
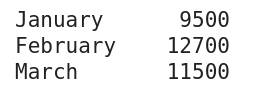
Pandas est la bibliothèque d’analyse de données la plus populaire pour Python. Il est largement utilisé par les analystes de données, les scientifiques des données et les ingénieurs en apprentissage automatique.
Aux côtés de NumPy, c’est l’une des bibliothèques et des outils incontournables pour quiconque travaille avec les données et l’IA.
Dans cet article, nous allons explorer Pandas et les fonctionnalités qui le rendent si populaire dans l’écosystème des données.
Table des matières
C’est quoi Pandas ?
Pandas est une bibliothèque d’analyse de données pour Python. Cela signifie qu’il est utilisé pour travailler et manipuler des données à partir de votre code Python. Avec Pandas, vous pouvez efficacement lire, manipuler, visualiser, analyser et stocker des données.
Le nom « Pandas » vient de l’association des mots Panel Data, un terme économétrique qui fait référence aux données obtenues en observant plusieurs individus au fil du temps. Pandas a été initialement publié en janvier 2008 par Wes Kinney, et il est depuis devenu la bibliothèque la plus populaire pour son cas d’utilisation.
Au cœur de Pandas se trouvent deux structures de données essentielles que vous devez connaître, Dataframes et Series. Lorsque vous créez ou chargez un jeu de données dans Pandas, il est représenté comme l’une de ces deux structures de données.
Dans la section suivante, nous explorerons ce qu’ils sont, en quoi ils sont différents et quand utiliser l’un d’entre eux est idéal.
Structures de données clés
Comme mentionné précédemment, toutes les données dans Pandas sont représentées à l’aide de l’une des deux structures de données, une Dataframe ou une Series. Ces deux structures de données sont expliquées en détail ci-dessous.
Trame de données
Cet exemple de trame de données a été produit à l’aide de l’extrait de code au bas de cette section
Une Dataframe dans Pandas est une structure de données bidimensionnelle avec des colonnes et des lignes. Il est similaire à une feuille de calcul dans votre application de tableur ou à une table dans une base de données relationnelle.
Il est composé de colonnes, et chaque colonne représente un attribut ou une caractéristique de votre ensemble de données. Ces colonnes sont alors constituées de valeurs individuelles. Cette liste ou série de valeurs individuelles est représentée sous la forme d’objets Series. Nous discuterons plus en détail de la structure des données de la série plus loin dans cet article.
Les colonnes d’un dataframe peuvent avoir des noms descriptifs afin de les distinguer les unes des autres. Ces noms sont attribués lors de la création ou du chargement de la trame de données, mais peuvent être facilement renommés à tout moment.
Les valeurs d’une colonne doivent être du même type de données, bien que les colonnes ne doivent pas nécessairement contenir des données du même type. Cela signifie qu’une colonne de nom dans un ensemble de données stockera exclusivement des chaînes. Mais le même jeu de données peut avoir d’autres colonnes comme age qui stockent des entiers.
Les dataframes ont également un index utilisé pour référencer les lignes. Les valeurs dans différentes colonnes mais avec le même index forment une ligne. Par défaut, les index sont numérotés mais peuvent être réaffectés en fonction de l’ensemble de données. Dans l’exemple (illustré ci-dessus, codé ci-dessous), nous définissons la colonne d’index sur la colonne « mois ».
import pandas as pd
sales_df = pd.DataFrame({
'Month': ['January', 'February', 'March'],
'Jane Doe': [5000, 6000, 5500],
'John Doe': [4500, 6700, 6000]
})
sales_df.set_index(['Month'], inplace=True)
print(sales_df)Série
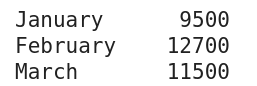 Cet exemple de série a été produit en utilisant le code au bas de cette section
Cet exemple de série a été produit en utilisant le code au bas de cette section
Comme indiqué précédemment, une série est utilisée pour représenter une colonne de données dans Pandas. Une série est donc une structure de données unidimensionnelle. Cela contraste avec une Dataframe bidimensionnelle.
