L’extraction de données web, souvent appelée « scraping web », consiste à recueillir des informations à partir d’un site internet afin de les utiliser dans un contexte spécifique.
Imaginez que vous souhaitez extraire un tableau présent sur une page web, le transformer en format JSON, puis utiliser ce fichier JSON pour la création d’outils internes. Le web scraping vous permet de récupérer les données pertinentes en ciblant des éléments précis de la page. Le langage Python est très prisé pour cette tâche, car il offre des bibliothèques efficaces comme BeautifulSoup ou Scrapy pour l’extraction de données.
La capacité d’extraire efficacement des données est une compétence précieuse pour les développeurs et les data scientists. Cet article a pour objectif de vous montrer comment réaliser un web scraping performant et récupérer le contenu nécessaire pour le manipuler selon vos besoins. Pour ce tutoriel, nous allons utiliser le package BeautifulSoup, très populaire pour la récupération de données avec Python.
Pourquoi choisir Python pour le Web Scraping ?
Python est le choix privilégié de nombreux développeurs pour la création de scrapers web. Plusieurs raisons expliquent cette popularité, mais nous nous concentrerons ici sur les trois principales.
Richesse des bibliothèques et soutien de la communauté : Python bénéficie d’un écosystème de bibliothèques exceptionnelles, telles que BeautifulSoup, Scrapy, et Selenium, qui facilitent grandement l’extraction de données. Cette communauté active et étendue permet de trouver rapidement de l’aide en cas de difficultés.
Automatisation : Python excelle dans l’automatisation de tâches, ce qui est un atout majeur pour le web scraping. Si vous souhaitez, par exemple, créer un outil de suivi des prix sur une boutique en ligne, l’automatisation est nécessaire pour mettre à jour quotidiennement les tarifs dans votre base de données. Python simplifie grandement ces processus.
Visualisation des données : Le web scraping est une pratique courante chez les data scientists, qui ont fréquemment besoin d’extraire des données depuis des pages web. Avec des bibliothèques telles que Pandas, Python facilite la visualisation des données à partir des informations brutes extraites.
Bibliothèques Python pour le Web Scraping
Plusieurs bibliothèques Python facilitent le web scraping. Nous allons examiner les trois plus populaires.
#1. BeautifulSoup
C’est l’une des bibliothèques les plus largement utilisées pour le web scraping. Depuis 2004, BeautifulSoup permet aux développeurs d’extraire des données de pages web de manière efficace. Elle propose des méthodes simples pour naviguer, rechercher et modifier la structure d’analyse. BeautifulSoup gère également l’encodage des données en entrée et en sortie. Cette bibliothèque est régulièrement mise à jour et soutenue par une grande communauté.
#2. Scrapy
Scrapy est un autre framework très populaire pour l’extraction de données, avec plus de 43 000 étoiles sur GitHub. Il peut également être utilisé pour extraire des données depuis des API. Scrapy offre des fonctionnalités intégrées intéressantes, comme l’envoi d’emails.
#3. Selenium
Selenium n’est pas principalement conçu pour le web scraping, mais plutôt comme un outil d’automatisation de navigateur. Toutefois, ses fonctionnalités peuvent être facilement étendues pour l’extraction de données de pages web. Il utilise le protocole WebDriver pour contrôler différents navigateurs. Selenium existe depuis près de 20 ans, ce qui témoigne de sa fiabilité et de sa pertinence.
Difficultés du Web Scraping avec Python
L’extraction de données de sites web peut s’accompagner de défis, tels que des réseaux lents, des dispositifs anti-scraping, le blocage par IP, ou encore les captchas. Ces obstacles peuvent entraver considérablement la collecte d’informations.
Cependant, il existe des méthodes pour contourner ces problèmes. Par exemple, un site web peut bloquer une adresse IP lorsqu’un trop grand nombre de requêtes est envoyé en peu de temps. Pour éviter cela, vous pouvez programmer votre scraper pour qu’il ralentisse les requêtes après un certain intervalle.

De plus, certains développeurs mettent en place des « pots de miel » pour piéger les scrapers. Ces pièges, souvent invisibles à l’œil nu, peuvent être détectés par un scraper mal conçu. Il est donc essentiel d’adapter votre code en conséquence.
Les captchas constituent une autre difficulté majeure. De nombreux sites web utilisent des captchas pour limiter l’accès des robots à leurs pages. Dans ce cas, il peut être nécessaire de recourir à des solveurs de captchas.
Extraire des données d’un site web avec Python
Nous utiliserons BeautifulSoup pour notre exemple de web scraping. Ce tutoriel vise à extraire l’historique des données d’Ethereum depuis Coingecko, et d’enregistrer les données du tableau dans un fichier JSON. Passons à la construction du scraper.
