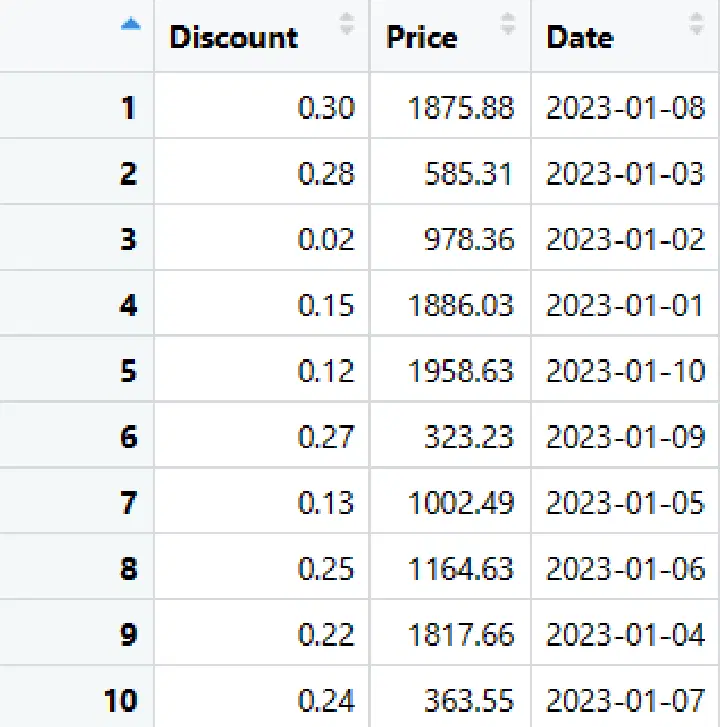
Vous pouvez extraire les colonnes avec l'une de ces méthodes.
Il existe plusieurs façons d'extraire des lignes d'un *DataFrame* dans R. Voici une méthode simple :
# Extraction de lignes spécifiques (lignes 3, 6 et 9) du DataFrame last_three_columns selected_rows <- last_three_columns[c(3, 6, 9), ] # Affichage des lignes sélectionnées print(selected_rows)
Vous pouvez également utiliser des conditions spécifiées :
# Extraction et arrangement de lignes qui répondent à des conditions selected_rows <- sales_data %>% filter(Discount < 0.3, Price > 100, format(Date, "%Y-%m") == "2023-01") %>% arrange(OrderID) %>% select(Discount, Price, Date) # Affichage des lignes sélectionnées print(selected_rows)
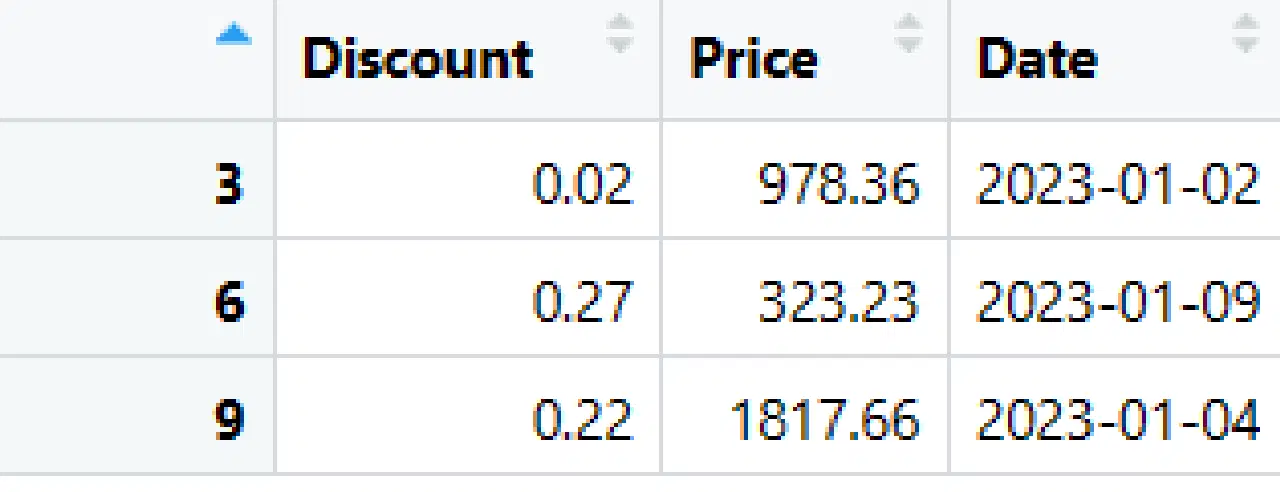 Lignes extraites
