Un guide étape par étape pour la configuration et l'exécution
Introduction à Apache Kafka et son installation locale
Dans l'univers informatique actuel, des myriades d'enregistrements de données sont générés quotidiennement. Ces flux d'informations incluent, par exemple, vos transactions financières, le suivi de vos commandes, ou les données émises par les capteurs de votre véhicule. Pour assurer le traitement en temps réel de ces événements et la transmission fiable des données entre différents systèmes, Apache Kafka se présente comme une solution incontournable.
Apache Kafka est une plateforme open source de diffusion de données, reconnue pour sa capacité à gérer plus d'un million d'enregistrements par seconde. Au-delà de ce débit impressionnant, elle offre une évolutivité et une disponibilité optimales, une latence réduite et un stockage persistant.
De grandes entreprises comme LinkedIn, Uber et Netflix font confiance à Apache Kafka pour le traitement et la diffusion de données en continu. Pour débuter avec Apache Kafka, le moyen le plus simple est de l'exécuter sur votre machine personnelle. Cela vous permettra d'observer le serveur Apache Kafka en action et d'expérimenter la production et la consommation de messages.
Grâce à une expérience pratique incluant le démarrage du serveur, la création de rubriques et l'écriture de code Java utilisant le client Kafka, vous serez parfaitement outillé pour exploiter Apache Kafka dans la gestion de vos flux de données.
Comment télécharger Apache Kafka sur votre machine locale
Vous pouvez récupérer la dernière version d'Apache Kafka directement depuis le site officiel. Le fichier téléchargé sera compressé au format .tgz. Après le téléchargement, vous devrez procéder à son extraction.
Si vous utilisez Linux, ouvrez votre terminal et dirigez-vous vers le dossier où vous avez enregistré le fichier compressé d'Apache Kafka. Ensuite, exécutez la commande suivante :
tar -xzvf kafka_2.13-3.5.0.tgz
Une fois l'exécution terminée, un nouveau répertoire nommé kafka_2.13-3.5.0 sera créé. Vous pouvez y accéder en utilisant la commande :
cd kafka_2.13-3.5.0
Vous pouvez à présent visualiser le contenu de ce répertoire à l'aide de la commande "ls".
Les utilisateurs de Windows peuvent suivre des étapes similaires. Si vous ne trouvez pas la commande "tar", vous pouvez utiliser un outil tiers tel que WinZip pour extraire l'archive.
Démarrer Apache Kafka sur votre ordinateur local
Une fois Apache Kafka téléchargé et décompressé, il est temps de le lancer. L'outil ne nécessite pas d'installation, vous pouvez directement l'utiliser via votre ligne de commande ou votre terminal.
Avant de commencer, assurez-vous que Java 8 ou une version ultérieure est installée sur votre système, car Apache Kafka en a besoin pour fonctionner.
#1. Lancer le serveur Apache Zookeeper
La première étape est de lancer Apache Zookeeper, qui est inclus dans l'archive téléchargée. Ce service est essentiel pour la gestion des configurations et la synchronisation avec d'autres services.
Après avoir accédé au répertoire contenant les fichiers extraits, exécutez la commande suivante :
Pour Linux :
bin/zookeeper-server-start.sh config/zookeeper.properties
Pour Windows :
bin/windows/zookeeper-server-start.bat config/zookeeper.properties
Le fichier zookeeper.properties fournit les paramètres de configuration nécessaires au démarrage du serveur Apache Zookeeper. Vous pouvez y définir des propriétés telles que le répertoire de stockage des données et le port d'écoute du serveur.
#2. Démarrer le serveur Apache Kafka
Après le démarrage du serveur Apache Zookeeper, vous pouvez lancer le serveur Apache Kafka.
Ouvrez une nouvelle fenêtre de terminal ou d'invite de commande et rendez-vous dans le répertoire où vous avez extrait les fichiers. Ensuite, lancez le serveur Apache Kafka à l'aide de la commande ci-dessous :
Pour Linux :
bin/kafka-server-start.sh config/server.properties
Pour Windows :
bin/windows/kafka-server-start.bat config/server.properties
Votre serveur Apache Kafka est à présent opérationnel. Si vous souhaitez ajuster la configuration par défaut, vous pouvez le faire en modifiant le fichier server.properties. Les détails de ces paramètres sont disponibles dans la documentation officielle.