La première étape consiste à installer BeautifulSoup et Requests. Pour ce tutoriel, nous utiliserons Pipenv, un outil de gestion d’environnements virtuels pour Python. Vous pouvez aussi utiliser Venv, mais je préfère Pipenv. La présentation de Pipenv dépasse le cadre de ce tutoriel, mais vous pouvez consulter ce guide pour en savoir plus. Si vous souhaitez approfondir votre compréhension des environnements virtuels Python, ce guide est également utile.
Ouvrez un shell Pipenv dans votre dossier de projet en exécutant la commande « pipenv shell ». Cela créera un sous-shell dans votre environnement virtuel. Ensuite, pour installer BeautifulSoup, tapez la commande suivante :
pipenv install beautifulsoup4
Pour installer Requests, saisissez la commande similaire ci-dessous:
pipenv install requests
Une fois l’installation terminée, importez les packages nécessaires dans votre fichier principal. Créez un fichier nommé « main.py » et ajoutez-y les importations suivantes:
from bs4 import BeautifulSoup import requests import json
L’étape suivante consiste à obtenir le contenu de la page de données historiques et à l’analyser avec l’analyseur HTML de BeautifulSoup.
r = requests.get('https://www.coingecko.com/en/coins/ethereum/historical_data#panel')
soup = BeautifulSoup(r.content, 'html.parser')
Dans ce code, la page est récupérée grâce à la méthode « get » de la bibliothèque « requests ». Le contenu analysé est ensuite stocké dans une variable appelée « soup ».
La phase de scraping à proprement parler peut maintenant commencer. Vous devez d’abord identifier correctement le tableau dans le DOM. Si vous ouvrez la page dans votre navigateur et l’inspectez avec les outils de développement, vous constaterez que le tableau possède les classes « table-striped text-sm text-lg-normal ».
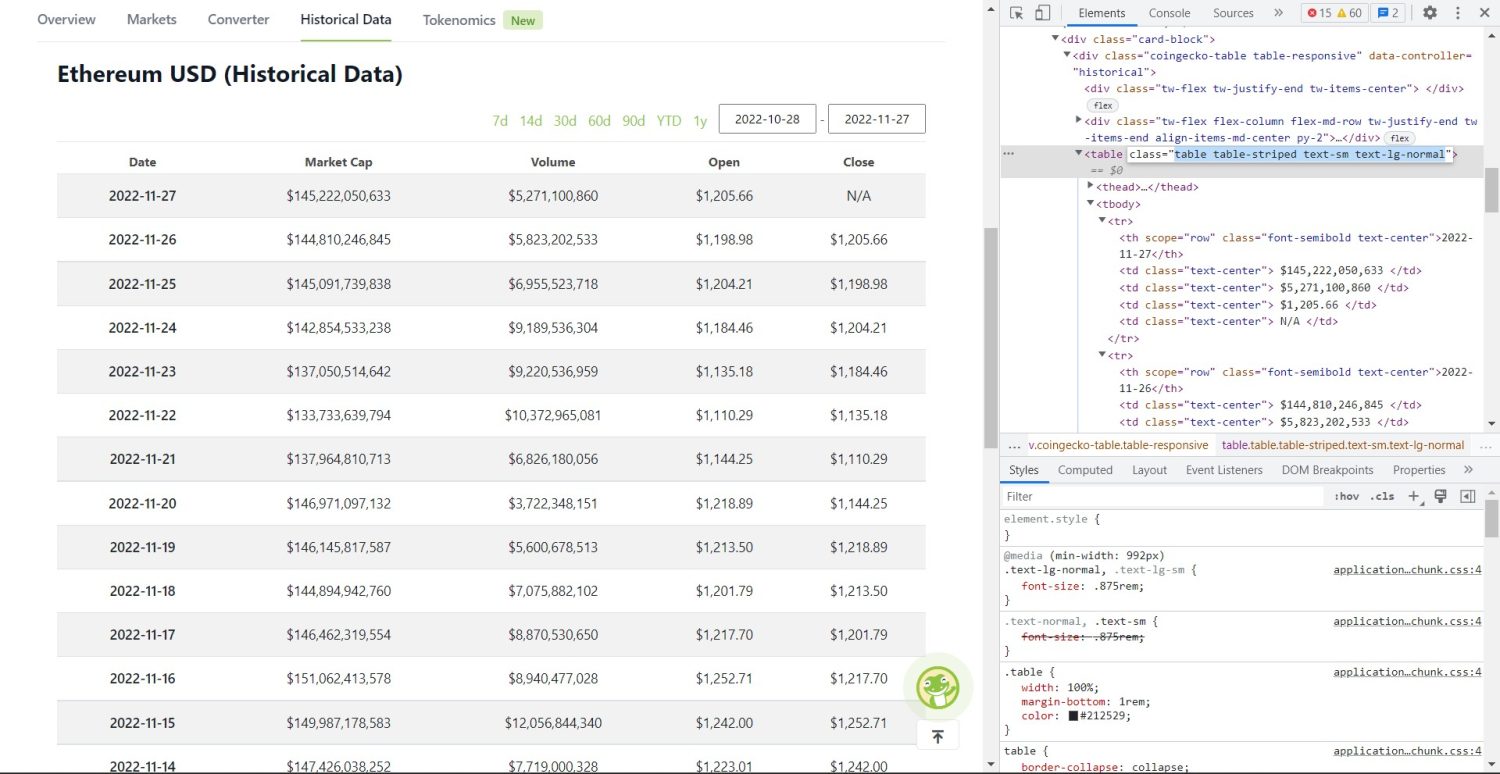 Tableau de données historiques d’Ethereum sur Coingecko
Tableau de données historiques d’Ethereum sur Coingecko
Pour cibler ce tableau, nous utilisons la méthode « find ».
