Voici pourquoi Pandas est la bibliothèque d'analyse de données Python la plus populaire
Pandas se positionne comme la bibliothèque d'analyse de données la plus prisée pour Python. Son utilisation est largement répandue parmi les analystes de données, les scientifiques des données et les spécialistes de l'apprentissage automatique.
En collaboration avec NumPy, elle constitue l'un des outils et bibliothèques incontournables pour quiconque manipule des données et travaille avec l'IA.
Dans cet article, nous plongerons dans l'univers de Pandas et explorerons les particularités qui expliquent sa popularité au sein de l'écosystème des données.
Qu'est-ce que Pandas ?
Pandas est une bibliothèque dédiée à l'analyse de données pour Python. Cela signifie qu'elle sert à traiter et manipuler les données directement depuis votre code Python. Avec Pandas, vous avez la capacité de lire, manipuler, visualiser, analyser et stocker des données de manière efficace.
Le nom "Pandas" est dérivé de l'association des mots "Panel Data", un terme économétrique désignant les données recueillies en observant plusieurs individus au cours du temps. Initialement lancée en janvier 2008 par Wes Kinney, Pandas est depuis devenue la bibliothèque phare dans son domaine d'application.
Au cœur de Pandas se trouvent deux structures de données fondamentales que vous devez absolument connaître : les DataFrames et les Series. Lors de la création ou du chargement d'un jeu de données dans Pandas, celui-ci est représenté sous l'une de ces deux formes.
Dans la section suivante, nous allons examiner plus en détail ces structures, en quoi elles diffèrent et les situations où l'utilisation de l'une est plus appropriée que l'autre.
Structures de données principales
Comme mentionné précédemment, toutes les données dans Pandas sont structurées à l'aide de l'une de ces deux entités : le DataFrame ou la Series. Ces deux structures de données sont détaillées ci-dessous.
DataFrame
L'exemple de DataFrame présenté ici a été généré grâce au fragment de code disponible à la fin de cette section.
Un DataFrame, dans le cadre de Pandas, se définit comme une structure de données bidimensionnelle, organisée en colonnes et en lignes. Il est comparable à une feuille de calcul dans votre tableur ou à une table dans une base de données relationnelle.
Il est composé de colonnes, chacune représentant un attribut ou une caractéristique de votre ensemble de données. Ces colonnes sont ensuite constituées de valeurs individuelles. Cette liste ou série de valeurs individuelles est représentée sous la forme d'objets Series. Nous aborderons la structure des données de la Series plus en détail dans cet article.
Les colonnes d'un DataFrame peuvent être nommées de manière descriptive afin de les distinguer. Ces noms sont attribués lors de la création ou du chargement du DataFrame, mais ils peuvent être facilement modifiés à tout moment.
Les valeurs d'une même colonne doivent être du même type de données, tandis que les colonnes elles-mêmes peuvent contenir des données de types différents. Par exemple, une colonne contenant des noms ne contiendra que des chaînes de caractères, alors qu'une autre colonne, comme l'âge, ne contiendra que des nombres entiers.
Les DataFrames possèdent également un index servant à référencer les lignes. Les valeurs des différentes colonnes ayant le même index constituent une ligne. Par défaut, les index sont numériques, mais ils peuvent être personnalisés en fonction de l'ensemble de données. Dans l'exemple (illustré ci-dessus et codé ci-dessous), nous avons défini la colonne "mois" comme index.
import pandas as pd
sales_df = pd.DataFrame({
'Month': ['January', 'February', 'March'],
'Jane Doe': [5000, 6000, 5500],
'John Doe': [4500, 6700, 6000]
})
sales_df.set_index(['Month'], inplace=True)
print(sales_df)
Series
L'exemple de Series illustré a été créé à partir du code situé à la fin de cette section.
Comme indiqué précédemment, une Series est employée pour représenter une colonne de données dans Pandas. C'est donc une structure de données unidimensionnelle, contrairement au DataFrame, qui est bidimensionnel.
Bien qu'une Series soit fréquemment utilisée en tant que colonne dans un DataFrame, elle peut aussi représenter un ensemble de données complet, à condition que celui-ci ne possède qu'un seul attribut enregistré dans une unique colonne. En d'autres termes, l'ensemble de données est simplement une liste de valeurs.
Étant donné qu'une Series n'est qu'une colonne, elle n'a pas forcément besoin de nom. Cependant, les valeurs de la Series sont indexées. De même que pour les DataFrames, l'index d'une Series peut être modifié et ne plus être une simple numérotation par défaut.
