Les données constituent un pilier fondamental pour optimiser les processus, accroître l’efficience, améliorer l’expérience client et faciliter une prise de décision éclairée.
Dans cette perspective, les entreprises et les organisations génèrent, recueillent et conservent des volumes massifs de données provenant de diverses sources. Cependant, à mesure que ces volumes s’intensifient, l’extraction d’informations pertinentes peut devenir un défi, notamment lorsque les données sont désorganisées et dispersées sur différents emplacements.
Une approche pour surmonter ces obstacles consiste à stocker les données dans un dépôt approprié. Cela établit une source unifiée de données, contenant des informations filtrées, consultables et préparées pour l’analyse et la production de rapports.
Source: aws.amazon.com
Dans cet exposé, nous définirons la notion de dépôt de données et explorerons ses avantages, ses différents types, ainsi que les meilleures pratiques à adopter.
Qu’est-ce qu’un dépôt de données ?
Un dépôt de données est une sorte de bibliothèque ou d’archive où sont conservées les données, destinées à appuyer les fonctions d’analyse et de production de rapports, que ce soit dans le cadre de la recherche ou des opérations commerciales. En termes pratiques, un dépôt de données est un terme générique désignant un emplacement centralisé pour le stockage des données. Il peut s’agir d’un unique dispositif de stockage ou d’un ensemble de bases de données réparties sur plusieurs appareils.
Dans un fonctionnement typique, les organisations peuvent collecter des données hétérogènes à partir de points de vente, de systèmes CRM, ERP, de feuilles de calcul et d’autres sources. Elles transfèrent ensuite ces données vers un dépôt où elles sont triées, nettoyées, validées, formatées, organisées et stockées.
Les organisations peuvent généralement isoler et stocker des types spécifiques de données dans le dépôt, à des fins d’analyse ou de création de rapports. Puisqu’il s’agit d’un stockage à long terme, les données peuvent être réutilisées de nombreuses fois pour divers types d’analyses.
Un dépôt de données standard est composé de trois couches principales :
- La couche des sources de données
- La couche de traitement des données ou l’entrepôt
- La couche d’application cible, incluant les utilisateurs, les analystes et les rapports
Pourquoi un dépôt de données est-il indispensable ?
Les données sont accessibles via les interactions avec les clients, internet, la recherche, le marketing, les applications et bien d’autres sources. Cependant, elles sont généralement au format brut, et les organisations ont besoin d’outils adéquats pour extraire des informations utiles, leur permettant d’atteindre leurs objectifs. Une pratique judicieuse consiste à mettre en place un dépôt de données pour organiser ces données et les rendre disponibles pour l’analyse et d’autres applications.
Le dépôt permet aux utilisateurs autorisés d’accéder, de récupérer et de gérer facilement et rapidement les données, en utilisant la recherche, des requêtes et d’autres outils. Les utilisateurs et les entreprises peuvent ainsi réaliser des analyses, des recherches, des partages et des rapports, ce qui leur permet d’optimiser les opérations et de prendre de meilleures décisions basées sur les données.
Par exemple, si vous désirez identifier le service de votre organisation qui génère le plus de coûts opérationnels, vous pouvez créer un dépôt de données pour les baux, la sécurité, les coûts énergétiques, les services publics et autres dépenses. Centraliser ces données vous aidera à analyser et à identifier le département le plus dépensier, facilitant ainsi une prise de décisions plus éclairées et ciblées en vue d’une réduction des coûts.
Bien que les dépôts de données soient couramment utilisés par les institutions de recherche et scientifiques, ils trouvent également leur utilité dans les organisations et les entreprises en général.
Les avantages des dépôts de données
Aujourd’hui, la plupart des organisations emploient les dépôts de données comme moyen de gérer et d’exploiter leurs données de manière plus efficace. Le concept de dépôt de données a gagné en popularité en raison de ses nombreux avantages, tels qu’un accès facilité, une gestion simplifiée, ainsi qu’une analyse et une production de rapports plus aisées.
