

Il est temps de choisir la meilleure option de base de données sans serveur qui convient le mieux à votre application moderne.
La base de données sans serveur a été spécialement conçue pour gérer des charges de travail imprévisibles qui peuvent changer rapidement. En conséquence, de nombreuses organisations ont adopté l’architecture sans serveur pour créer des architectures modernes pilotées par les événements. Cela a vu sa popularité augmenter au sein de l’écosystème des technologies sans serveur.
Table des matières
Introduction à la base de données sans serveur
L’informatique sans serveur nécessite une base de données sans serveur. Ces bases de données sont spécialement conçues pour gérer des charges de travail imprévisibles qui peuvent changer rapidement. Quoi de plus?
Vous ne pouvez payer que pour les ressources de base de données que vous utilisez par seconde. De plus, les bases de données cloud telles qu’Amazon Aurora, qui sont compatibles avec MySQL et PostgreSQL, peuvent être entièrement gérées et mises à l’échelle jusqu’à 64 To.
Cette base de données peut être créée en choisissant la taille de l’instance. Cela fonctionne bien lorsqu’il existe une charge de travail, un taux de demandes et des exigences de traitement prévisibles.
Il peut être difficile d’organiser la bonne quantité de capacité dans les cas où la charge de travail est imprévisible et où il y a un volume élevé de demandes pour seulement quelques minutes chaque semaine ou un jour. Cependant, ce n’est peut-être pas la meilleure option pour le payer de manière continue.
C’est là que la base de données sans serveur entre en jeu.
Fonctionnalités de base de données sans serveur

Voici les principales fonctionnalités des bases de données sans serveur :
- Accès en temps réel : L’accès à vos données est disponible à un niveau fin. Il indexe automatiquement les données et les rend immédiatement disponibles. Cela vous permet d’interroger, de lire, de mettre à jour et d’ajouter des éléments à votre base de données sans serveur de manière constante. Quoi de plus? Vous pourrez y accéder instantanément via des fonctions.
- Évolutivité infinie : vous pouvez augmenter ou réduire les bases de données sans serveur à tout moment. Ils démarrent et s’arrêtent en fonction des besoins de l’application. Il mettra à l’échelle les unités de calcul (ACU dans le cas d’Aurora Serverless) pour gérer vos requêtes, lire et écrire dans le même cluster de données. Cette automatisation vous permettra d’exécuter toutes vos fonctions simultanément et d’assurer la cohérence de vos données.
- Haute sécurité : les applications modernes peuvent être exposées à des publics malveillants et non fiables à l’échelle mondiale. Il garantit que chaque application interagissant avec la même base de données passe le même protocole de contrôle d’accès. Il réduit la surface d’attaque, qui est un risque crucial pour les entreprises.
- Disponibilité : la base de données sans serveur vous offre la possibilité de réduire la latence. Cette approche permet aux données des fonctions événementielles d’être lues directement par l’utilisateur.
- Schemaless : Schemaless vous permet de gérer toutes les sorties de données de vos fonctions. Il est facile d’intégrer la base de données sans serveur à vos fonctions en utilisant cette approche « tout gérer ». Il s’agit d’une fonctionnalité unique dans les bases de données sans serveur.
Explorons maintenant certaines des meilleures bases de données sans serveur pour les applications modernes.
Faune
Fauna est une base de données distribuée sans serveur. La faune offre une flexibilité extrême. Vous pouvez ajuster plusieurs paramètres pour répondre aux besoins de votre projet. Fauna peut être utilisé comme base de données relationnelle clé-valeur, graphique, basée sur des documents ou traditionnelle. Vous pouvez soit créer un schéma, soit laisser les données en vrac.