Dans l'exemple (illustré ci-dessus et codé ci-dessous), l'index a été défini sur différents mois en utilisant la méthode "set_axis" d'un objet Pandas Series.
import pandas as pd total_sales = pd.Series([9500, 12700, 11500]) months = ['January', 'February', 'March'] total_sales = total_sales.set_axis(months) print(total_sales)
Fonctionnalités de Pandas
Maintenant que vous avez une vision claire de ce qu'est Pandas et des structures de données clés qu'il exploite, nous pouvons aborder les aspects qui font de Pandas une bibliothèque d'analyse de données si performante, et par conséquent, incroyablement populaire au sein des écosystèmes de la science des données et de l'apprentissage automatique.
#1. Manipulation de données
Les objets DataFrame et Series sont modifiables. Vous avez la possibilité d'ajouter ou de supprimer des colonnes selon vos besoins. De plus, Pandas vous permet d'ajouter des lignes et même de fusionner différents jeux de données.
Vous pouvez réaliser des calculs numériques, tels que la normalisation des données, et effectuer des comparaisons logiques élément par élément. Pandas vous donne également la possibilité de regrouper des données et d'appliquer des fonctions d'agrégation telles que la moyenne, le maximum et le minimum. Tout cela facilite la manipulation des données dans Pandas.
#2. Nettoyage des données
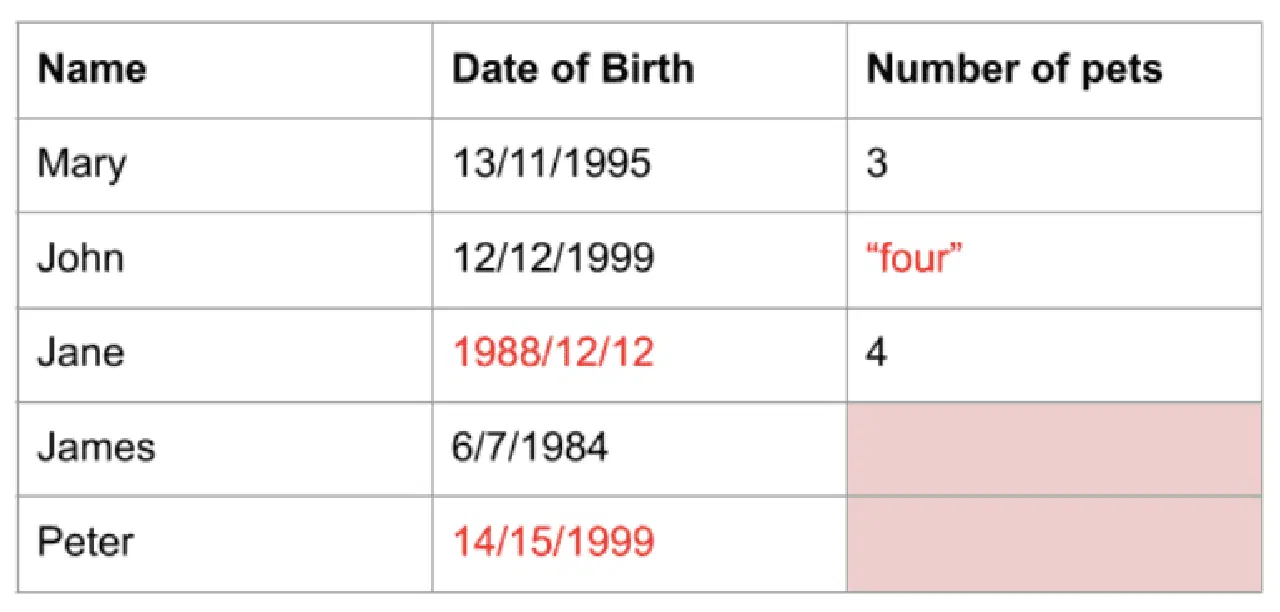
Les données issues du monde réel comportent souvent des valeurs qui rendent leur utilisation difficile ou qui ne sont pas optimales pour l'analyse ou l'application dans des modèles d'apprentissage automatique. Ces données peuvent être du mauvais type, dans un format incorrect ou simplement manquantes. Dans tous les cas, ces données nécessitent un prétraitement, appelé nettoyage, avant de pouvoir être exploitées.
Pandas dispose de fonctions pour vous aider à nettoyer vos données. Par exemple, dans Pandas, vous pouvez supprimer les lignes dupliquées, supprimer les colonnes ou lignes avec des données manquantes et remplacer les valeurs par des valeurs par défaut ou une autre valeur, telle que la moyenne de la colonne. D'autres fonctions et bibliothèques complètent Pandas pour un nettoyage des données plus poussé.