Utilisation d'Apache Kafka sur votre machine locale
Vous êtes maintenant en mesure d'utiliser Apache Kafka sur votre machine locale pour produire et consommer des messages. Les serveurs Apache Zookeeper et Apache Kafka étant en marche, découvrons comment créer votre premier sujet, produire votre premier message et le consommer.
Étapes pour créer un sujet dans Apache Kafka
Avant de créer votre premier sujet, comprenons sa définition. Dans Apache Kafka, un sujet représente un flux de données logique, une sorte de canal par lequel les données sont transportées d'un composant à un autre.
Un sujet autorise de multiples producteurs et consommateurs – plusieurs systèmes peuvent écrire et lire des données à partir d'un même sujet. Contrairement à d'autres systèmes de messagerie, un message dans un sujet peut être consommé plusieurs fois. Vous pouvez également définir la durée de conservation de vos messages.
Prenons l'exemple d'un système (producteur) générant des données de transactions bancaires. Un autre système (consommateur) consomme ces données et envoie une notification à l'utilisateur. La mise en place d'un sujet facilite cette interaction.
Ouvrez une nouvelle fenêtre de terminal ou d'invite de commande et dirigez-vous vers le dossier où vous avez extrait l'archive. La commande suivante créera un sujet nommé "transactions" :
Pour Linux :
bin/kafka-topics.sh --create --topic transactions --bootstrap-server localhost:9092
Pour Windows :
bin/windows/kafka-topics.bat --create --topic transactions --bootstrap-server localhost:9092
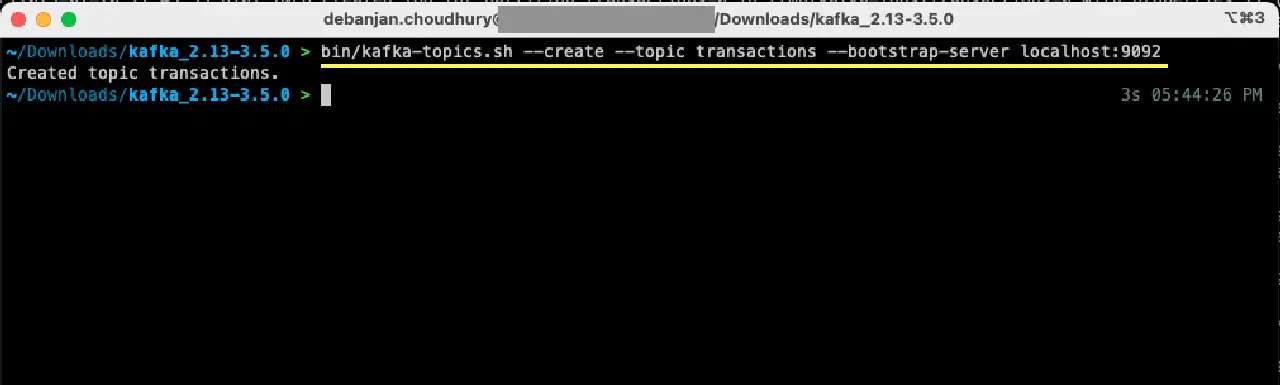
Votre premier sujet est créé, vous êtes maintenant prêt à produire et consommer des messages.
Comment produire un message dans Apache Kafka ?
Votre sujet Apache Kafka étant prêt, vous pouvez maintenant produire votre premier message. Ouvrez une nouvelle fenêtre de terminal ou d'invite de commande, ou utilisez celle que vous avez employée pour la création du sujet. Assurez-vous que vous êtes dans le bon répertoire. Utilisez la ligne de commande suivante pour envoyer un message à votre sujet :
Pour Linux :
bin/kafka-console-producer.sh --topic transactions --bootstrap-server localhost:9092
Pour Windows :
bin/windows/kafka-console-producer.bat --topic transactions --bootstrap-server localhost:9092
Après avoir exécuté la commande, votre terminal attendra une saisie. Écrivez votre premier message et appuyez sur Entrée.