Bien qu’une série soit couramment utilisée comme colonne dans une trame de données, elle peut également représenter un ensemble de données complet, à condition que l’ensemble de données n’ait qu’un seul attribut enregistré dans une seule colonne. Ou plutôt, l’ensemble de données est simplement une liste de valeurs.
Parce qu’une série est simplement une colonne, elle n’a pas besoin d’avoir un nom. Cependant, les valeurs de la série sont indexées. Comme l’index d’un Dataframe, le dataframe d’une Series peut être modifié à partir de la numérotation par défaut.
Dans l’exemple (illustré ci-dessus, codé ci-dessous), l’index a été défini sur différents mois à l’aide de la méthode set_axis d’un objet Pandas Series.
import pandas as pd total_sales = pd.Series([9500, 12700, 11500]) months = ['January', 'February', 'March'] total_sales = total_sales.set_axis(months) print(total_sales)
Caractéristiques des pandas
Maintenant que vous avez une bonne idée de ce qu’est Pandas et des structures de données clés qu’il utilise, nous pouvons commencer à discuter des fonctionnalités qui font de Pandas une bibliothèque d’analyse de données si puissante et, par conséquent, incroyablement populaire au sein de la science des données et de l’apprentissage automatique. Écosystèmes.
#1. Manipulation de données
Les objets Dataframe et Series sont modifiables. Vous pouvez ajouter ou supprimer des colonnes selon vos besoins. De plus, Pandas vous permet d’ajouter des lignes et même de fusionner des ensembles de données.
Vous pouvez effectuer des calculs numériques, tels que la normalisation des données et la réalisation de comparaisons logiques élément par élément. Pandas vous permet également de regrouper des données et d’appliquer des fonctions agrégées telles que moyenne, moyenne, max et min. Cela facilite le travail avec les données dans Pandas.
#2. Nettoyage des données
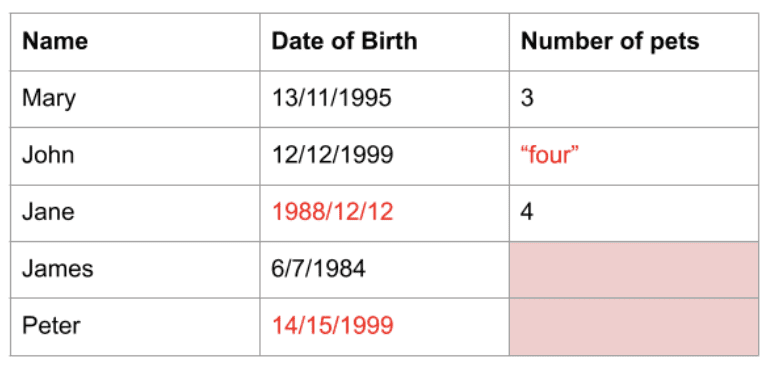
Les données obtenues dans le monde réel ont souvent des valeurs qui les rendent difficiles à utiliser ou qui ne sont pas idéales pour l’analyse ou l’utilisation dans des modèles d’apprentissage automatique. Les données peuvent être du mauvais type de données, dans le mauvais format, ou elles peuvent simplement manquer complètement. Dans tous les cas, ces données nécessitent un prétraitement, appelé nettoyage, avant de pouvoir être utilisées.
Pandas a des fonctions pour vous aider à nettoyer vos données. Par exemple, dans Pandas, vous pouvez supprimer des lignes en double, supprimer des colonnes ou des lignes avec des données manquantes et remplacer les valeurs par des valeurs par défaut ou une autre valeur, telle que la moyenne de la colonne. Il existe plus de fonctions et de bibliothèques qui fonctionnent avec Pandas pour vous permettre de faire plus de nettoyage des données.