Lignes extraites
Ajouter une nouvelle ligne
Pour ajouter une nouvelle ligne à un *DataFrame* existant, on peut utiliser la fonction `rbind()` :
# Création d'une nouvelle ligne sous forme de DataFrame
new_row <- data.frame(
OrderID = 1011,
Product = "Cafetière",
Quantity = 2,
Price = 75.99,
Discount = 0.1,
Date = as.Date("2023-01-12")
)
# Utilisation de la fonction rbind() pour ajouter la nouvelle ligne
sales_data <- rbind(sales_data, new_row)
# Affichage du DataFrame mis à jour
print(sales_data)
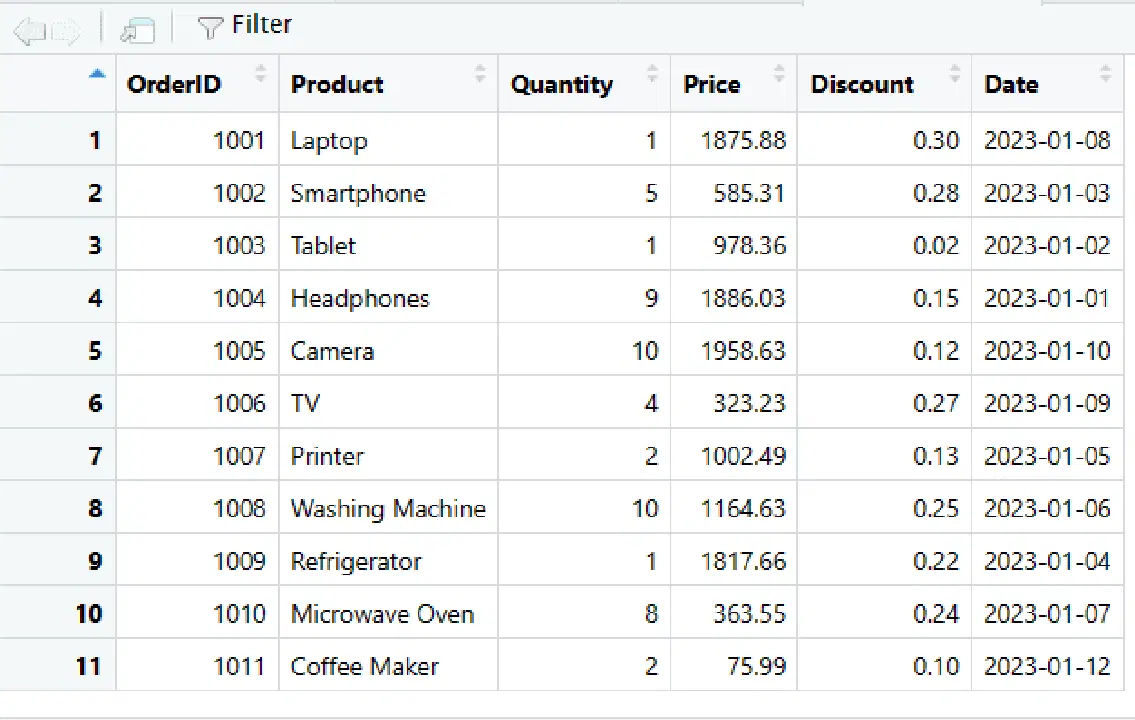 Nouvelle ligne ajoutée
Nouvelle ligne ajoutée
Ajouter une nouvelle colonne
L'ajout de colonnes à un *DataFrame* se fait avec un code simple. Ici, nous ajoutons une colonne "Mode de paiement".
