Les outils en ligne de commande df et du sont essentiels pour surveiller l’utilisation de l’espace disque sous Linux, macOS et d’autres systèmes d’exploitation de type Unix. Ils permettent de déterminer rapidement ce qui consomme le stockage de votre système.
Visualisation de l’espace disque : total, disponible et utilisé
Le shell Bash met à disposition deux commandes indispensables pour gérer l’espace disque. df (disk free, parfois interprété comme systèmes de fichiers de disque) donne un aperçu de l’espace disque disponible et utilisé. Pour identifier les éléments qui occupent cet espace, on utilise la commande du (disk usage).
Pour commencer, ouvrez une fenêtre de terminal Bash et tapez df puis appuyez sur Entrée. Vous obtiendrez un résultat semblable à la capture d’écran ci-dessous. Par défaut, df affiche l’espace disponible et utilisé de tous les systèmes de fichiers montés. Cette information, qui peut sembler complexe au premier abord, est assez simple à interpréter.
df
Chaque ligne du résultat se compose de six colonnes :
Filesystem : Le nom du système de fichiers.
1K-Blocks : Le nombre de blocs de 1 Ko présents sur ce système de fichiers.
Utilisé : Le nombre de blocs de 1 Ko qui sont utilisés sur ce système de fichiers.
Disponible : Le nombre de blocs de 1 Ko libres sur ce système de fichiers.
Utiliser% : Le pourcentage d’espace utilisé sur ce système de fichiers.
Fichier : Le nom du système de fichiers, s’il est indiqué directement sur la ligne de commande.
Monté sur : Le point de montage du système de fichiers.
Pour rendre l’affichage plus lisible, vous pouvez remplacer le nombre de blocs de 1 Ko par une unité de mesure plus appropriée, en utilisant l’option -B (taille de bloc). Après avoir tapé df et un espace, ajoutez -B suivi d’une lettre parmi les suivantes : K, M, G, T, P, E, Z ou Y, qui représentent respectivement kilo, méga, giga, téra, péta, exa, zetta et yotta (multiples de 1024).
Par exemple, pour afficher les tailles en mégaoctets, la commande est :
df -BM
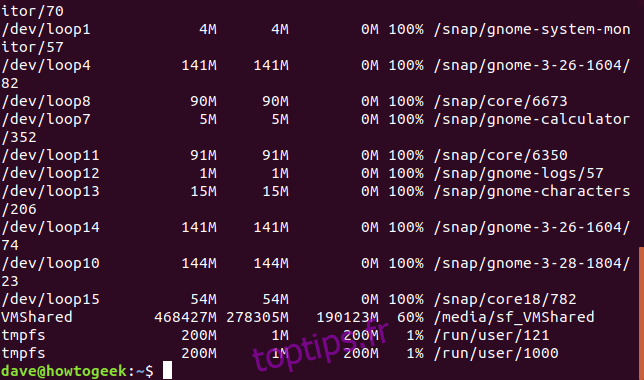
L’option -h (human-readable) permet à df d’utiliser l’unité de mesure la plus adaptée pour chaque système de fichiers. Dans l’exemple ci-dessous, on peut voir des systèmes de fichiers dont les tailles sont exprimées en gigaoctets, mégaoctets et même kilo-octets.
