

Si vous avez appris quelques langages de programmation informatique, vous avez peut-être entendu le terme analyse de texte. Ceci est utilisé pour simplifier les valeurs de données complexes du fichier. L’article vous aide à savoir comment analyser le texte à l’aide de la langue. En plus de cela, si vous avez rencontré une erreur dans l’analyse du texte x, vous saurez comment corriger l’erreur d’analyse dans l’article.

Table des matières
Comment analyser le texte
Dans cet article, nous avons montré un guide complet pour analyser le texte de différentes manières et avons également brièvement présenté l’analyse de texte.
Qu’est-ce que l’analyse de texte ?
Avant de plonger pour apprendre les concepts d’analyse de texte en utilisant n’importe quel code. Il est important de connaître les bases du langage et du codage.
PNL ou traitement du langage naturel
Pour analyser le texte, le traitement du langage naturel ou NLP, qui est un sous-domaine du domaine de l’intelligence artificielle, est utilisé. Le langage Python, qui est l’un des langages appartenant à la catégorie, est utilisé pour analyser le texte.
Les codes NLP permettent aux ordinateurs de comprendre et de traiter les langages humains pour les rendre adaptés à diverses applications. Pour appliquer des techniques de ML ou d’apprentissage automatique au langage, les données textuelles non structurées doivent être converties en données tabulaires structurées. Pour terminer l’activité d’analyse, le langage Python est utilisé pour modifier les codes du programme.
Qu’est-ce que l’analyse de texte ?
L’analyse de texte signifie simplement convertir les données d’un format à un autre format. Le format dans lequel le fichier est enregistré doit être analysé ou converti en un fichier dans un format différent pour permettre à l’utilisateur de l’utiliser dans diverses applications.
- En d’autres termes, le processus consiste à analyser la chaîne ou un texte et à le convertir en composants logiques en modifiant le format du fichier.
- Certaines règles du langage Python sont utilisées pour effectuer cette tâche de programmation courante. Lors de l’analyse du texte, la série de texte donnée est décomposée en composants plus petits.
Quelles sont les raisons d’analyser le texte ?
Les raisons pour lesquelles le texte doit être parsé sont données dans cette section et c’est une connaissance pré-requise avant de savoir comment parser du texte.
- Toutes les données informatisées ne seront pas dans le même format et peuvent différer selon les diverses applications.
- Les formats de données varient pour diverses applications et un code incompatible conduirait à cette erreur.
- Il n’existe pas de programme informatique universel individuel pour sélectionner les données de tous les formats de données.
Méthode 1 : via la classe DataFrame
La classe DataFrame du langage Python possède toutes les fonctions requises pour analyser le texte. Cette bibliothèque intégrée contient les codes nécessaires pour analyser les données de n’importe quel format vers un autre format.
Brève introduction de la classe DataFrame
La classe DataFrame est une structure de données riche en fonctionnalités, qui est utilisée comme outil d’analyse de données. Il s’agit d’un puissant outil d’analyse de données qui peut être utilisé pour analyser des données avec un minimum d’effort.
- Le code est lu dans le pandas DataFrame pour effectuer l’analyse dans le langage Python.
- La classe est livrée avec de nombreux packages fournis par les pandas qui sont utilisés par les analystes de données Python.
- La caractéristique de cette classe est une abstraction, un code dans lequel la fonctionnalité interne de la fonction est cachée aux utilisateurs, de la bibliothèque NumPy. La bibliothèque NumPy est une bibliothèque python qui englobe les commandes et les fonctions permettant de travailler avec des tableaux.
- La classe DataFrame peut être utilisée pour restituer un tableau à deux dimensions avec plusieurs indices de ligne et de colonne. Ces indices aident à stocker des données multidimensionnelles et sont donc appelés MultiIndex. Ceux-ci doivent être modifiés pour savoir comment corriger l’erreur d’analyse.
Les pandas du langage Python aident à effectuer les opérations de style SQL ou de base de données avec la plus grande perfection pour éviter les erreurs dans le texte d’analyse x. Il contient également des outils IO qui aident à analyser les fichiers CSV, MS Excel, JSON, HDF5 et d’autres formats de données.
Processus d’analyse de texte à l’aide de la classe DataFrame
Pour savoir comment analyser du texte, vous pouvez utiliser le processus standard utilisant la classe DataFrame donnée dans cette section.
- Déchiffrer le format de données des données d’entrée.
- Décidez des données de sortie des données telles que CSV ou Comma Separated Value.
- Écrivez sur le code un type de données primitif comme list ou dict.
Remarque : Écrire le code sur un DataFrame vide peut être fastidieux et complexe. Les pandas permettent de créer les données sur la classe DataFrame à partir de ces types de données. Par conséquent, les données du type de données primitif peuvent être facilement analysées au format de données requis.
- Analysez les données à l’aide de l’outil d’analyse de données, pandas DataFrame, et imprimez le résultat.
Option I : format standard
La méthode standard pour formater n’importe quel fichier avec un certain format de données tel que CSV est expliquée ici.
- Enregistrez le fichier avec les valeurs de données localement sur votre PC. Par exemple, vous pouvez nommer le fichier data.txt.
