Maîtriser Grep et Regex : Un Guide Complet
Si vous êtes un utilisateur régulier de Linux, vous êtes probablement familier avec `grep`, l’outil de traitement de texte puissant qui permet de rechercher des fichiers et des répertoires. C’est un allié précieux pour tout utilisateur Linux expérimenté. Cependant, sans l’utilisation des expressions régulières (regex), ses capacités restent limitées.
Mais qu’est-ce que Regex exactement ?
Regex, ou expression régulière, est un mécanisme de filtrage avancé qui peut considérablement améliorer la fonctionnalité de recherche de `grep`. Avec de la pratique, vous pouvez maîtriser regex et l’utiliser efficacement non seulement avec `grep`, mais aussi avec d’autres commandes Linux. C’est une compétence qui ouvre un monde de possibilités.
Ce tutoriel vous guidera à travers l’utilisation efficace de `grep` et de regex, en explorant leurs fonctionnalités et en vous fournissant des exemples pratiques.
Prérequis
Pour tirer le meilleur parti de ce tutoriel, une bonne connaissance de base de Linux est essentielle. Si vous débutez, nous vous recommandons de consulter nos guides Linux pour débutants.
Vous aurez également besoin d’un ordinateur sous Linux. Vous pouvez utiliser n’importe quelle distribution de votre choix. Si vous travaillez sous Windows, WSL2 (le sous-système Linux pour Windows) peut être une excellente alternative. Vous trouverez un guide détaillé ici.
L’accès au terminal ou à la ligne de commande est indispensable pour exécuter les commandes présentées dans ce tutoriel.
De plus, vous aurez besoin d’un ou plusieurs fichiers texte pour tester les exemples. Pour cela, nous avons utilisé ChatGPT pour générer un texte sur la technologie. L’invite était la suivante :
« Générez 400 mots sur la technologie. Le texte doit mentionner diverses technologies et répéter leurs noms. »
Après la génération du texte, nous l’avons copié et collé dans un fichier nommé `tech.txt`. Ce fichier nous servira d’exemple tout au long du tutoriel.
Enfin, une compréhension de base de la commande `grep` est nécessaire. Si vous souhaitez rafraîchir vos connaissances, nous vous recommandons de consulter 16 exemples de commandes `grep`. Nous allons également fournir un bref rappel de cette commande pour vous aider à démarrer.
Syntaxe et Exemples de la Commande `grep`
La syntaxe de la commande `grep` est assez simple.
$ grep -options [regex/motif] [fichiers]
Elle prend un motif ou une expression régulière et une liste de fichiers dans lesquels la rechercher.
Voici quelques options courantes qui modifient son comportement :
- `-i` : Recherche insensible à la casse (majuscules/minuscules).
- `-r` : Recherche récursive dans les répertoires.
- `-w` : Recherche les mots entiers uniquement.
- `-v` : Affiche les lignes qui ne correspondent pas au motif.
- `-n` : Affiche les numéros de ligne des correspondances.
- `-l` : Affiche les noms des fichiers contenant les correspondances.
- `–color` : Met en couleur la sortie.
- `-c` : Affiche le nombre de correspondances trouvées.
#1. Recherche d’un Mot Entier
Pour effectuer une recherche de mot entier, utilisez l’option `-w` avec `grep`. Cela exclut les chaînes qui correspondent partiellement au motif.
$ grep -w 'tech\|5G' tech.txt
Cette commande recherche les mots « 5G » et « tech » dans le fichier `tech.txt` et les met en évidence en rouge. Notez que le symbole `|` est échappé avec `\` afin qu’il ne soit pas interprété comme un métacaractère par `grep`.
#2. Recherche Insensible à la Casse
Pour une recherche insensible à la casse, utilisez l’option `-i` :
$ grep -i 'tech' tech.txt
Cette commande recherche toutes les occurrences de « tech » (ou « Tech », « TECH », etc.) qu’il s’agisse de mots entiers ou partiels.
#3. Recherche des Lignes Non Correspondantes
L’option `-v` permet d’afficher les lignes qui ne contiennent pas un motif spécifique :
$ grep -v 'tech' tech.txt