df -h
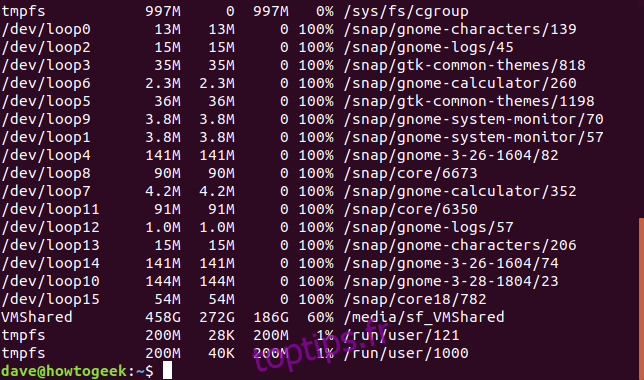
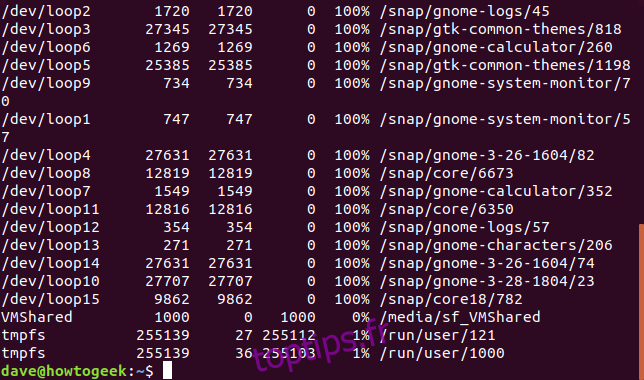
Si vous avez besoin d’informations en nombre d’inœuds, utilisez l’option -i (inodes). Un inode est une structure de données utilisée par les systèmes de fichiers Linux pour décrire les fichiers et stocker leurs métadonnées. Ces informations, comme le nom, la date de modification et la position sur le disque, sont utiles pour les administrateurs systèmes.
df -i
Par défaut, df affiche des informations pour tous les systèmes de fichiers montés. Cela peut aboutir à un affichage volumineux et parfois confus. Par exemple, les entrées /dev/loop sont des systèmes de fichiers virtuels qui permettent de monter un fichier comme s’il s’agissait d’une partition. Ces entrées, particulièrement fréquentes si vous utilisez la méthode d’installation d’applications Ubuntu Snap, occupent de l’espace, mais leur disponibilité est toujours nulle, car ils ne sont pas de véritables systèmes de fichiers. Il est donc pertinent de les exclure de l’affichage.
Pour exclure des systèmes de fichiers spécifiques, il est nécessaire de connaître leur type. L’option -T (print-type) permet d’inclure cette information dans la sortie.
df -T
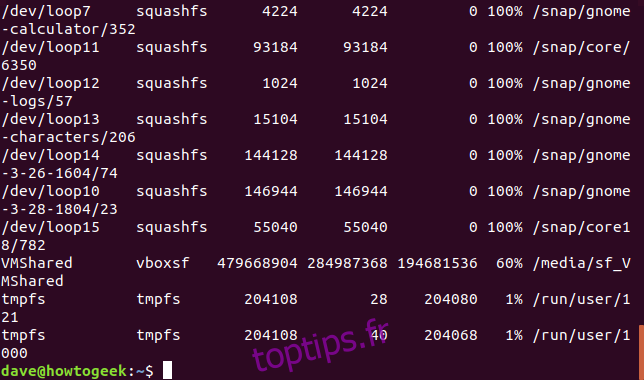
Dans notre exemple, les entrées /dev/loop sont de type squashfs. Nous pouvons les exclure en utilisant la commande suivante:
df -x squashfs
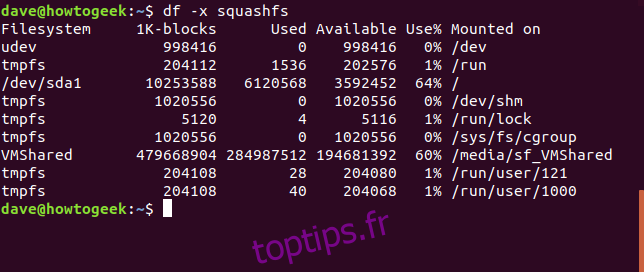
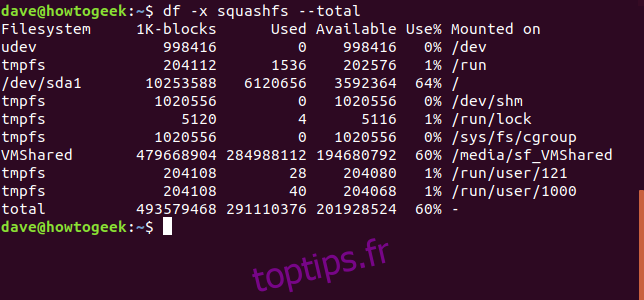
Ce qui rend l’affichage plus facile à gérer. Pour avoir un récapitulatif de l’espace disque utilisé, nous ajoutons l’option --total.