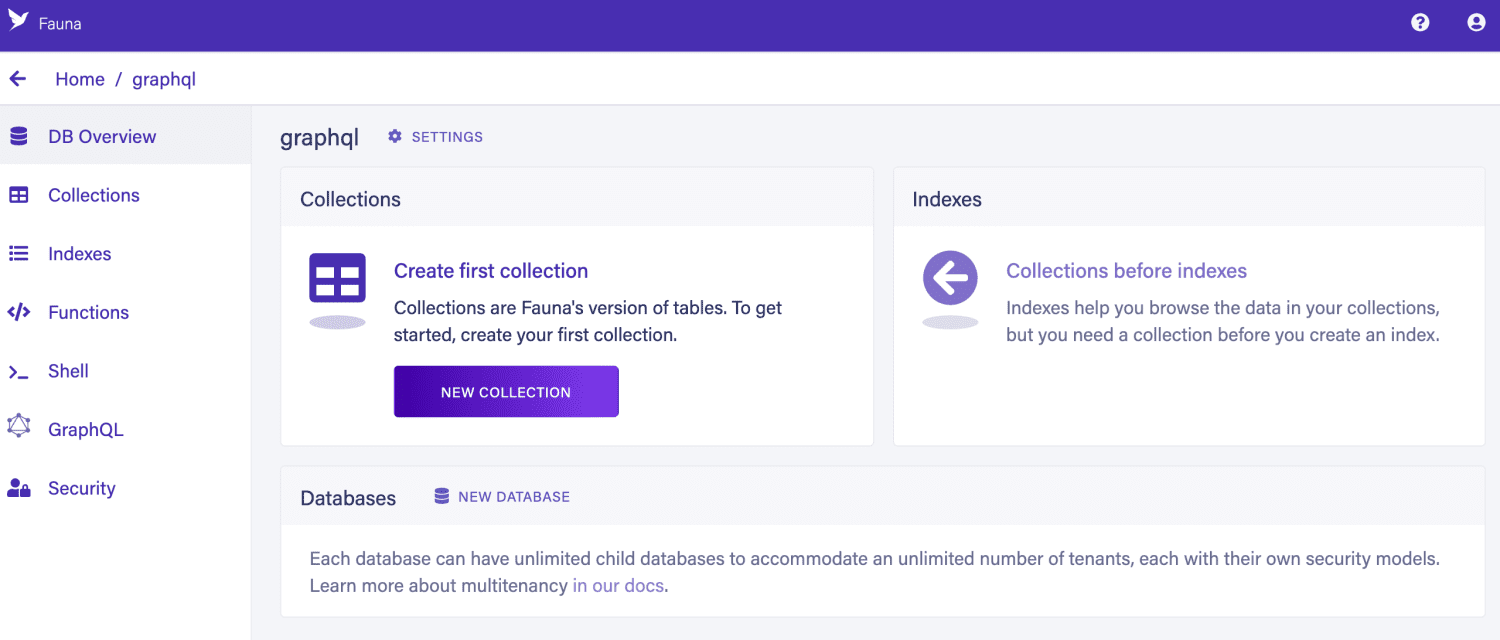
Il est extrêmement polyvalent. Fauna peut être exécuté dans le cloud, sur site ou intégré à notre application. Il offre également les options de déploiement les plus populaires telles que les images de machine ou les images docker. Cette application peut fonctionner à des vitesses très élevées et fonctionne bien avec les transactions ACID.
Amazone Aurore
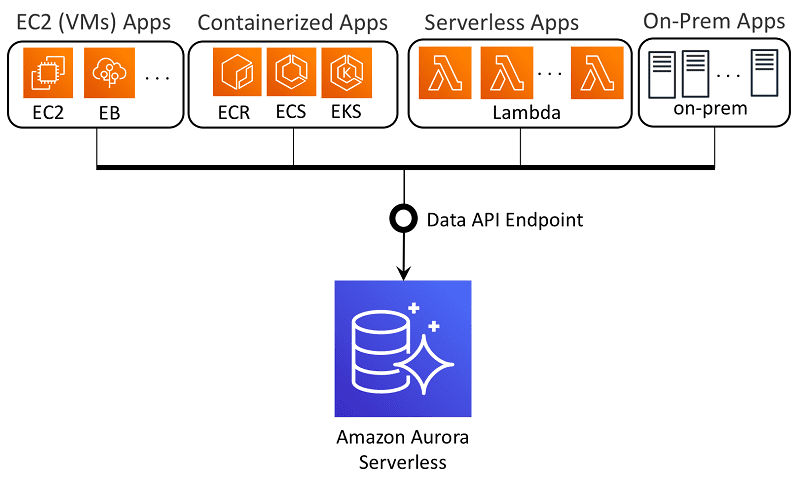
Amazon Aurora est un service de stockage de données relationnelles accessible depuis le cloud Amazon. Ce service est largement utilisé pour le stockage de données. Il permet un stockage de données à faible latence et basé sur la valeur.