> This is a transactional record for $100

Vous venez de produire votre premier message à Apache Kafka sur votre ordinateur local, vous êtes maintenant prêt à le consommer.
Comment consommer un message depuis Apache Kafka ?
Maintenant que votre sujet a été créé et que vous avez produit un message, vous pouvez le consommer.
Apache Kafka permet de connecter plusieurs consommateurs au même sujet. Chaque consommateur peut faire partie d'un groupe de consommateurs, identifié par un identifiant logique. Par exemple, deux services qui doivent consommer les mêmes données peuvent avoir des groupes de consommateurs différents.
Cependant, si vous avez deux instances du même service, vous voudrez éviter de consommer le même message deux fois. Dans ce cas, les deux instances utiliseront le même groupe de consommateurs.
Dans le terminal ou la fenêtre d'invite de commande, assurez-vous que vous êtes dans le bon répertoire. Utilisez la commande suivante pour démarrer le consommateur :
Pour Linux :
bin/kafka-console-consumer.sh --topic transactions --from-beginning --bootstrap-server localhost:9092 --group notif-consumer
Pour Windows :
bin/windows/kafka-console-consumer.bat --topic transactions --from-beginning --bootstrap-server localhost:9092 --group notif-consumer
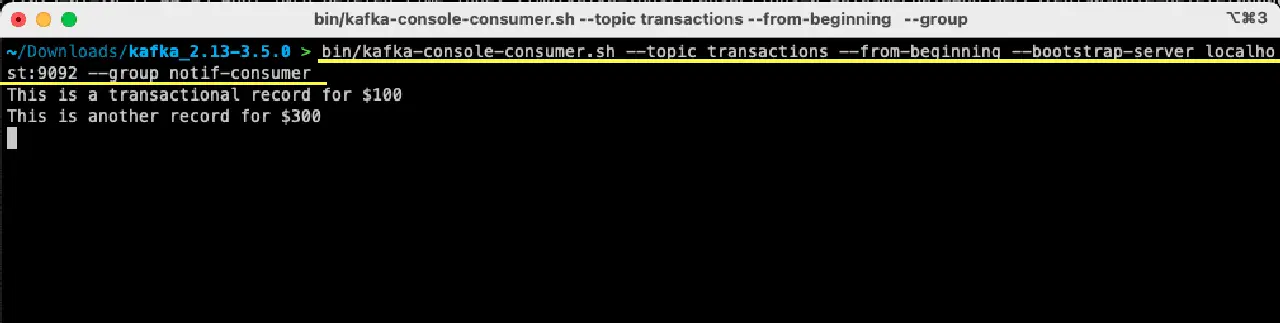
Le message que vous avez produit précédemment devrait s'afficher dans votre terminal. Vous venez d'utiliser Apache Kafka pour consommer votre premier message.
La commande `kafka-console-consumer` accepte plusieurs arguments. Voici leur signification :
- `--topic` : spécifie le sujet à partir duquel vous allez consommer les messages.
- `--from-beginning` : indique au consommateur de commencer à lire les messages depuis le début du sujet.
- `--bootstrap-server` : précise l'adresse de votre serveur Apache Kafka.
- `--group` : permet de définir un groupe de consommateurs. Si ce paramètre est omis, un groupe est généré automatiquement.
Le consommateur étant en cours d'exécution, vous pouvez essayer de produire de nouveaux messages, ils seront immédiatement consommés et affichés dans votre terminal.
Maintenant que vous avez créé un sujet et que vous avez produit et consommé des messages avec succès, voyons comment l'intégrer dans une application Java.
Comment créer un producteur et un consommateur Apache Kafka en Java
Avant de commencer, assurez-vous que Java 8 ou une version ultérieure est installée sur votre machine locale. Apache Kafka fournit sa propre librairie client qui permet une connexion transparente. Si vous utilisez Maven pour gérer vos dépendances, ajoutez la dépendance suivante à votre fichier pom.xml :
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.5.0</version>
</dependency>
Vous pouvez également télécharger la librairie depuis le Maven Repository et l'ajouter à votre classpath Java.
