Apprenez l'ingénierie des fonctionnalités pour la science des données et le ML en 5 minutes
Prêt à explorer l'art de l'ingénierie des caractéristiques pour l'apprentissage automatique et la science des données ? Vous êtes au bon endroit !
L'ingénierie des caractéristiques est une compétence indispensable pour extraire des informations pertinentes de vos données. Dans ce guide, je vais la décomposer en étapes simples et faciles à comprendre. Alors, plongeons-nous dans le sujet et commençons votre parcours vers la maîtrise de l'extraction de caractéristiques !
Qu'est-ce que l'ingénierie des caractéristiques ?
Lorsque vous développez un modèle d'apprentissage automatique pour résoudre un problème commercial ou scientifique, vous fournissez des données d'apprentissage organisées en colonnes et en lignes. En science des données et en développement ML, les colonnes sont appelées attributs ou variables.
Les données individuelles, les lignes sous ces colonnes, sont nommées observations ou instances. Les colonnes, ou attributs, représentent les entités d'un ensemble de données brut.
Ces caractéristiques brutes ne sont pas toujours suffisantes ni optimales pour entraîner un modèle ML efficace. Pour réduire le bruit des métadonnées collectées et maximiser le signal des caractéristiques, vous devez transformer ou convertir les colonnes de métadonnées en caractéristiques utilisables grâce à l'ingénierie des caractéristiques.
Exemple 1 : Modélisation financière
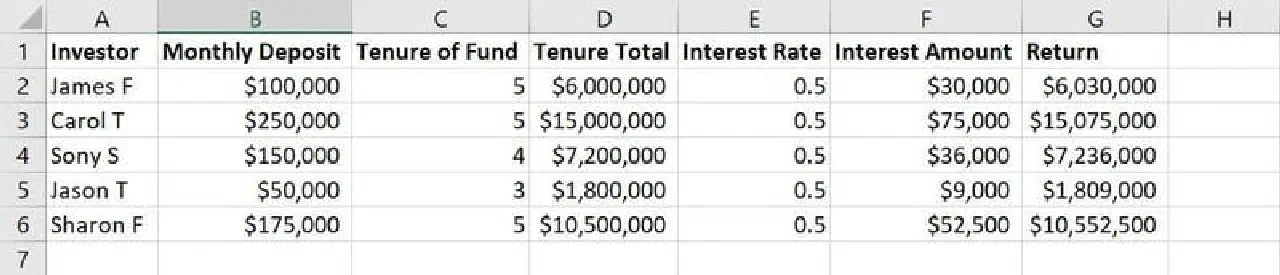
Dans l'exemple d'ensemble de données ci-dessus, les colonnes de A à G sont des entités. Les valeurs ou les chaînes de texte dans chaque colonne, comme les noms, le montant du dépôt, les années de dépôt, les taux d'intérêt, etc., sont des observations.
Lors de la modélisation ML, vous devrez potentiellement supprimer, ajouter, combiner ou transformer des données pour créer des caractéristiques significatives et réduire la taille de la base de données globale d'entraînement du modèle. C'est l'essence même de l'ingénierie des caractéristiques.
