Comment améliorer votre code Python avec la concurrence et le parallélisme
Points Essentiels à Retenir
- La simultanéité et le parallélisme sont deux approches fondamentales pour l'exécution de tâches en informatique, chacune possédant des attributs distincts.
- La simultanéité permet une exploitation optimisée des ressources et une réactivité accrue des applications, tandis que le parallélisme est indispensable pour des performances maximales et une évolutivité améliorée.
- Python offre des outils pour gérer la simultanéité, comme le threading et la programmation asynchrone avec asyncio, ainsi que le parallélisme via le module `multiprocessing`.
La simultanéité et le parallélisme sont deux techniques qui permettent d'exécuter plusieurs opérations en apparence au même moment. Python propose diverses solutions pour gérer les tâches de manière concurrente et parallèle, ce qui peut parfois être source de confusion.
Découvrons les outils et bibliothèques à disposition pour implémenter correctement la simultanéité et le parallélisme en Python, et en quoi ils se distinguent.
Comprendre la Simultanéité et le Parallélisme
La simultanéité et le parallélisme font référence à deux concepts clés dans l'exécution de tâches en informatique. Chacun a ses spécificités propres.

L'Importance de la Simultanéité et du Parallélisme
L'importance de la simultanéité et du parallélisme en informatique est indéniable. Voici pourquoi ces techniques sont cruciales :
Simultanéité en Python
En Python, on peut obtenir la simultanéité en utilisant le threading et la programmation asynchrone avec la bibliothèque asyncio.
Threading en Python
Le threading est un mécanisme de simultanéité en Python qui permet de créer et de gérer des tâches à l'intérieur d'un même processus. Les threads sont adaptés à certains types de tâches, notamment celles qui sont liées aux E/S et qui peuvent bénéficier d'une exécution en simultanéité.
