13 outils de génération de données synthétiques pour former des modèles d'apprentissage automatique
L'Essor des Données Synthétiques
Dans le domaine de l'apprentissage automatique, du test d'applications et de l'analyse commerciale, les données sont devenues une ressource absolument indispensable.
Cependant, l'impératif de se conformer aux multiples réglementations sur la protection des données implique souvent un confinement strict des données, nécessitant des mois d'approbations pour y accéder. Une alternative prometteuse pour les entreprises est l'utilisation de données synthétiques.
Qu'est-ce que les Données Synthétiques ?
Crédit photo : Twinify
Les données synthétiques sont des données créées de manière artificielle qui imitent statistiquement des ensembles de données existants. Elles peuvent être utilisées conjointement avec des données réelles pour renforcer et améliorer les modèles d'IA, ou encore comme substitut complet.
Étant donné qu'elles ne sont rattachées à aucune personne physique et ne contiennent aucune information d'identification personnelle ni données sensibles, telles que les numéros de sécurité sociale, elles offrent une alternative respectueuse de la vie privée aux données de production réelles.
Différences Fondamentales entre Données Réelles et Synthétiques
- La divergence la plus significative réside dans leur processus de création. Les données réelles proviennent de sources concrètes, issues de collectes via des enquêtes ou l'utilisation d'applications. Les données synthétiques, quant à elles, sont générées artificiellement, tout en conservant les caractéristiques de l'ensemble de données original.
- Un autre point de différenciation concerne l'impact des réglementations sur la protection des données. Les données réelles sont soumises à des obligations de transparence vis-à-vis des sujets concernés (information sur les données collectées et leur finalité) et à des restrictions d'utilisation. Ces contraintes n'existent pas pour les données synthétiques qui ne sont pas attribuables à une personne physique et ne contiennent pas d'informations personnelles.
- Enfin, la disponibilité en termes de quantité est également un facteur distinctif. Avec les données réelles, la quantité est limitée à ce que les utilisateurs consentent à fournir. En revanche, il est possible de générer des volumes de données synthétiques illimités.
Pourquoi Opter pour les Données Synthétiques ?
- Leur coût de production est généralement plus faible. Il est possible de générer des ensembles de données massifs similaires à un ensemble de données initial plus petit. Cela permet d'améliorer l'entraînement des modèles d'apprentissage automatique.
- Les données générées sont souvent étiquetées et nettoyées automatiquement, évitant ainsi les tâches fastidieuses de préparation de données pour l'apprentissage automatique ou l'analyse.
- L'absence de préoccupations en matière de confidentialité est un avantage majeur : les données ne sont pas personnellement identifiables et ne sont rattachées à aucun individu. Ceci facilite leur utilisation et leur partage.
- Elles permettent de lutter contre les biais de l'IA en garantissant une représentation équitable des classes minoritaires, contribuant ainsi à une IA plus juste et responsable.
Comment Générer des Données Synthétiques ?
Bien que le processus exact varie selon l'outil utilisé, il commence généralement par la connexion du générateur à un ensemble de données existant. L'étape suivante consiste à identifier les champs d'identification personnelle dans cet ensemble et à les marquer pour exclusion ou anonymisation.
Le générateur procède alors à l'identification des types de données et des modèles statistiques présents dans les colonnes restantes. Dès lors, il devient possible de créer autant de données synthétiques que nécessaire.
En règle générale, il est conseillé de comparer les données générées avec l'ensemble de données initial afin d'évaluer la fidélité de la réplication.
Explorons maintenant quelques outils de génération de données synthétiques pour entraîner des modèles d'apprentissage automatique.
Mostly AI
Mostly AI offre un générateur de données synthétiques basé sur l'IA, capable d'apprendre à partir des modèles statistiques de l'ensemble de données d'origine. Il génère ensuite des ensembles de données fictifs conformes à ces modèles.
Avec Mostly AI, il est possible de générer des bases de données complètes avec intégrité référentielle. L'outil permet de synthétiser une grande variété de données, améliorant ainsi la qualité des modèles d'IA.