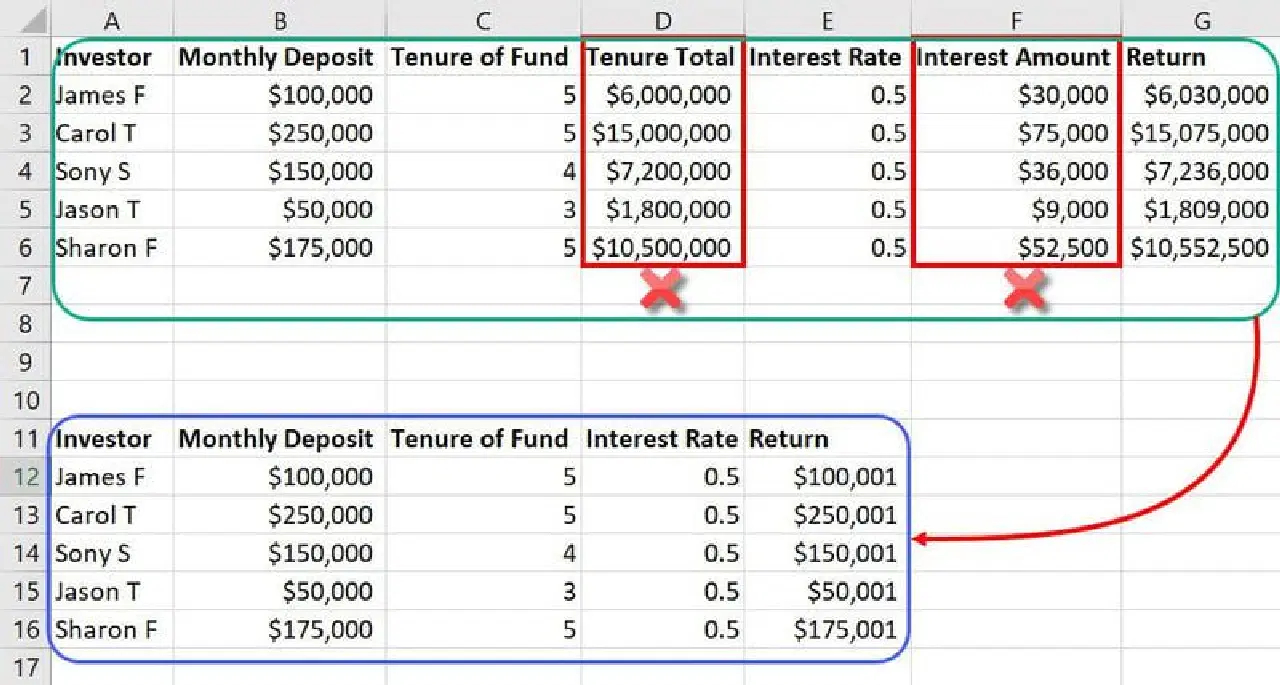
Dans le même ensemble de données, des caractéristiques comme la durée totale d'occupation et le montant des intérêts sont souvent redondantes. Elles prendraient simplement de l'espace et pourraient perturber le modèle ML. Ainsi, vous pouvez réduire deux caractéristiques sur un total de sept, améliorant ainsi l'efficacité.
Étant donné que les bases de données pour les modèles ML peuvent contenir des milliers de colonnes et des millions de lignes, la réduction de seulement deux caractéristiques a un impact non négligeable sur un projet.
Exemple 2 : Créateur de liste de lecture musicale par IA
Il est également possible de créer des caractéristiques entièrement nouvelles à partir de plusieurs caractéristiques existantes. Imaginez que vous créez un modèle d'IA pour générer automatiquement des listes de lecture musicales en fonction de l'événement, des goûts, de l'humeur, etc.
Vous avez collecté des données sur des chansons et de la musique provenant de diverses sources, créant ainsi la base de données suivante :
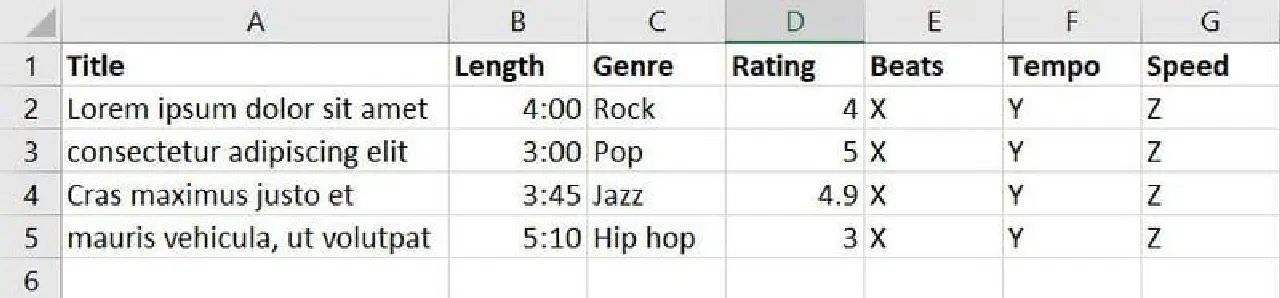
La base de données ci-dessus contient sept caractéristiques. Cependant, votre objectif étant d'entraîner un modèle ML pour décider quelle musique ou chanson convient le mieux à un événement particulier, vous pouvez regrouper des caractéristiques telles que le genre, la note, le rythme, le tempo et la vitesse dans une nouvelle caractéristique nommée Applicabilité.