Le module threading de Python fournit une interface de haut niveau pour créer et gérer des threads. Bien que le GIL (Global Interpreter Lock) limite les threads en termes de vrai parallélisme, ils peuvent tout de même atteindre la simultanéité en entrelaçant les tâches de manière efficace.
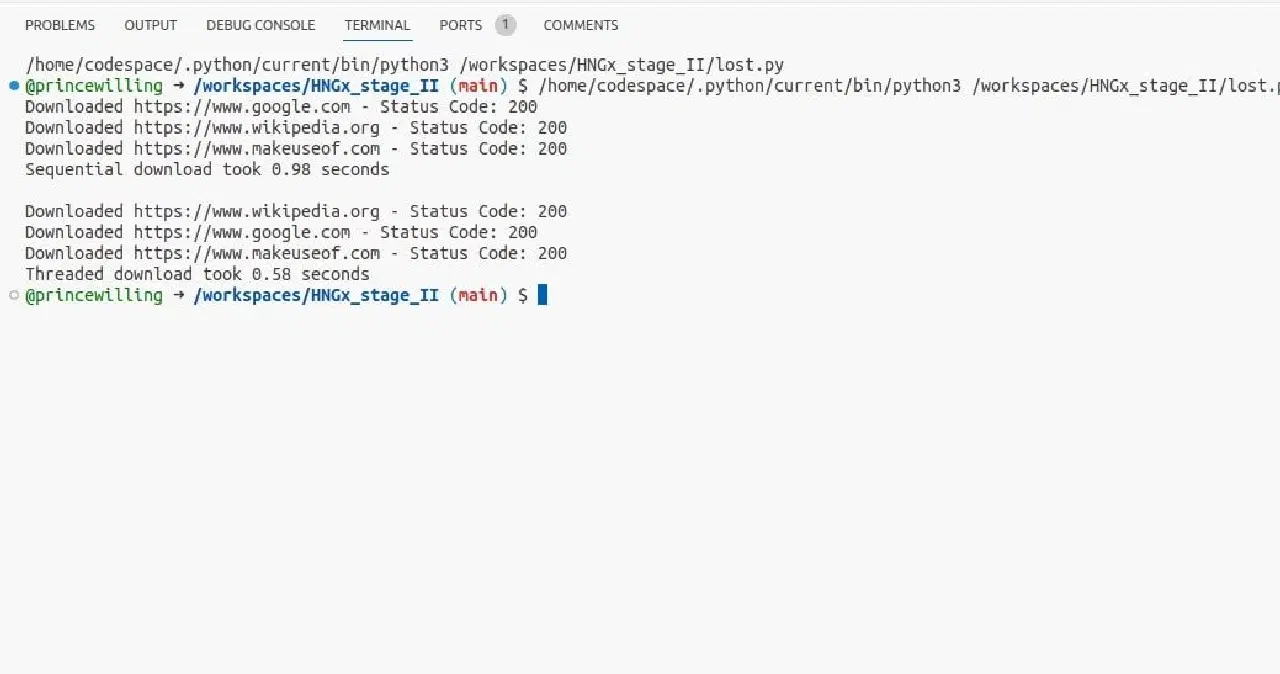
L'exemple de code ci-dessous illustre une implémentation de la simultanéité à l'aide de threads. Il emploie la bibliothèque `requests` de Python pour envoyer des requêtes HTTP, une tâche bloquante d'E/S courante. Il utilise également le module `time` pour mesurer le temps d'exécution.
import requests
import time
import threading
urls = [
'https://www.google.com',
'https://www.wikipedia.org',
'https://www.makeuseof.com',
]
def download_url(url):
response = requests.get(url)
print(f"Downloaded {url} - Status Code: {response.status_code}")
start_time = time.time()
for url in urls:
download_url(url)
end_time = time.time()
print(f"Sequential download took {end_time - start_time:.2f} seconds\n")
start_time = time.time()
threads = []
for url in urls:
thread = threading.Thread(target=download_url, args=(url,))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()
end_time = time.time()
print(f"Threaded download took {end_time - start_time:.2f} seconds")
En exécutant ce programme, vous remarquerez que les requêtes avec threads sont plus rapides que les requêtes séquentielles. Bien que la différence soit d'une fraction de seconde, vous aurez une idée précise de l'amélioration des performances lors de l'utilisation de threads pour les tâches liées aux E/S.
Programmation Asynchrone avec Asyncio