- Importez le fichier dans pandas avec un nom spécifique et importez les données dans une autre variable. Par exemple, les pandas du langage sont importés dans le nom pd dans le code donné.
- L’importation doit avoir un code complet avec le détail du nom du fichier d’entrée, la fonction et le format du fichier d’entrée.
Remarque : Ici, la variable nommée res est utilisée pour effectuer la fonction de lecture des données dans le fichier data.txt en utilisant les pandas importés dans pd. Le format de données du texte d’entrée est spécifié au format CSV.
- Appelez le type de fichier nommé et analysez le texte analysé sur le résultat imprimé. Par exemple, la commande res après l’exécution de la ligne de commande aidera à imprimer le texte analysé.
Un exemple de code pour le processus expliqué ci-dessus est donné ci-dessous et aidera à comprendre comment analyser le texte.
import pandas as pd res = pd.read_csv(‘data.txt’) res
Dans ce cas, si vous saisissez les valeurs de données dans le fichier data.txt telles que [1,2,3]il serait analysé et affiché sous la forme 1 2 3.
Option II : Méthode de chaîne
Si le texte donné au code ne contient que des chaînes ou des caractères alphabétiques, les caractères spéciaux de la chaîne tels que les virgules, les espaces, etc., peuvent être utilisés pour séparer et analyser le texte. Le processus est similaire aux opérations courantes sur les chaînes internes. Pour savoir comment corriger l’erreur d’analyse, vous devez suivre le processus d’analyse du texte à l’aide de cette option expliqué ci-dessous.
- Les données sont extraites de la chaîne et tous les caractères spéciaux qui séparent le texte sont notés.
Par exemple, dans le code ci-dessous, les caractères spéciaux de la chaîne my_string, qui sont, ‘,’ et ‘:’ sont identifiés. Ce processus doit être fait avec soin pour éviter toute erreur dans le texte d’analyse x.
- Le texte de la chaîne est fractionné individuellement en fonction des valeurs et de la position des caractères spéciaux.
Par exemple, la chaîne est divisée en valeurs de données de texte en fonction des caractères spéciaux identifiés à l’aide de la commande split.
- Les valeurs de données de la chaîne sont imprimées seules en tant que texte analysé. Ici, l’instruction print est utilisée pour imprimer la valeur de données analysée du texte.
L’exemple de code pour le processus expliqué ci-dessus est donné ci-dessous.
my_string = ‘Names: Tech, computer’
sfinal = [name.strip() for name in my_string.split(‘:’)[1].split(‘,’)]
print(“Names: {}”.format(sfinal))Dans ce cas, le résultat de la chaîne analysée serait affiché comme indiqué ci-dessous.
Names: [‘Tech’, ‘computer’]
Pour obtenir une meilleure clarté et savoir comment analyser le texte tout en utilisant le texte de la chaîne, une boucle for est utilisée et le code est modifié comme suit.
my_string = ‘Names: Tech, computer’
s1 = my_string.split(‘:’)
s2 = s1[1]
s3 = s2.split(‘,’)
s4 = [name.strip() for name in s3]
for idx, item in enumerate([s1, s2, s3, s4]):
print(“Step {}: {}”.format(idx, item))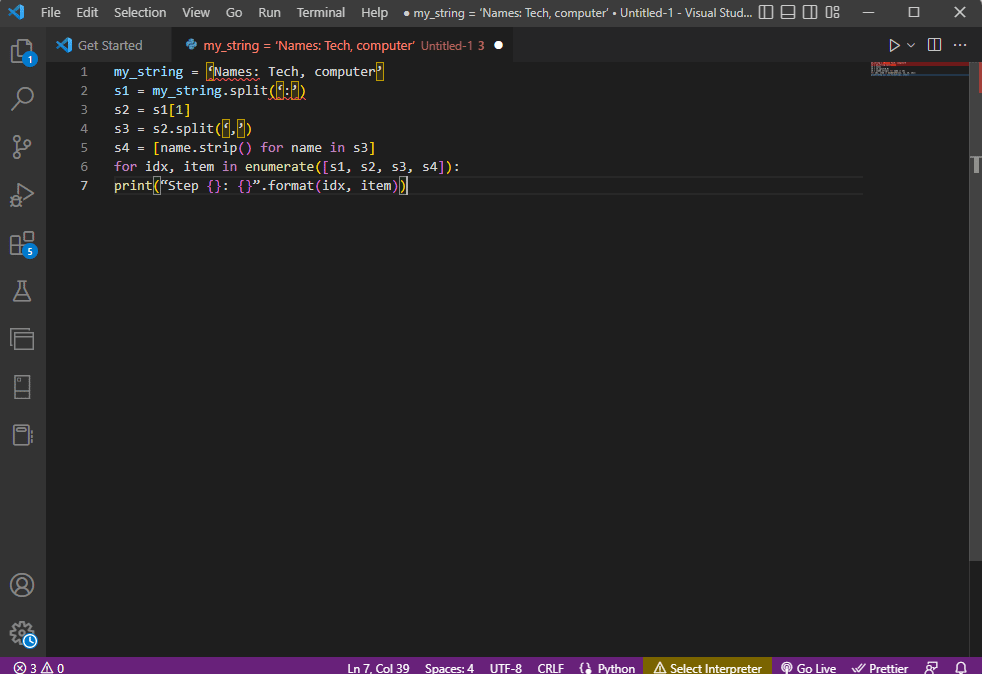
Le résultat du texte analysé pour chacune de ces étapes est affiché comme indiqué ci-dessous. Vous pouvez noter qu’à l’étape 0, la chaîne est séparée en fonction du caractère spécial : et les valeurs de données de texte sont séparées en fonction du caractère dans les étapes suivantes.
