
Data Lakehouse est une nouvelle architecture de gestion de données émergente qui combine les meilleurs éléments d’un lac de données et d’un entrepôt de données. En utilisant un data lakehouse, vous avez la possibilité de stocker différents types de données sur une seule plate-forme et d’effectuer des requêtes et des analyses conformes à ACID.
Alors, pourquoi utiliser un lac de données ? En tant qu’ingénieur logiciel senior, je peux comprendre à quel point il peut être difficile de gérer et de maintenir deux systèmes distincts et de faire circuler de grands volumes de données de l’un à l’autre.
Si vous souhaitez utiliser vos données pour exécuter des analyses commerciales et générer des rapports, vous devez stocker des données structurées dans un entrepôt de données. En revanche, pour stocker toutes les données provenant de diverses sources de données et dans leur format original, il faut un lac de données. Avoir une seule maison au bord du lac élimine ce besoin d’entretenir différents systèmes car elle apporte le meilleur des deux mondes.
Table des matières
Importance des données Lakehouse
Afin de développer votre organisation et votre activité, vous devez être capable de stocker et d’analyser des données quel que soit leur format ou leur structure. Les data lakehouses sont importants pour la gestion moderne des données car ils répondent aux limites des lacs de données et des entrepôts de données.
Vos lacs de données peuvent souvent se transformer en marécages de données, où les données sont vidées sans aucune structure ni gouvernance. Cela rend difficile la recherche et l’utilisation des données, et peut également entraîner des problèmes de qualité des données. En revanche, disposer d’un entrepôt de données conduit souvent à être trop rigide. Cela devient également cher.
Un data lakehouse a son propre ensemble de caractéristiques. Jetons un coup d’oeil à eux.
Caractéristiques d’un Data Lakehouse
Avant de plonger dans l’architecture d’un data Lakehouse, voyons les fonctionnalités ou caractéristiques les plus importantes d’un Data Lakehouse.
Architecture de Lakehouse de données
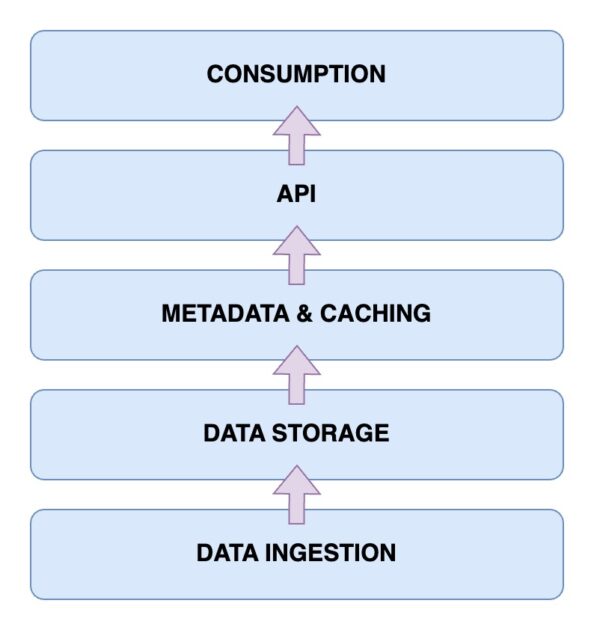
Il est maintenant temps de jeter un œil à l’architecture d’un data lakehouse. Comprendre l’architecture du Data Lakehouse est essentiel pour comprendre son fonctionnement. L’architecture Data Lakehouse comprend principalement cinq composants principaux. Regardons-les un par un.
Couche d’ingestion de données
Il s’agit de la couche où sont capturées toutes les différentes données dans leurs différents formats. Il peut s’agir de modifications de données dans votre base de données principale, de données provenant de divers capteurs IoT ou de données utilisateur en temps réel circulant via des flux de données.