 Crédit d’image : AWS
Crédit d’image : AWS
Amazon Aurora est une base de données relationnelle compatible PostgreSQL et MySQL qui consolide l’accessibilité et les performances des bases de données traditionnelles avec la fiabilité et la simplicité des bases de données commerciales à 1/10ème du coût. Il utilise une approche en cluster de la réplication des données dans la zone d’accessibilité d’AWS pour une disponibilité efficace des données.
Amazon Aurora possède de nombreux sous-systèmes hautes performances. Le stockage distribué le plus rapide est utilisé par les moteurs MySQL et PostgreSQL. Aurora accélère le débit et les performances MySQL de 5x et 3x, respectivement, par rapport au système actuel.
La base de données peut être mise à l’échelle jusqu’à 64 téraoctets, ce qui permet de prendre en charge la mise en œuvre en entreprise. Amazon Aurora est entièrement géré par Amazon Relational Database Service (RDS), qui automatise les tâches administratives telles que l’approvisionnement du matériel, l’organisation des données, la réparation, les renforts, etc.
Bit.io
bit.io vous permet de configurer rapidement et facilement une base de données PostgreSQL. Faites glisser et déposez des fichiers pour charger des données dans une base de données PostgreSQL. Vous pouvez également entrer une URL pour un fichier, envoyer des données depuis R ou Python, ou utiliser tout autre client Postgres/HTTP.
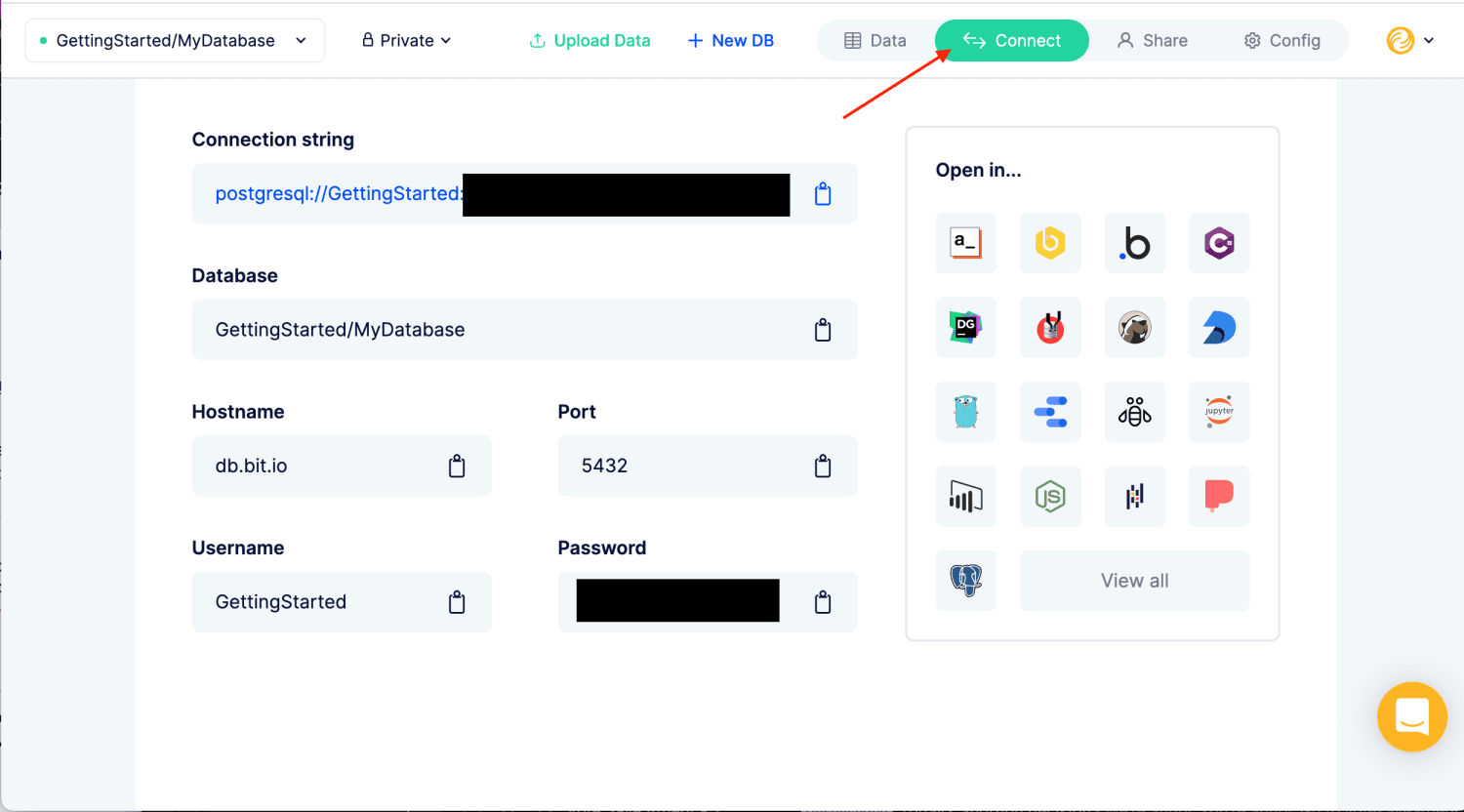
L’éditeur SQL intégré au navigateur vous permet de travailler avec les données à l’aide de l’un de vos outils d’analyse de données préférés, y compris les clients SQL, les blocs-notes R et Python, la ligne de commande et bien d’autres.