df -x squashfs --total
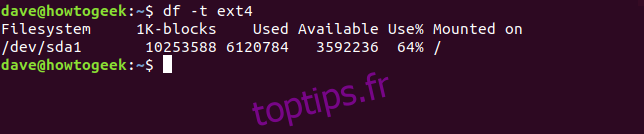
Pour n’afficher que les systèmes de fichiers d’un type spécifique, on utilise l’option -t (type).
df -t ext4
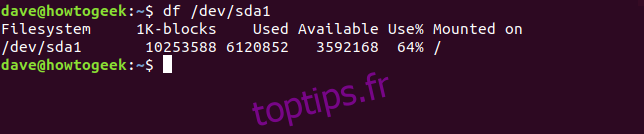
Il est aussi possible de spécifier le nom d’un système de fichiers particulier. Sous Linux, les noms des lecteurs sont alphabétiques (/dev/sda, /dev/sdb etc.), et les partitions sont numérotées (/dev/sda1 est la première partition du lecteur /dev/sda). Ainsi, pour afficher les informations de la première partition du premier disque dur :
df /dev/sda1
L’utilisation de caractères génériques permet de simplifier la recherche. Ainsi, * remplace n’importe quelle séquence de caractères et ? remplace n’importe quel caractère unique. Pour afficher les informations de toutes les partitions du premier lecteur :
df /dev/sda*
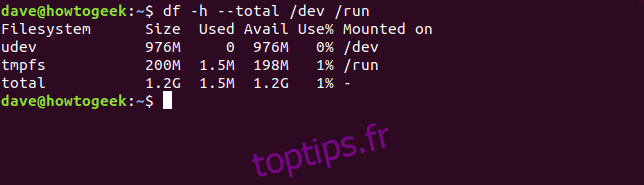
Pour afficher un rapport sur plusieurs systèmes de fichiers, il suffit de mentionner leurs noms. L’exemple ci-dessous affiche les tailles des systèmes de fichiers /dev et /run, avec un récapitulatif:
df -h --total /dev /run
L’option --output permet de personnaliser davantage l’affichage en sélectionnant les colonnes à afficher. Il est important de ne pas insérer d’espace dans la liste des noms de colonnes, qui doivent être séparés par des virgules. Les noms des colonnes sont :
source : Le nom du système de fichiers.
fstype : Le type de système de fichiers.
itotal : La taille du système de fichiers en inodes.
iused : L’espace utilisé sur le système de fichiers en inodes.
iavail : L’espace disponible sur le système de fichiers en inodes.
ipcent : Le pourcentage d’espace utilisé sur le système de fichiers en inœuds.
size : La taille du système de fichiers (par défaut, en blocs de 1K).
utilisé : L’espace utilisé sur le système de fichiers (par défaut, en blocs de 1K).
dispo : L’espace disponible sur le système de fichiers (par défaut, en blocs de 1K).
pcent : Le pourcentage d’espace utilisé sur le système de fichiers (par défaut, en blocs de 1K).
file : Le nom du système de fichiers s’il est spécifié sur la ligne de commande.
target : Le point de montage du système de fichiers.