# Ajout d'une colonne "PaymentMethod" avec des valeurs pour chaque ligne
sales_data$PaymentMethod <- c("Carte de crédit", "PayPal", "Espèces", "Carte de crédit", "Espèces", "PayPal", "Espèces", "Carte de crédit", "Carte de crédit", "Espèces", "Carte de crédit")
# Affichage du DataFrame mis à jour
print(sales_data)
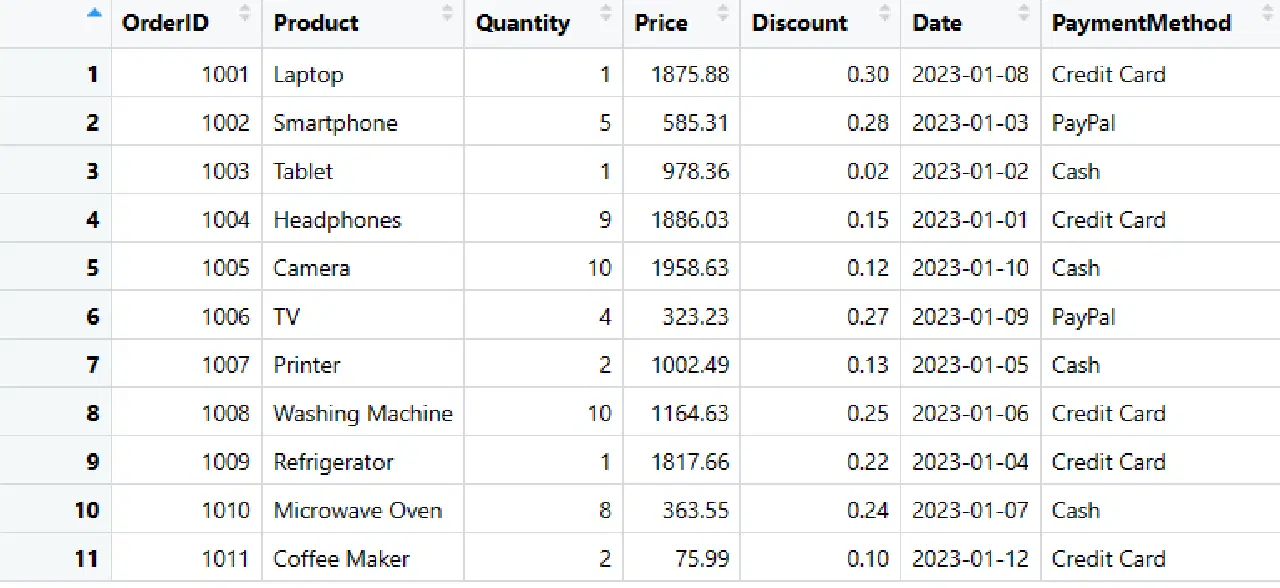 Colonne ajoutée au *DataFrame*
Colonne ajoutée au *DataFrame*
Supprimer des lignes
Si vous souhaitez supprimer des lignes spécifiques, voici une méthode :
# Identification de la ligne à supprimer grâce à son OrderID row_to_delete <- sales_data$OrderID == 1010 # Utilisation de la ligne identifiée pour l'exclure et créer un nouveau DataFrame sales_data <- sales_data[!row_to_delete, ] # Affichage du DataFrame mis à jour, sans la ligne supprimée print(sales_data)
Supprimer des colonnes
Vous pouvez supprimer une colonne d'un *DataFrame* en utilisant le package `dplyr`.
# Installation et chargement de la bibliothèque dplyr library(dplyr) # Suppression de la colonne "Discount" avec la fonction select() sales_data <- sales_data %>% select(-Discount) # Affichage du DataFrame mis à jour, sans la colonne "Discount" print(sales_data)
Obtenir le résumé
Pour obtenir un résumé de vos données dans R, utilisez la fonction `summary()`. Cette fonction fournit un aperçu rapide des tendances centrales et de la distribution des variables numériques.