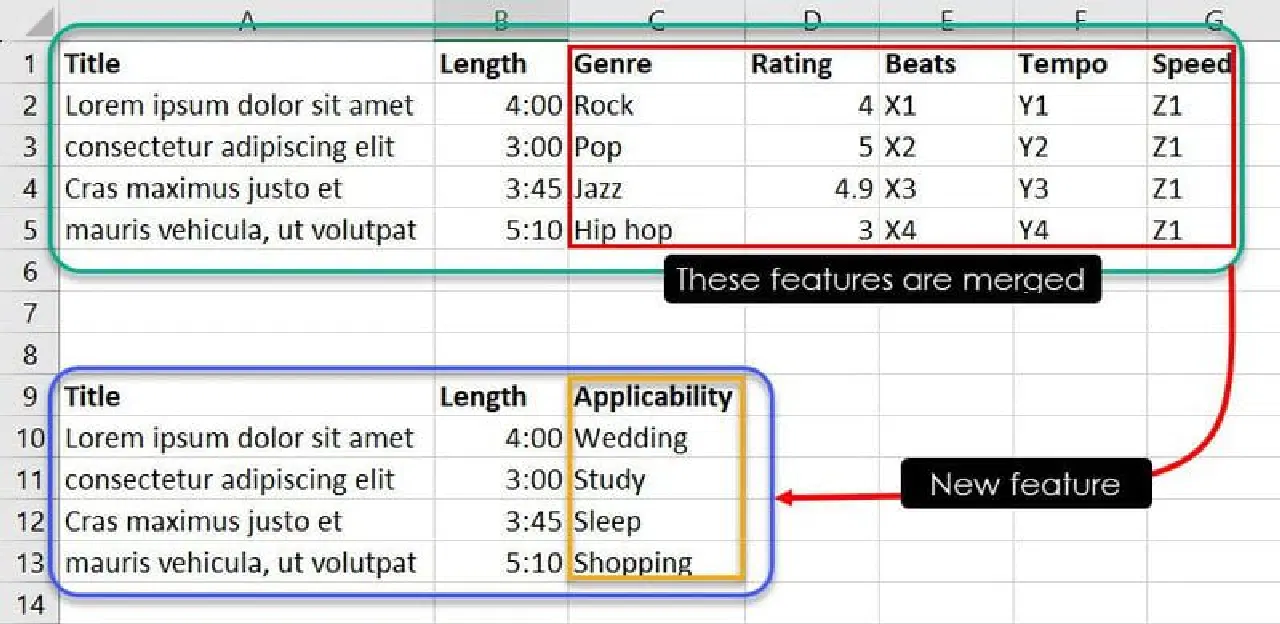
Grâce à votre expertise ou à l'identification de patterns, vous pouvez combiner certaines instances de caractéristiques pour déterminer quelle chanson correspond à quel événement. Par exemple, les observations Jazz, 4.9, X3, Y3 et Z1 pourraient indiquer au modèle ML que la chanson « Cras maximus justo » devrait figurer dans la liste de lecture d'un utilisateur recherchant une musique pour s'endormir.