Une fois la librairie configurée, ouvrez un éditeur de code de votre choix. Voyons comment démarrer votre producteur et votre consommateur en utilisant Java.
Créer un producteur Java Apache Kafka
Avec la librairie kafka-clients configurée, vous pouvez commencer à créer votre producteur Kafka.
Créons une classe nommée SimpleProducer.java. Celle-ci aura pour rôle de produire des messages sur le sujet que vous avez créé précédemment. Dans cette classe, vous allez créer une instance de org.apache.kafka.clients.producer.KafkaProducer. Vous utiliserez ensuite ce producteur pour envoyer vos messages.
Pour créer le producteur Kafka, vous avez besoin de l'adresse et du port de votre serveur Apache Kafka. Comme vous l'exécutez sur votre machine locale, l'adresse sera localhost et le port 9092 (si vous n'avez pas modifié la configuration par défaut). Le code suivant vous aidera à créer votre producteur :
package org.example.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
public class SimpleProducer {
private final KafkaProducer<String, String> producer;
public SimpleProducer(String host, String port) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
this.producer = new KafkaProducer<>(properties);
}
}
Vous remarquerez que trois propriétés sont définies. Voici une brève description de chacune :
- `BOOTSTRAP_SERVERS_CONFIG` : vous permet de spécifier l'adresse où le serveur Apache Kafka est en cours d'exécution.
- `KEY_SERIALIZER_CLASS_CONFIG` : indique au producteur le format à utiliser pour l'envoi des clés de message.
- `VALUE_SERIALIZER_CLASS_CONFIG` : définit le format utilisé pour l'envoi du message proprement dit.
Comme vous allez envoyer des messages texte, les deux dernières propriétés sont configurées pour utiliser StringSerializer.class.
Pour envoyer un message à votre sujet, vous devez utiliser la méthode Producer.send() qui prend un ProducerRecord. Le code suivant vous fournit une méthode pour envoyer un message au sujet et afficher la réponse avec le décalage du message.
public void produce(String topic, String message) throws ExecutionException, InterruptedException {
ProducerRecord<String, String> record = new ProducerRecord<>(topic, message);
final Future<RecordMetadata> send = this.producer.send(record);
final RecordMetadata recordMetadata = send.get();
System.out.println(recordMetadata);
}
Avec tout le code en place, vous pouvez maintenant envoyer des messages à votre sujet. Vous pouvez utiliser une méthode principale pour tester, comme dans le code suivant :
package org.example.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
public class SimpleProducer {
private final KafkaProducer<String, String> producer;
public SimpleProducer(String host, String port) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
this.producer = new KafkaProducer<>(properties);
}
public void produce(String topic, String message) throws ExecutionException, InterruptedException {
ProducerRecord<String, String> record = new ProducerRecord<>(topic, message);
final Future<RecordMetadata> send = this.producer.send(record);
final RecordMetadata recordMetadata = send.get();
System.out.println(recordMetadata);
}
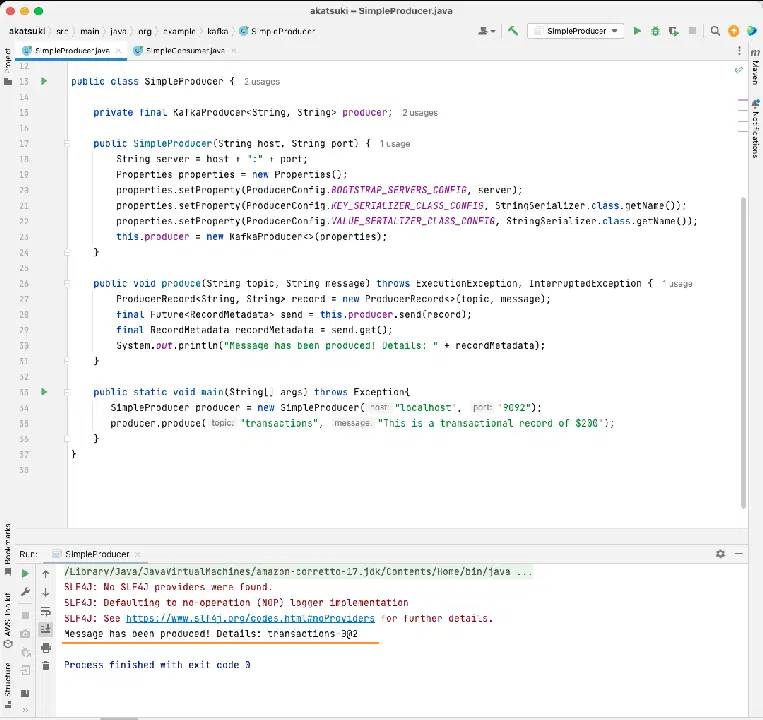
public static void main(String[] args) throws Exception{
SimpleProducer producer = new SimpleProducer("localhost", "9092");
producer.produce("transactions", "This is a transactional record of $200");
}
}
Dans ce code, vous créez un SimpleProducer qui se connecte à votre serveur Apache Kafka sur votre ordinateur local. Il utilise en interne le KafkaProducer pour produire des messages texte sur votre sujet.