# Obtention d'un résumé des données data_summary <- summary(sales_data) # Affichage du résumé print(data_summary)
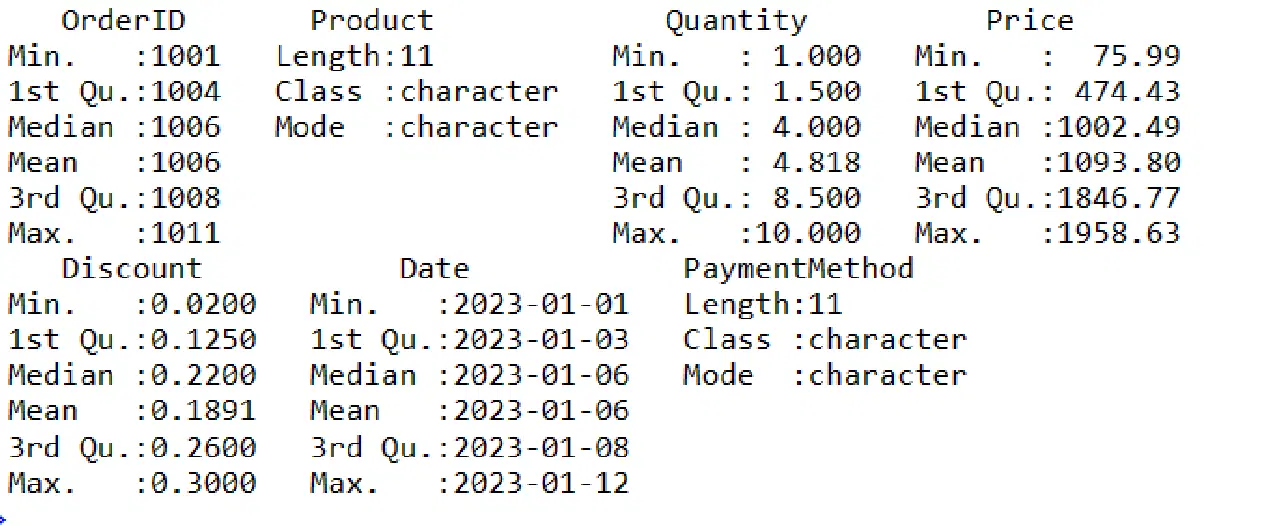
Ce sont les différentes étapes que vous pouvez suivre pour manipuler les données dans un *DataFrame*.
Passons à la deuxième méthode de création d'un *DataFrame*.
#2. Création d'un *DataFrame* R à partir d'un fichier CSV
Pour créer un *DataFrame* à partir d'un fichier CSV, vous pouvez utiliser `read.csv()`
# Lecture du fichier CSV et création d'un DataFrame
df <- read.csv("my_data.csv")
# Affichage des premières lignes du DataFrame
head(df)
Cette fonction lit les données du fichier CSV et les convertit. Vous pouvez ensuite travailler avec les données dans R.
# Installation et chargement du package readr, si ce n'est déjà fait
if (!requireNamespace("readr", quietly = TRUE)) {
install.packages("readr")
}
library(readr)
# Lecture du fichier CSV et création d'un DataFrame
df <- read_csv("data.csv")
# Affichage des premières lignes du DataFrame
head(df)
Vous pouvez utiliser le package `readr` pour lire un fichier CSV dans R. La fonction `read_csv()` de `readr` est couramment utilisée pour cela. Elle est plus rapide que la méthode habituelle.
#3. Utilisation de la fonction `as.data.frame()`
Vous pouvez créer un *DataFrame* avec `as.data.frame()`. Cette fonction permet de convertir d'autres structures de données, telles que des matrices ou des listes, en *DataFrames*.