Types de caractéristiques en apprentissage automatique
Caractéristiques catégorielles
Ce sont des attributs qui représentent des catégories ou des étiquettes distinctes. Elles servent à marquer des ensembles de données qualitatives.
#1. Caractéristiques catégorielles ordinales
Les caractéristiques ordinales ont des catégories avec un ordre significatif. Par exemple, les niveaux d'éducation tels que le lycée, la licence, le master, etc., ont une distinction claire dans les normes, mais sans différences quantitatives directes.
#2. Caractéristiques catégorielles nominales
Les caractéristiques nominales sont des catégories sans ordre inhérent. Des exemples seraient les couleurs, les pays ou les types d'animaux. Elles présentent uniquement des différences qualitatives.
Caractéristiques de tableaux
Ce type de caractéristique représente des données organisées en tableaux ou listes. Les data scientists et les développeurs de ML les utilisent pour gérer des séquences ou pour intégrer des données catégorielles.
#1. Intégration des caractéristiques de tableaux
L'intégration de tableaux convertit les données catégorielles en vecteurs denses. Cette technique est courante dans les systèmes de traitement du langage naturel et de recommandation.
#2. Listes de caractéristiques de tableaux
Les tableaux de listes stockent des séquences de données, comme des listes d'éléments dans un ordre particulier ou l'historique des actions.
Caractéristiques numériques
Ces caractéristiques sont utilisées pour les opérations mathématiques car elles représentent des données quantitatives.
#1. Caractéristiques numériques d'intervalle
Les caractéristiques d'intervalle ont des intervalles réguliers entre les valeurs mais n'ont pas de véritable point zéro (par exemple, les données de température). Ici, zéro signifie la température de congélation, mais la caractéristique existe toujours.
#2. Caractéristiques numériques de rapport
Les caractéristiques de rapport ont des intervalles cohérents entre les valeurs ainsi qu'un véritable point zéro. Cela comprend des exemples comme l'âge, la taille et le revenu.
Importance de l'ingénierie des caractéristiques en ML et science des données
- Une extraction efficace des caractéristiques améliore la précision du modèle, rendant les prédictions plus fiables et utiles pour la prise de décision.
- Une sélection rigoureuse des caractéristiques élimine les attributs inutiles ou redondants, simplifiant les modèles et optimisant les ressources informatiques.
- Des caractéristiques bien conçues révèlent des schémas dans les données, aidant les data scientists à comprendre les relations complexes au sein de l'ensemble de données.
- L'adaptation des caractéristiques à des algorithmes spécifiques permet d'optimiser les performances du modèle selon différentes méthodes d'apprentissage automatique.
- Des caractéristiques bien conçues permettent un entraînement plus rapide des modèles et une réduction des coûts de calcul, optimisant ainsi le workflow du ML.
Nous allons maintenant examiner le processus étape par étape de l'ingénierie des caractéristiques.
Processus d'ingénierie des caractéristiques étape par étape

- Collecte des données : la première étape consiste à collecter les données brutes à partir de différentes sources, comme les bases de données, fichiers ou API.
- Nettoyage des données : une fois les données collectées, il est nécessaire de les nettoyer en identifiant et corrigeant les erreurs, les incohérences ou les valeurs aberrantes.
- Gestion des valeurs manquantes : les valeurs manquantes peuvent fausser l'ensemble des caractéristiques du modèle ML. Les ignorer peut biaiser le modèle. Il faut donc trouver comment saisir les valeurs manquantes ou les omettre prudemment sans affecter le modèle.
- Encodage des variables catégorielles : les variables catégorielles doivent être converties en format numérique pour être utilisables par les algorithmes d'apprentissage automatique.
- Mise à l'échelle et normalisation : la mise à l'échelle garantit que les caractéristiques numériques sont sur une échelle cohérente, empêchant ainsi les caractéristiques avec des valeurs élevées de dominer le modèle.