Couche de stockage de données
Une fois les données ingérées à partir des différentes sources, il est temps de les stocker dans leurs formats appropriés. C’est là qu’intervient votre couche de stockage. Les données peuvent être stockées sur différents supports comme AWS S3. En fait, c’est votre lac de données.
Métadonnées et couche de mise en cache
Maintenant que votre couche de stockage de données est en place, vous avez besoin d’une couche de métadonnées et de gestion des données. Cela fournit une vue unifiée de toutes les données présentes dans le lac de données. C’est également la couche qui ajoute les transactions ACID au lac de données existant afin de le transformer en lac de données.
Couche API
Vous pouvez accéder aux données indexées à partir de la couche de métadonnées à l’aide de la couche API. Ceux-ci peuvent prendre la forme de pilotes de base de données qui vous permettent d’exécuter vos requêtes via du code. Ou bien, ceux-ci pourraient être exposés sous la forme de points de terminaison accessibles à partir de n’importe quel client.
Couche de consommation de données
Cette couche comprend vos outils d’analyse et de Business Intelligence, qui sont les principaux utilisateurs des données du data Lakehouse. Vous pouvez exécuter vos programmes d’apprentissage automatique ici pour obtenir des informations précieuses sur les données que vous avez stockées et indexées.
Ainsi, vous avez maintenant une idée claire de l’architecture de Lakehouse. Mais comment en construire un ?
Étapes pour créer un Data Lakehouse
Voyons comment vous pouvez créer votre propre lac de données. Que vous disposiez d’un lac ou d’un entrepôt de données existant ou que vous construisiez un Lakehouse à partir de zéro, les étapes restent similaires.
Voyons ensuite comment vous pouvez migrer vers un lac de données si vous disposez d’une solution de gestion de données existante.
Étapes pour migrer vers un Data Lakehouse
Lorsque vous migrez votre charge de travail de données vers une solution Data Lakehouse, vous devez garder certaines étapes à l’esprit. Avoir un plan d’action vous permet d’éviter les problèmes de dernière minute.
Étape 1 : Analyser les données
La première étape, et l’une des plus cruciales pour toute migration réussie, est l’analyse des données. Avec une analyse appropriée, vous pouvez définir la portée de votre migration. De plus, il vous permet d’identifier toutes les dépendances supplémentaires que vous pourriez avoir. Vous disposez désormais d’une meilleure vue d’ensemble de votre environnement et de ce que vous êtes sur le point de migrer. Cela vous permet de mieux prioriser vos tâches.
Étape 2 : préparer les données pour les migrations
La prochaine étape pour une migration réussie est la préparation des données. Cela inclut les données que vous allez migrer, ainsi que les cadres de données de support dont vous aurez besoin. Plutôt que d’attendre aveuglément que toutes vos données soient disponibles dans votre Lakehouse, savoir de quels ensembles de données et colonnes vous avez réellement besoin peut vous faire gagner un temps et des ressources précieux.
Étape 3 : Convertir les données au format requis
Vous pouvez tirer parti de la conversion automatique. En fait, vous devriez privilégier autant que possible les outils de conversion automatique. Les conversions de données lors de la migration vers Data Lakehouse peuvent être délicates. Heureusement, la plupart des outils sont livrés avec du code SQL ou des solutions low-code facilement lisibles. Des outils comme Alchimiste aider avec ça.
Étape 4 : valider les données après la migration
Une fois votre migration terminée, il est temps de valider les données. Ici, vous devriez essayer d’automatiser le processus de validation autant que possible. Sinon, la migration manuelle devient fastidieuse et vous ralentit. Il ne doit être utilisé qu’en dernier recours. Il est important de vérifier que vos processus métier et vos tâches de données ne sont pas affectés après la migration.
Principales fonctionnalités de Data Lakehouse
🔷 Gestion complète des données – Vous bénéficiez de fonctionnalités de gestion de données qui vous aident à tirer le meilleur parti de vos données. Ceux-ci incluent le nettoyage des données, le processus ETL ou Extract-Transform-Load et l’application du schéma. Ainsi, vous pouvez facilement nettoyer et préparer vos données pour des analyses plus approfondies et des outils de BI (Business Intelligence).