Voici comment l'utiliser :
# Création d'une liste imbriquée pour représenter les données
data_list <- list(
OrderID = 1001:1011,
Product = c("Ordinateur portable", "Smartphone", "Tablette", "Casque audio", "Appareil photo", "Téléviseur", "Imprimante", "Machine à laver", "Réfrigérateur", "Four à micro-ondes", "Cafetière"),
Quantity = c(1, 5, 1, 9, 10, 4, 2, 10, 1, 8, 2),
Price = c(1875.88, 585.31, 978.36, 1886.03, 1958.63, 323.23, 1002.49, 1164.63, 1817.66, 363.55, 75.99),
Discount = c(0.3, 0.28, 0.02, 0.15, 0.12, 0.27, 0.13, 0.25, 0.22, 0.24, 0.1),
Date = as.Date(c("2023-01-08", "2023-01-03", "2023-01-02", "2023-01-01", "2023-01-10", "2023-01-09", "2023-01-05", "2023-01-06", "2023-01-04", "2023-01-07", "2023-01-12")),
PaymentMethod = c("Carte de crédit", "PayPal", "Espèces", "Carte de crédit", "Espèces", "PayPal", "Espèces", "Carte de crédit", "Carte de crédit", "Espèces", "Carte de crédit")
)
# Conversion de la liste imbriquée en DataFrame
sales_data <- as.data.frame(data_list)
# Affichage du DataFrame
print(sales_data)
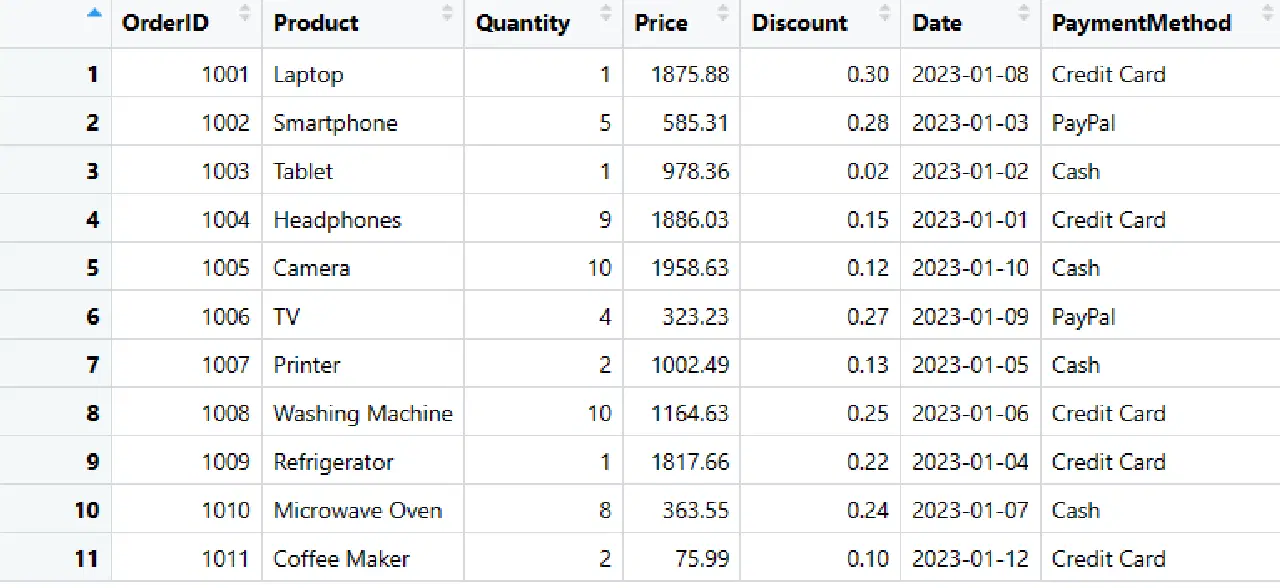 Données de ventes
Données de ventes
Cette méthode permet de créer un *DataFrame* sans spécifier chaque colonne individuellement et s'avère très pratique lorsque vous avez une grande quantité de données.