Parmi les autres avantages, on peut citer :
- Amélioration de la visibilité : Le fait de stocker les données dans un endroit central et fiable les rend accessibles en tout temps. Inversement, le maintien des données dans des applications non partagées ou des silos locaux limite leur accessibilité à un individu ou à quelques personnes seulement, réduisant ainsi leur visibilité et leur facilité d’utilisation. Par conséquent, les équipes peuvent perdre plus de temps et utiliser des ressources supplémentaires pour accéder aux données.
- Accès simplifié aux données utiles : Les données numériques sont faciles à rechercher et à consulter. L’ajout de métadonnées aux données dans le dépôt permet aux utilisateurs de mieux les comprendre et de les utiliser plus efficacement.
- Sécurisation aisée des données et respect des normes : Il est bien plus facile de protéger les données dans un emplacement central que lorsqu’elles sont dispersées. De plus, un dépôt de données permet de respecter plus simplement et à moindre coût les diverses normes réglementaires.
- Réutilisation des données : Un dépôt de données contient une grande diversité de données pour l’analyse et la production de rapports. Les analystes et les chercheurs peuvent utiliser les mêmes données pour générer différents types de rapports.
- Fourniture d’informations utiles : L’emploi d’outils adéquats sur les dépôts de données permet d’obtenir une vue multidimensionnelle des données au lieu d’analyser les informations à différents endroits.
Types de dépôts de données
Le terme dépôt de données est un terme générique désignant les archives d’informations. Cependant, il existe différents types de dépôts en fonction de l’application ou de l’objectif visé. Voici les quatre principaux types de dépôts de données :
#1. Entrepôt de données
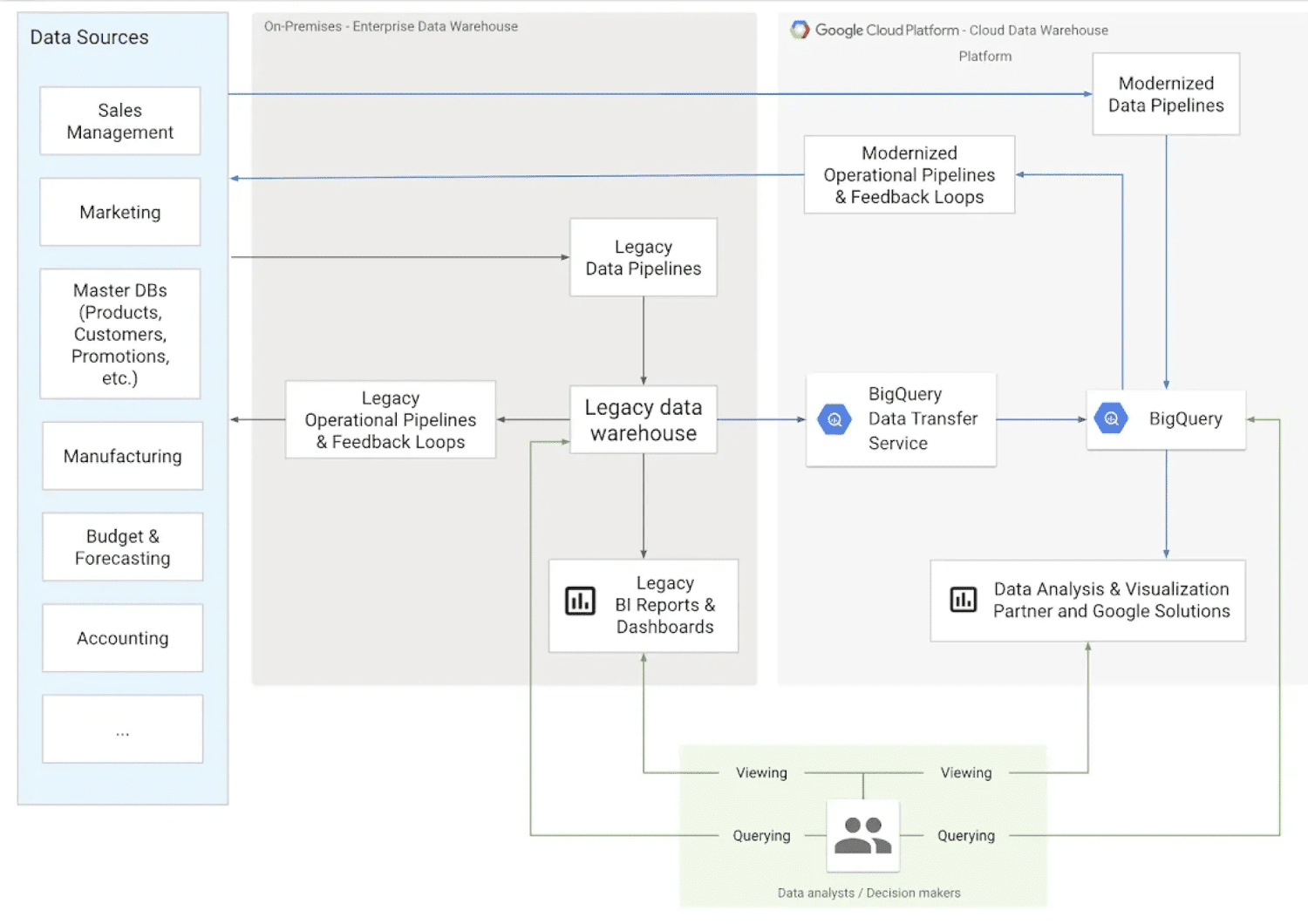 Source: cloud.google.com
Source: cloud.google.com
L’entrepôt de données est l’un des plus importants types de dépôts de données. Dans cette catégorie, les entreprises peuvent collecter des données provenant de multiples sources et sous différents formats. Un entrepôt de données typique stocke de gros volumes de données provenant de sources diverses. Sa structure facilite l’organisation des données, leur analyse et la production de rapports. Cela permet aux équipes de prendre de meilleures décisions basées sur les données.