bit.io fournit une base de données PostgreSQL complète. Il peut être utilisé rapidement et pratiquement sans configuration. Il s’intègre également à un nombre croissant d’outils de données. bit.io fonctionnera avec n’importe quel outil prenant en charge PostgreSQL.
Upstash
Upstash, une base de données cloud de mémoire sans serveur créée par Upstash Inc (une société basée en Californie). Il peut être utilisé comme couche de mise en cache ou comme base de données. Il ne vous oblige pas à gérer des clusters ou des serveurs de base de données. Il est complètement sans serveur.
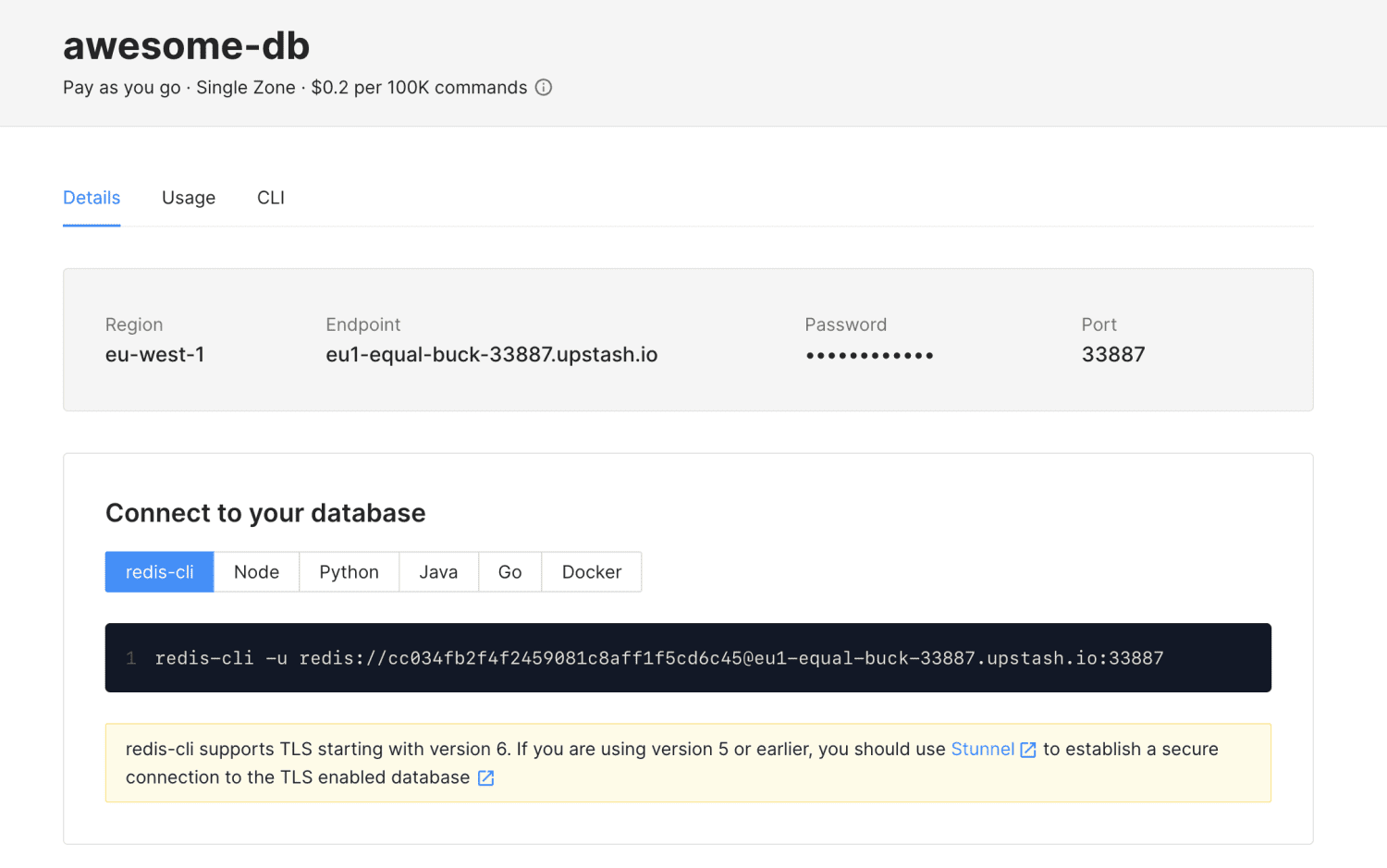
C’est pourquoi les technologies sans serveur telles que Upstash sont si utiles. Upstash ne facture rien si vous ne l’utilisez pas. Upstash peut être utilisé pour les cas d’utilisation populaires de Redis tels que :