#4. À partir d'un *DataFrame* existant
Pour créer un nouveau *DataFrame* en sélectionnant des colonnes ou lignes spécifiques d'un *DataFrame* existant, utilisez les crochets `[]` pour l'indexation. Voici comment :
# Sélection de lignes et colonnes
sales_subset <- sales_data[c(1, 3, 4), c("Product", "Quantity")]
# Affichage du sous-ensemble sélectionné
print(sales_subset)
Dans ce code, nous créons un nouveau *DataFrame* appelé `sales_subset`, contenant des lignes spécifiques (1, 3 et 4) et des colonnes spécifiques ("Produit" et "Quantité") de `sales_data`.
Vous pouvez ajuster les indices et noms de lignes/colonnes pour sélectionner les données souhaitées.
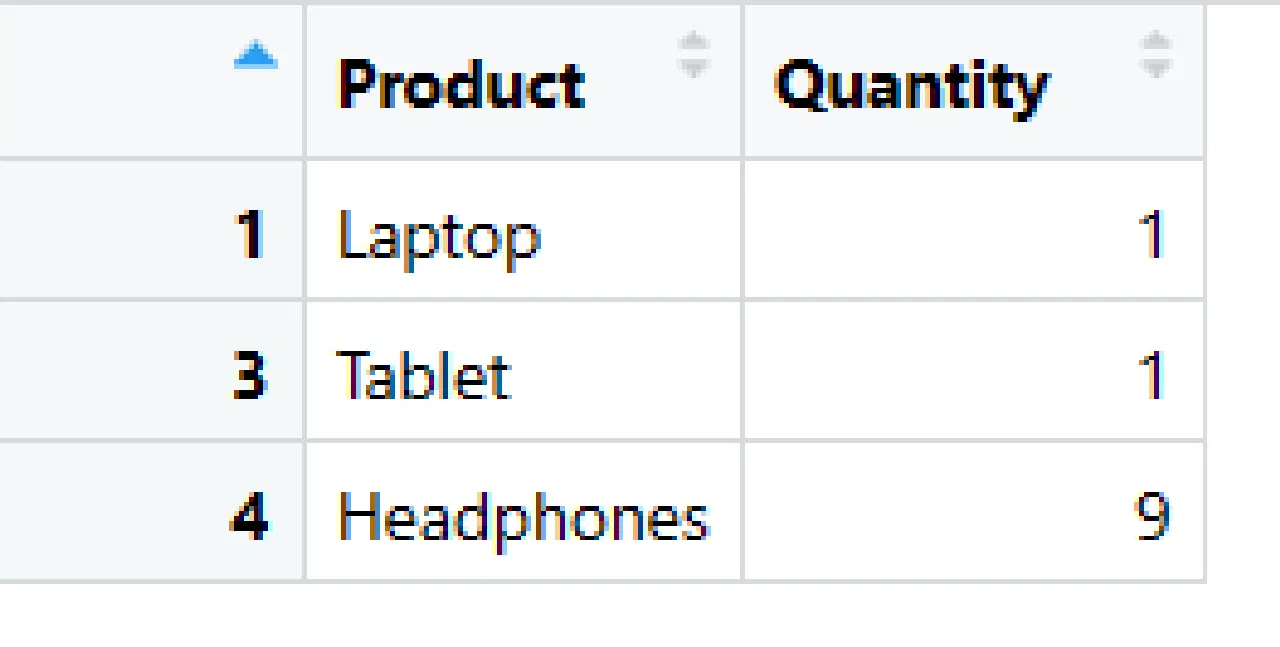 `sales_subset`
`sales_subset`
#5. À partir d'un vecteur
Un vecteur est une structure de données unidimensionnelle contenant des éléments du même type, notamment logique, entier, double, caractère, complexe ou brut.
Un *DataFrame*, quant à lui, est une structure bidimensionnelle organisée en lignes et colonnes. Plusieurs méthodes permettent de créer un *DataFrame* à partir d'un vecteur. L'exemple ci-dessous en donne une illustration.