table = soup.find('table', attrs={'class': 'table table-striped text-sm text-lg-normal'})
table_data = table.find_all('tr')
table_headings = []
for th in table_data[0].find_all('th'):
table_headings.append(th.text)
Dans ce code, nous commençons par localiser le tableau avec « soup.find », puis nous utilisons « find_all » pour sélectionner tous les éléments « tr » à l’intérieur du tableau. Ces éléments sont stockés dans la variable « table_data ». Le tableau contient les en-têtes du tableau, que nous stockerons dans la variable « table_headings », une liste initialement vide.
Une boucle « for » parcourt la première ligne du tableau. À l’intérieur de cette ligne, tous les éléments « th » sont récupérés et leur contenu textuel est ajouté à la liste « table_headings ». Le texte est extrait grâce à la méthode « text ». Si vous affichez la variable « table_headings », vous obtiendrez la sortie suivante:
['Date', 'Market Cap', 'Volume', 'Open', 'Close']
L’étape suivante consiste à extraire le reste des éléments du tableau, à créer un dictionnaire pour chaque ligne et à ajouter ces dictionnaires à une liste.
table_details = []
for tr in table_data:
th = tr.find_all('th')
td = tr.find_all('td')
data = {}
for i in range(len(td)):
data.update({table_headings[0]: th[0].text})
data.update({table_headings[i+1]: td[i].text.replace('n', '')})
if len(data) > 0:
table_details.append(data)
Cette partie du code est essentielle. Pour chaque élément « tr » dans la variable « table_data », nous récupérons d’abord les éléments « th » (qui représentent la date dans notre tableau), et les stockons dans la variable « th ». De la même manière, tous les éléments « td » sont placés dans la variable « td ».
Un dictionnaire vide « data » est créé. Ensuite, nous itérons à travers la liste des éléments « td ». Pour chaque ligne, le premier champ du dictionnaire est mis à jour avec le premier élément de « th », en associant la clé « date » à la valeur textuelle de l’élément « th ».
Après avoir initialisé le premier élément, les autres éléments sont assignés en utilisant `data.update({table_headings[i+1]: td[i].text.replace(‘n’, »)})`. Le contenu textuel des éléments « td » est extrait avec la méthode « text », les occurrences de « n » sont supprimées avec « replace », et la valeur est associée à la i+1ème clé de la liste « table_headings ».
Enfin, si le dictionnaire « data » n’est pas vide, nous l’ajoutons à la liste « table_details ». Vous pouvez afficher le contenu de « table_details » pour vérifier les résultats, mais nous allons l’écrire dans un fichier JSON. Voici le code correspondant:
with open('table.json', 'w') as f:
json.dump(table_details, f, indent=2)
print('Data saved to json file...')
Ici, nous utilisons la méthode « json.dump » pour écrire les données dans un fichier JSON nommé « table.json ». Une fois l’écriture terminée, le message « Data saved to json file… » est affiché dans la console.
Exécutez le fichier en utilisant la commande suivante:
python run main.py
Après un court délai, le message « Data saved to json file… » s’affichera dans la console et un fichier nommé « table.json » sera créé dans le répertoire de travail. Ce fichier contiendra des données au format JSON, comme celles-ci:
[
{
"Date": "2022-11-27",
"Market Cap": "$145,222,050,633",
"Volume": "$5,271,100,860",
"Open": "$1,205.66",
"Close": "N/A"
},
{
"Date": "2022-11-26",
"Market Cap": "$144,810,246,845",
"Volume": "$5,823,202,533",
"Open": "$1,198.98",
"Close": "$1,205.66"
},
{
"Date": "2022-11-25",
"Market Cap": "$145,091,739,838",
"Volume": "$6,955,523,718",
"Open": "$1,204.21",
"Close": "$1,198.98"
},
// ...
// ...
]
Vous avez implémenté avec succès un scraper web avec Python. Vous pouvez consulter ce dépôt GitHub pour le code complet.
Conclusion
Cet article a expliqué comment mettre en œuvre un simple scraper en Python. Nous avons exploré l’utilisation de BeautifulSoup pour extraire rapidement des données depuis des sites web. Nous avons également discuté d’autres bibliothèques disponibles et des raisons pour lesquelles Python est le premier choix de nombreux développeurs pour le web scraping.
Vous pouvez également consulter ces autres frameworks de web scraping.