Créer un consommateur Java Apache Kafka
Il est temps de créer un consommateur Apache Kafka en utilisant le client Java. Créez une classe nommée SimpleConsumer.java. Vous y ajouterez un constructeur qui initialise org.apache.kafka.clients.consumer.KafkaConsumer. Pour créer le consommateur, vous avez besoin de l'adresse et du port où le serveur Apache Kafka est en cours d'exécution. Vous avez également besoin du groupe de consommateurs ainsi que du sujet que vous souhaitez consommer. Utilisez l'extrait de code ci-dessous :
package org.example.kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.atomic.AtomicBoolean;
public class SimpleConsumer {
private static final String OFFSET_RESET = "earliest";
private final KafkaConsumer<String, String> consumer;
private boolean keepConsuming = true;
public SimpleConsumer(String host, String port, String consumerGroupId, String topic) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, consumerGroupId);
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, OFFSET_RESET);
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
this.consumer = new KafkaConsumer<>(properties);
this.consumer.subscribe(List.of(topic));
}
}
Comme pour le producteur Kafka, le consommateur Kafka prend également un objet Properties. Examinons les différentes propriétés définies :
- `BOOTSTRAP_SERVERS_CONFIG` : indique au consommateur l'adresse du serveur Apache Kafka.
- `GROUP_ID_CONFIG` : spécifie le groupe de consommateurs.
- `AUTO_OFFSET_RESET_CONFIG` : permet de préciser à quel moment le consommateur doit commencer à lire les messages.
- `KEY_DESERIALIZER_CLASS_CONFIG` : indique au consommateur le type de clé de message.
- `VALUE_DESERIALIZER_CLASS_CONFIG` : spécifie le type des messages consommés.
Dans ce cas précis, comme vous allez consommer des messages texte, les propriétés de désérialisation sont définies sur StringDeserializer.class.
Vous allez maintenant consommer les messages de votre sujet. Pour simplifier, une fois le message consommé, il sera affiché dans la console. Le code suivant montre comment procéder :
private boolean keepConsuming = true;
public void consume() {
while (keepConsuming) {
final ConsumerRecords<String, String> consumerRecords = this.consumer.poll(Duration.ofMillis(100L));
if (consumerRecords != null && !consumerRecords.isEmpty()) {
consumerRecords.iterator().forEachRemaining(consumerRecord -> {
System.out.println(consumerRecord.value());
});
}
}
}
Ce code continuera à interroger le sujet. Lorsque des enregistrements de consommateur sont reçus, le message est affiché. Vous pouvez tester votre consommateur en utilisant une méthode principale. Vous allez démarrer une application Java qui consommera les messages et les affichera. Il faudra stopper l'application Java pour terminer la consommation.