- Sélection des caractéristiques : cette étape permet d'identifier et de conserver les caractéristiques les plus pertinentes, réduisant ainsi la dimensionnalité et améliorant l'efficacité du modèle.
- Création de caractéristiques : de nouvelles caractéristiques peuvent être créées à partir de caractéristiques existantes pour capturer des informations précieuses.
- Transformation des caractéristiques : des techniques comme les transformations logarithmiques ou de puissance peuvent rendre les données plus adaptées à la modélisation.
Nous allons maintenant parler des méthodes d'ingénierie des caractéristiques.
Méthodes d'ingénierie des caractéristiques
#1. Analyse en composantes principales (ACP)
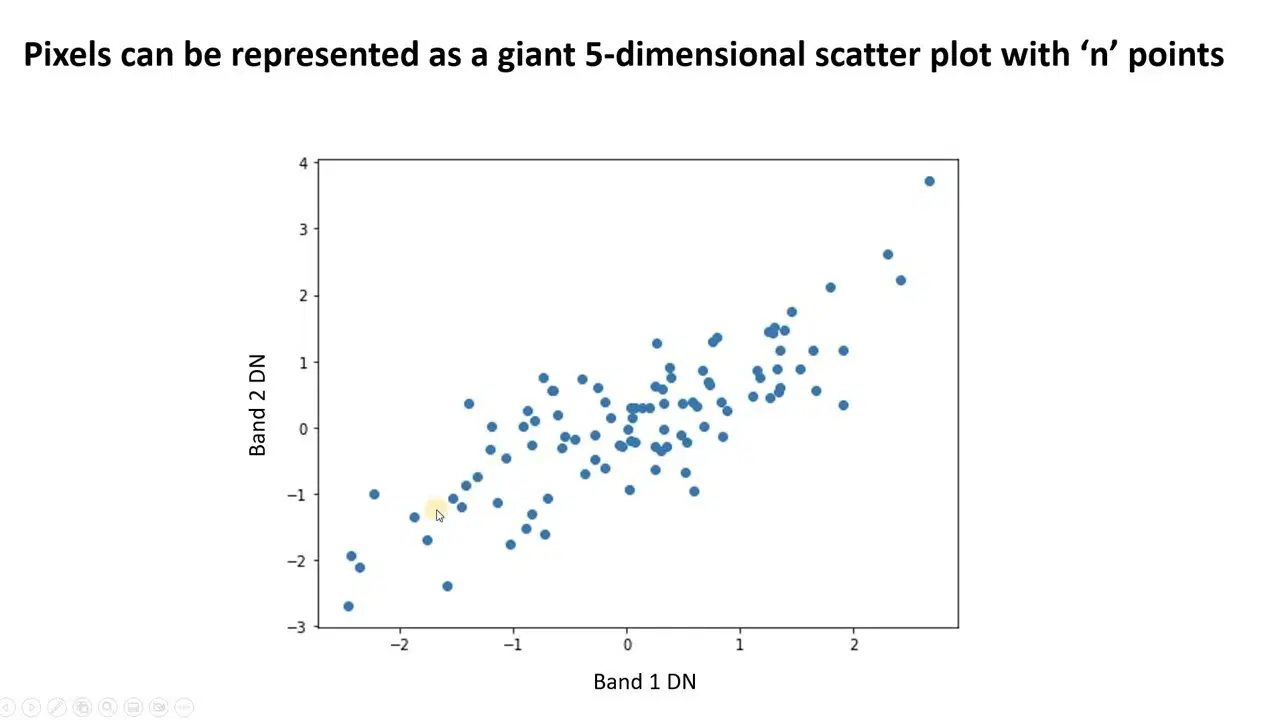
L'ACP simplifie les données complexes en trouvant de nouvelles caractéristiques non corrélées. Ces caractéristiques sont appelées composantes principales. Elles permettent de réduire la dimensionnalité et d'améliorer les performances du modèle.