La sortie affiche toutes les lignes qui ne contiennent pas le mot « tech ». Les lignes vides font également partie du résultat, ce sont les lignes vides entre les paragraphes.
#4. Recherche Récursive
Pour une recherche récursive dans les répertoires, utilisez l’option `-r` :
$ grep -R 'error\|warning' /var/log/*.log
#output /var/log/bootstrap.log:2023-01-03 21:40:18 URL:http://ftpmaster.internal/ubuntu/pool/main/libg/libgpg-error/libgpg-erro 0_1.43-3_amd64.deb [69684/69684] -> "/build/chroot//var/cache/apt/archives/partial/libgpg-error0_1.43-3_amd64.deb" [1] /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 5 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 5 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 24 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 24 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: ignoring pre-dependency problem!
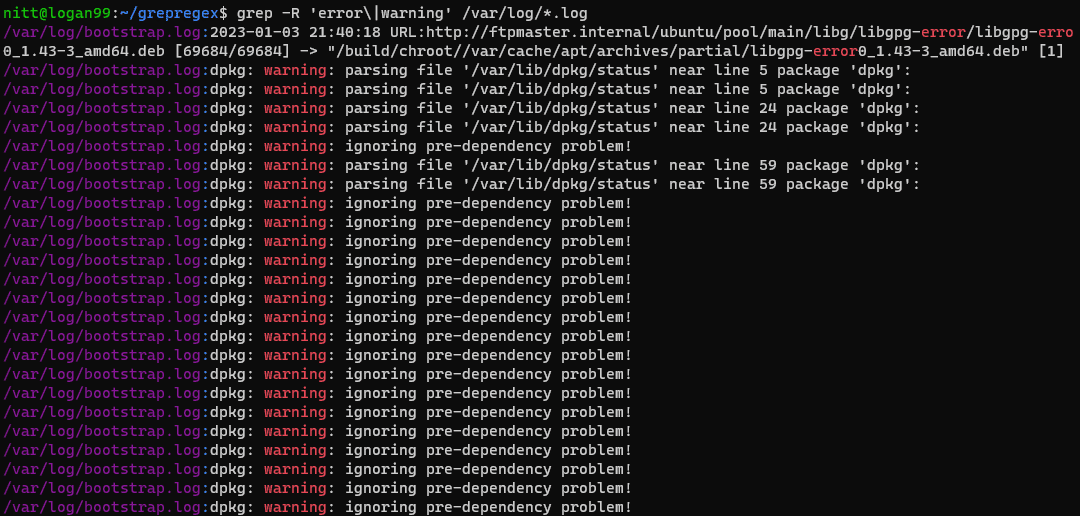
Cette commande recherche de manière récursive les mots « erreur » ou « avertissement » dans tous les fichiers `.log` du répertoire `/var/log`. C’est un moyen pratique de localiser rapidement des erreurs et des avertissements dans les fichiers journaux.
Grep et Regex : Définition et Exemples
Il est important de noter que regex propose trois syntaxes principales :
- Expressions régulières de base (BRE)
- Expressions régulières étendues (ERE)
- Expressions régulières compatibles Pearl (PCRE)
Par défaut, `grep` utilise BRE. Si vous souhaitez utiliser ERE ou PCRE, il faut le spécifier explicitement. En outre, `grep` traite les métacaractères tels quels, donc les caractères comme `?`, `+`, `)` doivent être échappés avec un antislash `\`.
La syntaxe de `grep` avec regex est la suivante :
$ grep [regex] [fichiers]
Voyons comment utiliser `grep` et regex avec quelques exemples concrets.
#1. Correspondances Littérales
Une correspondance littérale consiste à rechercher une chaîne exacte. C’est l’utilisation la plus basique de regex :
$ grep "technologies" tech.txt

Vous pouvez également utiliser les correspondances littérales pour rechercher les utilisateurs actifs. Pour cela :
$ grep bash /etc/passwd
#output root:x:0:0:root:/root:/bin/bash nitt:x:1000:1000:,,,:/home/nitt:/bin/bash
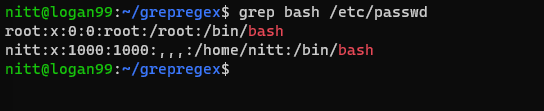
Cela affiche les utilisateurs ayant accès à `bash`.
#2. Correspondance d’Ancrage
La correspondance d’ancrage permet de rechercher des positions spécifiques dans le texte grâce à des caractères spéciaux. Voici les principaux caractères d’ancrage :
- `^` (symbole caret) : Correspond au début de la ligne.
- `$` (symbole dollar) : Correspond à la fin de la ligne.
- `\b` (limite de mot) : Correspond à la position entre un caractère de mot et un caractère de non-mot (début ou fin de mot).
- `\B` (limite de non-mot) : Correspond à une position qui n’est pas une limite de mot.
Illustrons ces ancres avec quelques exemples :
$ grep '^From' tech.txt