# Création de vecteurs pour chaque colonne
OrderID <- 1001:1011
Product <- c("Ordinateur portable", "Smartphone", "Tablette", "Casque audio", "Appareil photo", "Téléviseur", "Imprimante", "Machine à laver", "Réfrigérateur", "Four à micro-ondes", "Cafetière")
Quantity <- c(1, 5, 1, 9, 10, 4, 2, 10, 1, 8, 2)
Price <- c(1875.88, 585.31, 978.36, 1886.03, 1958.63, 323.23, 1002.49, 1164.63, 1817.66, 363.55, 75.99)
Discount <- c(0.3, 0.28, 0.02, 0.15, 0.12, 0.27, 0.13, 0.25, 0.22, 0.24, 0.1)
Date <- as.Date(c("2023-01-08", "2023-01-03", "2023-01-02", "2023-01-01", "2023-01-10", "2023-01-09", "2023-01-05", "2023-01-06", "2023-01-04", "2023-01-07", "2023-01-12"))
PaymentMethod <- c("Carte de crédit", "PayPal", "Espèces", "Carte de crédit", "Espèces", "PayPal", "Espèces", "Carte de crédit", "Carte de crédit", "Espèces", "Carte de crédit")
# Création du DataFrame avec data.frame()
sales_data <- data.frame(
OrderID = OrderID,
Product = Product,
Quantity = Quantity,
Price = Price,
Discount = Discount,
Date = Date,
PaymentMethod = PaymentMethod
)
# Affichage du DataFrame
print(sales_data)
Dans ce code, nous créons des vecteurs distincts pour chaque colonne, puis utilisons `data.frame()` pour les combiner en un *DataFrame* nommé `sales_data`.
Cela permet de structurer des données tabulaires à partir de vecteurs individuels.
#6. À partir d'un fichier Excel
Pour créer un *DataFrame* en important un fichier Excel dans R, utilisez des packages tiers comme `readxl`, la version de base de R ne prenant pas en charge la lecture de fichiers Excel. La fonction `read_excel()` de ce package est utile.
# Chargement de la bibliothèque readxl library(readxl) # Définition du chemin d'accès au fichier Excel excel_file_path <- "votre_fichier.xlsx" # Remplacez par le chemin réel # Lecture du fichier Excel et création d'un DataFrame data_frame_from_excel <- read_excel(excel_file_path) # Affichage du DataFrame print(data_frame_from_excel)
Ce code lira le fichier Excel et stockera ses données dans un *DataFrame* R, pour l'utiliser dans votre environnement R.
#7. À partir d'un fichier texte
La fonction `read.table()` dans R permet d'importer un fichier texte dans un *DataFrame*. Elle requiert deux paramètres : le nom du fichier à lire et le délimiteur qui indique comment les champs sont séparés.
# Définition du nom du fichier et du délimiteur file_name <- "votre_fichier_texte.txt" # Remplacez par le nom réel delimiter <- "\t" # Remplacez par le délimiteur réel (par ex. "\t" pour tabulation, "," pour CSV) # Utilisation de read.table() pour créer un DataFrame data_frame_from_text <- read.table(file_name, header = TRUE, sep = delimiter) # Affichage du DataFrame print(data_frame_from_text)
Ce code lira le fichier texte et créera un *DataFrame* dans R, pour l'analyse des données.