- Mise en cache générale
- Mise en cache des sessions
- Classements
- Files d’attente
- Mesure de l’utilisation (comptage)
- Filtrage du contenu
Caractéristiques
- Conçu pour le sans serveur
- Payez au fur et à mesure
- Faible latence
- Stockage durable et rapide
Xata
Xata, une base de données sans serveur, intègre de puissantes fonctions de recherche et d’analyse. Xata utilise un modèle de base de données relationnelle avec un schéma strict (schéma) et prend en charge les objets de type JSON. Les enregistrements sont organisés en tables qui sont ensuite regroupées en bases de données.
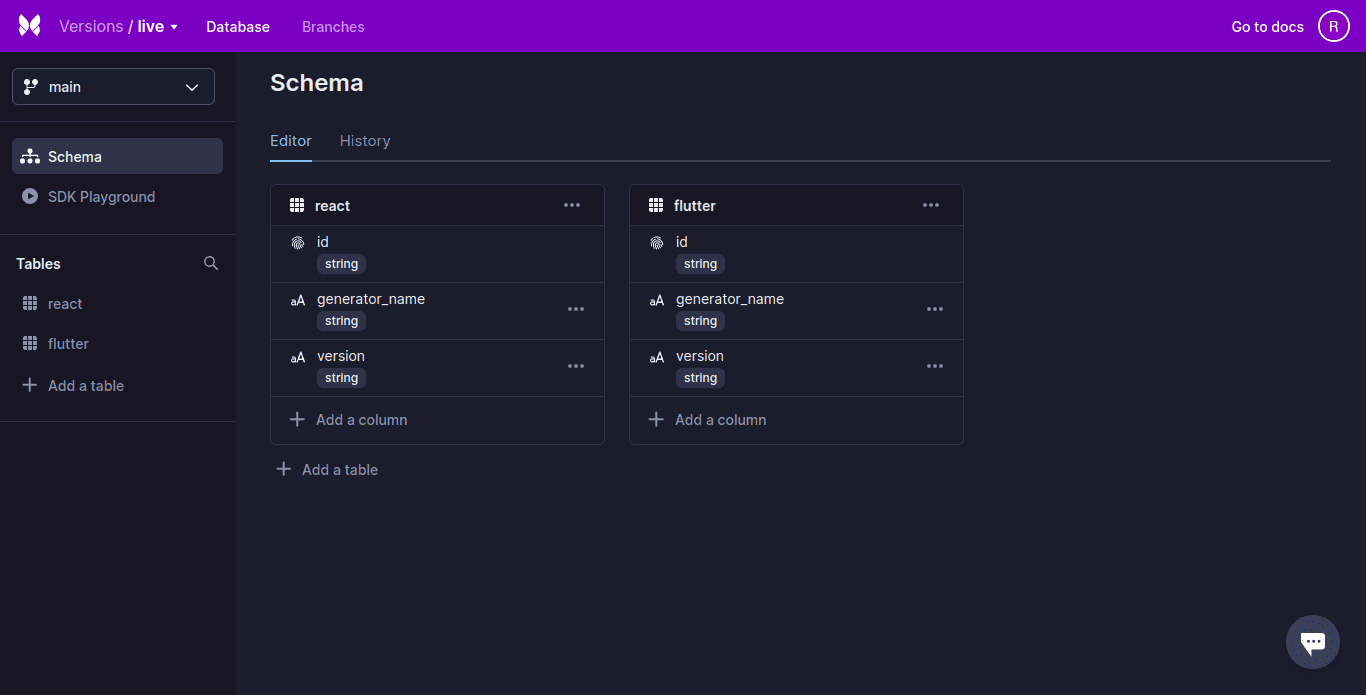
Xata prend en charge les colonnes riches et les relations entre les tables peuvent être représentées à l’aide de colonnes de liens. Celles-ci sont similaires à la clé étrangère.