Le symbole `^` est sensible à la casse. Donc, la commande suivante ne retournera rien :
$ grep '^from' tech.txt
De même, le symbole `$` permet de rechercher les lignes qui se terminent par une chaîne spécifique :
$ grep 'technology.$' tech.txt

Vous pouvez aussi combiner les symboles `^` et `$`, comme dans cet exemple :
$ grep "^From \| technology.$" tech.txt
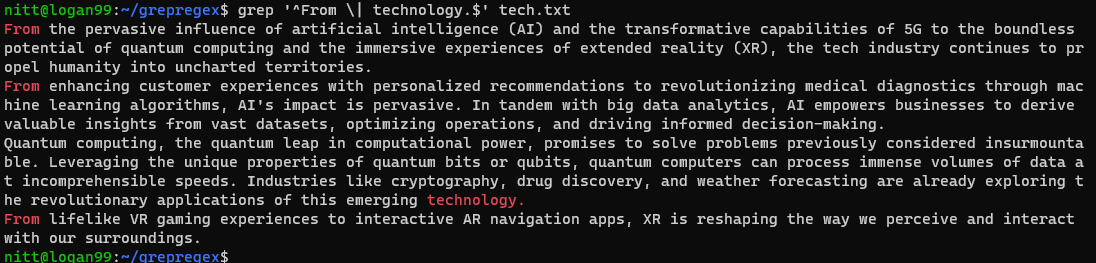
La sortie contient les lignes commençant par « From » et celles se terminant par « technology. »
#3. Groupement
Le groupement permet de traiter plusieurs caractères ou motifs comme une seule unité. Par exemple, vous pouvez créer un groupe `(tech)` pour les lettres ‘t’, ‘e’, ‘c’ et ‘h’.
Voyons cela en pratique :
$ grep 'technol\(ogy\)\?' tech.txt

Le groupement permet de faire des recherches de motifs répétitifs, de capturer des groupes ou de chercher des alternatives.
Recherche Alternative avec Groupement
Voici un exemple de recherche alternative :
$ grep "\(tech\|technology\)" tech.txt
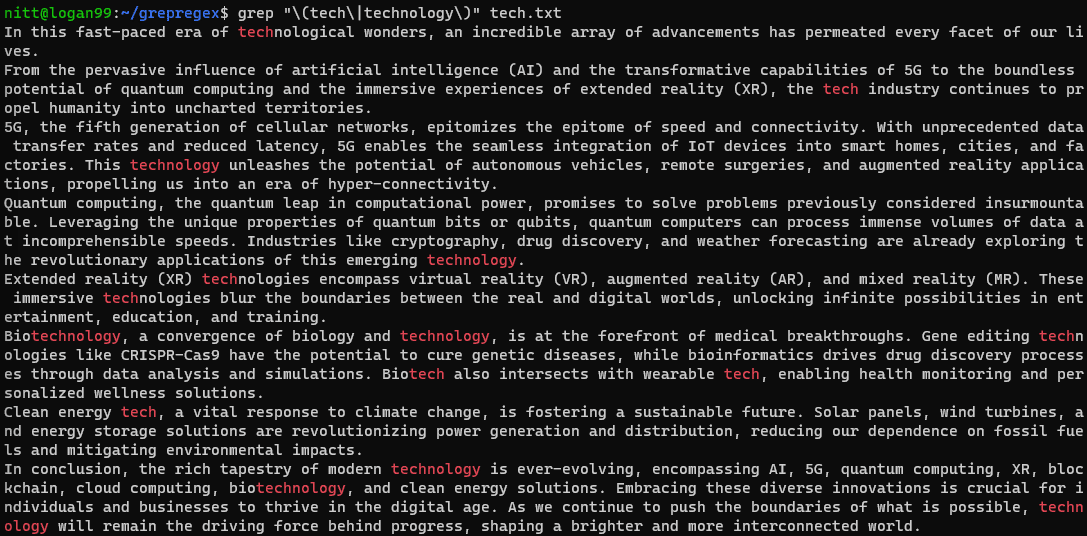
Si vous voulez faire une recherche sur une chaîne entière, vous devez utiliser le caractère `|` (pipe). Par exemple :
$ echo “tech technological technologies technical” | grep "\(tech\|technology\)"
#output “tech technological technologies technical”