Les informations stockées dans un entrepôt de données peuvent couvrir divers sujets et sont généralement nettoyées, filtrées et définies en vue d’un usage particulier.
#2. Magasin de données
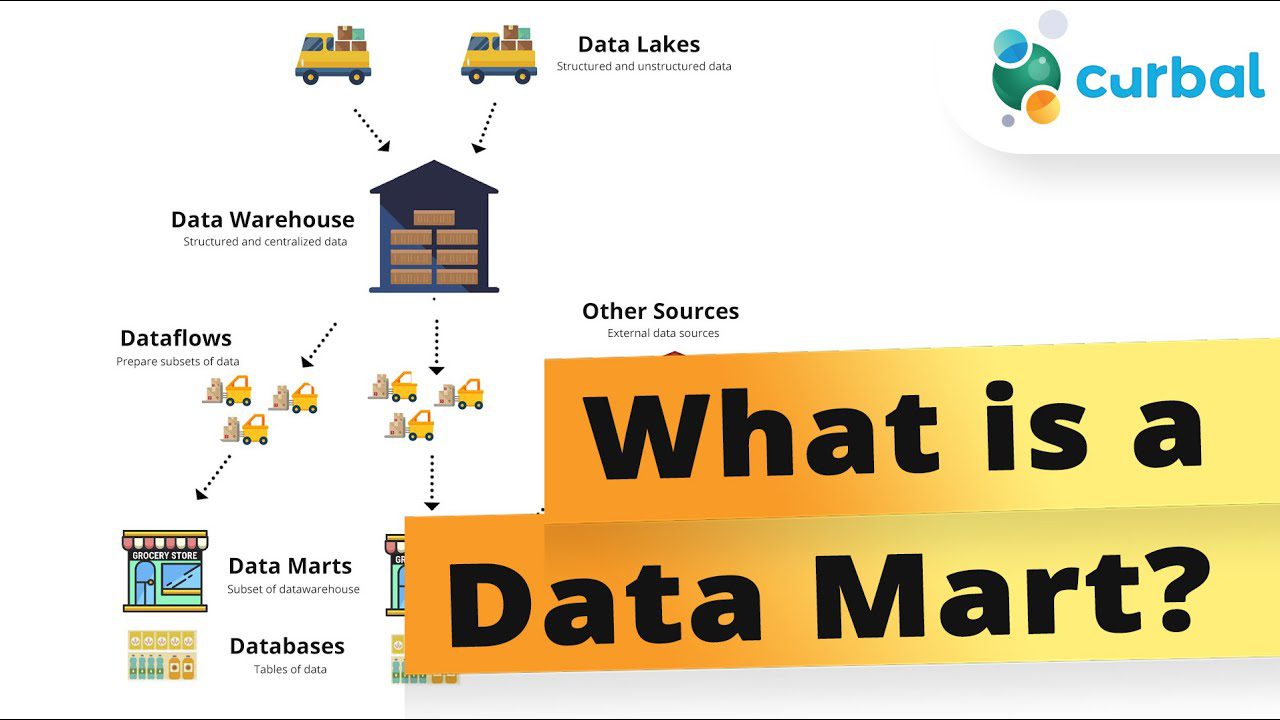
Un magasin de données est une section distincte d’un entrepôt de données. Ce dépôt de données orienté sujet stocke un sous-ensemble de données axé sur une fonction ou un service commercial spécifique, tel que la finance, le support, les achats ou le marketing.
En général, un magasin de données est de taille réduite. Cela permet d’accélérer les processus métiers en donnant un accès plus rapide aux données pertinentes. Ces magasins de données représentent une manière rentable d’obtenir rapidement des informations exploitables.
#3. Lac de données
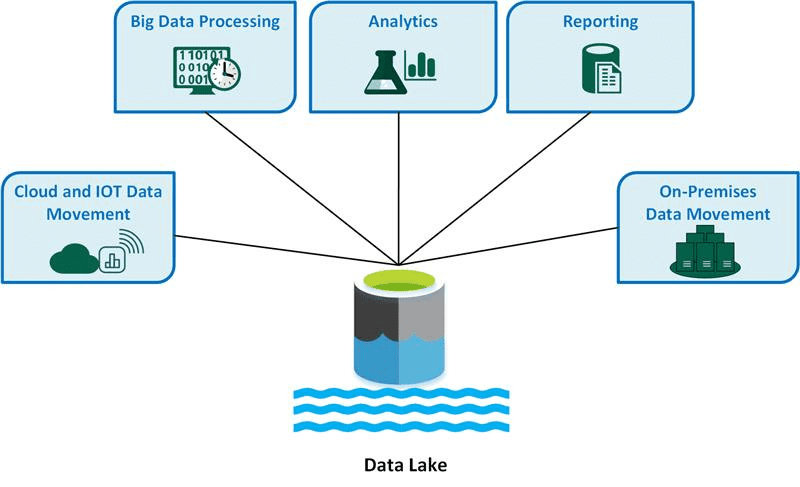 Source: microsoft.com
Source: microsoft.com
Un lac de données est une grande archive qui contient des données sous n’importe quelle forme, qu’il s’agisse de données non structurées, semi-structurées ou structurées. Il emploie des métadonnées pour catégoriser et étiqueter les données, qui sont en grande partie non structurées. Un lac de données offre un contrôle total et une meilleure gouvernance des données par rapport à un entrepôt de données.