asyncio fournit une boucle d'événements qui gère les tâches asynchrones appelées coroutines. Les coroutines sont des fonctions que vous pouvez suspendre et reprendre, ce qui les rend idéales pour les tâches liées aux E/S. La bibliothèque est particulièrement utile pour les situations où les tâches impliquent l'attente de ressources externes, comme les requêtes réseau.
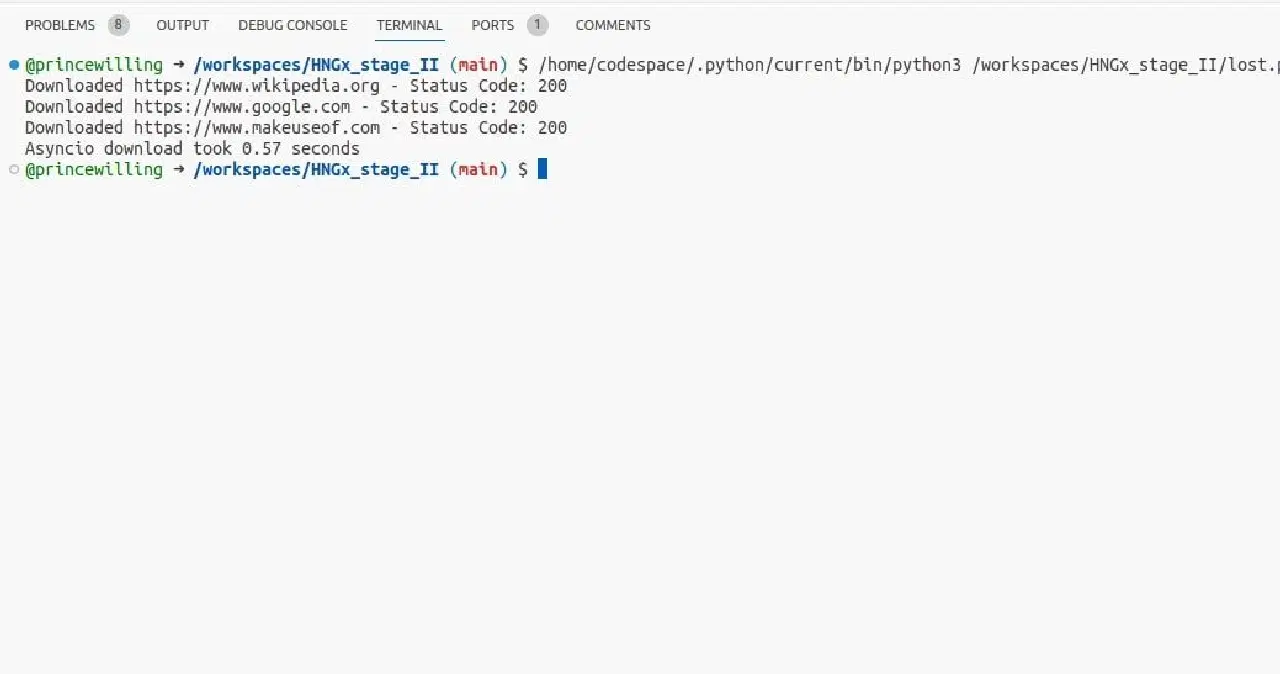
Vous pouvez modifier l'exemple d'envoi de requêtes précédent pour qu'il fonctionne avec asyncio :
import asyncio
import aiohttp
import time
urls = [
'https://www.google.com',
'https://www.wikipedia.org',
'https://www.makeuseof.com',
]
async def download_url(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
content = await response.text()
print(f"Downloaded {url} - Status Code: {response.status}")
async def main():
tasks = [download_url(url) for url in urls]
await asyncio.gather(*tasks)
start_time = time.time()
asyncio.run(main())
end_time = time.time()
print(f"Asyncio download took {end_time - start_time:.2f} seconds")
En utilisant ce code, vous pouvez télécharger des pages web simultanément en tirant parti d'asyncio et de ses opérations d'E/S asynchrones. Cela peut être plus efficace que le threading pour les tâches liées aux E/S.
Parallélisme en Python
Vous pouvez implémenter le parallélisme en utilisant le module multiprocessing de Python, qui vous permet d'exploiter pleinement les processeurs multicœurs.
Multiprocessing en Python
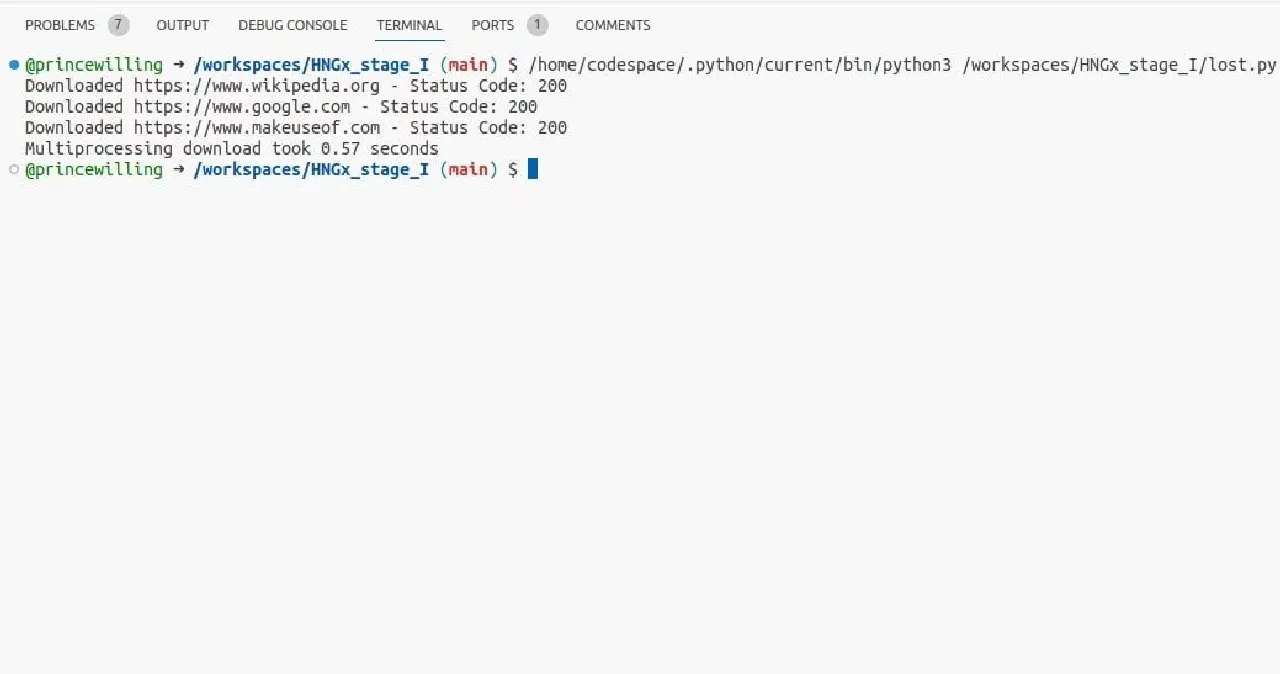
Le module multiprocessing de Python offre un moyen d'obtenir le parallélisme en créant des processus séparés, chacun avec son propre interpréteur Python et son propre espace mémoire. Cela contourne efficacement le Global Interpreter Lock (GIL), ce qui le rend adapté aux tâches gourmandes en calculs.
import requests
import multiprocessing