#2. Caractéristiques polynomiales
La création de caractéristiques polynomiales ajoute des puissances des caractéristiques existantes pour capturer les relations complexes dans les données. Cela permet au modèle de comprendre les modèles non linéaires.
#3. Gestion des valeurs aberrantes
Les valeurs aberrantes sont des points de données inhabituels qui peuvent affecter les performances des modèles. Il est nécessaire de les identifier et de les gérer pour éviter de fausser les résultats.
#4. Transformation logarithmique
La transformation logarithmique peut aider à normaliser les données ayant une distribution asymétrique. Elle réduit l'impact des valeurs extrêmes et rend les données plus appropriées à la modélisation.
#5. Intégration de voisin stochastique distribué t (t-SNE)
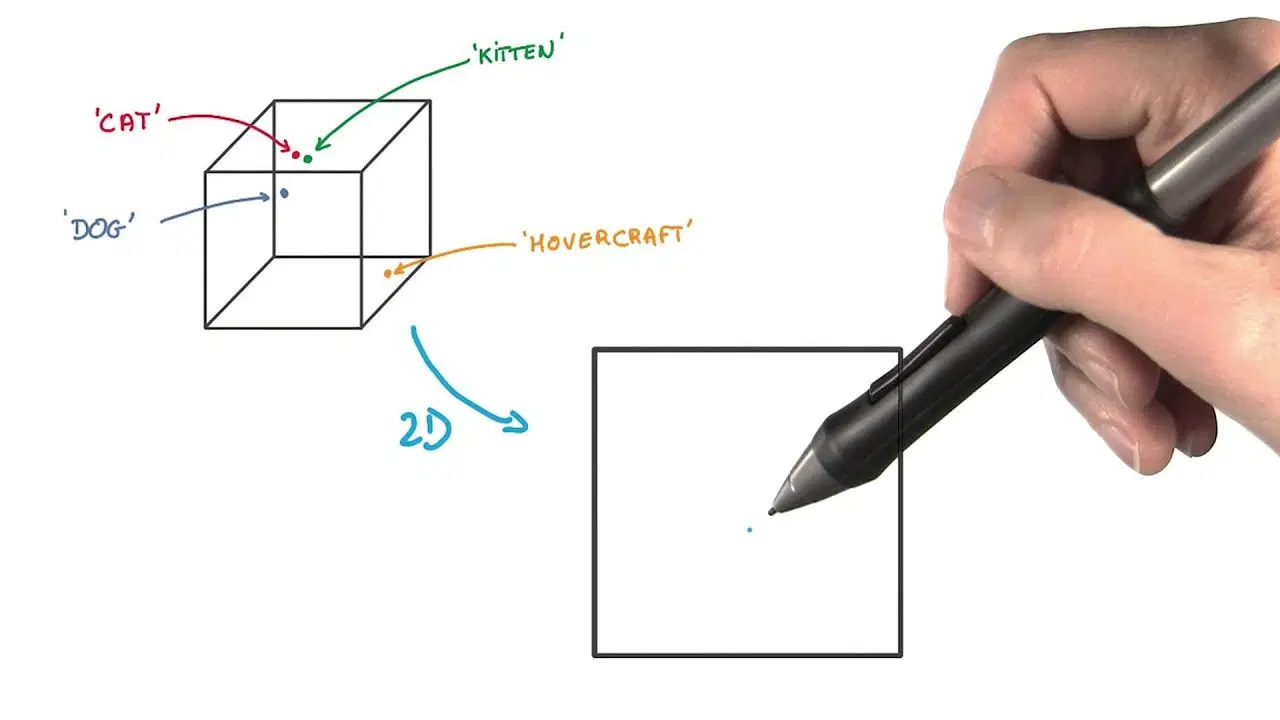
Le t-SNE est utile pour visualiser des données de grande dimension. Il réduit la dimensionnalité et rend les clusters plus apparents tout en préservant la structure des données.