Step 0: [‘Names’, ‘Tech, computer’] Step 1: Tech, computer Step 2: [‘ Tech’, ‘ computer’] Step 3: [‘Tech’, ‘computer’]
Option 3 : Analyser un fichier complexe
Dans la plupart des cas, les données de fichier qui doivent être analysées contiennent différents types de données et valeurs de données. Dans ce cas, il peut être difficile d’analyser le fichier à l’aide des méthodes expliquées précédemment.
Les fonctionnalités d’analyse des données complexes dans le fichier consistent à afficher les valeurs de données sous forme de tableau.
- Le titre ou les métadonnées des valeurs sont imprimés en haut du fichier,
- Les variables et les champs sont imprimés dans la sortie sous forme de tableau, et
- Les valeurs de données forment une clé composée.
Avant de se plonger dans l’apprentissage de l’analyse de texte dans cette méthode, il est nécessaire d’apprendre quelques concepts de base. L’analyse des valeurs de données est effectuée sur la base d’expressions régulières ou Regex.
Modèles d’expression régulière
Pour savoir comment corriger une erreur d’analyse, vous devez vous assurer que les modèles regex dans les expressions sont corrects. Le code pour analyser les valeurs de données des chaînes impliquerait les modèles Regex courants répertoriés ci-dessous dans cette section.
‘d’ : correspond au chiffre décimal dans la chaîne,
‘s’ : correspond au caractère blanc,
‘w’ : correspond au caractère alphanumérique,
‘+’ ou ‘*’ : effectue une correspondance gourmande en faisant correspondre un ou plusieurs caractères dans les chaînes,
‘a-z’ : correspond aux groupes en minuscules dans les valeurs de données textuelles,
‘A-Z’ ou ‘a-z’ : correspond aux groupes majuscules et minuscules de la chaîne, et
‘0-9’ : correspond aux valeurs numériques.
Expressions régulières
Les modules d’expressions régulières sont une partie importante du package pandas dans le langage Python et un mauvais re peut conduire à une erreur dans l’analyse du texte x. C’est un petit langage intégré à Python pour trouver le modèle de chaîne dans l’expression. Les expressions régulières ou Regex sont des chaînes avec une syntaxe spéciale. Il permet à l’utilisateur de faire correspondre des modèles dans d’autres chaînes en fonction des valeurs des chaînes.
L’expression régulière est créée en fonction du type de données et de l’exigence de l’expression dans la chaîne, telle que ‘String = (.*)n. L’expression régulière est utilisée avant le modèle dans chaque expression. Les symboles utilisés dans les expressions régulières sont répertoriés ci-dessous et vous aideront à savoir comment analyser le texte.
. : pour récupérer n’importe quel caractère des données,
* : utilise zéro ou plusieurs données de l’expression précédente,
(.*) : pour regrouper une partie de l’expression régulière entre parenthèses,
n : Crée un nouveau caractère de ligne en fin de ligne dans le code,
d : créer une valeur intégrale courte dans la plage de 0 à 9,
+ : utilise une ou plusieurs données de l’expression précédente, et
| : créer une déclaration logique ; utilisé pour ou expressions.
RegexObjets
Le RegexObject est une valeur de retour pour la fonction de compilation et est utilisé pour retourner un MatchObject si l’expression correspond à la valeur de correspondance.
1. MatchObject
Comme la valeur booléenne de MatchObject est toujours True, vous pouvez utiliser une instruction if pour identifier les correspondances positives dans l’objet. Dans le cas de l’utilisation de l’instruction if, le groupe référencé par l’index est utilisé pour trouver la correspondance de l’objet dans l’expression.
group() renvoie un ou plusieurs sous-groupes de match,
group(0) renvoie la correspondance entière,
group(1) renvoie le premier sous-groupe entre parenthèses, et
- Tout en faisant référence à plusieurs groupes, nous devrions utiliser une extension spécifique à Python. Cette extension est utilisée pour spécifier le nom du groupe dans lequel la correspondance doit être trouvée. L’extension spécifique est fournie dans le groupe entre parenthèses. Par exemple, l’expression (?P
regex1) ferait référence au groupe spécifique avec le nom group1 et vérifierait la correspondance dans l’expression régulière, regex1. Pour savoir comment corriger une erreur d’analyse, vous devez vérifier si le groupe pointe correctement.
2. Méthodes de MatchObject
Tout en trouvant comment analyser le texte, il est important de savoir que le MatchObject a deux méthodes de base comme indiqué ci-dessous. Si le MatchObject est trouvé dans l’expression spécifiée, il renverrait son instance, sinon, il renverrait None.
- La méthode match(string) est utilisée pour trouver les correspondances de la chaîne au début de l’expression régulière, et
- La méthode search(string) est utilisée pour parcourir la chaîne afin de trouver l’emplacement d’une correspondance dans l’expression régulière.