Synthesized.io
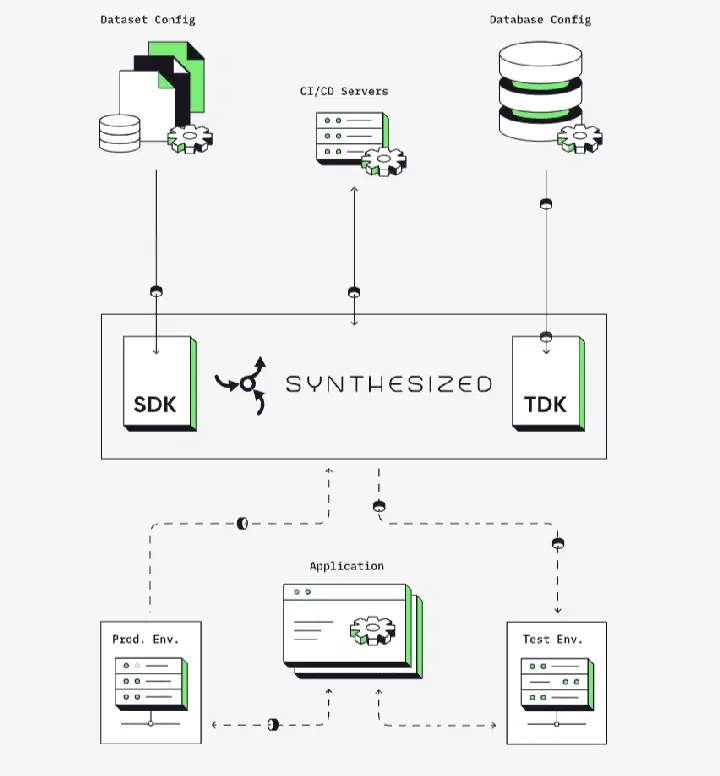
Synthesized.io est utilisé par des entreprises de premier plan pour leurs projets d'IA. Son fonctionnement repose sur la définition des besoins en données dans un fichier de configuration YAML.
Une tâche est ensuite créée et exécutée au sein d'un pipeline de données. Synthesized.io propose une formule gratuite très généreuse permettant de tester l'outil et d'évaluer sa pertinence par rapport aux besoins spécifiques.
YData

YData permet de générer des données tabulaires, chronologiques, transactionnelles, multi-tables et relationnelles, palliant ainsi les difficultés liées à la collecte, au partage et à la qualité des données.
YData est doté d'une IA et d'un SDK pour une interaction aisée avec la plateforme. Une version gratuite est également disponible pour tester le produit.
Gretel AI

Gretel AI propose des API pour la génération illimitée de données synthétiques. L'outil dispose d'un générateur de données open source installable et utilisable par tous.
Une API REST ou une CLI sont également disponibles, avec un coût variable. Le prix est néanmoins adapté à la taille des entreprises.
Copulas
Copulas est une bibliothèque Python open source permettant de modéliser des distributions multivariées à l'aide de fonctions de copule et de créer des données synthétiques aux mêmes propriétés statistiques.
Ce projet a vu le jour en 2018 au MIT dans le cadre du projet Synthetic Data Vault.
CTGAN
CTGAN est constitué de générateurs capables d'apprendre à partir de données réelles issues d'une seule table et de générer des données synthétiques basées sur les modèles ainsi identifiés.
Il est implémenté en tant que bibliothèque Python open-source. CTGAN, tout comme Copulas, fait partie intégrante du projet Synthetic Data Vault.
DoppelGANger
DoppelGANger est une implémentation open-source des Generative Adversarial Networks pour la génération de données synthétiques.
DoppelGANger est particulièrement adapté à la création de données de séries chronologiques et est utilisé par des entreprises telles que Gretel AI. La bibliothèque Python est disponible gratuitement et en open-source.
Synth
Synth est un générateur de données open source qui facilite la création de données réalistes selon des spécifications précises. Il permet également de masquer les informations personnelles et de développer des données de test pour les applications.
Synth peut être utilisé pour générer des séries en temps réel et des données relationnelles pour les besoins de l'apprentissage automatique. Il est indépendant de la base de données, ce qui permet de l'utiliser avec des bases de données SQL et NoSQL.
SDV.dev

SDV, acronyme de Synthetic Data Vault, est un projet logiciel initié au MIT en 2016, qui a donné naissance à divers outils pour la génération de données synthétiques.
Parmi ces outils, on retrouve Copulas, CTGAN, DeepEcho et RDT. Ils sont tous implémentés sous forme de bibliothèques Python open source.