🔷 Formats de stockage ouverts – Le format de stockage dans lequel vos données sont enregistrées est ouvert et standardisé. Cela signifie que les données que vous collectez à partir de différentes sources de données sont toutes stockées de la même manière et que vous pouvez travailler avec elles dès le début. Il prend en charge des formats tels que AVRO, ORC ou Parquet. De plus, ils prennent également en charge les formats de données tabulaires.
🔷 Séparation du stockage – Vous pouvez découpler votre stockage des ressources de calcul. Ceci est réalisé en utilisant des clusters distincts pour les deux. Par conséquent, vous pouvez augmenter séparément votre stockage si nécessaire sans avoir à apporter inutilement des modifications à vos ressources de calcul.
🔷 Prise en charge du streaming de données – Prendre des décisions basées sur les données implique souvent de consommer des flux de données en temps réel. Par rapport à un entrepôt de données standard, un data lakehouse vous offre la prise en charge de l’ingestion de données en temps réel.
🔷 Gouvernance des données – Elle soutient une gouvernance solide. De plus, vous bénéficiez également de capacités d’audit. Ceux-ci sont particulièrement importants pour maintenir l’intégrité des données.
🔷 Coûts de données réduits – Le coût opérationnel de l’exploitation d’un lac de données est comparativement inférieur à celui d’un entrepôt de données. Vous pouvez obtenir un stockage objet cloud pour vos besoins croissants en données à moindre coût. De plus, vous obtenez une architecture hybride. Ainsi, vous pouvez éliminer le besoin de maintenir plusieurs systèmes de stockage de données.
Data Lake, Data Warehouse et Data Lakehouse
FonctionnalitéData LakeData WarehouseData LakehouseData StorageStocke des données brutes ou non structuréesStocke des données traitées et structuréesStocke à la fois des données brutes et structuréesSchéma de donnéesN’a pas de schéma fixePossède un schéma fixeUtilise un schéma open source pour les intégrationsTransformation des donnéesLes données ne sont pas transforméesUn ETL étendu est requisETL est effectué selon les besoinsConformité ACIDAucune conformité ACIDACID -compliantACID-CompliantQuery PerformanceGénéralement plus lent car les données sont non structuréesTrès rapide en raison des données structuréesRapide en raison des données semi-structuréesCoûtLe stockage est rentableCoûts de stockage et de requête plus élevésLe coût du stockage et des requêtes est équilibréGouvernance des donnéesNécessite une gouvernance prudenteUne gouvernance solide est nécessairePrend en charge les mesures de gouvernanceAnalyses en temps réelAnalyses en temps réel limitéesRéel limité analyse temporellePrend en charge l’analyse en temps réelCas d’utilisationStockage de données, exploration, ML et AIRReporting et analyse à l’aide de BIBà la fois l’apprentissage automatique et l’analyse
Conclusion
En combinant de manière transparente les atouts des lacs de données et des entrepôts de données, un lac de données répond aux défis importants auxquels vous pourriez être confronté dans la gestion et l’analyse de vos données.
Vous connaissez maintenant les caractéristiques et l’architecture d’une maison au bord d’un lac. L’importance d’un data lakehouse est évidente dans sa capacité à travailler avec des données structurées et non structurées, offrant une plate-forme unifiée pour le stockage, les requêtes et l’analyse. De plus, vous bénéficiez également de la conformité ACID.
Grâce aux étapes mentionnées dans cet article sur la création et la migration vers un lac de données, vous pouvez bénéficier des avantages d’une plateforme de gestion de données unifiée et rentable. Restez à la pointe du paysage moderne de la gestion des données et stimulez la prise de décision, l’analyse et la croissance de votre entreprise basées sur les données.
Ensuite, consultez notre article détaillé sur la réplication des données.