Fonctions d’expression régulière
Les fonctions Regex sont des lignes de code utilisées pour exécuter une certaine fonction spécifiée par l’utilisateur à partir de l’ensemble de valeurs de données obtenues.
Remarque : Pour écrire les fonctions, des chaînes brutes sont utilisées pour les expressions régulières afin d’éviter les erreurs dans le texte d’analyse x. Cela se fait en ajoutant l’indice r avant chaque motif dans l’expression.
Les fonctions courantes utilisées dans les expressions sont expliquées ci-dessous.
1. re.trouver()
Cette fonction renvoie tous les motifs de la chaîne si une correspondance est trouvée et renvoie une liste vide si aucune correspondance n’est trouvée. Par exemple, la fonction string = re.findall(‘[aeiou]’, regex_filename) est utilisé pour trouver l’occurrence de voyelle dans le nom de fichier.
2. re.split()
Cette fonction est utilisée pour diviser la chaîne en cas de correspondance avec un caractère spécifié tel qu’un espace. Si aucune correspondance n’est trouvée, il renvoie une chaîne vide.
3. re.sub()
La fonction remplace le texte correspondant par le contenu de la variable de remplacement donnée. Contrairement aux autres fonctions, si aucun motif n’est trouvé, la chaîne d’origine est renvoyée.
4. recherche()
L’une des fonctions de base pour aider à apprendre à analyser le texte est la fonction de recherche. Cela aide à rechercher le modèle dans la chaîne et à renvoyer l’objet de correspondance. Si la recherche échoue à identifier la correspondance, aucune valeur n’est renvoyée.
5. recompiler (motif)
Cette fonction est utilisée pour compiler des modèles d’expressions régulières dans un RegexObject, qui a été discuté plus tôt.
Autres exigences
Les exigences répertoriées sont une fonctionnalité supplémentaire utilisée par les programmeurs avancés dans l’analyse des données.
- Pour visualiser l’expression régulière, regexper est utilisé, et
- Pour tester l’expression régulière, regex101 est utilisé.
Processus d’analyse de texte
La méthode pour analyser le texte dans cette option complexe est décrite ci-dessous.
- La première étape consiste à comprendre le format d’entrée en lisant le contenu du fichier. Par exemple, les fonctions with open et read() sont utilisées pour ouvrir et lire le contenu du fichier nommé sample. Le fichier d’exemple contient le contenu du fichier file.txt ; pour savoir comment corriger une erreur d’analyse, le fichier doit être lu complètement.
- Le contenu du fichier est imprimé pour analyser les données manuellement afin de connaître les métadonnées des valeurs. Ici, la fonction print() est utilisée pour imprimer le contenu du fichier d’exemple.
- Les packages de données requis pour analyser le texte sont importés dans le code et un nom est donné à la classe pour un codage ultérieur. Ici, les expressions régulières et les pandas sont importés.
- Les expressions régulières requises pour le code sont définies dans le fichier en incluant le modèle regex et la fonction regex. Cela permet à l’objet texte ou au corpus de prendre le code pour l’analyse des données.
- Pour savoir comment analyser du texte, vous pouvez vous référer à l’exemple de code donné ici. La fonction compile() est utilisée pour compiler la chaîne du groupe stringname1 du fichier filename. La fonction de vérification des correspondances dans la regex est utilisée par la commande ief_parse_line(line),
- L’analyseur de ligne pour le code est écrit à l’aide de def_parse_file(filepath), dans lequel la fonction définie vérifie toutes les correspondances d’expression régulière dans la fonction spécifiée. Ici, la méthode regex search() recherche la clé rx dans le fichier filename et renvoie la clé et la correspondance de la première regex correspondante. Tout problème avec l’étape peut entraîner une erreur dans l’analyse du texte x.
- L’étape suivante consiste à écrire un analyseur de fichiers à l’aide de la fonction d’analyseur de fichiers, qui est def_parse_file(filepath). Une liste vide est créée pour collecter les données du code, car data = []la correspondance est vérifiée à chaque ligne par match = _parse_line(line), et les données de valeur exactes sont renvoyées en fonction du type de données.
- Pour extraire le nombre et la valeur de la table, la ligne de commande.strip().split(‘,’) est utilisée. La commande row{} est utilisée pour créer un dictionnaire avec la ligne de données. La commande data.append(row) est utilisée pour comprendre les données et les analyser dans un format tabulaire.
La commande data = pd.DataFrame(data) est utilisée pour créer un pandas DataFrame à partir des valeurs dict. Alternativement, vous pouvez utiliser les commandes suivantes aux fins respectives, comme indiqué ci-dessous.
data.set_index([‘string’, ‘integer’]inplace=True) pour définir l’index de la Table.
data = data.groupby(level=data.index.names).first() pour consolider et supprimer les nans.
data = data.apply(pd.to_numeric, errors=’ignore’) pour mettre à niveau le score de float à valeur entière.
La dernière étape pour savoir comment analyser le texte consiste à tester l’analyseur à l’aide de l’instruction if en attribuant les valeurs à une donnée variable et en l’imprimant à l’aide de la commande print(data).