#3. Visualisation de données
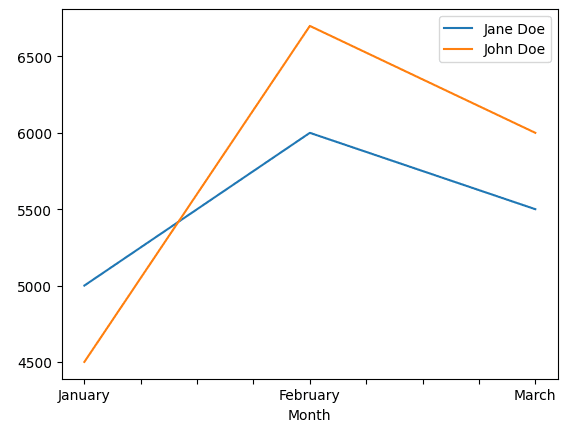 Ce graphique a été généré avec le code sous cette section
Ce graphique a été généré avec le code sous cette section
Bien qu’il ne s’agisse pas d’une bibliothèque de visualisation comme Matplotlib, Pandas dispose de fonctions permettant de créer des visualisations de données de base. Et bien qu’ils soient basiques, ils font toujours le travail dans la plupart des cas.
Avec Pandas, vous pouvez facilement tracer des graphiques à barres, des histogrammes, des matrices de dispersion et d’autres types de graphiques. Combinez cela avec certaines manipulations de données que vous pouvez effectuer en Python, et vous pouvez créer des visualisations encore plus compliquées pour mieux comprendre vos données.
import pandas as pd
sales_df = pd.DataFrame({
'Month': ['January', 'February', 'March'],
'Jane Doe': [5000, 6000, 5500],
'John Doe': [4500, 6700, 6000]
})
sales_df.set_index(['Month'], inplace=True)
sales_df.plot.line()#4. Analyse des séries chronologiques
Pandas prend également en charge le travail avec des données horodatées. Lorsque Pandas reconnaît une colonne comme ayant des valeurs datetime, vous pouvez effectuer de nombreuses opérations sur la même colonne qui sont utiles lorsque vous travaillez avec des données de séries chronologiques.
Il s’agit notamment de regrouper les observations par période et de leur appliquer des fonctions d’agrégation, telles que la somme ou la moyenne, ou d’obtenir les observations les plus anciennes ou les plus récentes à l’aide de min et max. Il y a, bien sûr, beaucoup plus de choses que vous pouvez faire avec les données de séries chronologiques dans Pandas.
#5. Entrée/Sortie dans Pandas
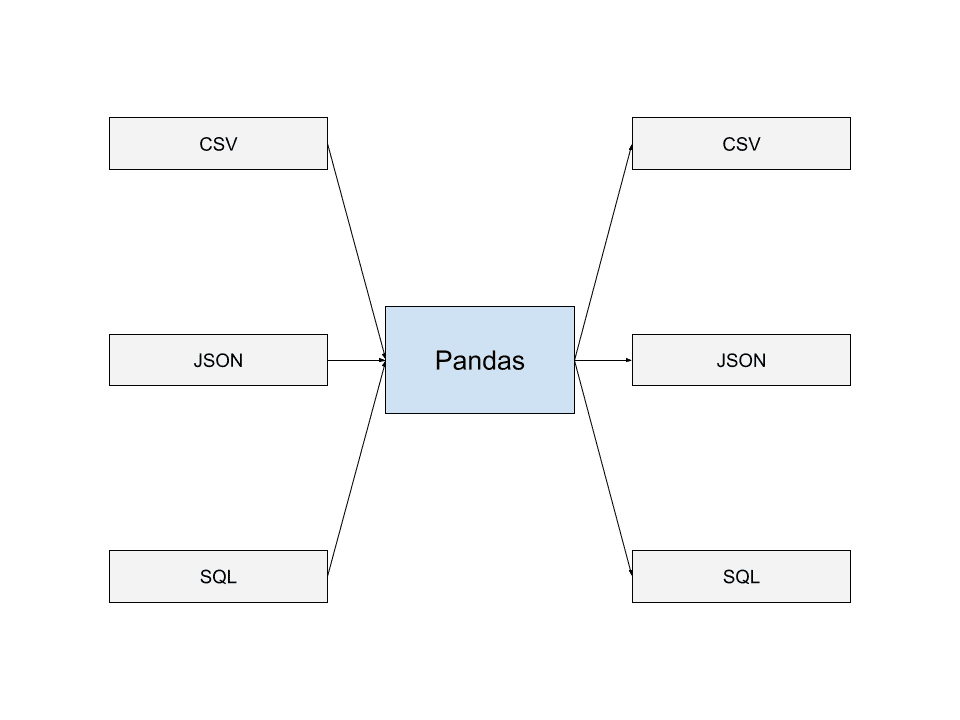
Pandas est capable de lire des données à partir des formats de stockage de données les plus courants. Ceux-ci incluent JSON, les vidages SQL et les fichiers CSV. Vous pouvez également écrire des données dans des fichiers dans plusieurs de ces formats.