#4. Cubes de données
Les cubes de données sont des dépôts de données multidimensionnels, qui se concentrent davantage sur des données complexes non prises en charge par les autres types. Ils présentent trois dimensions ou plus, chacune représentant une caractéristique spécifique, comme les coûts ou les ventes quotidiens, mensuels ou annuels. Les cubes de données permettent aux chercheurs d’évaluer les données selon différents points de vue.
À lire aussi : Data Lake vs Data Warehouse : quelles sont les différences ?
Meilleures pratiques pour la conception et la maintenance des dépôts de données
Un dépôt de données typique dispose d’outils pour stocker, gérer et sécuriser les informations. Il intègre des fonctionnalités telles que le contrôle d’accès, l’indexation, la compression, la création de rapports, le cryptage, etc.
Lors de la conception et de la création d’un dépôt de données, il est important de prendre en compte divers facteurs matériels et logiciels, en plus de collaborer avec des ingénieurs de pipeline de données, des analystes de données et d’autres experts. Selon le domaine, il est également nécessaire d’impliquer des experts de l’industrie. Par exemple, si vous créez un dépôt de données cliniques, vous travaillerez avec des médecins et d’autres professionnels de la santé.
Une stratégie efficace de gestion des données comprend les éléments suivants :
✅ Organisation des fichiers
✅ Stockage sécurisé et contrôles d’accès appropriés
✅ Contrôle des versions et de la documentation
✅ Prise en charge de la collaboration
✅ Des politiques claires sur la réutilisation et le partage
✅ Archivage et conservation des données pour référence ou utilisation future.
Bien que les étapes de conception, de création et de gestion d’un dépôt de données puissent différer d’un secteur ou d’une organisation à l’autre, voici quelques bonnes pratiques.
Limiter la portée aux étapes initiales
Au commencement, il est recommandé d’opter pour une portée plus restreinte du dépôt de données. Une approche pertinente consiste à commencer avec un nombre limité de domaines et d’ensembles de données, puis à augmenter progressivement la portée.
Choisir les bons outils
Les outils sont essentiels dans la création, le stockage, le partage, l’analyse et la gestion des dépôts de données. La qualité et l’analyse des données dépendront donc des outils employés. Étant donné qu’il existe divers types d’outils avec des capacités variables, assurez-vous que votre choix correspond à vos besoins spécifiques.
Automatiser autant de processus que possible
Dans la mesure du possible, automatisez les tâches de chargement et de maintenance pour améliorer l’efficacité, réduire les pertes de temps et les risques d’erreurs.
Concevoir un dépôt flexible et évolutif
Pour pouvoir s’adapter à l’augmentation des volumes de données, à l’évolution des types de données et des formats, il est recommandé de concevoir et de créer un dépôt évolutif. Un tel système répondra aux besoins et à l’échelle actuels pour supporter des types et des volumes de données accrus à l’avenir. De plus, il doit être flexible pour pouvoir travailler avec différents outils et technologies émergentes.
Protéger les données en permanence
Assurez l’intégrité et la sécurité des données, car toute divergence, compromission ou vol peut entraîner des résultats d’analyse inexacts et des décisions inappropriées. Définissez des règles d’accès appropriées et n’accordez aux utilisateurs autorisés que les permissions nécessaires à l’accomplissement de leurs tâches. En outre, chiffrez les données au repos et en transit. Envisagez d’autres mesures comme l’authentification multifacteur pour ajouter une couche de protection supplémentaire.
Utiliser des modèles de données standard
La modélisation des données facilite la transformation des données en informations précieuses, que les chercheurs et les chefs d’entreprise peuvent mieux comprendre. Les informations contenues dans un dépôt de données sont généralement réutilisables.
Les organisations peuvent utiliser les mêmes données pour extraire des informations utiles dans divers domaines. Les données peuvent avoir plusieurs contextes, en fonction de la manière dont elles sont utilisées dans les différents processus et applications analytiques. Par conséquent, une organisation peut utiliser plusieurs modèles de données pour répondre à des besoins analytiques divers.