Avec cette méthode, vous représentez les points de données sous forme de points dans un espace de dimension inférieure. Ensuite, les points similaires dans l'espace de grande dimension d'origine sont modélisés pour être proches les uns des autres dans la représentation de dimension inférieure.
Cette approche se distingue des autres méthodes de réduction de dimensionnalité en conservant la structure et les distances entre les points de données.
#6. Encodage one-hot
L'encodage one-hot transforme les variables catégorielles en format binaire (0 ou 1), en créant de nouvelles colonnes binaires pour chaque catégorie. Cela rend les données catégorielles utilisables pour les algorithmes ML.
#7. Encodage de comptage
L'encodage de comptage remplace les valeurs catégorielles par le nombre de fois où elles apparaissent dans l'ensemble de données, permettant ainsi de capturer des informations utiles à partir de ces variables.
Avec cette technique, vous utilisez la fréquence ou le nombre d'occurrences de chaque catégorie comme une nouvelle caractéristique numérique, au lieu des étiquettes de catégorie d'origine.
#8. Standardisation des caractéristiques

Les caractéristiques avec des valeurs plus élevées ont tendance à dominer les caractéristiques avec des valeurs plus petites, ce qui peut biaiser le modèle ML. La normalisation permet d'éviter de tels problèmes dans les modèles d'apprentissage automatique.
La normalisation implique généralement les deux techniques suivantes :
- Standardisation du score Z : cette méthode transforme chaque caractéristique de sorte qu'elle ait une moyenne de 0 et un écart type de 1. Vous soustrayez la moyenne de la caractéristique de chaque point de données et divisez le résultat par l'écart type.
- Mise à l'échelle Min-Max : elle transforme les données dans une plage spécifique, généralement entre 0 et 1. Vous y parvenez en soustrayant la valeur minimale de la caractéristique de chaque point de données et en divisant le résultat par la plage.
#9. Normalisation
La normalisation met à l'échelle les caractéristiques numériques selon une plage commune, généralement entre 0 et 1. Cela maintient les différences relatives entre les valeurs et assure que toutes les caractéristiques sont sur un pied d'égalité.

#1. Outils de caractéristiques
Outils de caractéristiques est un framework Python open source qui crée automatiquement des caractéristiques à partir d'ensembles de données temporelles et relationnelles. Il peut être utilisé avec des outils que vous utilisez déjà pour développer des pipelines ML.
La solution utilise Deep Feature Synthesis pour automatiser l'ingénierie des caractéristiques. Elle possède une bibliothèque de fonctions de bas niveau pour la création de caractéristiques. Featuretools a également une API, idéale pour la gestion précise du temps.
#2. ChatBoost
Si vous cherchez une bibliothèque open source combinant plusieurs arbres de décision pour créer un modèle prédictif puissant, optez pour ChatBoost. Cette solution offre des résultats précis avec des paramètres par défaut, vous évitant de longues heures d'affinage des paramètres.
CatBoost permet aussi d'utiliser des facteurs non numériques pour améliorer les résultats de l'entraînement. Vous pouvez également vous attendre à des résultats plus précis et à des prédictions rapides.
#3. Moteur de caractéristiques
Moteur de caractéristiques est une bibliothèque Python proposant plusieurs transformateurs et fonctions utilisables pour les modèles ML. Les transformateurs permettent la transformation de variables, la création de variables, la gestion des caractéristiques de date et d'heure, le prétraitement, le codage catégoriel, la gestion des valeurs aberrantes et l'imputation des données manquantes. Il est capable de reconnaître automatiquement les variables numériques, catégorielles et de date/heure.
Ressources d'apprentissage pour l'ingénierie des caractéristiques
Cours en ligne et classes virtuelles

#1. Ingénierie des caractéristiques pour l'apprentissage automatique en Python : Datacamp
Ce cours de Datacamp sur l'ingénierie des caractéristiques pour l'apprentissage automatique en Python vous apprend à créer de nouvelles caractéristiques améliorant les performances de vos modèles d'apprentissage automatique. Vous apprendrez à réaliser l'ingénierie des caractéristiques et la fusion des données pour développer des applications ML sophistiquées.