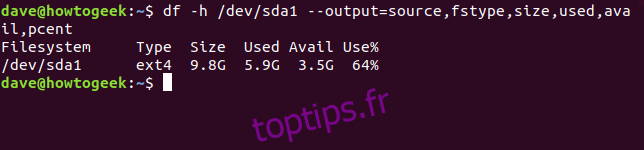
L’exemple ci-dessous montre comment obtenir les informations (source, type, taille, espace utilisé et disponible, pourcentage) de la première partition du premier disque dur, avec des unités de taille lisibles :
df -h /dev/sda1 --output=source,fstype,size,used,avail,pcent
Pour simplifier la saisie de ces commandes longues, il est possible de créer des alias. L’exemple ci-dessous crée l’alias dfc (pour df custom) qui exécutera la commande ci-dessus:
alias dfc="df -h /dev/sda1 --output=source,fstype,size,used,avail,pcent"
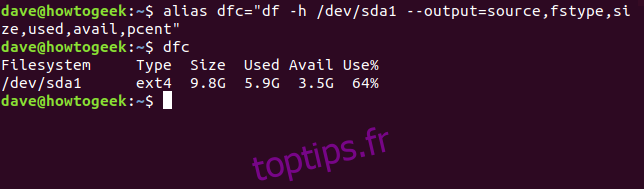
Pour utiliser l’alias, il suffit de taper dfc puis Entrée. Pour rendre cet alias permanent, il faut l’ajouter au fichier .bashrc ou .bash_aliases.
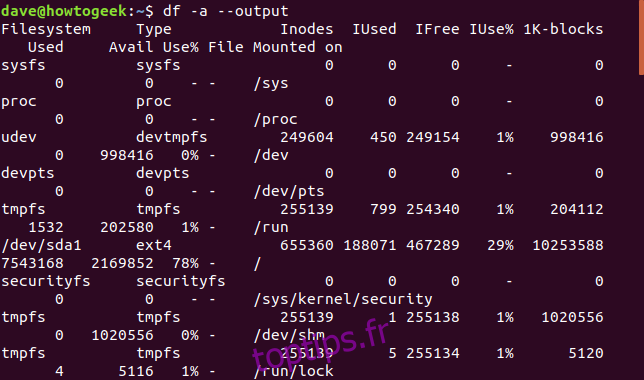
Toutes les options de df ont été détaillées ci-dessus, ce qui permet de personnaliser l’affichage des informations. Pour afficher toutes les informations, on peut utiliser l’option -a (all) combinée à l’option --output sans liste de colonnes, comme dans l’exemple ci-dessous :
df -a --output
Pour gérer la grande quantité de données générée, on peut rediriger la sortie de df vers la commande less :
df -a --output | less
Identifier ce qui consomme de l’espace disque
Il est essentiel de pouvoir localiser ce qui occupe l’espace sur votre ordinateur. En utilisant les informations retournées par df, il est possible d’identifier les partitions qui sont les plus utilisées. L’exemple ci-dessous affiche les informations sur les partitions de type ext4 :
df -h -t ext4

La première partition du premier disque dur est utilisée à 78%. Pour identifier les dossiers qui contiennent le plus de données, on utilise la commande du. Par défaut, du affiche la taille de chaque répertoire et sous-répertoire du répertoire courant. En lançant la commande à partir de votre dossier personnel, on obtient une longue liste de résultats.