package org.example.kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.atomic.AtomicBoolean;
public class SimpleConsumer {
private static final String OFFSET_RESET = "earliest";
private final KafkaConsumer<String, String> consumer;
private boolean keepConsuming = true;
public SimpleConsumer(String host, String port, String consumerGroupId, String topic) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, consumerGroupId);
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, OFFSET_RESET);
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
this.consumer = new KafkaConsumer<>(properties);
this.consumer.subscribe(List.of(topic));
}
public void consume() {
while (keepConsuming) {
final ConsumerRecords<String, String> consumerRecords = this.consumer.poll(Duration.ofMillis(100L));
if (consumerRecords != null && !consumerRecords.isEmpty()) {
consumerRecords.iterator().forEachRemaining(consumerRecord -> {
System.out.println(consumerRecord.value());
});
}
}
}
public static void main(String[] args) {
SimpleConsumer simpleConsumer = new SimpleConsumer("localhost", "9092", "transactions-consumer", "transactions");
simpleConsumer.consume();
}
}
Lorsque vous exécuterez le code, vous remarquerez qu'il consomme non seulement le message produit par votre producteur Java, mais également ceux que vous avez produit via le producteur de la console. Cela est dû au fait que la propriété `AUTO_OFFSET_RESET_CONFIG` a été définie sur "earliest".
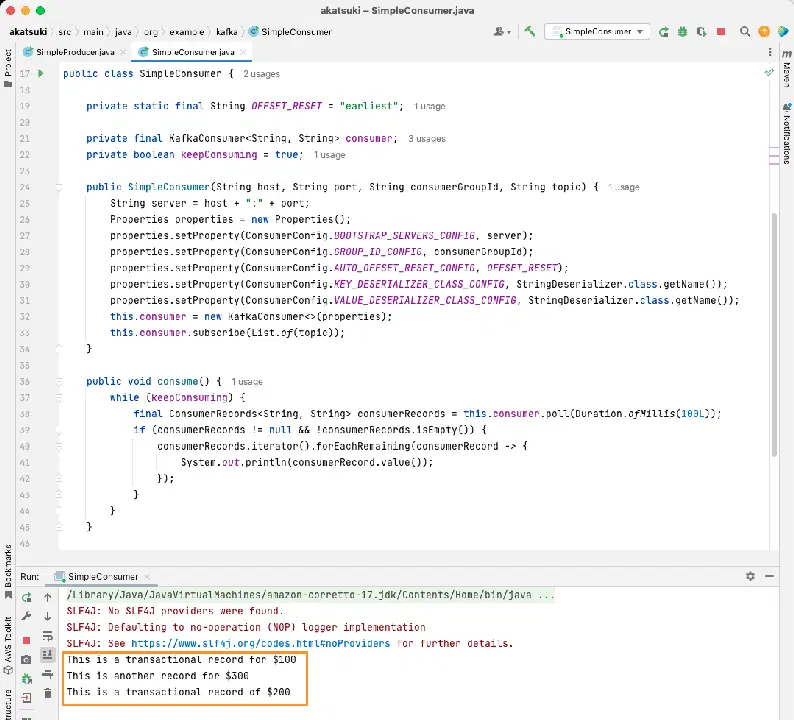
Pendant que SimpleConsumer est en cours d'exécution, vous pouvez utiliser le producteur de la console ou l'application Java SimpleProducer pour générer d'autres messages dans le sujet. Vous les verrez consommés et affichés dans la console.
Répondre à tous vos besoins en matière de flux de données avec Apache Kafka
Apache Kafka vous permet de gérer aisément toutes vos exigences en matière de flux de données. En installant Apache Kafka sur votre ordinateur local, vous pouvez explorer toutes les fonctionnalités qu'il offre. De plus, le client Java officiel vous permet d'interagir efficacement avec votre serveur Apache Kafka.
En tant que système de diffusion de données polyvalent, évolutif et performant, Apache Kafka peut véritablement transformer vos projets. Vous pouvez l'utiliser lors de vos développements locaux ou l'intégrer dans vos systèmes de production. De même que sa configuration locale est simple, configurer Apache Kafka pour des applications plus importantes est tout à fait envisageable.
Si vous recherchez des plateformes de diffusion de données, vous pouvez consulter les meilleures plateformes de données de diffusion pour l'analyse et le traitement en temps réel.