Xata, un nouveau type de service cloud, offre une couche d’abstraction au-dessus de plusieurs magasins de données pour simplifier le développement et le fonctionnement des applications. Ce type de service s’appelle une plate-forme de données sans serveur. Ce document peut être utilisé pour vous aider à répliquer l’architecture, ce qui vous donnera certains des avantages de l’utilisation de Xata.
SurrealDB
SurrealDB, une base de données cloud NewSQL innovante, peut être utilisée pour les applications sans serveur, jamstack, monopage, traditionnelles et sans serveur. Il offre une flexibilité et une valeur financière inégalées. Il peut être déployé dans des environnements informatiques sur site, intégrés ou en périphérie, ainsi que sur le cloud.
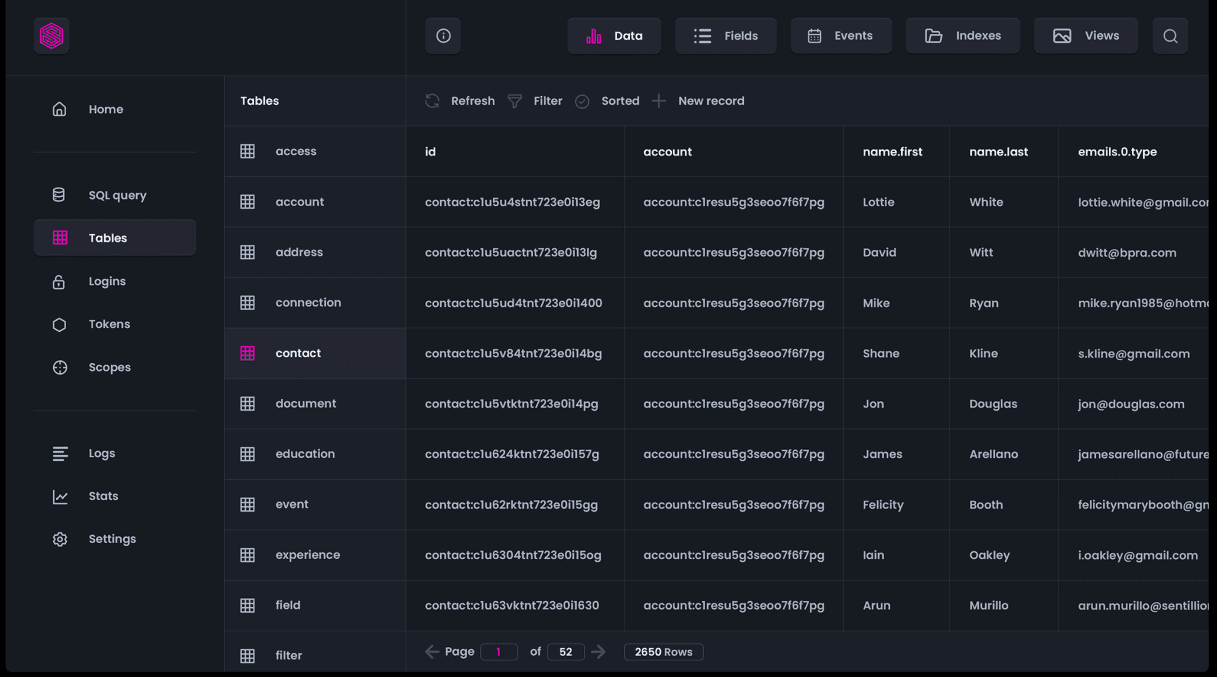
Votre équipe n’a pas besoin de maîtriser des langages de bases de données complexes. Les fonctionnalités avancées sont également simples et directes, mais toujours rapides et performantes. Vous pouvez oublier la mise à l’échelle des serveurs, des bases de données, des équilibreurs de charge et des points de terminaison d’API.