Groupes de Capture, Groupes de Non-Capture et Motifs Répétés
Qu’en est-il des groupes de capture et de non-capture ?
Pour capturer un groupe, vous devez créer le groupe dans l’expression régulière et la transmettre à une chaîne ou un fichier :
$ echo 'tech655 tech655nical technologies655 tech655-oriented 655' | grep "\(tech\)\(655\)"
#output tech655 tech655nical technologies655 tech655-oriented 655

Pour les groupes de non-capture, utilisez `?:` entre parenthèses.
Enfin, pour les motifs répétés, modifiez l’expression régulière :
$ echo ‘teach tech ttrial tttechno attest’ | grep '\(t\+\)'
#output ‘teach tech ttrial tttechno attest’
Ici, la regex recherche une ou plusieurs occurrences du caractère `t`.
#4. Classes de Caractères
Les classes de caractères permettent de simplifier l’écriture des expressions regex. Ces classes utilisent des crochets. Voici quelques exemples :
- `[:digit:]` – Chiffres de 0 à 9.
- `[:alpha:]` – Caractères alphabétiques.
- `[:alnum:]` – Caractères alphanumériques.
- `[:lower:]` – Caractères minuscules.
- `[:upper:]` – Caractères majuscules.
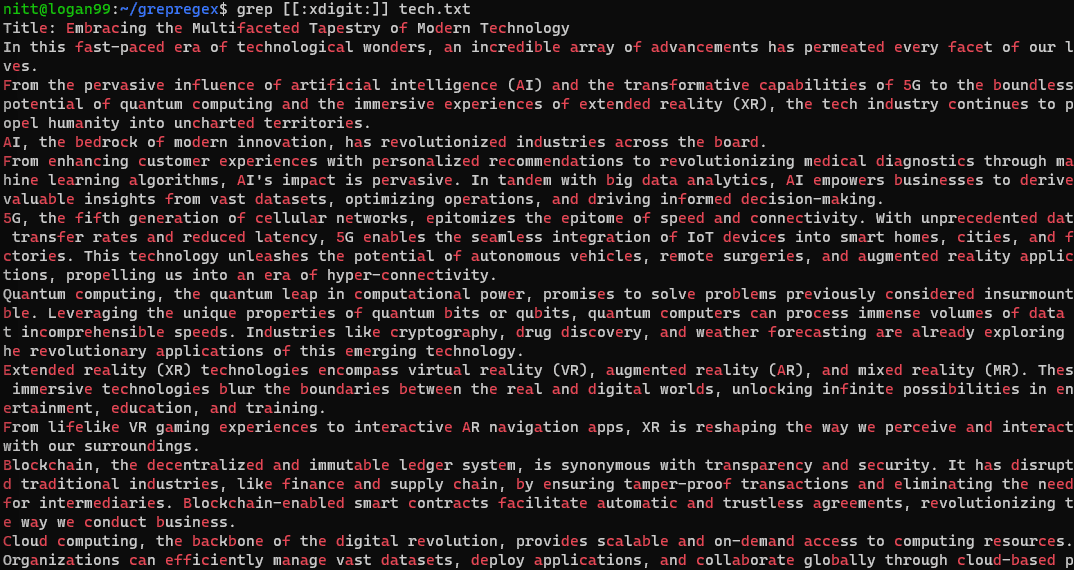
- `[:xdigit:]` – Chiffres hexadécimaux (0-9, A-F, a-f).
- `[:blank:]` – Espaces ou tabulations.
Et la liste continue !
Voyons ces classes en action :
$ grep [[:digit:]] tech.txt