L’exemple de code pour l’explication ci-dessus est donné ici.
with open(‘file.txt’) as sample:
sample_contents = sample.read()
print(sample_contents)
import re
import pandas as pd
rx_filename = {
‘string1’: re.compile(r ‘string = (?<P<stringname1>,*)n’),
}
ief_parse_line(line):
for key, rx in rx_filename.items():
match = rx.search(line)
if match:
return key, match
return None, None
def parse_file(filepath):
data = []
with open(filepath, ‘r’) as file_object:
line = file_object.readline()
while line:
key, match = _parse_line(line)
if key == ‘string1’:
string = match.group(‘string1’)
integer = int(string1)
value_type = match.group(‘string1’)
line = file_object.readline()
while line.strip():
number, value = line.strip().split(‘,’)
value = value.strip()
row = {
‘Data1’: string1,
‘Data2’: number,
value_type: value
}
data.append(row)
line = file_object.readline()
line = file_object.readline()
data = pd.DataFrame(data)
return data
if _ _name_ _ = = ‘_ _main_ _’:
filepath = ‘sample.txt’
data = parse(filepath)
print(data)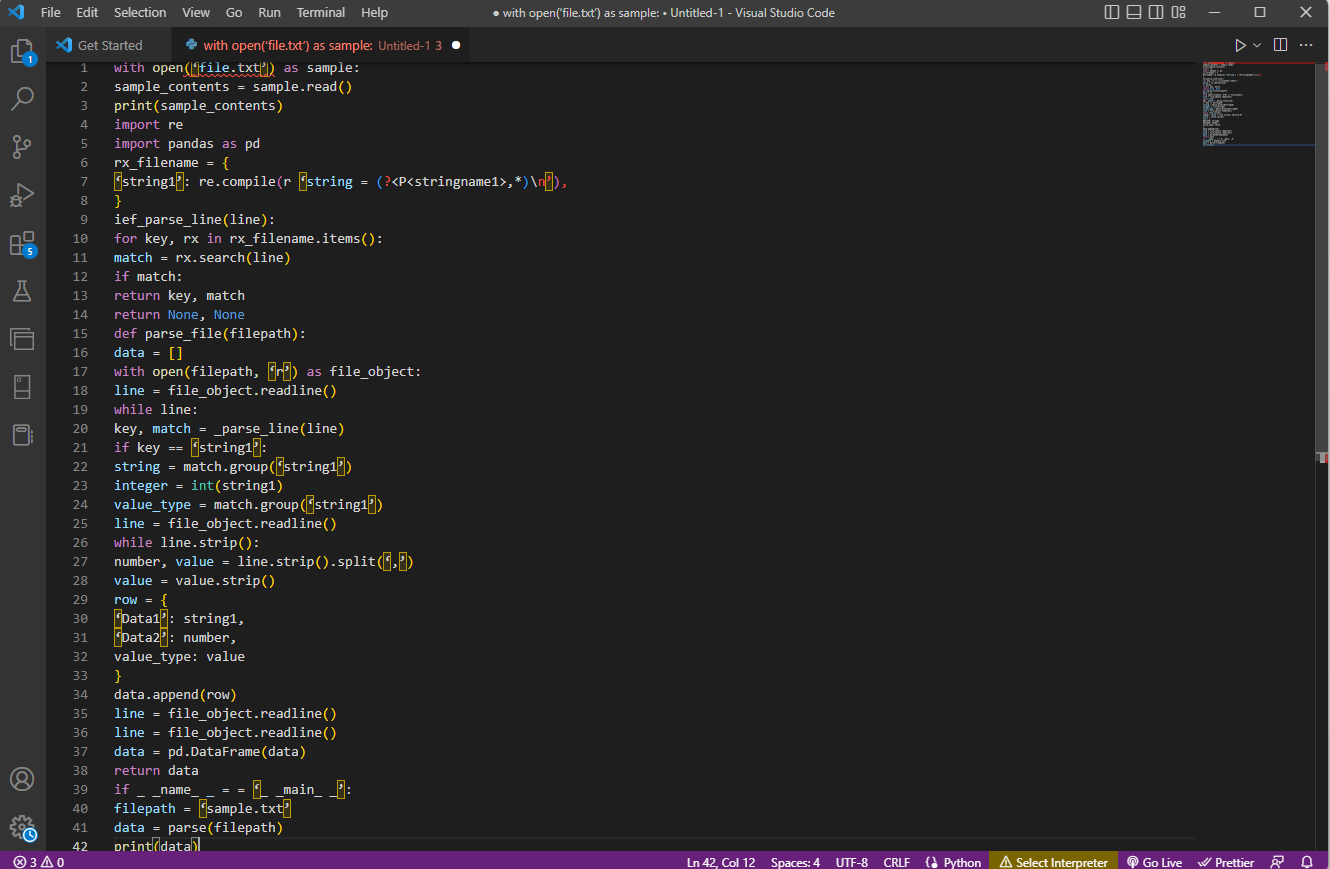
Méthode 2 : par la tokenisation de mots
Le processus de conversion d’un texte ou d’un corpus en jetons ou en morceaux plus petits en fonction de certaines règles s’appelle la tokenisation. Pour savoir comment corriger une erreur d’analyse, il est important d’analyser les commandes de tokenisation de mots dans le code. Semblable à la regex, des règles propres peuvent être créées dans cette méthode et cela aide dans les tâches de prétraitement de texte telles que le mappage de parties du discours. En outre, des activités telles que la recherche et la correspondance de mots communs, le nettoyage du texte et la préparation des données pour les techniques avancées d’analyse de texte telles que l’analyse des sentiments sont effectuées dans cette méthode. Si la tokenisation est incorrecte, une erreur dans le texte d’analyse x peut se produire.