SurrealDB supprime la complexité de votre pile et vous permet d’évoluer avec une plate-forme distribuée et hautement disponible. SurrealDB Cloud vous permet de déployer n’importe où.
CosmosDB
Azure Cosmos DB, une base de données mondiale distribuée basée sur JSON, est disponible en tant que « Platform as a Service (PaaS) » dans Microsoft Azure. Il permet aux utilisateurs de créer et de distribuer automatiquement des applications dans les centres de données Azure sans configuration.
Il fait partie d’Azure et est disponible dans toutes les régions. Il réplique également les données sur plusieurs centres de données du réseau.
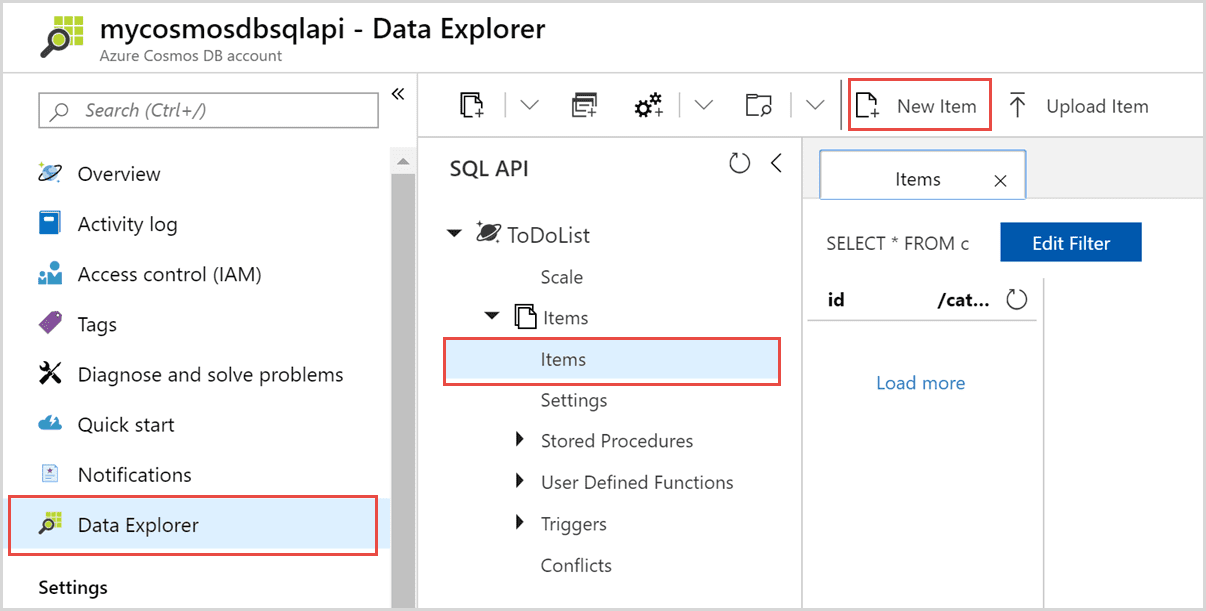
Il existe de nombreuses interfaces disponibles, la plus intéressante étant basée sur SQL. CosmosDB est le service idéal pour les organisations qui traitent, interrogent et gèrent de nombreuses informations importantes et éphémères.
CafardDB
CockroachDB, une base de données SQL distribuée construite sur une clé-valeur cohérente et un magasin transactionnel, s’appelle CockroachDB.