du
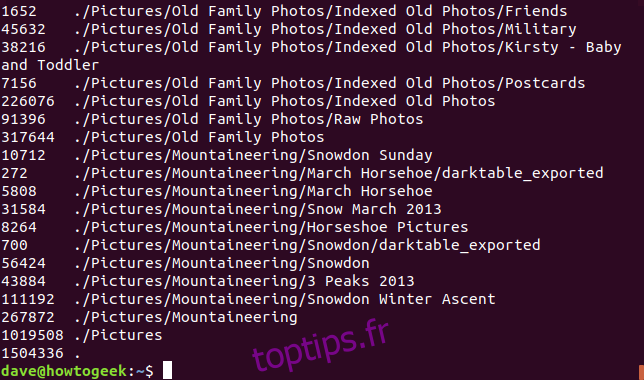
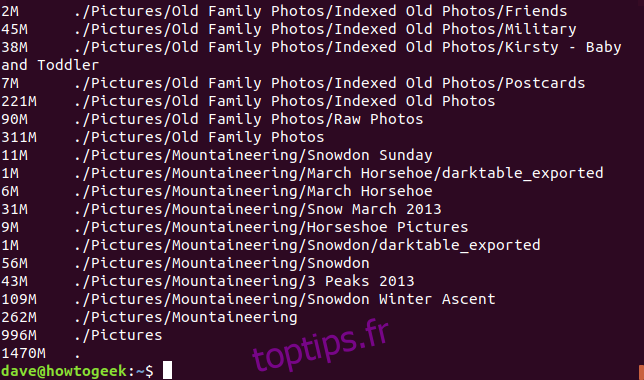
Par défaut, la taille affichée est en blocs de 1 Ko. L’option -B (taille de bloc) permet de forcer du à utiliser d’autres unités de mesure (K, M, G, T, P, E, Z et Y). L’exemple ci-dessous affiche les tailles en mégaoctets :
du -BM
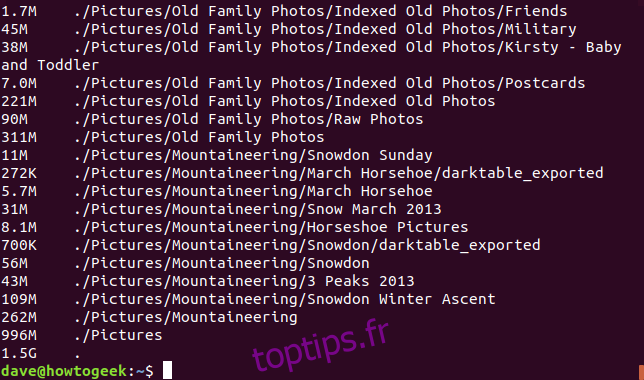
Comme pour df, l’option -h (human-readable) permet d’adapter l’unité de mesure à la taille des répertoires :
du -h
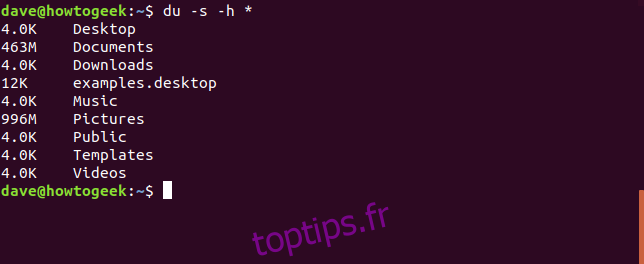
L’option -s (summary) donne un total pour chaque répertoire, sans afficher les sous-répertoires. La commande suivante affiche les tailles de tous les répertoires (avec l’option *) au format récapitulatif, et avec des unités de taille lisibles :
du -h -s *
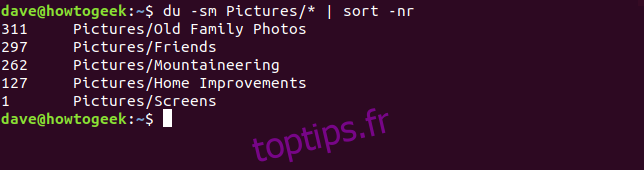
Pour identifier les dossiers qui consomment le plus d’espace, on peut trier les résultats de du du plus grand au plus petit, comme dans l’exemple ci-dessous qui analyse le dossier Pictures.
du -sm Pictures/* | sort -nr
En affinant les informations retournées par df et du, il est facile de surveiller l’utilisation de l’espace disque et d’identifier ce qui consomme cet espace. Ces informations permettent de prendre des décisions éclairées : déplacer des données vers un autre emplacement de stockage, ajouter un disque dur ou supprimer des données inutiles.
Pour connaître toutes les options de la commande df, consulter la page de manuel Linux
et la page de manuel Linux de la commande du.