#2. Ingénierie des caractéristiques pour l'apprentissage automatique : Udemy
Le cours Udemy sur l'ingénierie des caractéristiques pour l'apprentissage automatique vous enseignera des sujets comme l'imputation, le codage des variables, l'extraction de caractéristiques, la discrétisation, les caractéristiques de date/heure, les valeurs aberrantes et plus encore. Vous apprendrez aussi à travailler avec des variables asymétriques et à gérer les catégories peu fréquentes, invisibles ou rares.
#3. Ingénierie des caractéristiques : Pluralsight
Ce parcours d'apprentissage Pluralsight comprend six cours au total. Ils vous aideront à découvrir l'importance de l'ingénierie des caractéristiques dans le workflow du ML, les moyens d'appliquer ses techniques, et l'extraction de caractéristiques à partir de texte et d'images.
#4. Sélection de caractéristiques pour l'apprentissage automatique : Udemy
Avec ce cours Udemy, vous apprendrez le brassage de caractéristiques, les méthodes de filtrage, d'encapsulation et intégrées, l'élimination récursive de caractéristiques et la recherche exhaustive. Il aborde également les techniques de sélection de caractéristiques avec Python, Lasso et les arbres de décision. Ce cours contient 5,5 heures de vidéo à la demande et 22 articles.
#5. Ingénierie des caractéristiques pour l'apprentissage automatique : Great Learning
Ce cours de Great Learning vous initiera à l'ingénierie des caractéristiques tout en vous apprenant le suréchantillonnage et le sous-échantillonnage. Vous aurez également la possibilité d'effectuer des exercices pratiques sur le réglage du modèle.
#6. Ingénierie des caractéristiques : Coursera
Rejoignez le cours Coursera pour utiliser BigQuery ML, Keras et TensorFlow pour réaliser l'ingénierie des caractéristiques. Ce cours de niveau intermédiaire couvre également les pratiques avancées d'ingénierie des caractéristiques.
Livres numériques ou brochés

#1. Ingénierie des caractéristiques pour l'apprentissage automatique
Ce livre vous apprend à transformer les caractéristiques en formats adaptés aux modèles d'apprentissage automatique.
Il vous enseigne aussi les principes de l'ingénierie des caractéristiques et leur application pratique grâce à des exercices.
#2. Ingénierie et sélection de caractéristiques
La lecture de ce livre vous permettra d'apprendre les méthodes de développement de modèles prédictifs à différents stades.
Vous apprendrez aussi des techniques pour trouver les meilleures représentations des prédicteurs pour la modélisation.
#3. L'ingénierie des caractéristiques simplifiée
Ce livre est un guide pour améliorer le pouvoir de prédiction des algorithmes de ML.
Il vous enseigne la conception et la création de caractéristiques efficaces pour les applications basées sur le ML en offrant une compréhension approfondie des données.
#4. Bookcamp d'ingénierie des caractéristiques
Ce livre traite d'études de cas pratiques pour vous enseigner les techniques d'ingénierie de caractéristiques afin d'améliorer les résultats de ML et la gestion des données.
Sa lecture vous permettra d'obtenir de meilleurs résultats sans passer trop de temps à affiner les paramètres ML.
#5. L'art de l'ingénierie des caractéristiques
Ce livre est une ressource essentielle pour tout data scientist ou ingénieur en apprentissage automatique.
Il utilise une approche interdomaines pour discuter des graphiques, textes, séries chronologiques, images et études de cas.
Conclusion
Voilà comment réaliser l'ingénierie des caractéristiques. Maintenant que vous connaissez la définition, le processus, les méthodes et les ressources d'apprentissage, vous pouvez les mettre en œuvre dans vos projets ML et constater votre succès !
Ensuite, vous pouvez consulter un article sur l'apprentissage par renforcement.