Tofu
Tofu est une bibliothèque Python open source, spécialisée dans la génération de données synthétiques à partir des données de la biobanque britannique. Contrairement aux outils précédents, qui génèrent n'importe quel type de données à partir d'un ensemble existant, Tofu est spécifiquement conçu pour les données ressemblant à celles de la biobanque.
La UK Biobank est une étude axée sur les caractéristiques phénotypiques et génotypiques de 500 000 adultes d'âge moyen du Royaume-Uni.
Twinify
Twinify est un progiciel utilisable comme bibliothèque ou outil en ligne de commande pour le jumelage de données sensibles, en produisant des données synthétiques avec des distributions statistiques identiques.

Son utilisation est basée sur l'importation de données réelles sous forme de fichier CSV, à partir desquelles l'outil apprend pour créer un modèle apte à générer des données synthétiques. Son utilisation est entièrement gratuite.
Datanamique
Datanamic facilite la création de données de test pour les applications basées sur les données et l'apprentissage automatique. L'outil génère des données en fonction de caractéristiques de colonne, telles que l'adresse e-mail, le nom et le numéro de téléphone.
Les générateurs de données Datanamic sont personnalisables et compatibles avec la plupart des bases de données, dont Oracle, MySQL, MySQL Server, MS Access et Postgres. Ils assurent également l'intégrité référentielle des données générées.
Benerator
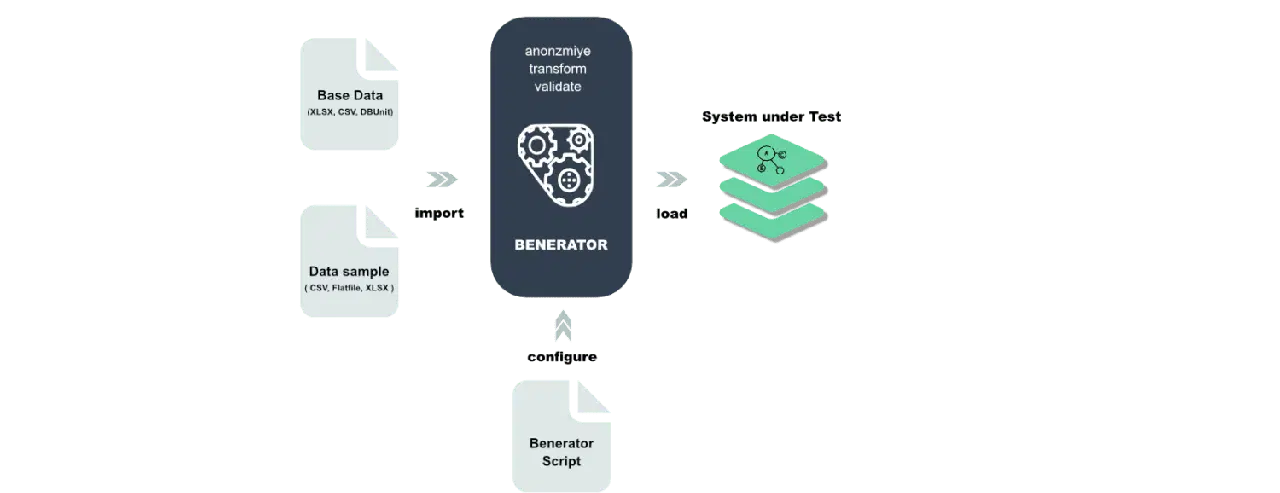
Benerator est un logiciel conçu pour l'obscurcissement, la génération et la migration de données à des fins de test et de formation. L'outil permet de décrire les données en XML (Extensible Markup Language) et de les générer à l'aide d'une ligne de commande.
Pensé pour les non-développeurs, Benerator permet de générer des milliards de lignes de données. Il est gratuit et open-source.
Conclusion
Selon les prévisions de Gartner, les données synthétiques seront plus largement utilisées que les données réelles dans le domaine de l'apprentissage automatique d'ici 2030.
Les problèmes de coût et de confidentialité liés à l'utilisation des données réelles justifient cet essor. Il est donc essentiel que les entreprises se familiarisent avec les données synthétiques et les outils permettant de les générer.
Pour aller plus loin, découvrez les outils de surveillance synthétiques pour votre activité en ligne.