Bibliothèque NTLK
Le processus prend l’aide de la bibliothèque de boîtes à outils linguistiques populaire appelée nltk, qui dispose d’un riche ensemble de fonctions pour effectuer de nombreuses tâches NLP. Ceux-ci peuvent être téléchargés via les packages Pip ou Pip Installs. Pour savoir comment parser du texte, vous pouvez utiliser le pack de base de la distribution Anaconda qui inclut la bibliothèque par défaut.
Formes de tokenisation
Les formes courantes de cette méthode sont la segmentation des mots et la segmentation des phrases. En raison du jeton au niveau du mot, le premier imprime un mot une seule fois, tandis que le second imprime le mot au niveau de la phrase.
Processus d’analyse de texte
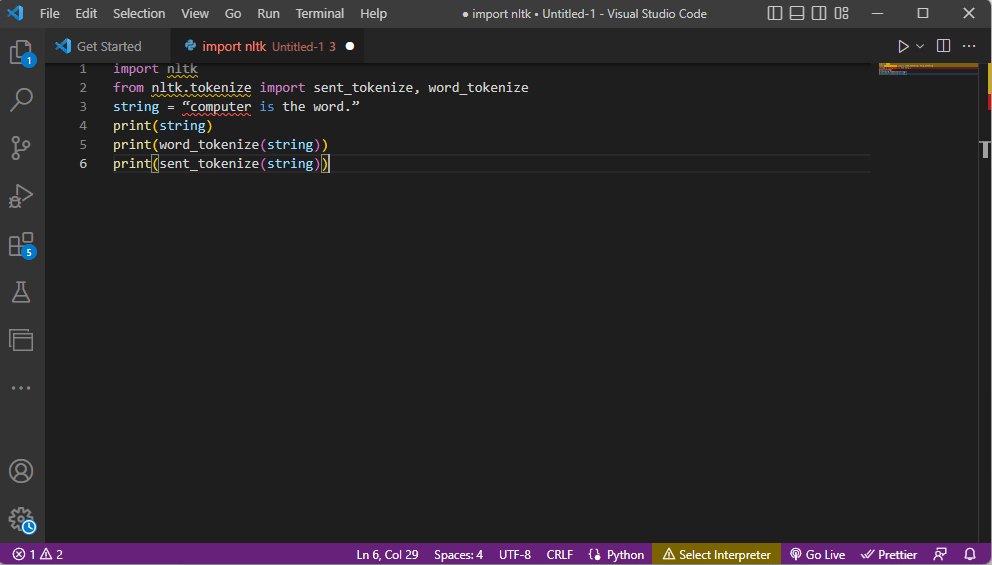
- La bibliothèque de la boîte à outils ntlk est importée et les formulaires de tokenisation sont importés de la bibliothèque.
- Une chaîne est donnée et les commandes pour effectuer la tokenisation sont données.
- Pendant que la chaîne est imprimée, la sortie serait ordinateur est le mot.
- Dans le cas de la tokenisation de mots ou de word_tokenize(), chaque mot de la phrase est imprimé individuellement entre » et est séparé par une virgule. La sortie de la commande serait ‘ordinateur’, ‘est’, ‘le’, ‘mot’, ‘.’
- Dans le cas de la tokenisation de phrases ou de sent_tokenize(), les phrases individuelles sont placées entre les » et la répétition de mots est autorisée. La sortie de la commande serait « l’ordinateur est le mot ».
Le code expliquant les étapes de la tokenisation ci-dessus est donné ici.
import nltk from nltk.tokenize import sent_tokenize, word_tokenize string = “computer is the word.” print(string) print(word_tokenize(string)) print(sent_tokenize(string))
Méthode 3 : via la classe DocParser
Semblable à la classe DataFrame, la classe DocParser peut être utilisée pour analyser le texte dans le code. La classe vous permet d’appeler la fonction d’analyse avec le chemin du fichier.
Processus d’analyse de texte
Pour savoir comment analyser du texte à l’aide de la classe DocParser, suivez les instructions ci-dessous.
- La fonction get_format(filename) est utilisée pour extraire l’extension de fichier, la renvoyer à une variable définie pour la fonction et la transmettre à la fonction suivante. Par exemple, p1 = get_format(filename) extrairait l’extension de fichier de filename, la définirait sur la variable p1 et la passerait à la fonction suivante.
- Une structure logique avec d’autres fonctions est construite à l’aide des instructions et des fonctions if-elif-else.
- Si l’extension de fichier est valide et que la structure est logique, la fonction get_parser est utilisée pour analyser les données dans le chemin du fichier et renvoyer l’objet chaîne à l’utilisateur.
Remarque : Pour savoir comment corriger une erreur d’analyse, cette fonction doit être implémentée correctement.