#8. Utiliser Tibble
Pour le créer avec les vecteurs fournis et utiliser la bibliothèque Tidyverse, suivez ces étapes :
# Chargement de la bibliothèque tidyverse
library(tidyverse)
# Création d'un tibble avec les vecteurs fournis
sales_data <- tibble(
OrderID = 1001:1011,
Product = c("Ordinateur portable", "Smartphone", "Tablette", "Casque audio", "Appareil photo", "Téléviseur", "Imprimante", "Machine à laver", "Réfrigérateur", "Four à micro-ondes", "Cafetière"),
Quantity = c(1, 5, 1, 9, 10, 4, 2, 10, 1, 8, 2),
Price = c(1875.88, 585.31, 978.36, 1886.03, 1958.63, 323.23, 1002.49, 1164.63, 1817.66, 363.55, 75.99),
Discount = c(0.3, 0.28, 0.02, 0.15, 0.12, 0.27, 0.13, 0.25, 0.22, 0.24, 0.1),
Date = as.Date(c("2023-01-08", "2023-01-03", "2023-01-02", "2023-01-01", "2023-01-10", "2023-01-09", "2023-01-05", "2023-01-06", "2023-01-04", "2023-01-07", "2023-01-12")),
PaymentMethod = c("Carte de crédit", "PayPal", "Espèces", "Carte de crédit", "Espèces", "PayPal", "Espèces", "Carte de crédit", "Carte de crédit", "Espèces", "Carte de crédit")
)
# Affichage du tibble créé
print(sales_data)
Ce code utilise la fonction `tibble()` de la bibliothèque Tibbleverse pour créer un *DataFrame* tibble nommé `sales_data`. Le format tibble offre une représentation plus informative que le *DataFrame* par défaut.
Comment utiliser efficacement les *DataFrames* dans R
L'utilisation efficace des *DataFrames* dans R est cruciale pour la manipulation et l'analyse des données. Les *DataFrames*, structure de données fondamentale dans R, sont créés et manipulés avec la fonction `data.frame`. Voici quelques conseils :
- Avant de créer le *DataFrame*, assurez-vous que vos données sont propres et bien structurées. Supprimez les lignes/colonnes inutiles, gérez les valeurs manquantes et assurez-vous que les types de données sont corrects.
- Définissez les types de données appropriés pour vos colonnes (numérique, caractère, facteur, date). Cela optimise l'utilisation de la mémoire et la vitesse de calcul.
- Utilisez l'indexation et la sélection pour travailler avec des portions plus petites. `subset()` et les opérateurs `[]` sont utiles pour cela.
- Bien que `attach()` et `detach()` puissent être pratiques, ils peuvent créer des ambigüités et des comportements inattendus. Évitez-les.
- R est hautement optimisé pour les opérations vectorisées. Utilisez des fonctions vectorisées au lieu de boucles pour manipuler les données, si possible.
- Les boucles imbriquées peuvent être lentes dans R. Remplacez-les par des opérations vectorisées ou des fonctions comme `lapply` ou `sapply`.
- Les *DataFrames* volumineux peuvent consommer beaucoup de mémoire. Utilisez les packages `data.table` ou `dtplyr`, plus efficaces en mémoire pour les gros ensembles de données.
- R propose de nombreux packages de manipulation de données. Utilisez `dplyr`, `Tidyr` et `data.table` pour des transformations efficaces.
- Minimisez l'utilisation de variables globales, en particulier avec plusieurs *DataFrames*. Utilisez des fonctions et passez les *DataFrames* comme arguments.
- Pour agréger des données, utilisez `group_by()` et `summary()` dans `dplyr`.
- Pour les gros ensembles de données, le traitement parallèle avec des packages comme `parallel` ou `foreach` peut accélérer les opérations.
- Pour lire des données dans R, utilisez des fonctions comme `readr` ou `data.table::fread`, plus rapides que les fonctions de base comme `read.csv`.
- Pour les très gros ensembles de données, utilisez des bases de données ou des formats de stockage spécialisés comme Feather, Arrow ou Parquet.
En suivant ces bonnes pratiques, vous travaillerez plus efficacement avec les *DataFrames* dans R, rendant la manipulation et l'analyse de données plus simples et rapides.
Dernières réflexions
La création de *DataFrames* dans R est simple et différentes méthodes sont à votre disposition. J'ai souligné leur importance et abordé leur création avec la fonction `data.frame()`.
De plus, nous avons exploré les méthodes de manipulation, la création à partir de fichiers CSV et Excel, la conversion depuis d'autres structures et l'utilisation de la bibliothèque `tibble`.
Vous pourriez être intéressé par les meilleurs environnements de développement intégrés pour la programmation en R.