import time
urls = [
'https://www.google.com',
'https://www.wikipedia.org',
'https://www.makeuseof.com',
]
def download_url(url):
response = requests.get(url)
print(f"Downloaded {url} - Status Code: {response.status_code}")
def main():
num_processes = len(urls)
pool = multiprocessing.Pool(processes=num_processes)
start_time = time.time()
pool.map(download_url, urls)
end_time = time.time()
pool.close()
pool.join()
print(f"Multiprocessing download took {end_time-start_time:.2f} seconds")
main()
Dans cet exemple, le multiprocessing génère plusieurs processus, ce qui permet à la fonction `download_url` de s'exécuter en parallèle.
Quand Utiliser la Simultanéité ou le Parallélisme
Le choix entre la simultanéité et le parallélisme dépend de la nature de vos tâches et des ressources matérielles à disposition.
Vous pouvez privilégier la simultanéité lorsque vous gérez des tâches liées aux E/S, comme la lecture et l'écriture dans des fichiers ou l'exécution de requêtes réseau, et lorsque les contraintes de mémoire sont un problème.
Utilisez le multiprocessing lorsque vous avez des tâches gourmandes en calculs qui peuvent bénéficier d'un vrai parallélisme et lorsque vous disposez d'une isolation robuste entre les tâches, où l'échec d'une tâche ne doit pas impacter les autres.
Tirer Parti de la Simultanéité et du Parallélisme
Le parallélisme et la simultanéité sont des méthodes efficaces pour améliorer la réactivité et les performances de votre code Python. Il est important de comprendre les distinctions entre ces concepts et de choisir la stratégie la plus appropriée.
Python offre les outils et modules nécessaires pour rendre votre code plus efficace grâce à la simultanéité ou au parallélisme, que vous travailliez avec des opérations gourmandes en calculs ou liées aux E/S.