Cette capacité à lire et à écrire dans différents formats de fichiers de données permet à Pandas d’interagir de manière transparente avec d’autres applications et de créer des pipelines de données qui s’intègrent bien avec Pandas. C’est l’une des raisons pour lesquelles Pandas est largement utilisé par de nombreux développeurs.
#6. Intégration avec d’autres bibliothèques
Pandas dispose également d’un riche écosystème d’outils et de bibliothèques construits dessus pour compléter ses fonctionnalités. Cela en fait une bibliothèque encore plus puissante et utile.
Les outils de l’écosystème Pandas améliorent ses fonctionnalités dans différents domaines, notamment le nettoyage des données, la visualisation, l’apprentissage automatique, les entrées/sorties et la parallélisation. Pandas tient un registre de ces outils dans sa documentation.
Considérations de performance et d’efficacité dans Pandas
Bien que Pandas brille dans la plupart des opérations, il peut être notoirement lent. Le bon côté est que vous pouvez optimiser votre code et améliorer sa vitesse. Pour ce faire, vous devez comprendre comment Pandas est construit.
Pandas est construit sur NumPy, une bibliothèque Python populaire pour le calcul numérique et scientifique. Par conséquent, comme NumPy, Pandas fonctionne plus efficacement lorsque les opérations sont vectorisées au lieu de sélectionner des cellules ou des lignes individuelles à l’aide de boucles.
La vectorisation est une forme de parallélisation où la même opération est appliquée à plusieurs points de données à la fois. C’est ce qu’on appelle SIMD – Instruction unique, données multiples. Tirer parti des opérations vectorisées améliorera considérablement la vitesse et les performances de Pandas.
Parce qu’ils utilisent des tableaux NumPy sous le capot, les structures de données DataFrame et Series sont plus rapides que leurs dictionnaires et listes alternatifs.
L’implémentation par défaut de Pandas s’exécute sur un seul cœur de processeur. Une autre façon d’accélérer votre code consiste à utiliser des bibliothèques qui permettent à Pandas d’utiliser tous les cœurs de processeur disponibles. Ceux-ci incluent Dask, Vaex, Modin et IPython.
Communauté et ressources
En tant que bibliothèque populaire du langage de programmation le plus populaire, Pandas possède une large communauté d’utilisateurs et de contributeurs. En conséquence, il existe de nombreuses ressources à utiliser pour apprendre à l’utiliser. Ceux-ci incluent la documentation officielle de Pandas. Mais il existe également d’innombrables cours, tutoriels et livres à partir desquels apprendre.
Il existe également des communautés en ligne sur des plateformes telles que Reddit dans les sous-reddits r/Python et r/Data Science pour poser des questions et obtenir des réponses. Étant une bibliothèque open source, vous pouvez signaler des problèmes sur GitHub et même contribuer au code.
Derniers mots
Pandas est incroyablement utile et puissant en tant que bibliothèque de science des données. Dans cet article, j’ai essayé d’expliquer sa popularité en explorant les fonctionnalités qui en font l’outil incontournable pour les data scientists et les programmeurs.
Ensuite, découvrez comment créer un Pandas DataFrame.