#3. Visualisation des données
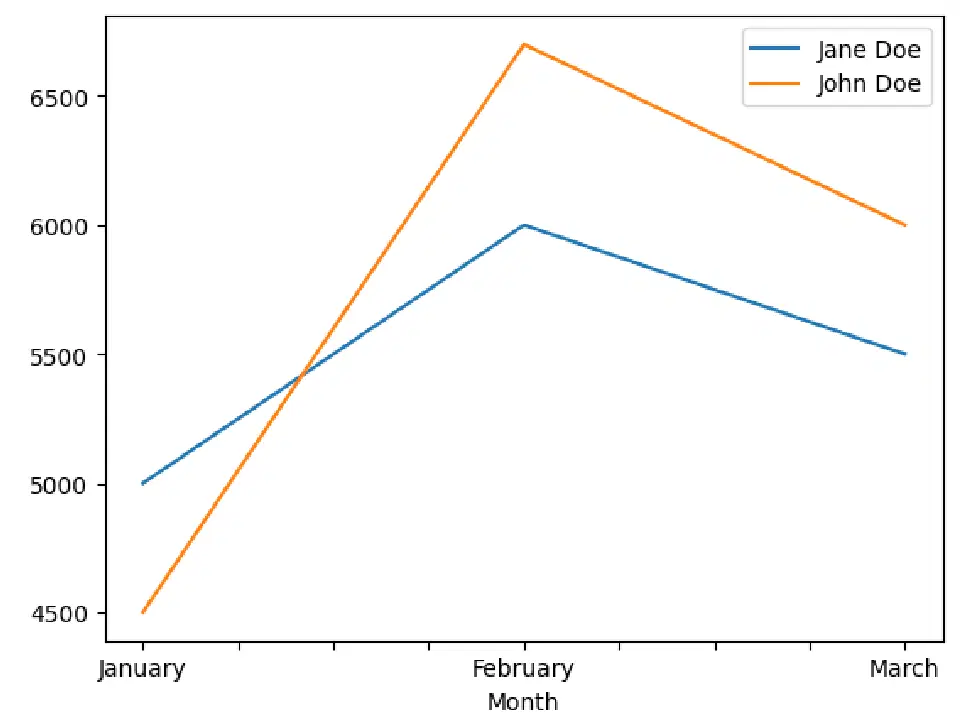 Ce graphique a été généré avec le code situé ci-dessous.
Ce graphique a été généré avec le code situé ci-dessous.
Bien que Pandas ne soit pas une bibliothèque de visualisation comme Matplotlib, il propose des fonctions pour créer des visualisations basiques. Et bien qu'elles soient simples, elles restent efficaces dans la plupart des cas.
Grâce à Pandas, vous pouvez facilement générer des graphiques à barres, des histogrammes, des matrices de dispersion et d'autres types de graphiques. En combinant cela avec les manipulations de données possibles en Python, vous pouvez créer des visualisations plus complexes pour mieux comprendre vos données.
import pandas as pd
sales_df = pd.DataFrame({
'Month': ['January', 'February', 'March'],
'Jane Doe': [5000, 6000, 5500],
'John Doe': [4500, 6700, 6000]
})
sales_df.set_index(['Month'], inplace=True)
sales_df.plot.line()
#4. Analyse des séries temporelles
Pandas prend également en charge le travail avec des données horodatées. Quand Pandas identifie une colonne contenant des valeurs de type datetime, vous pouvez effectuer un grand nombre d'opérations pertinentes pour l'analyse de données de séries temporelles.
Cela inclut le regroupement des observations par période et l'application de fonctions d'agrégation comme la somme ou la moyenne, ou l'identification des observations les plus anciennes ou les plus récentes à l'aide des fonctions min et max. Bien sûr, de nombreuses autres opérations sont possibles avec les données de séries temporelles dans Pandas.