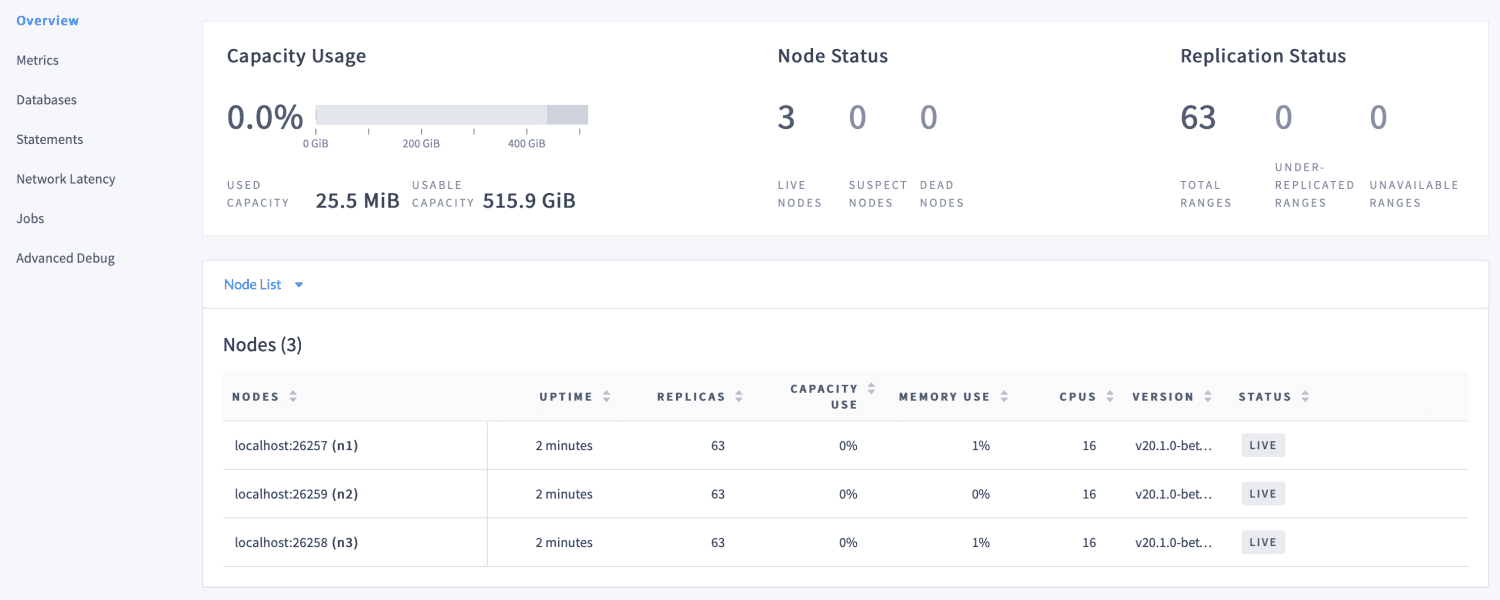
Il est écrit en Go et est entièrement open-source. Ses principaux objectifs incluent la prise en charge des transactions ACID, la mise à l’échelle horizontale et la capacité de survie. Il vise à tout tolérer, d’une panne de disque unique à une opération complète de reprise après sinistre, sans aucune intervention manuelle et avec une interruption de latence minimale.
CockroachDB est un bon choix pour les applications qui ont besoin de données fiables, précises et disponibles à toutes les échelles. Vous pouvez accéder à l’interface utilisateur d’administration, qui est fournie avec CockroachDB à l’adresse http://localhost:8080 dès que le cluster est opérationnel.
Il fournit des informations sur la configuration du cluster et de la base de données et nous aide à optimiser les performances du cluster en surveillant des métriques telles que la santé, les métriques d’exécution, la réplication et les détails des nœuds.
PlanèteÉchelle
PlanetScale, une nouvelle plate-forme DBaaS, vous permet de créer rapidement une base de données sans aucune gestion de connexion. Les bases de données PlanetScale ont été conçues pour les développeurs et leurs workflows. Vous pouvez déployer une base de données entièrement gérée qui bénéficie de la fiabilité et de la flexibilité de MySQL. Leurs bases de données sont construites sur MySQL 8.0.
PlanetScale propose deux types de branches de bases de données : production et développement. Sa fonctionnalité de branchement vous permet de traiter vos bases de données comme du code. Vous pouvez créer une branche à partir de votre schéma de base de données de production qui sera utilisée pour les environnements de développement isolés.
Conclusion
Il s’agissait donc des meilleures bases de données sans serveur pour les applications modernes. Les bases de données sans serveur, et en particulier Amazon Aurora Serverless, sont un avenir prometteur. Parce que maintenant, nous pouvons nous concentrer sur l’essentiel de l’accès en temps réel aux données, de l’évolutivité et de la sécurité avec cette nouvelle technologie.
Vous pourriez également être intéressé par 7 façons dont l’informatique sans serveur est une technologie en plein essor.