- L’analyse des valeurs de données est effectuée avec l’extension de fichier du fichier. L’implémentation concrète de la classe, qui sont parse_txt ou parse_docx, est utilisée pour générer des objets de chaîne à partir des parties du type de fichier donné.
- L’analyse peut être effectuée pour des fichiers d’autres extensions lisibles telles que parse_pdf, parse_html et parse_pptx.
- Les valeurs de données et l’interface peuvent être importées dans des applications avec des instructions d’importation et instancier un objet DocParser. Cela peut être fait en analysant des fichiers dans le langage Python, tels que parse_file.py. Cette opération doit être effectuée avec soin pour éviter toute erreur dans le texte d’analyse x.
Méthode 4 : via l’outil d’analyse de texte
L’outil d’analyse de texte est utilisé pour extraire des données spécifiques à partir de variables et les mapper à d’autres variables. Ceci est indépendant de tout autre outil utilisé dans une tâche et l’outil BPA Platform est utilisé pour consommer et générer des variables. Utilisez le lien indiqué ici pour accéder au Outil d’analyse de texte en ligne et utilisez les réponses données précédemment sur la façon d’analyser le texte.
Méthode 5 : via TextFieldParser (Visual Basic)
Le TextFieldParser a utilisé des objets pour analyser et traiter de très gros fichiers structurés et délimités. La largeur et la colonne de texte telles que les fichiers journaux ou les informations de base de données héritées peuvent être utilisées dans cette méthode. La méthode d’analyse est similaire à l’itération du code sur un fichier texte et est principalement utilisée pour extraire des champs de texte similaires aux méthodes de manipulation de chaînes. Ceci est fait pour marquer des chaînes délimitées et des champs de différentes largeurs en utilisant le délimiteur défini tel que la virgule ou l’espace de tabulation.
Fonctions pour analyser le texte
Les fonctions suivantes peuvent être utilisées pour analyser le texte dans cette méthode.
- Pour définir un délimiteur, SetDelimiters est utilisé. Par exemple, la commande testReader.SetDelimiters (vbTab) est utilisée pour définir l’espace de tabulation comme délimiteur.
- Pour définir une largeur de champ sur une valeur entière positive à une largeur de champ fixe de fichiers texte, vous pouvez utiliser la commande testReader.SetFieldWidths (entier).
- Pour tester le type de champ du texte, vous pouvez utiliser la commande suivante testReader.TextFieldType = Microsoft.VisualBasic.FileIO.FieldType.FixedWidth.
Méthodes pour trouver MatchObject
Il existe deux méthodes de base pour trouver le MatchObject dans le code ou le texte analysé.
- La première méthode consiste à définir le format et à parcourir le fichier à l’aide de la méthode ReadFields. Cette méthode aiderait à traiter chaque ligne du code.
- La méthode PeekChars est utilisée pour vérifier chaque champ individuellement avant de le lire, définir plusieurs formats et réagir.
Dans les deux cas, si un champ ne correspond pas au format spécifié lors de l’analyse ou de la recherche de la manière d’analyser le texte, une exception MalformedLineException est renvoyée.
Conseil de pro : Comment analyser du texte via MS Excel
Comme méthode finale et simple pour analyser le texte, vous pouvez utiliser le Microsoft Excel app en tant qu’analyseur pour créer des fichiers délimités par des tabulations et des virgules. Cela aiderait à vérifier avec votre résultat analysé et aiderait à trouver comment corriger l’erreur d’analyse.
1. Sélectionnez les valeurs de données dans le fichier source et appuyez simultanément sur les touches Ctrl + C pour copier le fichier.