#5. Entrée/Sortie dans Pandas
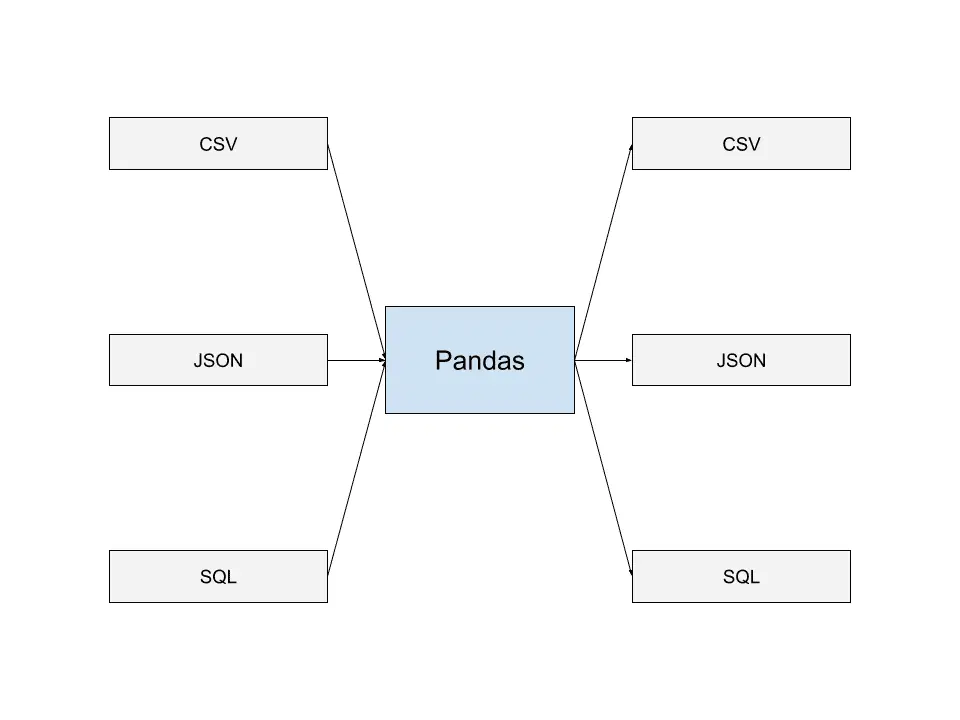
Pandas est capable de lire des données à partir des formats de stockage les plus courants, comme JSON, les vidages SQL et les fichiers CSV. Vous pouvez également écrire des données dans des fichiers dans plusieurs de ces formats.
Cette capacité à lire et écrire dans différents formats de fichiers de données permet à Pandas d'interagir de manière fluide avec d'autres applications et de créer des pipelines de données s'intégrant parfaitement avec Pandas. C'est l'une des raisons pour lesquelles Pandas est largement utilisé par de nombreux développeurs.
#6. Intégration avec d'autres bibliothèques
Pandas dispose d'un écosystème riche d'outils et de bibliothèques conçus pour compléter ses fonctionnalités, la rendant ainsi encore plus puissante et utile.
Les outils de l'écosystème Pandas enrichissent ses capacités dans divers domaines comme le nettoyage des données, la visualisation, l'apprentissage automatique, les entrées/sorties et la parallélisation. Pandas tient un registre de ces outils dans sa documentation.
Considérations de performance et d'efficacité dans Pandas
Bien que Pandas excelle dans la plupart des opérations, il peut parfois être notoirement lent. Cependant, il est possible d'optimiser votre code et d'améliorer sa vitesse. Pour cela, il est nécessaire de comprendre comment Pandas est construit.
Pandas est basé sur NumPy, une bibliothèque Python populaire pour le calcul numérique et scientifique. Par conséquent, tout comme NumPy, Pandas fonctionne de manière plus efficace lorsque les opérations sont vectorisées au lieu de sélectionner des cellules ou des lignes individuelles avec des boucles.
La vectorisation est une forme de parallélisation dans laquelle la même opération est appliquée à plusieurs points de données simultanément. C'est ce que l'on appelle SIMD - Instruction unique, données multiples. L'utilisation d'opérations vectorisées améliorera considérablement la vitesse et les performances de Pandas.
Les structures de données DataFrame et Series, utilisant des tableaux NumPy en interne, sont plus rapides que leurs alternatives comme les dictionnaires et les listes.
L'implémentation par défaut de Pandas s'exécute sur un seul cœur de processeur. Pour accélérer votre code, vous pouvez utiliser des bibliothèques qui permettent à Pandas d'exploiter tous les cœurs disponibles de votre processeur, comme Dask, Vaex, Modin et IPython.
Communauté et ressources
En tant que bibliothèque populaire du langage de programmation le plus utilisé, Pandas bénéficie d'une large communauté d'utilisateurs et de contributeurs. De ce fait, de nombreuses ressources sont disponibles pour apprendre à l'utiliser. Parmi elles, la documentation officielle de Pandas, ainsi que d'innombrables cours, tutoriels et livres.
Des communautés en ligne, comme sur Reddit dans les sous-reddits r/Python et r/Data Science, sont également là pour poser des questions et obtenir des réponses. Étant une bibliothèque open source, vous pouvez signaler des problèmes sur GitHub et même participer à son développement.
Derniers mots
Pandas est une bibliothèque incroyablement utile et puissante pour la science des données. Dans cet article, j'ai essayé de mettre en lumière sa popularité en examinant les fonctionnalités qui en font un outil incontournable pour les data scientists et les programmeurs.
À présent, apprenez comment créer un DataFrame Pandas.