Indexation des données
La création d’index sur les tables du dépôt de données améliore les performances des requêtes et devrait être une pratique courante. L’indexation améliore la vitesse de requête en fournissant une table de recherche organisée, basée sur certains attributs, et avec des entrées qui pointent vers des emplacements de données spécifiques.
L’indexation sur les dépôts de données peut varier en fonction de l’utilisation. Elle peut être légère ou étendue, selon les besoins. Idéalement, la stratégie d’indexation devrait se concentrer sur l’accélération des processus ETL. Une bonne pratique lors de la transformation des données consiste à s’assurer que l’index fournit les informations nécessaires, sans omettre de données utiles, tout en évitant d’être inutilement volumineux.
Il est également crucial d’équilibrer le compromis entre l’amélioration des performances de requête du dépôt de données et les frais généraux associés, ainsi que les coûts de maintenance de l’indexation.
Consultez également : Meilleurs outils ETL à utiliser par les PME.
Exemples de dépôts de données
Les dépôts de données peuvent être classés en différentes catégories :
- Dépôts institutionnels (DI) destinés aux institutions de recherche, comme le Texas Data Repository par les bibliothèques universitaires Texas A&M.
- Dépôts disciplinaires ou spécifiques à un domaine (DD) : ils sont spécifiques à un domaine et gérés par un consortium de chercheurs ou une organisation professionnelle, comme le Registry of Research Data Repositories (re3data) par DataCite, et le Directory of Open Access Repositories (OpenDOAR), qui regroupe plusieurs dépôts universitaires en libre accès.
- Dépôts ouverts ou à usage général, tels que Dryad, Figshare et Dataverse de Harvard.
Cas d’utilisation des dépôts de données
La fintech, la santé, le commerce électronique, la chaîne d’approvisionnement et d’autres secteurs peuvent tirer profit de l’utilisation de dépôts de données. En exploitant pleinement les grandes quantités de données qu’ils collectent et génèrent, ils peuvent obtenir de meilleures informations pour optimiser leurs services et fournir des prestations plus efficaces et plus rapides.
Recherche clinique
La recherche clinique est un domaine extrêmement gourmand en données. Tirer le meilleur parti de ces données permet d’orienter le secteur de la santé dans la bonne direction. L’analyse du Big Data permet aux scientifiques et autres professionnels d’approfondir les essais cliniques et d’obtenir des informations qui contribuent à améliorer les soins de santé et à sauver des vies.
Services financiers

Le secteur des services financiers peut bénéficier de l’analyse de vastes quantités de données dont il dispose. L’analyse leur fournit des informations qu’ils peuvent utiliser pour améliorer les services, l’efficacité et les revenus. Voici quelques-uns des domaines dans lesquels les institutions financières peuvent utiliser des dépôts de données :
- Produire des rapports financiers en analysant les données à partir d’un emplacement centralisé.
- Faciliter une prise de décision automatisée, alimentée par l’IA.
Derniers mots
Les données sont un atout essentiel pour la prise de décision. Cependant, les organisations qui stockent de gros volumes de données ont besoin des solutions appropriées pour collecter, stocker, gérer et analyser ces données.
Dans ce contexte, un dépôt de données offre une solution pour consolider et gérer les données critiques. Les dépôts permettent aux organisations d’analyser les données, d’en extraire des informations et de prendre de meilleures décisions basées sur ces données.
Un dépôt de données fournit un stockage centralisé de différents types d’informations, mais d’une manière logique qui facilite l’accès, la recherche, l’analyse et la gestion. Il aide également les organisations à sécuriser, partager, maintenir et garantir l’intégrité et la qualité des données, ainsi qu’à se conformer aux normes réglementaires.
Pour aller plus loin, découvrez les meilleurs outils de gestion de données pour les moyennes et grandes entreprises.