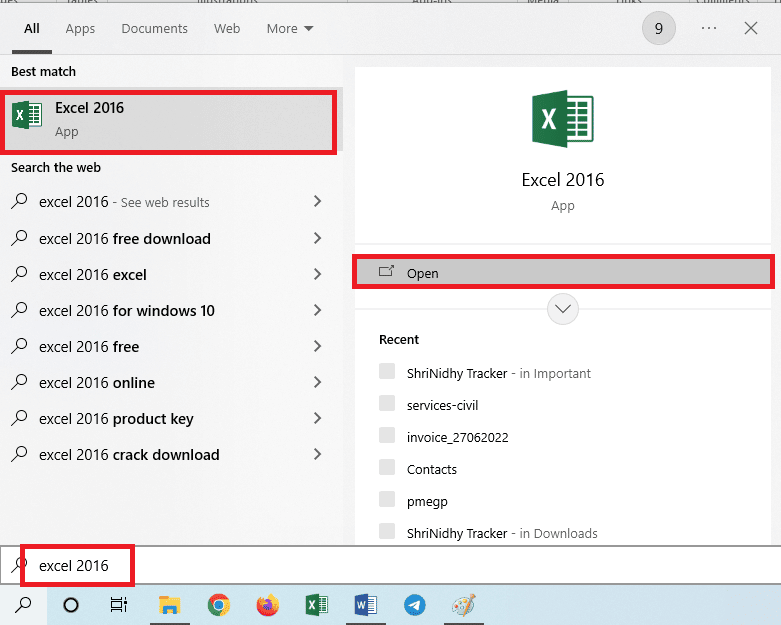
2. Ouvrez l’application Excel à l’aide de la barre de recherche Windows.
3. Cliquez sur la cellule A1 et appuyez simultanément sur les touches Ctrl + V pour coller le texte copié.
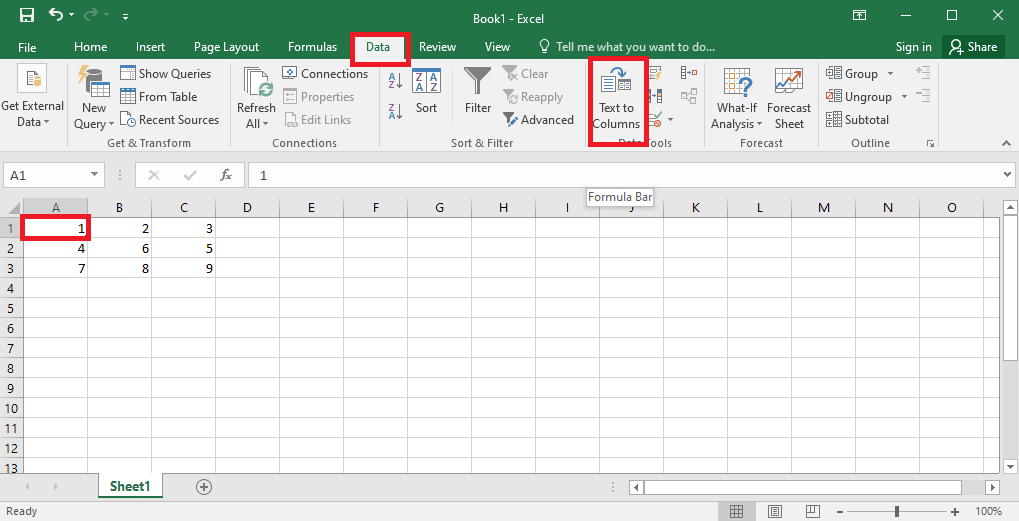
4. Sélectionnez la cellule A1, accédez à l’onglet Données et cliquez sur l’option Texte en colonnes dans la section Outils de données.
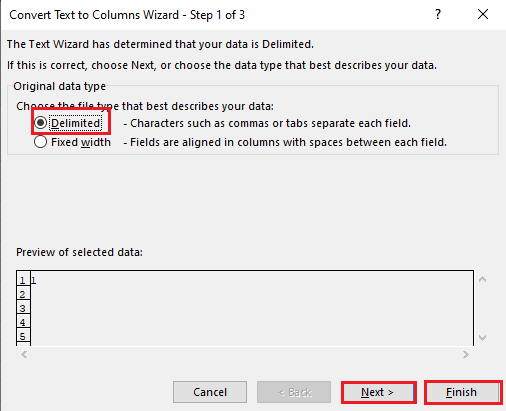
5A. Sélectionnez l’option Délimité si une virgule ou un espace de tabulation est utilisé comme séparateur, puis cliquez sur les boutons Suivant et Terminer.
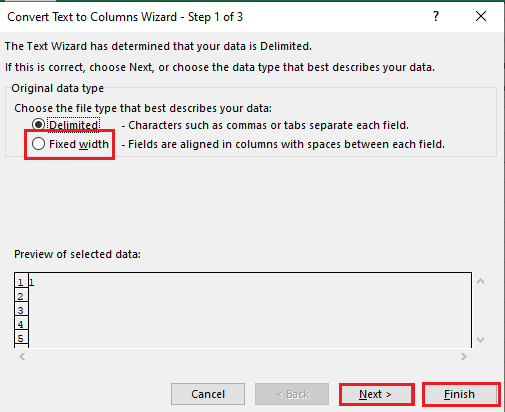
5B. Sélectionnez l’option Largeur fixe, attribuez une valeur au séparateur et cliquez sur les boutons Suivant et Terminer.
Comment réparer une erreur d’analyse
Une erreur dans le texte d’analyse x peut se produire sur les appareils Android en tant qu’erreur d’analyse : un problème est survenu lors de l’analyse du package. Cela se produit généralement lorsque l’application ne parvient pas à s’installer à partir du Google Play Store ou lors de l’exécution d’une application tierce.
Le texte d’erreur x peut apparaître si la liste des vecteurs de caractères est mise en boucle et que d’autres fonctions forment un modèle linéaire pour calculer les valeurs de données. Le message d’erreur est Error in parse(text = x, keep.source = FALSE):
Vous pouvez lire l’article sur la façon de corriger l’erreur d’analyse sur Android pour connaître les causes et les méthodes pour corriger l’erreur.
Outre les solutions du guide, vous pouvez essayer les correctifs suivants.
- Re-télécharger le fichier .apk ou restaurer le nom du fichier.
- Restauration des modifications dans le fichier Androidmanifest.xml, si vous avez des compétences en programmation de niveau expert.
***
L’article aide à apprendre à analyser le texte et à apprendre à corriger les erreurs d’analyse. Faites-nous savoir quelle méthode a aidé à corriger l’erreur dans le texte d’analyse x et quelle méthode d’analyse est préférée. Veuillez partager vos suggestions et questions dans la section des commentaires ci-dessous.