$ grep [[:alpha:]] tech.txt
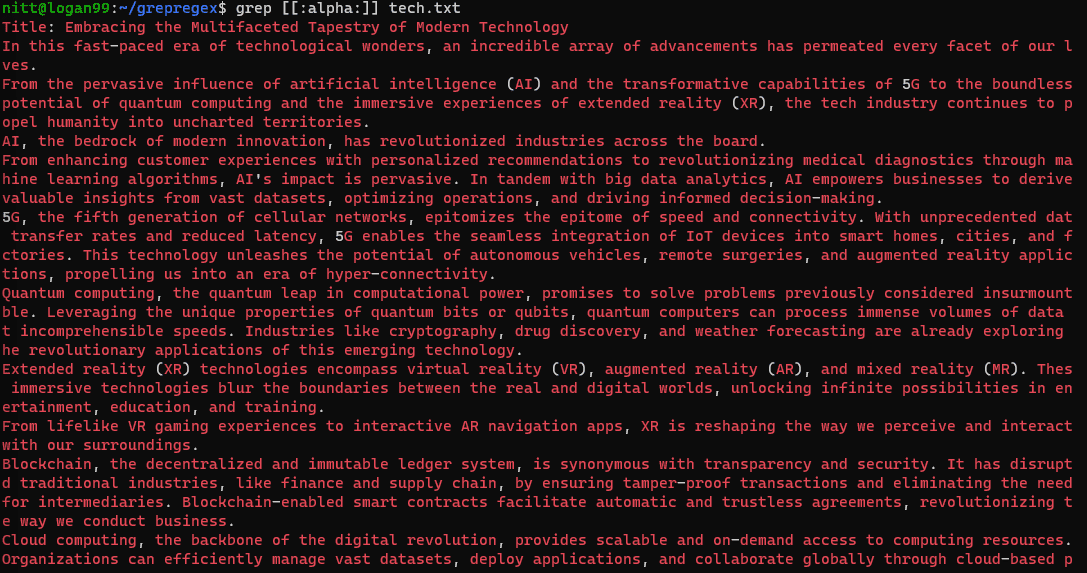
$ grep [[:xdigit:]] tech.txt
#5. Quantificateurs
Les quantificateurs sont des métacaractères essentiels qui permettent de spécifier le nombre exact d’occurrences d’un caractère ou d’un motif. Voici quelques quantificateurs :
- `*` → Zéro ou plusieurs correspondances.
- `+` → Une ou plusieurs correspondances.
- `?` → Zéro ou une correspondance.
- `{x}` → `x` correspondances.
- `{x, }` → `x` ou plusieurs correspondances.
- `{x,z}` → Entre `x` et `z` correspondances.
- `{,z}` → Jusqu’à `z` correspondances.
$ echo ‘teach tech ttrial tttechno attest’ | grep -E 't+'
#output ‘teach tech ttrial tttechno attest’
Ici, on recherche une ou plusieurs occurrences de `t`. L’option `-E` indique qu’on utilise des expressions régulières étendues (voir ci-dessous).

#6. Expressions Régulières Étendues (ERE)
Si vous souhaitez éviter l’échappement des métacaractères, vous pouvez utiliser les expressions régulières étendues avec l’option `-E`:
$ grep -E 'in+ovation' tech.txt

#7. Utilisation de PCRE pour des Recherches Complexes
PCRE (Perl Compatible Regular Expressions) est plus puissant que les expressions régulières de base. Par exemple, vous pouvez utiliser `\d` pour représenter `[0-9]`.
Voici un exemple d’utilisation de PCRE pour rechercher des adresses e-mail :
echo "Contact me at [email protected]" | grep -P "\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}\b"
#output Contact me at [email protected]

PCRE vérifie que le motif correspond à une adresse e-mail. On peut également utiliser PCRE pour vérifier un format de date :
$ echo "The Sparkain site launched on 2023-07-29" | grep -P "\b\d{4}-\d{2}-\d{2}\b"
#output The Sparkain site launched on 2023-07-29

Cette commande trouve la date au format AAAA-MM-JJ, mais peut facilement être modifiée pour d’autres formats.
#8. Alternation
Si vous souhaitez faire une recherche alternative, utilisez le caractère `|` :
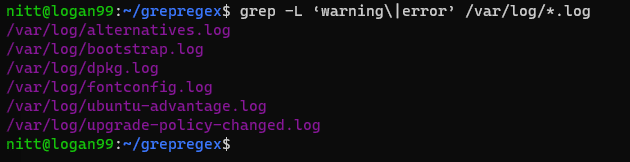
$ grep -L 'warning\|error' /var/log/*.log
#output /var/log/alternatives.log /var/log/bootstrap.log /var/log/dpkg.log /var/log/fontconfig.log /var/log/ubuntu-advantage.log /var/log/upgrade-policy-changed.log
La sortie affiche les fichiers qui contiennent le mot « warning » ou « error ».
Derniers Mots
Nous arrivons à la fin de ce guide sur `grep` et regex. En combinant ces outils, vous pouvez effectuer des recherches extrêmement précises et efficaces. Une utilisation appropriée de `grep` et regex vous fera gagner du temps et vous aidera à automatiser des tâches, notamment via des scripts.
Pour aller plus loin, consultez notre article sur les questions d’entretien courantes sur Linux.